

Detaillierte Einführung in Unicode- und JavaScript-Codebeispiele ()

Unicode ist ein allgemeiner Zeichenkodierungssatz. Wie unterstützt Unicode also JavaScript? In diesem Artikel wird die Unterstützung der JavaScript-Sprache für den Unicode--Zeichensatz erläutert. Ich hoffe, dass die Leser das Konzept und die Verwendung von Zeichensätzen in JavaScript im Wesentlichen verstehen können.
1. Was ist Unicode?
Unicode entstand aus einer sehr einfachen Idee: Alle Zeichen der Welt in einem Satz zusammenfassen. Solange der Computer diesen Zeichensatz unterstützt, kann er alle Zeichen anzeigen und es treten keine verstümmelten Zeichen mehr auf.
Es beginnt bei 0 und weist jedem Symbol eine Zahl zu, die als „Codepunkt“ bezeichnet wird. Das Symbol für Codepunkt 0 ist beispielsweise null (was bedeutet, dass alle Binärbits 0 sind).
U+0000 = null
In der obigen Formel gibt U+ an, dass die unmittelbar folgende Hexadezimalzahl der Unicode-Codepunkt ist.

Derzeit ist die neueste Version von Unicode Version 7.0, die insgesamt 109.449 Symbole enthält, darunter 74.500 chinesische, japanische und koreanische Zeichen. Schätzungsweise stammen mehr als zwei Drittel der weltweit existierenden Symbole aus ostasiatischen Schriften. Der Codepunkt für „gut“ auf Chinesisch ist beispielsweise 597D im Hexadezimalformat.
U+597D = 好
Bei so vielen Symbolen wird Unicode nicht auf einmal definiert, sondern in Partitionen. Jeder Bereich kann 65536 (216) Zeichen speichern, was als Ebene bezeichnet wird. Derzeit gibt es insgesamt 17 (25) Ebenen, was bedeutet, dass die Größe des gesamten Unicode-Zeichensatzes nun 221 beträgt.
Die ersten 65536 Zeichenbits werden als Basisebene bezeichnet (Abkürzung BMP). Der Codepunktbereich liegt zwischen 0 und 216-1 zu U+FFFF. Alle gebräuchlichen Zeichen werden auf dieser Ebene platziert, die die erste von Unicode definierte und angekündigte Ebene ist.
Die restlichen Zeichen werden in der Hilfsebene (Abkürzung SMP) platziert und die Codepunkte reichen von U+010000 bis U+10FFFF.

2. UTF-32 und UTF-8
Unicode gibt nur den Codepunkt jedes Zeichens an und welche Art von Bytereihenfolge zur Darstellung verwendet wird ? Dieser Codepunkt beinhaltet die Kodierungsmethode.
Die intuitivste Codierungsmethode besteht darin, dass jeder Codepunkt durch vier Bytes dargestellt wird und der Byteinhalt eins zu eins dem Codepunkt entspricht. Diese Kodierungsmethode heißt UTF-32. Beispielsweise wird Codepunkt 0 durch vier Bytes von 0 dargestellt, und Codepunkt 597D werden durch zwei Bytes von 0 vorangestellt.
U+0000 = 0x0000 0000 U+597D = 0x0000 597D

Der Vorteil von UTF-32 besteht darin, dass die Konvertierungsregeln einfach und intuitiv sind und die Sucheffizienz hoch ist. Der Nachteil besteht darin, dass dadurch Platz verschwendet wird. Für denselben englischen Text ist er viermal größer als die ASCII-Kodierung. Dieser Mangel ist so schwerwiegend, dass niemand diese Kodierungsmethode tatsächlich verwendet. Der HTML-5-Standard schreibt eindeutig vor, dass Webseiten nicht in UTF-32 kodiert werden dürfen.

Was die Menschen wirklich brauchten, war eine platzsparende Kodierungsmethode, die zur Geburt von UTF-8 führte. UTF-8 ist eine Codierungsmethode mit variabler Länge, wobei die Zeichenlänge zwischen 1 Byte und 4 Byte liegt. Je häufiger Zeichen verwendet werden, desto kürzer sind die Bytes. Die ersten 128 Zeichen werden durch nur 1 Byte dargestellt, was genau dem ASCII-Code entspricht.
| 编号范围 | 字节 |
| 0×0000 – 0x007F | 1 |
| 0×0080 – 0x07FF | 2 |
| 0×0800 – 0xFFFF | 3 |
| 0×010000 – 0x10FFFF | 4 |
由于UTF-8这种节省空间的特性,导致它成为互联网上最常见的网页编码。不过,它跟今天的主题关系不大,我就不深入了,具体的转码方法,可以参考我多年前写的《字符编码笔记》。
三、UTF-16简介
UTF-16编码介于UTF-32与UTF-8之间,同时结合了定长和变长两种编码方法的特点。
它的编码规则很简单:基本平面的字符占用2个字节,辅助平面的字符占用4个字节。也就是说,UTF-16的编码长度要么是2个字节(U+0000到U+FFFF),要么是4个字节(U+010000到U+10FFFF)。

于是就有一个问题,当我们遇到两个字节,怎么看出它本身是一个字符,还是需要跟其他两个字节放在一起解读?
说来很巧妙,我也不知道是不是故意的设计,在基本平面内,从U+D800到U+DFFF是一个空段,即这些码点不对应任何字符。因此,这个空段可以用来映射辅助平面的字符。
具体来说,辅助平面的字符位共有220个,也就是说,对应这些字符至少需要20个二进制位。UTF-16将这20位拆成两半,前10位映射在U+D800到U+DBFF(空间大小210),称为高位(H),后10位映射在U+DC00到U+DFFF(空间大小210),称为低位(L)。这意味着,一个辅助平面的字符,被拆成两个基本平面的字符表示。

所以,当我们遇到两个字节,发现它的码点在U+D800到U+DBFF之间,就可以断定,紧跟在后面的两个字节的码点,应该在U+DC00到U+DFFF之间,这四个字节必须放在一起解读。
四、UTF-16的转码公式
Unicode码点转成UTF-16的时候,首先区分这是基本平面字符,还是辅助平面字符。如果是前者,直接将码点转为对应的十六进制形式,长度为两字节。
U+597D = 0x597D
如果是辅助平面字符,Unicode 3.0版给出了转码公式。
H = Math.floor((c-0x10000) / 0x400)+0xD800 L = (c - 0x10000) % 0x400 + 0xDC00

以字符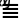 为例,它是一个辅助平面字符,码点为U+1D306,将其转为UTF-16的计算过程如下。
为例,它是一个辅助平面字符,码点为U+1D306,将其转为UTF-16的计算过程如下。
H = Math.floor((0x1D306-0x10000)/0x400)+0xD800 = 0xD834 L = (0x1D306-0x10000) % 0x400+0xDC00 = 0xDF06
所以,字符的UTF-16编码就是0xD834 DF06,长度为四个字节。

五、JavaScript使用哪一种编码?

JavaScript语言采用Unicode字符集,但是只支持一种编码方法。
这种编码既不是UTF-16,也不是UTF-8,更不是UTF-32。上面那些编码方法,JavaScript都不用。
JavaScript用的是UCS-2!

六、UCS-2编码
怎么突然杀出一个UCS-2?这就需要讲一点历史。
互联网还没出现的年代,曾经有两个团队,不约而同想搞统一字符集。一个是1988年成立的Unicode团队,另一个是1989年成立的UCS团队。等到他们发现了对方的存在,很快就达成一致:世界上不需要两套统一字符集。
1991年10月,两个团队决定合并字符集。也就是说,从今以后只发布一套字符集,就是Unicode,并且修订此前发布的字符集,UCS的码点将与Unicode完全一致。

UCS的开发进度快于Unicode,1990年就公布了第一套编码方法UCS-2,使用2个字节表示已经有码点的字符。(那个时候只有一个平面,就是基本平面,所以2个字节就够用了。)UTF-16编码迟至1996年7月才公布,明确宣布是UCS-2的超集,即基本平面字符沿用UCS-2编码,辅助平面字符定义了4个字节的表示方法。
两者的关系简单说,就是UTF-16取代了UCS-2,或者说UCS-2整合进了UTF-16。所以,现在只有UTF-16,没有UCS-2。
七、JavaScript的诞生背景
那么,为什么JavaScript不选择更高级的UTF-16,而用了已经被淘汰的UCS-2呢?
答案很简单:非不想也,是不能也。因为在JavaScript语言出现的时候,还没有UTF-16编码。
1995年5月,Brendan Eich用了10天设计了JavaScript语言;10月,第一个解释引擎问世;次年11月,Netscape正式向ECMA提交语言标准(整个过程详见《JavaScript诞生记》)。对比UTF-16的发布时间(1996年7月),就会明白Netscape公司那时没有其他选择,只有UCS-2一种编码方法可用!

八、JavaScript字符函数的局限
由于JavaScript只能处理UCS-2编码,造成所有字符在这门语言中都是2个字节,如果是4个字节的字符,会当作两个双字节的字符处理。JavaScript的字符函数都受到这一点的影响,无法返回正确结果。

还是以字符为例,它的UTF-16编码是4个字节的0xD834 DF06。问题就来了,4个字节的编码不属于UCS-2,JavaScript不认识,只会把它看作单独的两个字符U+D834和U+DF06。前面说过,这两个码点是空的,所以JavaScript会认为是两个空字符组成的字符串!

上面代码表示,JavaScript认为字符的长度是2,取到的第一个字符是空字符,取到的第一个字符的码点是0xDB34。这些结果都不正确!

解决这个问题,必须对码点做一个判断,然后手动调整。下面是正确的遍历字符串的写法。
while (++index < length) {
// ...
if (charCode >= 0xD800 && charCode <= 0xDBFF) {
output.push(character + string.charAt(++index));
} else {
output.push(character);
}
}上面代码表示,遍历字符串的时候,必须对码点做一个判断,只要落在0xD800到0xDBFF的区间,就要连同后面2个字节一起读取。
类似的问题存在于所有的JavaScript字符操作函数。
String.prototype.replace() String.prototype.substring() String.prototype.slice() ...
上面的函数都只对2字节的码点有效。要正确处理4字节的码点,就必须逐一部署自己的版本,判断一下当前字符的码点范围。
九、ECMAScript 6

JavaScript的下一个版本ECMAScript 6(简称ES6),大幅增强了Unicode支持,基本上解决了这个问题。
(1)正确识别字符
ES6可以自动识别4字节的码点。因此,遍历字符串就简单多了。
for (let s of string ) {
// ...
}但是,为了保持兼容,length属性还是原来的行为方式。为了得到字符串的正确长度,可以用下面的方式。
Array.from(string).length
(2)码点表示法
JavaScript允许直接用码点表示Unicode字符,写法是”反斜杠+u+码点”。
'好' === '\u597D' // true
但是,这种表示法对4字节的码点无效。ES6修正了这个问题,只要将码点放在大括号内,就能正确识别。

(3)字符串处理函数
ES6新增了几个专门处理4字节码点的函数。
String.fromCodePoint():从Unicode码点返回对应字符 String.prototype.codePointAt():从字符返回对应的码点 String.prototype.at():返回字符串给定位置的字符
(4)正则表达式
ES6提供了u修饰符,对正则表达式添加4字节码点的支持。

(5)Unicode正规化
有些字符除了字母以外,还有附加符号。比如,汉语拼音的Ǒ,字母上面的声调就是附加符号。对于许多欧洲语言来说,声调符号是非常重要的。

Unicode提供了两种表示方法。一种是带附加符号的单个字符,即一个码点表示一个字符,比如Ǒ的码点是U+01D1;另一种是将附加符号单独作为一个码点,与主体字符复合显示,即两个码点表示一个字符,比如Ǒ可以写成O(U+004F) + ˇ(U+030C)。
// 方法一 '\u01D1' // 'Ǒ' // 方法二 '\u004F\u030C' // 'Ǒ'
这两种表示方法,视觉和语义都完全一样,理应作为等同情况处理。但是,JavaScript无法辨别。
'\u01D1'==='\u004F\u030C' //false
ES6提供了normalize方法,允许“Unicode正规化”,即将两种方法转为同样的序列。
'\u01D1'.normalize() === '\u004F\u030C'.normalize() // true
Das obige ist der detaillierte Inhalt vonDetaillierte Einführung in Unicode- und JavaScript-Codebeispiele (). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie ein Online-Spracherkennungssystem mit WebSocket und JavaScript
Dec 17, 2023 pm 02:54 PM
So implementieren Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem. Einführung: Mit der kontinuierlichen Weiterentwicklung der Technologie ist die Spracherkennungstechnologie zu einem wichtigen Bestandteil des Bereichs der künstlichen Intelligenz geworden. Das auf WebSocket und JavaScript basierende Online-Spracherkennungssystem zeichnet sich durch geringe Latenz, Echtzeit und plattformübergreifende Eigenschaften aus und hat sich zu einer weit verbreiteten Lösung entwickelt. In diesem Artikel wird erläutert, wie Sie mit WebSocket und JavaScript ein Online-Spracherkennungssystem implementieren.
 WebSocket und JavaScript: Schlüsseltechnologien zur Implementierung von Echtzeitüberwachungssystemen
Dec 17, 2023 pm 05:30 PM
WebSocket und JavaScript: Schlüsseltechnologien zur Implementierung von Echtzeitüberwachungssystemen
Dec 17, 2023 pm 05:30 PM
WebSocket und JavaScript: Schlüsseltechnologien zur Realisierung von Echtzeit-Überwachungssystemen Einführung: Mit der rasanten Entwicklung der Internet-Technologie wurden Echtzeit-Überwachungssysteme in verschiedenen Bereichen weit verbreitet eingesetzt. Eine der Schlüsseltechnologien zur Erzielung einer Echtzeitüberwachung ist die Kombination von WebSocket und JavaScript. In diesem Artikel wird die Anwendung von WebSocket und JavaScript in Echtzeitüberwachungssystemen vorgestellt, Codebeispiele gegeben und deren Implementierungsprinzipien ausführlich erläutert. 1. WebSocket-Technologie
 So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript
Dec 17, 2023 am 09:39 AM
So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript
Dec 17, 2023 am 09:39 AM
So implementieren Sie ein Online-Reservierungssystem mit WebSocket und JavaScript. Im heutigen digitalen Zeitalter müssen immer mehr Unternehmen und Dienste Online-Reservierungsfunktionen bereitstellen. Es ist von entscheidender Bedeutung, ein effizientes Online-Reservierungssystem in Echtzeit zu implementieren. In diesem Artikel wird erläutert, wie Sie mit WebSocket und JavaScript ein Online-Reservierungssystem implementieren, und es werden spezifische Codebeispiele bereitgestellt. 1. Was ist WebSocket? WebSocket ist eine Vollduplex-Methode für eine einzelne TCP-Verbindung.
 Verwendung von JavaScript und WebSocket zur Implementierung eines Echtzeit-Online-Bestellsystems
Dec 17, 2023 pm 12:09 PM
Verwendung von JavaScript und WebSocket zur Implementierung eines Echtzeit-Online-Bestellsystems
Dec 17, 2023 pm 12:09 PM
Einführung in die Verwendung von JavaScript und WebSocket zur Implementierung eines Online-Bestellsystems in Echtzeit: Mit der Popularität des Internets und dem Fortschritt der Technologie haben immer mehr Restaurants damit begonnen, Online-Bestelldienste anzubieten. Um ein Echtzeit-Online-Bestellsystem zu implementieren, können wir JavaScript und WebSocket-Technologie verwenden. WebSocket ist ein Vollduplex-Kommunikationsprotokoll, das auf dem TCP-Protokoll basiert und eine bidirektionale Kommunikation zwischen Client und Server in Echtzeit realisieren kann. Im Echtzeit-Online-Bestellsystem, wenn der Benutzer Gerichte auswählt und eine Bestellung aufgibt
 JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems
Dec 17, 2023 pm 05:13 PM
JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems
Dec 17, 2023 pm 05:13 PM
JavaScript und WebSocket: Aufbau eines effizienten Echtzeit-Wettervorhersagesystems Einführung: Heutzutage ist die Genauigkeit von Wettervorhersagen für das tägliche Leben und die Entscheidungsfindung von großer Bedeutung. Mit der Weiterentwicklung der Technologie können wir genauere und zuverlässigere Wettervorhersagen liefern, indem wir Wetterdaten in Echtzeit erhalten. In diesem Artikel erfahren Sie, wie Sie mit JavaScript und WebSocket-Technologie ein effizientes Echtzeit-Wettervorhersagesystem aufbauen. In diesem Artikel wird der Implementierungsprozess anhand spezifischer Codebeispiele demonstriert. Wir
 Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
Einfaches JavaScript-Tutorial: So erhalten Sie den HTTP-Statuscode
Jan 05, 2024 pm 06:08 PM
JavaScript-Tutorial: So erhalten Sie HTTP-Statuscode. Es sind spezifische Codebeispiele erforderlich. Vorwort: Bei der Webentwicklung ist häufig die Dateninteraktion mit dem Server erforderlich. Bei der Kommunikation mit dem Server müssen wir häufig den zurückgegebenen HTTP-Statuscode abrufen, um festzustellen, ob der Vorgang erfolgreich ist, und die entsprechende Verarbeitung basierend auf verschiedenen Statuscodes durchführen. In diesem Artikel erfahren Sie, wie Sie mit JavaScript HTTP-Statuscodes abrufen und einige praktische Codebeispiele bereitstellen. Verwenden von XMLHttpRequest
 So verwenden Sie insertBefore in Javascript
Nov 24, 2023 am 11:56 AM
So verwenden Sie insertBefore in Javascript
Nov 24, 2023 am 11:56 AM
Verwendung: In JavaScript wird die Methode insertBefore() verwendet, um einen neuen Knoten in den DOM-Baum einzufügen. Diese Methode erfordert zwei Parameter: den neuen Knoten, der eingefügt werden soll, und den Referenzknoten (d. h. den Knoten, an dem der neue Knoten eingefügt wird).
 Vertiefendes Verständnis von PHP: Implementierungsmethode zur Konvertierung von JSON Unicode in Chinesisch
Mar 05, 2024 pm 02:48 PM
Vertiefendes Verständnis von PHP: Implementierungsmethode zur Konvertierung von JSON Unicode in Chinesisch
Mar 05, 2024 pm 02:48 PM
Vertiefendes Verständnis von PHP: Implementierungsmethode zum Konvertieren von JSONUnicode in Chinesisch Während der Entwicklung stoßen wir häufig auf Situationen, in denen wir JSON-Daten verarbeiten müssen, und die Unicode-Codierung in JSON verursacht in einigen Szenarien einige Probleme, insbesondere wenn Unicode konvertiert werden muss Bei der Kodierung wird in chinesische Zeichen konvertiert. In PHP gibt es einige Methoden, die uns bei der Umsetzung dieses Konvertierungsprozesses helfen können. Im Folgenden wird eine allgemeine Methode vorgestellt und es werden spezifische Codebeispiele bereitgestellt. Lassen Sie uns zunächst das Un in JSON verstehen
