
 Datenbank
MySQL-Tutorial
Detaillierte Erläuterung des Codes zum Sammeln von Tabelleninformationen während der Überwachung von MySQL (Bilder und Text)
Datenbank
MySQL-Tutorial
Detaillierte Erläuterung des Codes zum Sammeln von Tabelleninformationen während der Überwachung von MySQL (Bilder und Text)
Detaillierte Erläuterung des Codes zum Sammeln von Tabelleninformationen während der Überwachung von MySQL (Bilder und Text)

1. Geschichte
Vielleicht werden Sie oft nach dem monatlichen Datenvolumenwachstum einer bestimmten Tabelle in der Bibliothek im vergangenen Jahr gefragt. Natürlich wäre es einfacher, wenn Sie die Tabellen einzeln nach Monaten aufteilen würden show table status Wenn es nur eine große Tabelle gibt, müssen Sie wahrscheinlich in der einsamen Nacht, in der sich alle ausruhen, SQL-Statistiken ausführen, weil Sie das können Erhalten Sie nur die aktuellen Tabelleninformationen, historische Informationen können nicht zurückverfolgt werden.
Darüber hinaus müssen Sie als DBA auch das Wachstum des Datenbankspeicherplatzes abschätzen, um die Kapazität zu planen. Zu den Tabelleninformationen, über die wir sprechen, gehören hauptsächlich:
Tabellendatengröße (DATA_LENGTH)
Indexgröße (INDEX_LENGTH)
Anzahl der Zeilen (ROWS)
Aktueller Auto-Inkrementwert (AUTO_INCREMENT, falls vorhanden)
Ich habe Ich habe noch nicht gesehen, welcheMySQL solche Indikatoren im Überwachungstool bereitstellt. Diese Informationen müssen nicht zu häufig erfasst werden, und das Ergebnis ist nur eine Schätzung und möglicherweise nicht genau. Daher dient dies der Überwachung (Erfassung) der Tabelle aus einer globalen und langfristigen Perspektive.
Das Sammlungstool, das ich in diesem Artikel vorgestellt habe, basiert auf dem vorhandenen Überwachungssystem in der Gruppe:
InfluxDB: Zeitreihendatenbank, SpeicherüberwachungsdatenGrafana: DatenanzeigefeldTelegraf: Agent, der Informationen sammelt
Schauen Sie sich das neueste MySQL-Plug-in von telegraf an Ich war zunächst sehr zufrieden: Es unterstützt die Sammlung von Tabellenschemastatistiken und automatisch inkrementierenden Infoschemaspalten. Ich habe es ausprobiert und es gibt Daten, aber wie bereits erwähnt, ist alles andere eine Schätzung, die Telegraf-Erfassungshäufigkeit ist zu hoch, was keinen Sinn ergibt. DasIntervalSlowOption ist im Code behoben. Die einzige Möglichkeit besteht darin, die Häufigkeit der globalen Statusüberwachung zu verlangsamen. Es kann jedoch implementiert werden, indem es von anderen Überwachungsindikatoren in zwei Konfigurationsdateien getrennt und jeweils die Erfassungsintervalle definiert wird.
Schließlich habe ich vor, mit Python selbst eines zu erstellen und es an influxdb zu melden:)
2. Konzept
Den vollständigen Code finden Sie unter die GitHub-Projektadresse: DBschema_gather
Die Implementierung ist ebenfalls sehr einfach, fragen Sie einfach die Tabellen information_schema und COLUMNS der TABLES-Bibliothek ab:
SELECT
IFNULL(@@hostname, @@server_id) SERVER_NAME,
%s as HOST,
t.TABLE_SCHEMA,
t.TABLE_NAME,
t.TABLE_ROWS,
t.DATA_LENGTH,
t.INDEX_LENGTH,
t.AUTO_INCREMENT,
c.COLUMN_NAME,
c.DATA_TYPE,
LOCATE('unsigned', c.COLUMN_TYPE) COL_UNSIGNED
# CONCAT(c.DATA_TYPE, IF(LOCATE('unsigned', c.COLUMN_TYPE)=0, '', '_unsigned'))
FROM
information_schema.`TABLES` t
LEFT JOIN information_schema.`COLUMNS` c ON t.TABLE_SCHEMA = c.TABLE_SCHEMA
AND t.TABLE_NAME = c.TABLE_NAME
AND c.EXTRA = 'auto_increment'
WHERE
t.TABLE_SCHEMA NOT IN (
'mysql',
'information_schema',
'performance_schema',
'sys'
)
AND t.TABLE_TYPE = 'BASE TABLE'Überauto_increment achten wir nicht nur darauf, wo das aktuelle Wachstum ist, sondern auch darauf, wie viel freier Speicherplatz im Vergleich zum Maximalwert von int / bigint steht. Daher wurde die Spalte autoIncrUsage berechnet, um das aktuell verwendete Verhältnis zu speichern.
Verwenden Sie dann den Python-Client von InfluxDB, um stapelweise in influxdb zu speichern. Ohne InfluxDB wird das Ergebnis json ausgedruckt – dies ist ein Format, das häufig von Überwachungstools wie Zabbix und Open-Falcon unterstützt wird.
Der letzte Schritt besteht darin, mit Grafana Diagramme aus der Influxdb-Datenquelle zu zeichnen.
3. Verwendung
Umgebung
Geschrieben in der Python 2.7-Umgebung, 2.6 und 3.x wurden nicht getestet.
Für den Betrieb sind MySQLdb und influxdbzwei Bibliotheken erforderlich:
$ sudo pip install mysql-python influxdb
Konfiguration
settings_dbs.pyKonfigurationsdateiDBLIST_INFO: In der Liste werden die zu sammelnden MySQL-Instanztabelleninformationen und die Tupel gespeichert die Verbindungen. Adresse, Port, Benutzername, Passwort
Benutzer benötigen die Berechtigung, die Tabelle auszuwählen, sonst können sie die entsprechenden Informationen nicht sehen.
InfluxDB_INFO: Influxdb-Verbindungsinformationen, bitte erstellen Sie den Datenbanknamen im Vorausmysql_info
und setzen Sie ihn aufNone. Das Ausgabeergebnis kann JSON sein.Erstellen Sie Datenbank- und Speicherstrategie auf influxdb
Speicherung für 2 Jahre, 1 Replikatsatz: (Nach Bedarf anpassen)-
Crontab ausführen
Es kann separat auf dem für die Überwachung verwendeten Server platziert werden, es wird jedoch empfohlen, es auf dem Host auszuführen, auf dem sich die MySQL-Instanz in der Produktionsumgebung befindet aus Sicherheitsgründen. Bei Unterdatenbank und Tabelle kann die globale eindeutige ID nicht in der Tabelle autoIncrUsage berechnet werden
Es ist tatsächlich sehr schwierig zu implementieren. Einfach, das Wichtigste ist, das Bewusstsein für das Sammeln dieser Informationen zu wecken
Sie können das Graphite-Ausgabeformat hinzufügen
CREATE DATABASE "mysql_info" CREATE RETENTION POLICY "mysql_info_schema" ON "mysql_info" DURATION 730d REPLICATION 1 DEFAULT
Sehen Sie sich die großen Informationen an, ähnlich wie: 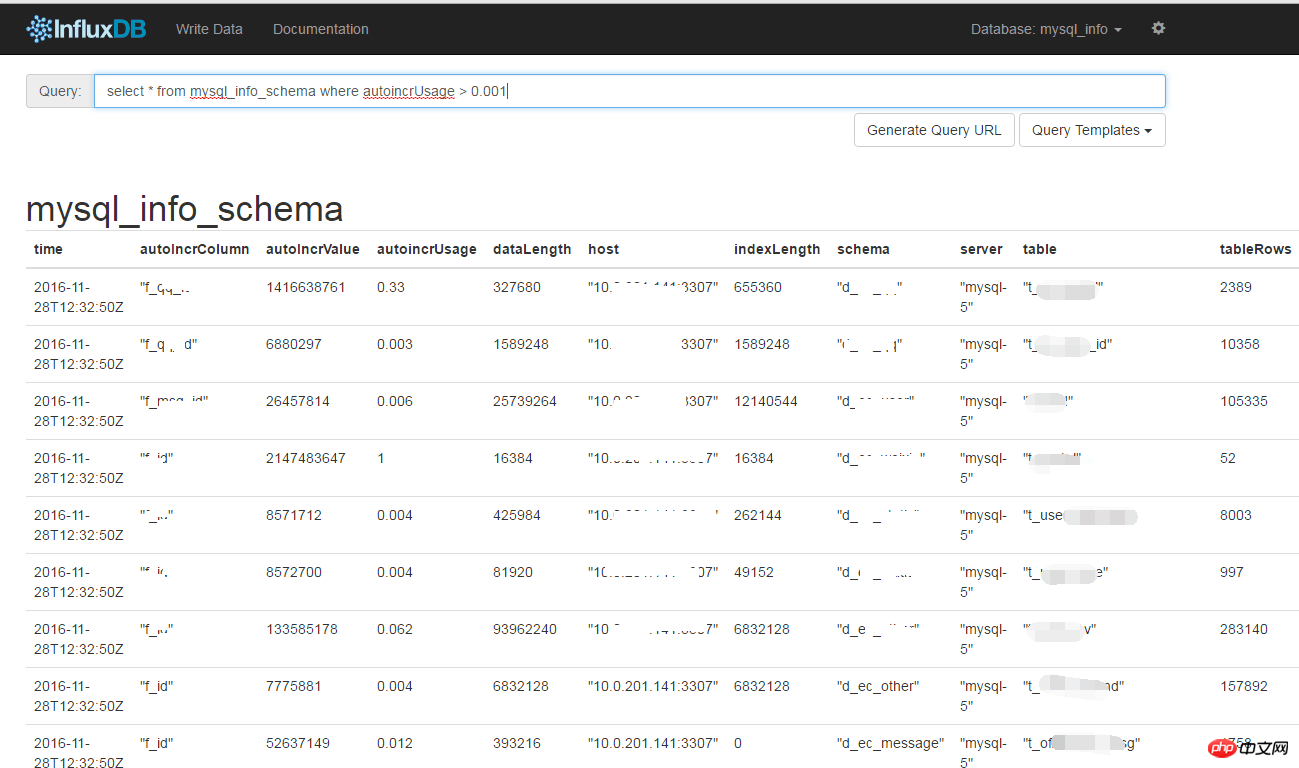
Allgemeine Bibliotheken führen die Datenmigration nachts durch. Sie können mysql_schema_info.py vor und nach der Migration ausführen, um sie zu sammeln. Nicht allzu oft empfohlen.
40 23,5,12,18 * * * /opt/DBschema_info/mysql_schema_info.py >> /tmp/collect_DBschema_info.log 2>&1
Tabellendatengröße und Anzahl der Zeilen
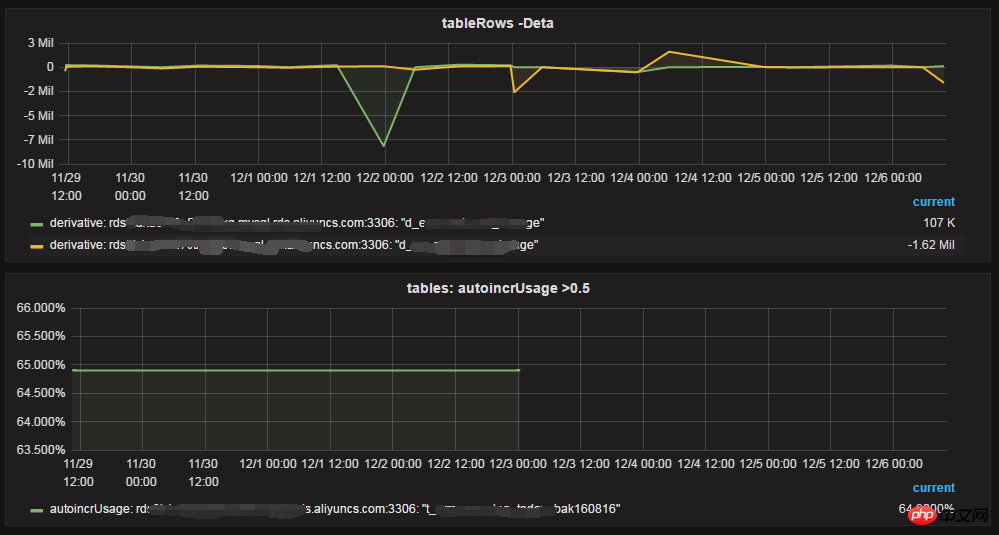
Erhöhung der Anzahl der Zeilen pro Tag, Auto_Inkrement-Nutzung
4. Mehr
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung des Codes zum Sammeln von Tabelleninformationen während der Überwachung von MySQL (Bilder und Text). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
Fähigkeiten zur Verarbeitung von Big-Data-Strukturen: Chunking: Teilen Sie den Datensatz auf und verarbeiten Sie ihn in Blöcken, um den Speicherverbrauch zu reduzieren. Generator: Generieren Sie Datenelemente einzeln, ohne den gesamten Datensatz zu laden, geeignet für unbegrenzte Datensätze. Streaming: Lesen Sie Dateien oder fragen Sie Ergebnisse Zeile für Zeile ab, geeignet für große Dateien oder Remote-Daten. Externer Speicher: Speichern Sie die Daten bei sehr großen Datensätzen in einer Datenbank oder NoSQL.
 Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Die MySQL-Abfrageleistung kann durch die Erstellung von Indizes optimiert werden, die die Suchzeit von linearer Komplexität auf logarithmische Komplexität reduzieren. Verwenden Sie PreparedStatements, um SQL-Injection zu verhindern und die Abfrageleistung zu verbessern. Begrenzen Sie die Abfrageergebnisse und reduzieren Sie die vom Server verarbeitete Datenmenge. Optimieren Sie Join-Abfragen, einschließlich der Verwendung geeigneter Join-Typen, der Erstellung von Indizes und der Berücksichtigung der Verwendung von Unterabfragen. Analysieren Sie Abfragen, um Engpässe zu identifizieren. Verwenden Sie Caching, um die Datenbanklast zu reduzieren. Optimieren Sie den PHP-Code, um den Overhead zu minimieren.
 Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Das Sichern und Wiederherstellen einer MySQL-Datenbank in PHP kann durch Befolgen dieser Schritte erreicht werden: Sichern Sie die Datenbank: Verwenden Sie den Befehl mysqldump, um die Datenbank in eine SQL-Datei zu sichern. Datenbank wiederherstellen: Verwenden Sie den Befehl mysql, um die Datenbank aus SQL-Dateien wiederherzustellen.
 Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich Daten in eine MySQL-Tabelle ein? Mit der Datenbank verbinden: Stellen Sie mit mysqli eine Verbindung zur Datenbank her. Bereiten Sie die SQL-Abfrage vor: Schreiben Sie eine INSERT-Anweisung, um die einzufügenden Spalten und Werte anzugeben. Abfrage ausführen: Verwenden Sie die Methode query(), um die Einfügungsabfrage auszuführen. Bei Erfolg wird eine Bestätigungsmeldung ausgegeben.
 So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
Eine der wichtigsten Änderungen, die in MySQL 8.4 (der neuesten LTS-Version von 2024) eingeführt wurden, besteht darin, dass das Plugin „MySQL Native Password“ nicht mehr standardmäßig aktiviert ist. Darüber hinaus entfernt MySQL 9.0 dieses Plugin vollständig. Diese Änderung betrifft PHP und andere Apps
 Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
So verwenden Sie gespeicherte MySQL-Prozeduren in PHP: Verwenden Sie PDO oder die MySQLi-Erweiterung, um eine Verbindung zu einer MySQL-Datenbank herzustellen. Bereiten Sie die Anweisung zum Aufrufen der gespeicherten Prozedur vor. Führen Sie die gespeicherte Prozedur aus. Verarbeiten Sie die Ergebnismenge (wenn die gespeicherte Prozedur Ergebnisse zurückgibt). Schließen Sie die Datenbankverbindung.
 Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Das Erstellen einer MySQL-Tabelle mit PHP erfordert die folgenden Schritte: Stellen Sie eine Verbindung zur Datenbank her. Erstellen Sie die Datenbank, falls sie nicht vorhanden ist. Wählen Sie eine Datenbank aus. Tabelle erstellen. Führen Sie die Abfrage aus. Schließen Sie die Verbindung.
 Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Oracle-Datenbank und MySQL sind beide Datenbanken, die auf dem relationalen Modell basieren, aber Oracle ist in Bezug auf Kompatibilität, Skalierbarkeit, Datentypen und Sicherheit überlegen, während MySQL auf Geschwindigkeit und Flexibilität setzt und eher für kleine bis mittlere Datensätze geeignet ist. ① Oracle bietet eine breite Palette von Datentypen, ② bietet erweiterte Sicherheitsfunktionen, ③ ist für Anwendungen auf Unternehmensebene geeignet; ① MySQL unterstützt NoSQL-Datentypen, ② verfügt über weniger Sicherheitsmaßnahmen und ③ ist für kleine bis mittlere Anwendungen geeignet.
