
 Datenbank
MySQL-Tutorial
Detaillierte Erläuterung des Schemacodes des verteilten MySQL-Clusters MyCAT (2).
Datenbank
MySQL-Tutorial
Detaillierte Erläuterung des Schemacodes des verteilten MySQL-Clusters MyCAT (2).
Detaillierte Erläuterung des Schemacodes des verteilten MySQL-Clusters MyCAT (2).

Im ersten Teil gibt es eine kurze Einführung in die Grundsituation von MyCAT-Konstruktions- und Konfigurationsdateien. In diesem Artikel werden einige spezifische Parameter des Schemas und seine tatsächliche Funktion beschrieben.
Beitrag Es zuerst In der Schemadatei für meine eigenen Tests wird der Backslash vor dem doppelten Anführungszeichen nicht entfernt...
<?xml version=\"1.0\"?>
<!DOCTYPE mycat:schema SYSTEM \"schema.dtd\">
<mycat:schema xmlns:mycat=\"http://org.opencloudb/\">
<schema name=\"mycat\" checkSQLschema=\"false\" sqlMaxLimit=\"100\">
<!-- auto sharding by id (long) -->
<table name=\"students\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule1\" />
<table name=\"log_test\" dataNode=\"dn1,dn2,dn3,dn4\" rule=\"rule2\" />
<!-- global table is auto cloned to all defined data nodes ,so can join
with any table whose sharding node is in the same data node -->
<!--<table name=\"company\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3\" />
<table name=\"goods\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2\" />
-->
<table name=\"item_test\" primaryKey=\"ID\" type=\"global\" dataNode=\"dn1,dn2,dn3,dn4\" />
<!-- random sharding using mod sharind rule -->
<!-- <table name=\"hotnews\" primaryKey=\"ID\" dataNode=\"dn1,dn2,dn3\"
rule=\"mod-long\" /> -->
<!--
<table name=\"worker\" primaryKey=\"ID\" dataNode=\"jdbc_dn1,jdbc_dn2,jdbc_dn3\" rule=\"mod-long\" />
-->
<!-- <table name=\"employee\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\" />
<table name=\"customer\" primaryKey=\"ID\" dataNode=\"dn1,dn2\"
rule=\"sharding-by-intfile\">
<childTable name=\"orders\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\">
<childTable name=\"order_items\" joinKey=\"order_id\"
parentKey=\"id\" />
<ildTable>
<childTable name=\"customer_addr\" primaryKey=\"ID\" joinKey=\"customer_id\"
parentKey=\"id\" /> -->
</schema>
<!-- <dataNode name=\"dn\" dataHost=\"localhost\" database=\"test\" /> -->
<dataNode name=\"dn1\" dataHost=\"localhost\" database=\"test1\" />
<dataNode name=\"dn2\" dataHost=\"localhost\" database=\"test2\" />
<dataNode name=\"dn3\" dataHost=\"localhost\" database=\"test3\" />
<dataNode name=\"dn4\" dataHost=\"localhost\" database=\"test4\" />
<!--
<dataNode name=\"jdbc_dn1\" dataHost=\"jdbchost\" database=\"db1\" />
<dataNode name=\"jdbc_dn2\" dataHost=\"jdbchost\" database=\"db2\" />
<dataNode name=\"jdbc_dn3\" dataHost=\"jdbchost\" database=\"db3\" />
-->
<dataHost name=\"localhost\" maxCon=\"100\" minCon=\"10\" balance=\"1\"
writeType=\"1\" dbType=\"mysql\" dbDriver=\"native\">
<heartbeat>select user()<beat>
<!-- can have multi write hosts -->
<writeHost host=\"localhost\" url=\"localhost:3306\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS1\" url=\"localhost:3307\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
<writeHost host=\"localhost1\" url=\"localhost:3308\" user=\"root\" password=\"wangwenan\">
<!-- can have multi read hosts -->
<readHost host=\"hostS11\" url=\"localhost:3309\" user=\"root\" password=\"wangwenan\"/>
</writeHost>
</dataHost>
<!-- <writeHost host=\"hostM2\" url=\"localhost:3316\" user=\"root\" password=\"123456\"/> -->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"1\" balance=\"0\" writeType=\"0\" dbType=\"mongodb\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM\" url=\"mongodb://192.168.0.99/test\" user=\"admin\" password=\"123456\" ></writeHost>
</dataHost>
-->
<!--
<dataHost name=\"jdbchost\" maxCon=\"1000\" minCon=\"10\" balance=\"0\"
dbType=\"mysql\" dbDriver=\"jdbc\">
<heartbeat>select user()<beat>
<writeHost host=\"hostM1\" url=\"jdbc:mysql://localhost:3306\"
user=\"root\" password=\"123456\">
</writeHost>
</dataHost>
-->
</mycat:schema> Erste Parameterzeile<Schemaname ="mycat" checkSQLschema="false" sqlMaxLimit= "100"/>
In dieser Parameterzeile definiert Schemaname den Namen der logischen Datenbank, die sein kann wird auf dem MyCAT-Frontend angezeigt ,
Wenn der checkSQLschema-Parameter „False“ ist, bedeutet dies, dass MyCAT beispielsweise automatisch den Datenbanknamen vor dem Tabellennamen ignoriert , mydatabase1.test1 wird als test1 betrachtet;
sqlMaxLimit gibt den Grenzwert für die Anzahl der von der SQL-Anweisung zurückgegebenen Zeilen an;
🎜>
Als Screenshot zeigt dieses Limit, dass mycat beim Verteilen der SQL-Anweisung automatisch ein LIMIT hinzufügt. limit Wie Sie in der oberen rechten Ecke sehen können, wird MyCAT selbst zwischengespeichert
; Wenn also die von uns ausgeführte Anweisung mehr Datenzeilen zurückgibt, was wird MyCAT dann tun, ohne dieses Limit zu ändern? > Wenn also in der eigentlichen Anwendung eine große Datenmenge zurückgegeben werden muss, müssen Sie dies möglicherweise manuell tun Ändern Sie die Logik
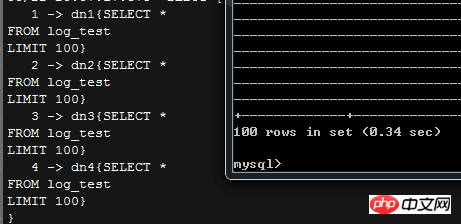 In der Version 1.4 von mycat deckt der Limit-Parameter des Benutzers die Standard-MyCAT-Einstellung ab
In der Version 1.4 von mycat deckt der Limit-Parameter des Benutzers die Standard-MyCAT-Einstellung ab
> ----- ------------------------------------------- ------- ------------------------------------------- ------- ------------------------------------------- ------- -------------------------- >Tabelle
name
="students" dataNode
=
"dn1,dn2,dn3,dn4" Regel="rule1" /> Diese Zeile stellt Which dar Tabellennamen werden auf dem MyCAT-Frontend angezeigt? Ähnliche Zeilen bedeuten hier alle dasselbe. Der Schwerpunkt liegt hier auf der Tabelle, und MyCAT definiert nicht die Tabellenstruktur in der Konfigurationsdatei. Wenn Sie show create table verwenden Im Frontend zeigt MyCAT normalerweise Informationen zur Tabellenstruktur an. Beachten Sie das Debug-Protokoll. Es ist ersichtlich, dass MyCAT den Befehl an die durch dn1 dargestellte Datenbank verteilt und dann das Abfrageergebnis von dn1 an das Front-End zurückgibt.
Es kann davon ausgegangen werden, dass einige ähnliche Abfrageanweisungen auf Datenbankebene möglicherweise an eine bestimmte Datenbank verteilt werden Geben Sie dann die Informationen eines bestimmten Knotens separat an das Frontend zurück. Derzeit unterstützt MyCAT nur die Segmentierung nach einer speziellen Spalte und nach einigen speziellen Regeln wie Modulo, Aufzählung usw. Die Details werden besprochen später
----- -------------------------------------- ------------ -------------------------------------- ------------ -------------------------------------- ----------- --------------------
Name
=
"item_test" PrimaryKey="ID" Typ ="global" dataNode="dn1,dn2,dn3,dn4" /> Diese Zeile stellt die globale Tabelle dar, was bedeutet, dass die Tabelle item_test vollständige Datenkopien in den vier dataNodes enthält und dann an alle Datenbanken verteilt wird bei der Abfrage? ---------- ------------------------------------- ------------- ------------------------------------- ------------- ------------------------------------- ------------- -------------Ich habe im Test eigentlich keine Childtable verwendet, aber im Designdokument von MyCAT wurde erwähnt, dass Childtable eine Struktur ist, die von der Parent-Tabelle abhängt.
Das bedeutet, dass der Joinkey von Childtable der ParentKey-Strategie von folgt Übergeordnete Tabelle. Wenn die übergeordnete Tabelle mit der untergeordneten Tabelle verbunden ist und die Verbindungsbedingung childtable.joinKey=parenttable.parentKey lautet, wird keine datenbankübergreifende Verbindung hergestellt. ---------------------------------------- ---------- ---------------------------------------- ---------- ---------------------------------------- ---------- -------------
Die Parameter von dataNode wurden im vorherigen Kapitel vorgestellt, also überspringen Sie hier~
--------- ---------------------------------------- --------- ---------------------------------------- --------- ---------------------------------------- --------- -----------------
dataHost konfiguriert den eigentlichen Back-End-Datenbankcluster. Die meisten Parameter sind einfach und leicht zu verstehen. Hier werde ich sie nicht vorstellen Ich werde nur die beiden wichtigeren Parameter writeType und balance von
vorstellen. Der Testprozess ist hier schwieriger, daher werde ich die Schlussfolgerung direkt veröffentlichen:
) 2. Wenn Balance=1, werden Lesevorgänge zufällig auf localhost1 und zwei Lesehosts verteilt (wenn
localhost fehlschlägt, werden Schreibvorgänge auf
localhost1 ausgeführt, wenn Wenn localhost1 schlägt erneut fehl, Schreibvorgänge können nicht ausgeführt werden
) 3. Wenn Balance=2, werden Schreibvorgänge auf localhost ausgeführt und Lesevorgänge werden zufällig auf LocalHost1, LocalHost1 und zwei Readhost (das gleiche wie oben)
4.writeType = 0, Schreibvorgänge erfolgen auf LocalHost1 Nach localhost wird wiederhergestellt, es wird nicht zurück zu localhost für Schreibvorgänge gewechselt Auf localhost und
localhost1 hat der einzelne Fehlerpunkt keinen Einfluss auf den Schreibvorgang des Clusters . Die Back-End-Slave-Bibliothek kann jedoch keine Updates von der ausgefallenen Hauptbibliothek erhalten und schlägt fehl, wenn Dateninkonsistenz auftritt
, aber die Slave-Bibliothek von localhost kann keine Aktualisierungen von localhost erhalten. Die Slave-Bibliothek von localhost weist Dateninkonsistenzen mit anderen Bibliotheken auf. ------------- -------------------------------------------------- -------------------------------------------------- -------------------------------------------------- -------------Tatsächlich Die Lese- und Schreibtrennung von MyCAT selbst basiert auf der Synchronisierung des Back-End-Clusters, und MyCAT selbst bietet Funktionen zur Anweisungsverteilung. Die sqlLimit-Einschränkung führt auch dazu, dass MyCAT einige Auswirkungen auf die Logik der Front-End-Anwendungsschicht hat
Die Konfiguration vom Schema zur Tabelle zeigt, dass die logische Struktur von MyCAT selbst die Funktion der Unterdatenbank und Untertabelle umfasst (kann Geben Sie an, dass verschiedene Tabellen in verschiedenen Datenbanken vorhanden sind, ohne dass sie in alle Datenbanken aufgeteilt werden müssen)
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung des Schemacodes des verteilten MySQL-Clusters MyCAT (2).. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL: Einfache Konzepte für einfaches Lernen
Apr 10, 2025 am 09:29 AM
MySQL ist ein Open Source Relational Database Management System. 1) Datenbank und Tabellen erstellen: Verwenden Sie die Befehle erstellte und creatEtable. 2) Grundlegende Vorgänge: Einfügen, aktualisieren, löschen und auswählen. 3) Fortgeschrittene Operationen: Join-, Unterabfrage- und Transaktionsverarbeitung. 4) Debugging -Fähigkeiten: Syntax, Datentyp und Berechtigungen überprüfen. 5) Optimierungsvorschläge: Verwenden Sie Indizes, vermeiden Sie ausgewählt* und verwenden Sie Transaktionen.
 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
So erstellen Sie Navicat Premium
Apr 09, 2025 am 07:09 AM
Erstellen Sie eine Datenbank mit Navicat Premium: Stellen Sie eine Verbindung zum Datenbankserver her und geben Sie die Verbindungsparameter ein. Klicken Sie mit der rechten Maustaste auf den Server und wählen Sie Datenbank erstellen. Geben Sie den Namen der neuen Datenbank und den angegebenen Zeichensatz und die angegebene Kollektion ein. Stellen Sie eine Verbindung zur neuen Datenbank her und erstellen Sie die Tabelle im Objektbrowser. Klicken Sie mit der rechten Maustaste auf die Tabelle und wählen Sie Daten einfügen, um die Daten einzufügen.
 MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL: Wesentliche Fähigkeiten für Entwickler
Apr 10, 2025 am 09:30 AM
MySQL und SQL sind wesentliche Fähigkeiten für Entwickler. 1.MYSQL ist ein Open -Source -Relational Database Management -System, und SQL ist die Standardsprache, die zum Verwalten und Betrieb von Datenbanken verwendet wird. 2.MYSQL unterstützt mehrere Speichermotoren durch effiziente Datenspeicher- und Abruffunktionen, und SQL vervollständigt komplexe Datenoperationen durch einfache Aussagen. 3. Beispiele für die Nutzung sind grundlegende Abfragen und fortgeschrittene Abfragen wie Filterung und Sortierung nach Zustand. 4. Häufige Fehler umfassen Syntaxfehler und Leistungsprobleme, die durch Überprüfung von SQL -Anweisungen und Verwendung von Erklärungsbefehlen optimiert werden können. 5. Leistungsoptimierungstechniken umfassen die Verwendung von Indizes, die Vermeidung vollständiger Tabellenscanning, Optimierung von Join -Operationen und Verbesserung der Code -Lesbarkeit.
 So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
So erstellen Sie eine neue Verbindung zu MySQL in Navicat
Apr 09, 2025 am 07:21 AM
Sie können eine neue MySQL -Verbindung in Navicat erstellen, indem Sie den Schritten folgen: Öffnen Sie die Anwendung und wählen Sie eine neue Verbindung (Strg N). Wählen Sie "MySQL" als Verbindungstyp. Geben Sie die Hostname/IP -Adresse, den Port, den Benutzernamen und das Passwort ein. (Optional) Konfigurieren Sie erweiterte Optionen. Speichern Sie die Verbindung und geben Sie den Verbindungsnamen ein.
 So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
So wiederherstellen Sie Daten nach dem Löschen von SQL Zeilen
Apr 09, 2025 pm 12:21 PM
Das Wiederherstellen von gelöschten Zeilen direkt aus der Datenbank ist normalerweise unmöglich, es sei denn, es gibt einen Backup- oder Transaktions -Rollback -Mechanismus. Schlüsselpunkt: Transaktionsrollback: Führen Sie einen Rollback aus, bevor die Transaktion Daten wiederherstellt. Sicherung: Regelmäßige Sicherung der Datenbank kann verwendet werden, um Daten schnell wiederherzustellen. Datenbank-Snapshot: Sie können eine schreibgeschützte Kopie der Datenbank erstellen und die Daten wiederherstellen, nachdem die Daten versehentlich gelöscht wurden. Verwenden Sie eine Löschanweisung mit Vorsicht: Überprüfen Sie die Bedingungen sorgfältig, um das Verhandlich von Daten zu vermeiden. Verwenden Sie die WHERE -Klausel: Geben Sie die zu löschenden Daten explizit an. Verwenden Sie die Testumgebung: Testen Sie, bevor Sie einen Löschvorgang ausführen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 PhpMyAdmin Connection MySQL
Apr 10, 2025 pm 10:57 PM
PhpMyAdmin Connection MySQL
Apr 10, 2025 pm 10:57 PM
Wie verbinde ich mit PhpMyAdmin mit MySQL? Die URL zum Zugriff auf phpmyadmin ist normalerweise http: // localhost/phpmyadmin oder http: // [Ihre Server -IP -Adresse]/Phpmyadmin. Geben Sie Ihren MySQL -Benutzernamen und Ihr Passwort ein. Wählen Sie die Datenbank aus, mit der Sie eine Verbindung herstellen möchten. Klicken Sie auf die Schaltfläche "Verbindung", um eine Verbindung herzustellen.
