

hat zuvor die Rolle von SCHEMA vorgestellt ~
Zunächst werden in dieser Datei die Regeln für das Sharding entwickelt. Dieses Mal extrahieren wir nur einige Methoden mit relativ hoher Nutzungsrate. Schauen wir uns zunächst den Inhalt der Konfigurationsdatei an.
Der obere Teil des Screenshots beschreibt die Definition der Regel und der untere Teil zeigt Die tatsächlichen Segmentierungsregeln, die der Regel entsprechen, stellen hier die folgenden vier Segmentierungsmethoden vor~Murmel wurde ausgetrickst~ - --------------- ----------------------------------- --------------- ----------Hash-int------- --------------- ----------------------------------- --------------- -----------
- --------------- ----------------------------------- --------------- ----------Hash-int------- --------------- ----------------------------------- --------------- -----------
Schauen wir uns zunächst hash-int an. Unter dieser Segmentierungsregel gibt es eine Mapfile, was bedeutet, dass die Segmentierungsregel basierend auf dem Inhalt bestimmt wird von partition-hash-int, dann schauen Sie sich diese Textdatei an
Sehr einfacher Inhalt. Dies bedeutet, dass in der für die Segmentierung verwendeten Basisspalte ein Wert von 10000 platziert wird erster DN (dn1), und wenn der Wert 10010 ist, wird er im zweiten DN (dn2) platziert
Sie können den tatsächlichen Effekt sehen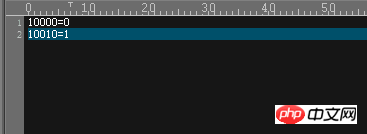
Schauen Sie sich das MyCAT-Debug-Protokoll an. Diese beiden Anweisungen sind dn1 und dn2 zugewiesen und die entsprechenden Daten werden auch in die Datenbank eingefügt.
(Bagger rollt unruhig ~), welche Auswirkung hat es, wenn der Wert der Referenzspalte in den eingefügten Daten nicht dem in dieser Datei angegebenen Wert entspricht?
, die grob als 
Aufzählungspartition verstanden werden kann, was für Anlässe mit festen Werten wie Geschlecht (0,1) besser geeignet ist Provinz (fester Wert, der kurzfristig nicht möglich sein wird) Nehmen wir die japanische Provinz zurück~), Kanalhändler
oder IDs verschiedener Plattformen
Und mit einer Komma-Trennung können mehrere Werte in einer Partition platziert werden, sodass Sie die Segmentierungsstrategie entsprechend dem tatsächlichen Daten-/Verkehrs-/Zugriffsvolumen umfassend formulieren können. Kein allmächtiger Krieger╮(╯_ ╰)╭
--------------------- -------- ------------------------------------------ -------- ----------Reichweite-lang--------------------------------- ---- ---------------------------------------------- --- Die zweite Segmentierungsmethode, Range-Long, ähnelt Hash-Int, wenn Sie genau hinsehen. Die Segmentierungsstrategie wird auch durch eine bestimmte Datei bestimmt, daher ist es besser, einen Blick auf den Inhalt der Datei zu werfen Aus dem Inhalt der Datei geht hervor, dass dies eine Möglichkeit ist, den Bereich zu unterteilen, den Bereich der Benchmark-Spalte zu formulieren und dann alle Daten in diesem Bereich auf einem DN zusammenzufassen, diesem This Die Methode ist im Grunde die gleiche wie Hash-Int, daher werde ich keine Screenshots machen (spätes Stadium der Faulheit, nicht genug Zeit!)
Bei dieser Segmentierungsstrategie bin ich persönlich der Meinung, dass es in Geschäftsdatenbanken weniger Nutzungsszenarien geben wird, weil dieser Segmentierung Die Methode muss die Gesamtmenge vorbestimmen, die bestimmt, dass Daten mit unbegrenztem Wachstum nicht verwendet werden können. Schließlich wird es sehr mühsam sein, diese Segmentierungsstrategie zu ändern.
Wenn Sie sie wirklich verwenden möchten, bin ich der Meinung, dass dies der Fall ist Es wird nur zum automatischen Erhöhen von Primärschlüsseln verwendet und dann gleichmäßig durch eine bestimmte Anzahl geteilt, z. B. ein Unternehmen, das täglich X Daten erfasst (Temperaturerfassung? Datenerfassung usw.) und dann mehrere erstellt DNs (Bibliotheken) im Voraus. 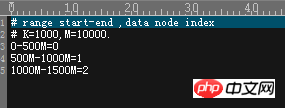 Datenbanken) haben überhaupt keine E/A-Vorgänge. Es wird
Datenbanken) haben überhaupt keine E/A-Vorgänge. Es wird
ähnlich dem üblichen Hot-Block-/Hot-Disk-Phänomen in der Datenbank geben, und MySQL verwendet häufig automatisch inkrementierende Primärschlüssel, sodass es viel mehr Möglichkeiten für a gibt große Anzahl „sequentieller“ Einfügungen in MySQL-Tabellen
.
---------------- ------ ----------------------------------------mod- long- -------------------------------------------------- ------------- -------------------- Mod-lang, aus Mod-Sicht sollte dies eine Methode sein, um den Rest zu erfassen. Werfen wir einen Blick auf die spezifischen Konfigurationsinformationen. Erreichen Sie die gleichmäßig verteilten Daten auf vier DN. (die Anzahl der DNs von Count & LT; DN ist kein Problem) Schauen Sie sich den tatsächlichen Effekt an Schauen Sie sich die Mycat-Debug-Protokolle an, siehe Mycat ist der Umgang mit
Bei Verwendung dieser Methode zum Berechnen des Rests werden diese vier Daten in vier DN (Bibliotheken) eingefügt, und es ist ersichtlich, dass die Daten beim Einfügen der Sequenz gleichmäßig in den Daten verteilt sind. Bibliotheken) oben Im Vergleich zur oben genannten Bereichsmethode verteilt diese Aufteilungsstrategie den Druck des Datenbankschreibens besser , aber das Problem liegt auch auf der Hand Sobald eine Bereichsabfrage erfolgt, muss MyCAT zusammengeführt werden Wenn die Datenmenge groß ist, kann der Zeitaufwand für diese Art von datenbankübergreifenden Abfragen und zusammengeführten Ergebnissen erheblich zunehmen, insbesondere wenn die Reihenfolge eingehalten wird.
von.
Diese Art der Divisionsstrategie wird also besser für eine Einzelpunkt-Abfrageszene geeignet sein , zum Beispiel ... Ich weiß nicht ... Ich weiß es wirklich nicht, vielleicht in der Bank: Bei der Abfrage persönlicher Kontoinformationen können einige Tabellen mit Benutzerinformationen überflüssig sein. Anschließend wird diese Methode verwendet, um effizientere Abfragen bereitzustellen (schließlich hat die Bank eine große Anzahl von Benutzern, eh~)
-------------------------------------------------------- - --------------------------------------------partition-by-long- ----- --------------------------------------------- ----- ------------
   Seien Sie in Reichweite -long und mod -Eine leicht kompromittierte Partitionierungsstrategie zwischen -long. Die spezifische Partitionierungssituation wird wie folgt beschrieben: Mit 1024 als Einheit speichert jeder DN die Datenmenge partitionLength und partitionCount x partitionLength = 1024
Um es anschaulich zu beschreiben, nehmen Sie
partitionCount(4) x partitionLength(256) als Beispiel in DN1,256-. 511 Legen Sie es auf DN2 usw. Versuchen Sie, acht Daten mit 128 als Offset-Wert einzufügen und sehen Sie sich direkt das Protokoll von MyCat an
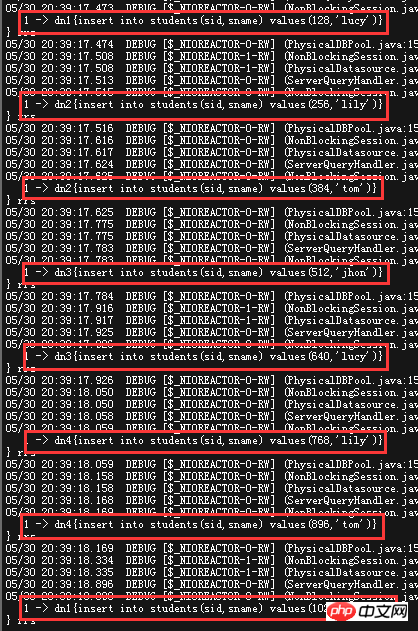 Innerhalb eines DN~
Innerhalb eines DN~
Es lohnt sich Erwähnung, dass diese Segmentierungsstrategie auch eine ungleichmäßige Verteilung unterstützt ~ Es ist wirklich unfassbar, zwei gestohlene Bilder ~
> > Diese Teilungsstrategie erfordert gleichzeitig einen Kompromiss zwischen  range-long und mod-long Zeitlich ist es relativ flexibel und kann je nach Situation für eine ungleichmäßige Aufteilung verwendet werden. Es kann tatsächlich in etwas mehr Szenarien angewendet werden, oder mit anderen Worten, es kann in vielen Szenarien verwendet werden, was die Kreuzigkeit relativ verringert -DN-Situation und teilt die Daten gleichmäßig auf, und Einzelpunktabfragen werden nicht zu langsam sein.
range-long und mod-long Zeitlich ist es relativ flexibel und kann je nach Situation für eine ungleichmäßige Aufteilung verwendet werden. Es kann tatsächlich in etwas mehr Szenarien angewendet werden, oder mit anderen Worten, es kann in vielen Szenarien verwendet werden, was die Kreuzigkeit relativ verringert -DN-Situation und teilt die Daten gleichmäßig auf, und Einzelpunktabfragen werden nicht zu langsam sein. 
----------------------------- -------------------------------------------------- ----Schreiben Sie es am Ende-------------- ------- ------------------------------------------
Tatsächlich unterstützt MyCAT viele Segmentierungsmethoden. Beispielsweise können Segmentierungsstrategien auf Basis der Zeit nach Monat, Tag usw. segmentiert werden. Es gibt keine Möglichkeit, sie einzubeziehen Alle Strategien hier. Entschuldigung o( ̄ヘ ̄o#)
Tatsächlich ist es aus persönlicher Sicht kein Problem, die Zeit entsprechend der Partitionierungsstrategie der Datenbank selbst aufzuteilen. Die halbjährlichen und vierteljährlichen Daten sind immer noch dieselben. PS: _(:з ∠)_Ich bin wirklich nicht faul... Man kann sagen, dass die wichtigsten Punkte des Sub -Datenbank und Tabelle spiegeln sich grundsätzlich in dieser Regel wider. Die Aufteilung der Tabellendaten muss auf der Grundlage der tatsächlichen Geschäftsmerkmale erfolgen das Geschäft~
Das obige ist der detaillierte Inhalt vonDetaillierte Analyse der MyCAT (3)-Regel des verteilten MySQL-Clusters (Bild und Text). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



