
 Web-Frontend
js-Tutorial
Detaillierte Erklärung der regulären JavaScript-Ausdrücke, die jeder kennt
Web-Frontend
js-Tutorial
Detaillierte Erklärung der regulären JavaScript-Ausdrücke, die jeder kennt
Detaillierte Erklärung der regulären JavaScript-Ausdrücke, die jeder kennt

Wenn dies eine Zusammenfassung von regulären Ausdrücken ist, betrachte ich es lieber als Handbuch.
Drei Hauptmethoden von RegExp
RegExp verwendet in diesem Artikel die direkte Mengensyntax: /pattern/attributes. Es gibt drei Optionen für Attribute: i, m und g. m (mehrzeiliges Matching) wird nicht häufig verwendet und kann direkt weggelassen werden, sodass ein Muster (Matching-Muster) wie folgt ausgedrückt werden kann:
var pattern = /hello/ig;
i (ignorieren) bedeutet keine Größenunterscheidung. Schreiben (lokale Suche Übereinstimmung), was relativ einfach ist und in den folgenden Beispielen nicht beschrieben wird. g (global) bedeutet global (Suchübereinstimmung). , Suchen Sie weiter, nachdem Sie eine gefunden haben, die relativ kompliziert ist. Unter den folgenden Methoden wird speziell vorgestellt.
Da es sich um die drei Hauptmethoden von RegExp handelt, haben sie alle das Format „pattern.test/exec/complie“.
Test
Hauptfunktion: Erkennen, ob die angegebene Zeichenfolge eine bestimmte Teilzeichenfolge (oder ein passendes Muster) enthält, und Rückgabe wahr oder falsch.
Beispiele sind wie folgt:
var s = 'you love me and I love you'; var pattern = /you/; var ans = pattern.test(s); console.log(ans); // true
Wenn Attribute g verwenden, können Sie mit der Suche fortfahren, die auch das lastIndexAttribut einbezieht (siehe Einführung von g in exec ).
exec
Hauptfunktion: Extrahieren Sie die erforderliche Teilzeichenfolge (oder das passende Muster) in der angegebenen Zeichenfolge und geben Sie ein Array <🎜 zurück > speichert die passenden Ergebnisse; wenn keine vorhanden sind, wird null zurückgegeben. (Sie können auch Ihre eigene Methode schreiben, um eine Schleife zu erstellen, um alle oder bestimmte Indexdaten zu extrahieren.)
exec kann als aktualisierte Version von Test bezeichnet werden, da es nicht nur erkennen, sondern auch Extrahieren Sie die Ergebnisse auch direkt nach der Erkennung. Ein Beispiel ist wie folgt:var s = 'you love me and I love you'; var pattern = /you/; var ans = pattern.exec(s); console.log(ans); // ["you", index: 0, input: "you love me and I love you"] console.log(ans.index); // 0 console.log(ans.input); // you love me and I love you
var s = 'you love me and I love you'; var pattern = /y(o?)u/; var ans = pattern.exec(s); console.log(ans); // ["you", "o", index: 0, input: "you love me and I love you"] console.log(ans.length) // 2
chrome kann irreführend sein).
Zusätzlich zu den Array-Elementen und Längeneigenschaften gibt die Methode exec() zwei Eigenschaften zurück. Das Indexattribut deklariert die Position des ersten Zeichens des übereinstimmenden Textes. Das Eingabeattribut speichert die abgerufene Zeichenfolgestring. Wir können sehen, dass, wenn die Methode exec() des nicht-globalen RegExp-Objekts aufruft, das zurückgegebene Array dasselbe ist wie das Array, das durch Aufrufen der Methode String.match() zurückgegeben wird .
Wenn Sie den Parameter „g“ verwenden, funktioniert exec() wie folgt (immer noch das obige Beispiel ps: Wenn test den Parameter g verwendet, ist es ähnlich):- Finden Sie das erste „Sie“ und speichern Sie seine Position
- Wenn Sie exec() erneut ausführen, starten Sie den Abruf von der gespeicherten Position (lastIndex) und suchen Sie das nächste „Sie“ und speichern Sie es Position
Verhalten von exec() etwas komplizierter. Es beginnt mit dem Abrufen der Zeichenfolge string bei dem Zeichen, das durch die lastIndex-Eigenschaft des RegExpObject angegeben wird. Wenn exec() Text findet, der mit einem Ausdruck übereinstimmt, setzt es die lastIndex-Eigenschaft des RegExpObject auf die Position neben dem letzten Zeichen des übereinstimmenden Texts nach der Übereinstimmung. Das bedeutet, dass wir den gesamten übereinstimmenden Text in einer Zeichenfolge durchlaufen können, indem wir die Methode exec() wiederholt aufrufen. Wenn exec() keinen passenden Text mehr findet, gibt es null zurück und setzt die lastIndex-Eigenschaft auf 0 zurück. Hier wird das lastIndex-Attribut eingeführt, das nur in Kombination mit g und test (oder g und exec) funktioniert. Es ist ein Attribut des Musters, eine Ganzzahl , die die Zeichenposition angibt, an der der nächste Abgleich beginnt.
Das Beispiel ist wie folgt:var s = 'you love me and I love you';
var pattern = /you/g;
var ans;
do {
ans = pattern.exec(s);
console.log(ans);
console.log(pattern.lastIndex);
}
while (ans !== null)
如果在一个字符串中完成了一次模式匹配之后要开始检索新的字符串(仍然使用旧的pattern),就必须手动地把 lastIndex 属性重置为 0。
compile
主要功能:改变当前匹配模式(pattern)
这货是改变匹配模式时用的,用处不大,略过。详见JavaScript compile() 方法
String 四大护法
和RegExp三大方法分庭抗礼的是String的四大护法,四大护法有些和RegExp三大方法类似,有的更胜一筹。
既然是String家族下的四大护法,所以肯定是string在前,即str.search/match/replace/split形式。
既然是String的方法,当然参数可以只用字符串而不用pattern。
search
主要功能:搜索指定字符串中是否含有某子串(或者匹配模式),如有,返回子串在原串中的初始位置,如没有,返回-1。
是不是和test类似呢?test只能判断有木有,search还能返回位置!当然test()如果有需要能继续找下去,而search则会自动忽略g(如果有的话)。实例如下:
var s = 'you love me and I love you'; var pattern = /you/; var ans = s.search(pattern); console.log(ans); // 0
话说和String的indexOf方法有点相似,不同的是indexOf方法可以从指定位置开始查找,但是不支持正则。
match
主要功能:和exec类似,从指定字符串中查找子串或者匹配模式,找到返回数组,没找到返回null
match是exec的轻量版,当不使用全局模式匹配时,match和exec返回结果一致;当使用全局模式匹配时,match直接返回一个字符串数组,获得的信息远没有exec多,但是使用方式简单。
实例如下:
var s = 'you love me and I love you'; console.log(s.match(/you/)); // ["you", index: 0, input: "you love me and I love you"] console.log(s.match(/you/g)); // ["you", "you"]
replace
主要功能:用另一个子串替换指定字符串中的某子串(或者匹配模式),返回替换后的新的字符串 str.replace(‘搜索模式’,'替换的内容’) 如果用的是pattern并且带g,则全部替换;否则替换第一处。
实例如下:
var s = 'you love me and I love you'; console.log(s.replace('you', 'zichi')); // zichi love me and I love you console.log(s.replace(/you/, 'zichi')); // zichi love me and I love you console.log(s.replace(/you/g, 'zichi')); // zichi love me and I love zichi
如果需要替代的内容不是指定的字符串,而是跟匹配模式或者原字符串有关,那么就要用到$了(记住这些和$符号有关的东东只和replace有关哦)。

怎么用?看个例子就明白了。
var s = 'I love you'; var pattern = /love/; var ans = s.replace(pattern, '$`' + '$&' + "$'"); console.log(ans); // I I love you you
没错,’$`’ + ‘$&’ + “$’”其实就相当于原串了!
replace的第二个参数还能是函数,看具体例子前先看一段介绍:
注意:第一个参数是匹配到的子串,接下去是子表达式匹配的值,如果要用子表达式参数,则必须要有第一个参数(表示匹配到的串),也就是说,如果要用第n个参数代表的值,则左边参数都必须写出来。最后两个参数跟exec后返回的数组的两个属性差不多。
var s = 'I love you';
var pattern = /love/;
var ans = s.replace(pattern, function(a) { // 只有一个参数,默认为匹配到的串(如还有参数,则按序表示子表达式和其他两个参数)
return a.toUpperCase();
});
console.log(ans); // I LOVE yousplit
主要功能:分割字符串
字符串分割成字符串数组的方法(另有数组变成字符串的join方法)。直接看以下例子:
var s = 'you love me and I love you'; var pattern = 'and'; var ans = s.split(pattern); console.log(ans); // ["you love me ", " I love you"]
如果你嫌得到的数组会过于庞大,也可以自己定义数组大小,加个参数即可:
var s = 'you love me and I love you'; var pattern = /and/; var ans = s.split(pattern, 1); console.log(ans); // ["you love me "]
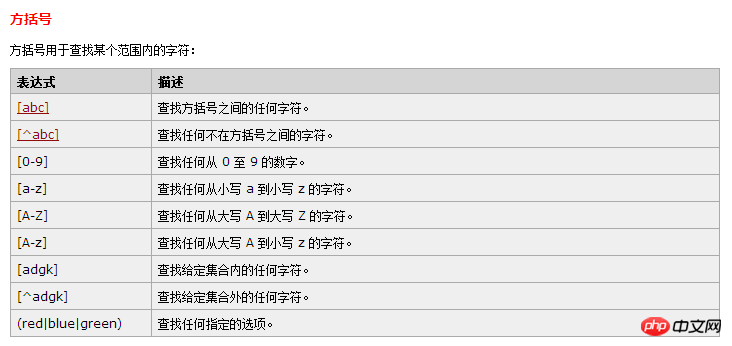
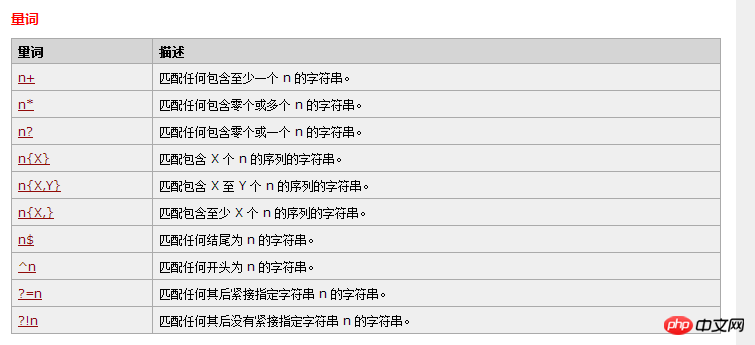
RegExp 字符
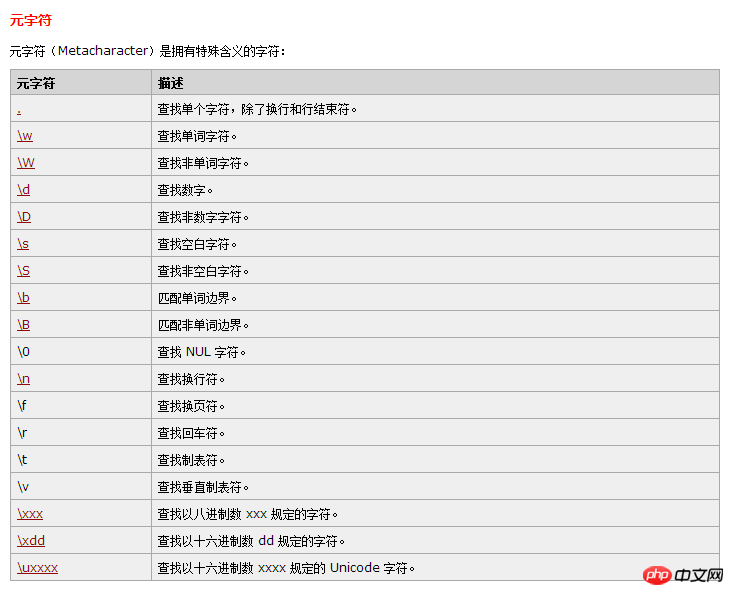
\s 任意空白字符 \S相反 空白字符可以是: 空格符 (space character) 制表符 (tab character) 回车符 (carriage return character) 换行符 (new line character) 垂直换行符 (vertical tab character) 换页符 (form feed character)
\b是正则表达式规定的一个特殊代码,代表着单词的开头或结尾,也就是单词的分界处。虽然通常英文的单词是由空格,标点符号或者换行来分隔的,但是\b并不匹配这些单词分隔字符中的任何一个,它只匹配一个位置。(和^ $ 以及零宽断言类似)
\w 匹配字母或数字或下划线 [a-z0-9A-Z_]完全等同于\w
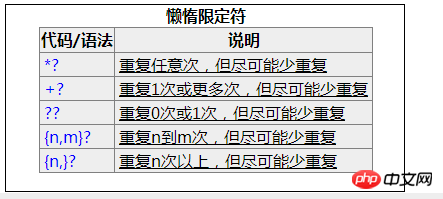
贪婪匹配和懒惰匹配
什么是贪婪匹配?贪婪匹配就是在正则表达式的匹配过程中,默认会使得匹配长度越大越好。
var s = 'hello world welcome to my world'; var pattern = /hello.*world/; var ans = pattern.exec(s); console.log(ans) // ["hello world welcome to my world", index: 0, input: "hello world welcome to my world"]
以上例子不会匹配最前面的Hello World,而是一直贪心的往后匹配。
那么我需要最短的匹配怎么办?很简单,加个‘?’即可,这就是传说中的懒惰匹配,即匹配到了,就不往后找了。
var s = 'hello world welcome to my world'; var pattern = /hello.*?world/; var ans = pattern.exec(s); console.log(ans) // ["hello world", index: 0, input: "hello world welcome to my world"]
懒惰限定符(?)添加的场景如下:
子表达式
表示方式
用一个小括号指定:
var s = 'hello world'; var pattern = /(hello)/; var ans = pattern.exec(s); console.log(ans);
子表达式出现场景
在exec中数组输出子表达式所匹配的值:
var s = 'hello world'; var pattern = /(h(e)llo)/; var ans = pattern.exec(s); console.log(ans); // ["hello", "hello", "e", index: 0, input: "hello world"]
在replace中作为替换值引用:
var s = 'hello world'; var pattern = /(h\w*o)\s*(w\w*d)/; var ans = s.replace(pattern, '$2 $1') console.log(ans); // world hello
后向引用 & 零宽断言
子表达式的序号问题
简单地说:从左向右,以分组的左括号为标志,第一个出现的分组的组号为1,第二个为2,以此类推。
复杂地说:分组0对应整个正则表达式实际上组号分配过程是要从左向右扫描两遍的:第一遍只给未命名组分配,第二遍只给命名组分配--因此所有命名组的组号都大于未命名的组号。可以使用(?:exp)这样的语法来剥夺一个分组对组号分配的参与权.
后向引用
如果我们要找连续两个一样的字符,比如要找两个连续的c,可以这样/c{2}/,如果要找两个连续的单词hello,可以这样/(hello){2}/,但是要在一个字符串中找连续两个相同的任意单词呢,比如一个字符串hellohellochinaworldworld,我要找的是hello和world,怎么找?
这时候就要用后向引用。看具体例子:
var s = 'hellohellochinaworldworld'; var pattern = /(\w+)\1/g; var a = s.match(pattern); console.log(a); // ["hellohello", "worldworld"]
这里的\1就表示和匹配模式中的第一个子表达式(分组)一样的内容,\2表示和第二个子表达式(如果有的话)一样的内容,\3 \4 以此类推。(也可以自己命名,详见参考文献)
或许你觉得数组里两个hello两个world太多了,我只要一个就够了,就又要用到子表达式了。因为match方法里是不能引用子表达式的值的,我们回顾下哪些方法是可以的?没错,exec和replace是可以的!
exec方式:
var s = 'hellohellochinaworldworld';
var pattern = /(\w+)\1/g;
var ans;
do {
ans = pattern.exec(s);
console.log(ans);
} while(ans !== null);
// result
// ["hellohello", "hello", index: 0, input: "hellohellochinaworldworld"] index.html:69
// ["worldworld", "world", index: 15, input: "hellohellochinaworldworld"] index.html:69
// null如果输出只要hello和world,console.log(ans[1])即可。
replace方式:
var s = 'hellohellochinaworldworld';
var pattern = /(\w+)\1/g;
var ans = [];
s.replace(pattern, function(a, b) {
ans.push(b);
});
console.log(ans); // ["hello", "world"]如果要找连续n个相同的串,比如说要找出一个字符串中出现最多的字符:
String.prototype.getMost = function() {
var a = this.split('');
a.sort();
var s = a.join('');
var pattern = /(\w)\1*/g;
var a = s.match(pattern);
a.sort(function(a, b) {
return a.length < b.length;
});
var letter = a[0][0];
var num = a[0].length;
return letter + ': ' + num;
}
var s = 'aaabbbcccaaabbbcccccc';
console.log(s.getMost()); // c: 9如果需要引用某个子表达式(分组),请认准后向引用!
零宽断言
别被名词吓坏了,其实解释很简单。
它们用于查找在某些内容(但并不包括这些内容)之后的东西,也就是说它们像\b,^,$那样用于指定一个位置,这个位置应该满足一定的条件(即断言)
(?=exp)
零宽度正预测先行断言,它断言自身出现的位置的后面能匹配表达式exp。
// 获取字符串中以ing结尾的单词的前半部分 var s = 'I love dancing but he likes singing'; var pattern = /\b\w+(?=ing\b)/g; var ans = s.match(pattern); console.log(ans); // ["danc", "sing"]
(?!exp)
零宽度负预测先行断言,断言此位置的后面不能匹配表达式exp
// 获取第五位不是i的单词的前四位
var s = 'I love dancing but he likes singing';
var pattern = /\b\w{4}(?!i)/g;
var ans = s.match(pattern);
console.log(ans); // ["love", "like"]javascript正则只支持前瞻,不支持后瞻((?<=exp)和(?
关于零宽断言的具体应用可以参考综合应用一节给字符串加千分符。
其他
字符转义
因为某些字符已经被正则表达式用掉了,比如. * ( ) / \ [],所以需要使用它们(作为字符)时,需要用\转义
var s = 'http://www.cnblogs.com/zichi/'; var pattern = /http:\/\/www\.cnblogs\.com\/zichi\//; var ans = pattern.exec(s); console.log(ans); // ["http://www.cnblogs.com/zichi/", index: 0, input: "http://www.cnblogs.com/zichi/"]
分支条件
如果需要匹配abc里的任意字母,可以用[abc],但是如果不是单个字母那么简单,就要用到分支条件。
分支条件很简单,就是用|表示符合其中任意一种规则。
var s = "I don't like you but I love you"; var pattern = /I.*(like|love).*you/g; var ans = s.match(pattern); console.log(ans); // ["I don't like you but I love you"]
答案执行了贪婪匹配,如果需要懒惰匹配,则:
var s = "I don't like you but I love you"; var pattern = /I.*?(like|love).*?you/g; var ans = s.match(pattern); console.log(ans); // ["I don't like you", "I love you"]
综合应用
去除字符串首尾空格(replace)
String.prototype.trim = function() {
return this.replace(/(^\s*)|(\s*$)/g, "");
};
var s = ' hello world ';
var ans = s.trim();
console.log(ans.length); // 12给字符串加千分符(零宽断言)
String.prototype.getAns = function() {
var pattern = /(?=((?!\b)\d{3})+$)/g;
return this.replace(pattern, ',');
}
var s = '123456789';
console.log(s.getAns()); // 123,456,789找出字符串中出现最多的字符(后向引用)
String.prototype.getMost = function() {
var a = this.split('');
a.sort();
var s = a.join('');
var pattern = /(\w)\1*/g;
var a = s.match(pattern);
a.sort(function(a, b) {
return a.length < b.length;
});
var letter = a[0][0];
var num = a[0].length;
return letter + ': ' + num;
}
var s = 'aaabbbcccaaabbbcccccc';
console.log(s.getMost()); // c: 9常用匹配模式(持续更新)
只能输入汉字:/^[\u4e00-\u9fa5]{0,}$/
Zusammenfassung
Test: Überprüfen Sie, ob in der angegebenen Zeichenfolge eine bestimmte Teilzeichenfolge (oder ein passendes Muster) vorhanden ist, und geben Sie „true“ zurück oder false; bei Bedarf kann eine globale Mustersuche durchgeführt werden.
exec: Überprüfen Sie, ob in der angegebenen Zeichenfolge eine bestimmte Teilzeichenfolge (oder ein passendes Muster) vorhanden ist, und geben Sie in diesem Fall ein Array zurück (die Array-Informationen sind umfangreich). (siehe Einleitung oben). Wenn null nicht zurückgegeben wird, kann bei Bedarf eine globale Suche durchgeführt werden, um die Informationen aller Teilzeichenfolgen (oder übereinstimmenden Muster) zu finden Unterausdruck im passenden Muster.
- Kompilieren
: Ändern Sie das Muster im regulären Ausdruck.
- Suchen
: Überprüfen Sie die angegebenen Zeichen Gibt es eine bestimmte Teilzeichenfolge (oder ein passendes Muster) in der Zeichenfolge? Wenn ja, wird die Startposition der Teilzeichenfolge (oder eines passenden Musters) in der Originalzeichenfolge zurückgegeben. Wenn nicht, wird -1 zurückgegeben. Eine globale Suche ist nicht möglich.
- match
: Überprüfen Sie, ob in der angegebenen Zeichenfolge ein bestimmter Teilstring (oder ein passendes Muster) vorhanden ist. Im nicht-globalen Modus stimmen die zurückgegebenen Informationen mit exec überein ; wenn eine globale Suche durchgeführt wird, wird direkt ein String-Array zurückgegeben. (Wenn Sie keine weiteren Informationen zu den einzelnen Übereinstimmungen benötigen, wird empfohlen, match anstelle von exec zu verwenden.)
- replace
: Überprüfen Sie, ob eine bestimmte Teilzeichenfolge vorhanden ist in der angegebenen Zeichenfolge (oder dem passenden Muster) und ersetzen Sie sie durch eine andere Teilzeichenfolge (die Teilzeichenfolge kann sich auf die ursprüngliche Zeichenfolge oder die gesuchte Teilzeichenfolge beziehen). Wenn g aktiviert ist, wird sie global ersetzt, andernfalls wird nur die erste ersetzt ersetzt. Die replace-Methode kann auf den Wert verweisen, der dem Unterausdruck entspricht.
- split
: Teilen Sie die Zeichenfolge mithilfe eines bestimmten Musters und geben Sie ein Zeichenfolgenarray zurück, das genau das Gegenteil der Join-Methode von Array ist.
- Unterausdruck
: ein in Klammern eingeschlossener regulärer Übereinstimmungsausdruck, auf den auch mit exec verwiesen werden kann oder der seinen wahren Übereinstimmungswert ersetzt .
- Rückwärtsreferenz
: Verweisen Sie auf die Gruppe, in der sich der Unterausdruck befindet.
- Behauptung mit Nullbreite
: Ein Positionskonzept ähnlich b ^ und $.
Das obige ist der detaillierte Inhalt vonDetaillierte Erklärung der regulären JavaScript-Ausdrücke, die jeder kennt. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Validierung regulärer PHP-Ausdrücke: Erkennung des Zahlenformats
Mar 21, 2024 am 09:45 AM
Validierung regulärer PHP-Ausdrücke: Erkennung des Zahlenformats
Mar 21, 2024 am 09:45 AM
Überprüfung regulärer PHP-Ausdrücke: Erkennung des Zahlenformats Beim Schreiben von PHP-Programmen ist es häufig erforderlich, die vom Benutzer eingegebenen Daten zu überprüfen. Eine der häufigsten Überprüfungen besteht darin, zu überprüfen, ob die Daten dem angegebenen Zahlenformat entsprechen. In PHP können Sie reguläre Ausdrücke verwenden, um diese Art der Validierung zu erreichen. In diesem Artikel wird erläutert, wie Sie mithilfe regulärer PHP-Ausdrücke Zahlenformate überprüfen und spezifische Codebeispiele bereitstellen. Schauen wir uns zunächst die allgemeinen Validierungsanforderungen für Zahlenformate an: Ganzzahlen: enthalten nur die Zahlen 0–9, können mit einem Plus- oder Minuszeichen beginnen und enthalten keine Dezimalstellen. Gleitkomma
 Wie validiere ich eine E-Mail-Adresse in Golang mithilfe eines regulären Ausdrucks?
May 31, 2024 pm 01:04 PM
Wie validiere ich eine E-Mail-Adresse in Golang mithilfe eines regulären Ausdrucks?
May 31, 2024 pm 01:04 PM
Um E-Mail-Adressen in Golang mithilfe regulärer Ausdrücke zu validieren, führen Sie die folgenden Schritte aus: Verwenden Sie regexp.MustCompile, um ein reguläres Ausdrucksmuster zu erstellen, das gültigen E-Mail-Adressformaten entspricht. Verwenden Sie die MatchString-Funktion, um zu überprüfen, ob eine Zeichenfolge mit einem Muster übereinstimmt. Dieses Muster deckt die meisten gültigen E-Mail-Adressformate ab, einschließlich: Lokale Benutzernamen können Buchstaben, Zahlen und Sonderzeichen enthalten: !.#$%&'*+/=?^_{|}~-`Domänennamen müssen mindestens Eins enthalten Buchstabe, gefolgt von Buchstaben, Zahlen oder Bindestrichen. Die Top-Level-Domain (TLD) darf nicht länger als 63 Zeichen sein.
 Wie kann ich Zeitstempel mithilfe regulärer Ausdrücke in Go abgleichen?
Jun 02, 2024 am 09:00 AM
Wie kann ich Zeitstempel mithilfe regulärer Ausdrücke in Go abgleichen?
Jun 02, 2024 am 09:00 AM
In Go können Sie reguläre Ausdrücke verwenden, um Zeitstempel abzugleichen: Kompilieren Sie eine Zeichenfolge mit regulären Ausdrücken, z. B. die, die zum Abgleich von ISO8601-Zeitstempeln verwendet wird: ^\d{4}-\d{2}-\d{2}T \d{ 2}:\d{2}:\d{2}(\.\d+)?(Z|[+-][0-9]{2}:[0-9]{2})$ . Verwenden Sie die Funktion regexp.MatchString, um zu überprüfen, ob eine Zeichenfolge mit einem regulären Ausdruck übereinstimmt.
 Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
JavaScript-Tutorial: So erhalten Sie HTTP-Statuscode. Es sind spezifische Codebeispiele erforderlich. Vorwort: Bei der Webentwicklung ist häufig die Dateninteraktion mit dem Server erforderlich. Bei der Kommunikation mit dem Server müssen wir häufig den zurückgegebenen HTTP-Statuscode abrufen, um festzustellen, ob der Vorgang erfolgreich ist, und die entsprechende Verarbeitung basierend auf verschiedenen Statuscodes durchführen. In diesem Artikel erfahren Sie, wie Sie mit JavaScript HTTP-Statuscodes abrufen und einige praktische Codebeispiele bereitstellen. Verwenden von XMLHttpRequest
 Reguläre PHP-Ausdrücke: Exakte Übereinstimmung und Ausschluss von Fuzzy-Einschlüssen
Feb 28, 2024 pm 01:03 PM
Reguläre PHP-Ausdrücke: Exakte Übereinstimmung und Ausschluss von Fuzzy-Einschlüssen
Feb 28, 2024 pm 01:03 PM
Reguläre PHP-Ausdrücke: Exakte Übereinstimmung und Ausschluss. Reguläre Fuzzy-Inklusion-Ausdrücke sind ein leistungsstarkes Text-Matching-Tool, das Programmierern bei der effizienten Suche, Ersetzung und Filterung bei der Textverarbeitung helfen kann. In PHP werden reguläre Ausdrücke auch häufig zur Zeichenfolgenverarbeitung und zum Datenabgleich verwendet. Dieser Artikel konzentriert sich auf die Durchführung von exakten Übereinstimmungen und den Ausschluss von Fuzzy-Inklusion-Operationen in PHP und veranschaulicht dies anhand spezifischer Codebeispiele. Exakte Übereinstimmung Exakte Übereinstimmung bedeutet, dass nur Zeichenfolgen abgeglichen werden, die die genaue Bedingung erfüllen, keine Variationen oder zusätzlichen Wörter.
 Wie überprüfe ich das Passwort mithilfe eines regulären Ausdrucks in Go?
Jun 02, 2024 pm 07:31 PM
Wie überprüfe ich das Passwort mithilfe eines regulären Ausdrucks in Go?
Jun 02, 2024 pm 07:31 PM
Die Methode zur Verwendung regulärer Ausdrücke zur Überprüfung von Passwörtern in Go lautet wie folgt: Definieren Sie ein Muster für reguläre Ausdrücke, das die Mindestanforderungen für Passwörter erfüllt: mindestens 8 Zeichen, einschließlich Kleinbuchstaben, Großbuchstaben, Zahlen und Sonderzeichen. Kompilieren Sie reguläre Ausdrucksmuster mit der MustCompile-Funktion aus dem Regexp-Paket. Verwenden Sie die MatchString-Methode, um zu testen, ob die Eingabezeichenfolge mit einem regulären Ausdrucksmuster übereinstimmt.
 So erhalten Sie auf einfache Weise HTTP-Statuscode in JavaScript
Jan 05, 2024 pm 01:37 PM
So erhalten Sie auf einfache Weise HTTP-Statuscode in JavaScript
Jan 05, 2024 pm 01:37 PM
Einführung in die Methode zum Abrufen des HTTP-Statuscodes in JavaScript: Bei der Front-End-Entwicklung müssen wir uns häufig mit der Interaktion mit der Back-End-Schnittstelle befassen, und der HTTP-Statuscode ist ein sehr wichtiger Teil davon. Das Verstehen und Abrufen von HTTP-Statuscodes hilft uns, die von der Schnittstelle zurückgegebenen Daten besser zu verarbeiten. In diesem Artikel wird erläutert, wie Sie mithilfe von JavaScript HTTP-Statuscodes erhalten, und es werden spezifische Codebeispiele bereitgestellt. 1. Was ist ein HTTP-Statuscode? HTTP-Statuscode bedeutet, dass der Dienst den Dienst anfordert, wenn er eine Anfrage an den Server initiiert
 Filterung chinesischer Zeichen: PHP-Praxis für reguläre Ausdrücke
Mar 24, 2024 pm 04:48 PM
Filterung chinesischer Zeichen: PHP-Praxis für reguläre Ausdrücke
Mar 24, 2024 pm 04:48 PM
PHP ist eine weit verbreitete Programmiersprache, die besonders im Bereich der Webentwicklung beliebt ist. Im Prozess der Webentwicklung stoßen wir häufig auf die Notwendigkeit, die vom Benutzer eingegebenen Texte zu filtern und zu überprüfen, wobei die Zeichenfilterung ein sehr wichtiger Vorgang ist. In diesem Artikel wird erläutert, wie reguläre Ausdrücke in PHP zum Implementieren der Filterung chinesischer Zeichen verwendet werden, und es werden spezifische Codebeispiele aufgeführt. Zunächst müssen wir klarstellen, dass der Unicode-Bereich chinesischer Schriftzeichen von u4e00 bis u9fa5 reicht, d. h. alle chinesischen Schriftzeichen liegen in diesem Bereich.
