

Für Hochleistungsdatenbanken: Optimierung der Bibliothekstabellenstruktur, Indexoptimierung und Abfrageoptimierung müssen Hand in Hand gehen
Abfragen bestehen eigentlich aus einer Reihe von Unteraufgaben. Die Optimierung von Abfragen bedeutet eigentlich: entweder das Eliminieren einiger Unteraufgaben oder das Reduzieren der Anzahl der ausgeführten Unteraufgaben.
1) Unnötige Daten werden abgefragt:
Zum Beispiel fragen wir eine große Anzahl von Ergebnissen über select ab und schließen die Ergebnismenge, nachdem wir die ersten N Zeilen erhalten haben. Tatsächlich fragt MySQL alle Ergebnisse ab . Set, der Client empfängt einen Teil der Daten und verwirft dann die restlichen Daten. Hier liegt eine Abfrageredundanz vor. Wir müssen also nur die vorherigen n Datensätze abfragen und dabei das Schlüsselwort limit verwenden.
2) Alle Spalten zurückgeben, wenn mehrere Tabellen verknüpft sind
Wenn wir Abfragen mit mehreren Tabellen durchführen, stoßen wir häufig auf
mysql>select * from ……>Eine solche Abfrage ist es tatsächlich Beeinträchtigt die Leistung erheblich. Bestimmte Feldnamen sollten anstelle von
Platzhaltern *
und verbieten Sie das Schreiben von Anweisungen wie „select *“.
(1) Antwortzeit
(3) Anzahl der zurückgegebenen Zeilen.
Reaktionszeit Reaktionszeit: einschließlich Servicezeit (echte Abfragezeit) und Warteschlangenzeit (Blockierungswartezeit).
Anzahl der gescannten Zeilen und Anzahl der zurückgegebenen Zeilen Bei der Analyse einer Abfrage ist es sehr hilfreich, die Anzahl der von der Abfrage gescannten Zeilen anzuzeigen, was in gewissem Maße darauf hinweist ob die Abfrage effizient ist oder nicht.
Anzahl der gescannten Zeilen und Zugriffstyp MySQL verfügt über mehrere Zugriffsmethoden, um eine Zeile mit Ergebnissen zu finden und zurückzugeben: vollständiger Tabellenscan, Indexscan, Bereichsscan, eindeutige Indexabfrage, Ständige Referenzen usw.
(1) Eine komplexe Abfrage oder mehrere einfache Abfragen Eine Frage, die wir beim Schreiben von SQL häufig berücksichtigen müssen, ist: Muss eine komplexe Abfrage in mehrere einfache Abfragen unterteilt werden?
(2) Segmentierte Abfrage Die Idee von Teile und herrsche. Manchmal müssen wir eine große Abfrage in Teile aufteilen, sie in Teilen ausführen und eine Verzögerung zwischen den Schritten festlegen, um zu vermeiden, dass viele Daten über einen längeren Zeitraum gesperrt werden.
(3) Zerlegen Sie verwandte Abfragen Viele Hochleistungsanwendungen teilen verwandte Abfragen auf, zum Beispiel:
mysql>select * from tag left join tag_post on tag_post.tag_id=tag.id left join post on tag_post.post_id = post.idwhere tag.tag='mysql';
zerlegt werden
mysql>select * from tag where tag='mysql';mysql>select * from tag_post where tag_id=1234; mysql>select * from post where post.id in (123,345,456,8933);
(1) Machen Sie den
Cache effizienter. (Wenn beispielsweise das oben abgefragte Tag zwischengespeichert wurde, kann die Anwendung die erste Abfrage überspringen.)
Werfen wir zunächst einen Blick auf das schematische Diagramm des Abfrageausführungspfads: 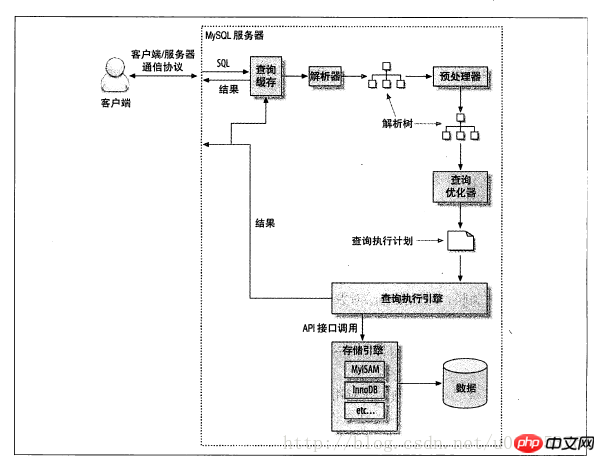
Die Schritte sind wie folgt:
(1) Der Client sendet eine Abfrage an den Server
(2) Der Server überprüft zunächst den Abfragecache und gibt die gespeicherten Ergebnisse sofort zurück im Cache, andernfalls geht es zum nächsten Schritt.
(3) Der Server analysiert und verarbeitet das SQL vor, und dann generiert der Optimierer den entsprechenden Ausführungsplan.
(4) MySQL ruft die API der Speicher-Engine auf, um die Abfrage basierend auf dem vom Optimierer generierten Ausführungsplan auszuführen.
(5) Geben Sie das Ergebnis an den Client zurück.
Wir müssen nicht verstehen, wie das Kommunikationsprotokoll intern implementiert wird, wir müssen nur verstehen, wie die Kommunikation erfolgt Protokoll funktioniert.
Das Client- und Server-Kommunikationsprotokoll von MySQL ist Halbduplex, was bedeutet, dass nur eine Partei gleichzeitig Daten an die andere Partei senden kann.
Wenn der Cache aktiviert ist, prüft MySQL vor dem Parsen einer SQL-Anweisung vorrangig, ob die Abfrage auf die Daten in trifft Abfrage-Cache. Wenn der Cache erreicht wird, wird die Ergebnismenge direkt aus dem Cache abgerufen und an den Client zurückgegeben. Wenn der Cache nicht erreicht wird, gelangt er in die nächste Stufe.
Das Wichtigste in diesem Teil ist der Abfrageoptimierer. Eine Abfrageanweisung kann auf viele Arten ausgeführt werden, und alle werden zurückgegeben Letztendlich besteht die Aufgabe des Optimierers darin, den effizientesten Ausführungsplan zu finden.
Die folgenden Optimierungstypen können vom MySQL-Abfrageoptimierer automatisch verarbeitet werden:
(1) Definieren Sie die Reihenfolge der Zuordnungstabellen neu: Die Zuordnungsreihenfolge der Datentabellen entspricht nicht immer der in der Abfrage angegebenen Reihenfolge. Dies hängt mit dem Optimierer zusammen.(2) Konvertieren Sie äußere Verknüpfungen in innere Verknüpfungen:
(3) Verwenden Sie äquivalente Transformationsregeln: Sie können einige Vergleiche reduzieren oder einige Identitäten entfernen. Beispielsweise wird (5=5 und a>5) in (a > 5) umgeschrieben.
(4) Optimieren Sie die Funktionen COUNT(), MIN() und MAX(): Ob Indizes und Spalten leer sein dürfen, kann dabei helfen, diese Art von Ausdruck zu optimieren: z. B. das Finden des Mindestwerts mithilfe von B -Tree-Strukturmerkmale. Fragen Sie einfach den Datensatz ganz links von B-Tree ab und fertig. Das Gleiche gilt für die Suche nach der Funktion max(). Für die Funktion COUNT(*) verwaltet der MyISAM-Speichertyp jedoch eine -Variable , um speziell die Gesamtzahl der Datensatzzeilen in der Tabelle zu speichern.
(5) Abgedeckter Index-Scan: Wenn die Spalten im Index alle Spalten enthalten, die in der Abfrage verwendet werden müssen, kann MySQL den Index direkt verwenden, um die erforderlichen Daten zurückzugeben, ohne die entsprechenden Datenzeilen abzufragen.
(6) Unterabfrageoptimierung
(8) Abfrage vorzeitig beenden: MySQL kann die Abfrage immer sofort beenden, wenn es feststellt, dass die Abfrageanforderungen erfüllt wurden. Begrenzen Sie beispielsweise das Schlüsselwort.
(9) Vergleich der Liste IN statt OR: MySQL sortiert zuerst die Daten in der IN-Anweisung und ermittelt dann mithilfe der Binärsuche, ob die Daten in der Liste den Anforderungen entsprechen . Dies ist eine O(logn)-Komplexitätsoperation. Bei gleichwertiger Konvertierung in OR ergibt sich eine O(n)-Zeitkomplexität.
Auf jeden Fall ist das Sortieren ein sehr kostspieliger Vorgang, und Sie müssen das Sortieren großer Datenmengen vermeiden. Daher müssen wir Indexspalten zum Sortieren verwenden. Wenn der Index nicht zum Generieren von Sortierergebnissen verwendet werden kann, wird es definitiv eine Situation geben, in der der Tabellen- Abfragedatensatz zu diesem Zeitpunkt zurückgegeben wird ist riesig und es wird eine Dateisortierung verwendet.
Das obige ist der detaillierte Inhalt vonDetails zur Optimierung der MySQL-Abfrageleistung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 MySQL ändert den Namen der Datentabelle
MySQL ändert den Namen der Datentabelle
 MySQL erstellt eine gespeicherte Prozedur
MySQL erstellt eine gespeicherte Prozedur
 Der Unterschied zwischen Mongodb und MySQL
Der Unterschied zwischen Mongodb und MySQL
 So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
So überprüfen Sie, ob das MySQL-Passwort vergessen wurde
 MySQL-Datenbank erstellen
MySQL-Datenbank erstellen
 MySQL-Standard-Transaktionsisolationsstufe
MySQL-Standard-Transaktionsisolationsstufe
 Der Unterschied zwischen SQL Server und MySQL
Der Unterschied zwischen SQL Server und MySQL
 mysqlPasswort vergessen
mysqlPasswort vergessen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



