
 Java
javaLernprogramm
Eine detaillierte Einführung in die Zusammenfassung und das Denken der gleichzeitigen Java-Programmierung
Java
javaLernprogramm
Eine detaillierte Einführung in die Zusammenfassung und das Denken der gleichzeitigen Java-Programmierung
Eine detaillierte Einführung in die Zusammenfassung und das Denken der gleichzeitigen Java-Programmierung

Guten gleichzeitigen Code zu schreiben ist äußerst schwierig. Die Java-Sprache verfügt seit der ersten Version über eine integrierte Unterstützung für Multithreading, was damals sehr bemerkenswert war. Als wir jedoch ein tieferes Verständnis und mehr Praxis der gleichzeitigen Programmierung hatten, kam die Erkenntnis, dass gleichzeitige Programmierung möglich ist hat mehr Lösungen und bessere Möglichkeiten. Dieser Artikel ist eine Zusammenfassung und Reflexion der gleichzeitigen Programmierung. Außerdem werden einige Erfahrungen zum Schreiben von gleichzeitigem Code in Java 5 und späteren Versionen vermittelt.
Warum Parallelität benötigt wird
Parallelität ist eigentlich eine Entkopplungsstrategie, die uns hilft, zu unterscheiden, was zu tun ist (Ziel) und wann es zu tun ist (Zeitpunkt). Dies kann den Durchsatz der Anwendung (mehr CPU-Planungszeit) und die Struktur (das Programm besteht aus mehreren zusammenarbeitenden Teilen) erheblich verbessern. Jeder, der sich mit der Java-Webentwicklung beschäftigt hat, weiß, dass das Servlet-Programm in Java Web mit Unterstützung des Servlet-Containers einen Einzelinstanz-Multithread-Arbeitsmodus übernimmt.
Missverständnisse und Antworten
Die häufigsten Missverständnisse über gleichzeitige Programmierung sind wie folgt:
-Parallelität verbessert immer die Leistung (Parallelität hinterlässt viel Leerlaufzeit auf dem CPU) kann die Leistung des Programms erheblich verbessern, aber wenn die Anzahl der Threads groß ist, beeinträchtigt ein häufiger Planungswechsel zwischen Threads die Leistung des Systems)
-Das Schreiben gleichzeitiger Programme erfordert keine Änderung des ursprünglichen Designs (Der Zweck ist derselbe, da der Zeitpunkt der Entkopplung oft einen großen Einfluss auf die Systemstruktur hat)
- Machen Sie sich bei der Verwendung von Web- oder EJB-Containern keine Sorgen über Parallelitätsprobleme (nur wenn Sie verstehen, was der Container tut). Sie nutzen den Container besser)
Die folgenden Aussagen sind objektive Erkenntnisse über Parallelität:
-Das Schreiben gleichzeitiger Programme führt zu zusätzlichem Overhead für den Code
-Korrekte Parallelität Es ist sehr komplex, selbst bei sehr einfachen Problemen
-Fehler in der Parallelität sind nicht leicht zu finden, da sie nicht leicht zu reproduzieren sind
-Parallelität erfordert oft grundlegende Änderungen am Design Strategie
Prinzipien und Techniken der gleichzeitigen Programmierung
Prinzip der Einzelverantwortung
Separieren Sie Parallelitätscode und anderen Code (Parallelitätscode hat seinen eigenen). Entwicklungs-, Modifikations- und Tuning-Lebenszyklus).
Datenbereich begrenzen
Zwei Threads können sich gegenseitig stören, wenn sie dasselbe Feld eines gemeinsam genutzten Objekts ändern, was zu unvorhersehbarem Verhalten führt. Eine Lösung besteht darin, einen kritischen Thread zu erstellen Die Anzahl der kritischen Bereiche muss jedoch begrenzt werden.
Datenkopien verwenden
Datenkopien sind eine gute Möglichkeit, die gemeinsame Nutzung von Daten zu vermeiden. Die kopierten Objekte werden nur als schreibgeschützt behandelt. Dem Paket java.util.concurrent von Java 5 wurde eine Klasse mit dem Namen CopyOnWriteArrayList hinzugefügt. Es handelt sich um einen Untertyp der List-Schnittstelle, sodass Sie sie sich als threadsichere Version von ArrayList vorstellen können. Sie verwendet Copy-on-Write Erstellen Sie eine Kopie der Daten, um Probleme durch den gleichzeitigen Zugriff auf gemeinsam genutzte Daten zu vermeiden.
Threads sollten so unabhängig wie möglich sein
Threads in ihrer eigenen Welt existieren lassen und keine Daten mit anderen Threads teilen. Jeder, der Erfahrung in der Java-Webentwicklung hat, weiß, dass Servlet in einer Einzelinstanz und mit mehreren Threads funktioniert. Die mit jeder Anfrage verbundenen Daten werden über die Parameter der Servicemethode (oder doGet- oder doPost-Methode) der Servlet-Unterklasse übergeben. von. Solange der Code im Servlet nur lokale Variablen verwendet, verursacht das Servlet keine Synchronisationsprobleme. Der springMVC-Controller macht dasselbe. Die aus der Anfrage erhaltenen Objekte werden als Methodenparameter und nicht als Mitglieder der Klasse übergeben. Offensichtlich macht Struts 2 genau das Gegenteil, sodass die Action-Klasse als Controller in Struts 2 jeder Anfrage entspricht zu einer Instanz.
Gleichzeitige Programmierung vor Java 5
Das Thread-Modell von Java basiert auf präemptivem Thread-Scheduling, das heißt:
Alle Threads können Einfache gemeinsame Nutzung von Objekten im selben Prozess.
Jeder Thread, der einen Verweis auf diese Objekte hat, kann diese Objekte ändern.
Zum Schutz der Daten können Objekte gesperrt werden.
Die auf Threads und Sperren basierende Parallelität von Java ist zu niedrig, und die Verwendung von Sperren ist oft sehr böse, da sie gleichbedeutend damit ist, die gesamte Parallelität in Warteschlangen umzuwandeln.
Vor Java 5 kann das synchronisierte Schlüsselwort zum Implementieren der Sperrfunktion verwendet werden. Es kann in Codeblöcken und Methoden verwendet werden und gibt an, dass der Thread die entsprechende Sperre erhalten muss, bevor er den gesamten Codeblock oder die gesamte Methode ausführen kann. Für nicht statische Methoden (Mitgliedsmethoden) einer Klasse bedeutet dies, die Sperre der Objektinstanz zu erwerben. Für statische Methoden (Klassenmethoden) der Klasse bedeutet dies, die Sperre des Klassenobjekts der Klasse zu erwerben Blöcke können Programmierer angeben, welche Objektsperre erhalten werden soll.
Unabhängig davon, ob es sich um einen synchronisierten Codeblock oder eine synchronisierte Methode handelt, kann jeweils nur ein Thread eintreten. Wenn andere Threads versuchen, einzutreten (sei es derselbe synchronisierte Block oder ein anderer synchronisierter Block), werden sie von der JVM angehalten (legen Sie sie in Warteschleusen). Diese Struktur wird in der Parallelitätstheorie als kritischer Abschnitt bezeichnet. Hier können wir eine Zusammenfassung der Funktionen der Verwendung von synchronisiert zum Implementieren von Synchronisierung und Sperren in Java erstellen:
Kann nur Objekte sperren, keine grundlegenden Datentypen
-
Ein einzelnes Objekt in einem Array gesperrter Objekte wird nicht gesperrt
Eine synchronisierte Methode kann als synchronisierter (this) { … } Codeblock betrachtet werden, der das Ganze enthält Methode
Die statische Synchronisationsmethode sperrt ihr Klassenobjekt
Die Synchronisation der inneren Klasse ist unabhängig von der äußeren Klasse
Der synchronisierte Modifikator ist nicht Teil der Methodensignatur, daher kann er nicht in der Methodendeklaration der Schnittstelle erscheinen
Asynchrone Methoden kümmern sich nicht um die Sperren status; Die synchronisierte Methode kann weiterhin ausgeführt werden, wenn sie ausgeführt wird
Die von synchronisiert implementierte Sperre ist eine wiedereintrittsfähige Sperre.
Um die Effizienz zu verbessern, verfügt jeder Thread, der gleichzeitig ausgeführt wird, über eine zwischengespeicherte Kopie der Daten, die er verarbeitet. Wenn wir synchronisiert für die Synchronisierung verwenden tatsächlich synchronisiert Es handelt sich um einen Speicherblock, der das gesperrte Objekt in verschiedenen Threads darstellt (die Kopierdaten bleiben mit dem Hauptspeicher synchronisiert. Jetzt wissen Sie, warum das Wort Synchronisierung verwendet wird. Einfach ausgedrückt, nachdem der Synchronisierungsblock oder die Synchronisierungsmethode ausgeführt wurde). Alle am gesperrten Objekt vorgenommenen Änderungen müssen in den Hauptspeicher zurückgeschrieben werden, bevor die Sperre aufgehoben wird. Nach dem Eingeben des Synchronisationsblocks werden die Daten des gesperrten Objekts aus dem Hauptspeicher gelesen und die Daten kopiert Der Thread, der die Sperre hält, muss mit der Datenansicht im Hauptspeicher synchronisiert werden.
In der Originalversion von Java gab es ein Schlüsselwort namens Volatile, bei dem es sich um einen einfachen Synchronisationsverarbeitungsmechanismus handelt, da durch Volatile geänderte Variablen den folgenden Regeln folgen:
Der Wert einer Variablen wird vor der Verwendung immer aus dem Hauptspeicher gelesen.
Änderungen an Variablenwerten werden nach Abschluss immer in den Hauptspeicher zurückgeschrieben.
Die Verwendung des Schlüsselworts volatile kann verhindern, dass der Compiler in einer Multithread-Umgebung falsche Optimierungsannahmen trifft (der Compiler optimiert möglicherweise Variablen, deren Werte sich in einem Thread nicht ändern, in Konstanten). ), aber nur Variablen, deren Änderung nicht vom aktuellen Status (Wert beim Lesen) abhängt, sollten als flüchtig deklariert werden.
Der unveränderliche Modus ist auch ein Design, das bei der gleichzeitigen Programmierung berücksichtigt werden kann. Lassen Sie den Zustand des Objekts unverändert. Wenn Sie den Zustand des Objekts ändern möchten, erstellen Sie eine Kopie des Objekts und schreiben Sie die Änderungen in die Kopie, ohne das ursprüngliche Objekt zu ändern wird kein inkonsistenter Zustand sein, daher sind unveränderliche Objekte threadsicher. Die Klasse String, die wir in Java sehr häufig verwenden, übernimmt dieses Design. Wenn Sie mit unveränderlichen Mustern nicht vertraut sind, können Sie Kapitel 34 von Dr. Yan Hongs Buch „Java and Patterns“ lesen. Vor diesem Hintergrund ist Ihnen möglicherweise auch die Bedeutung des Schlüsselworts final bewusst.
Gleichzeitige Programmierung in Java 5
Egal in welche Richtung Java sich entwickelt oder in Zukunft stirbt, Java 5 ist definitiv eine äußerst wichtige Version in der Geschichte der Java-Entwicklung. Diese Version bietet verschiedene Sprachen Ich werde die Funktionen hier nicht diskutieren (wenn Sie interessiert sind, können Sie meinen anderen Artikel „Das 20. Jahr von Java: Blick auf die Entwicklung der Programmiertechnologie aus der Entwicklung der Java-Versionen“ lesen), aber wir müssen Doug Lea für die Bereitstellung danken In Java 5, dem bahnbrechenden Meisterwerk java.util.concurrent, hat sein Aufkommen der Java-Parallelprogrammierung mehr Auswahlmöglichkeiten und bessere Arbeitsweisen gegeben. Doug Leas Meisterwerk umfasst hauptsächlich den folgenden Inhalt:
Bessere Thread-sichere Container
-
Thread-Pools und verwandte Werkzeugklassen
Optionale nicht blockierende Lösung
Expliziter Sperr- und Semaphormechanismus
Nachfolgend haben wir diese Dinge einzeln erklärt.
Atomic-Klasse
Unter dem Paket java.util.concurrent in Java 5 gibt es ein atomares Unterpaket, das mehrere Klassen enthält, die mit Atomic beginnen, z. B. AtomicInteger und AtomicLong. Sie nutzen die Eigenschaften moderner Prozessoren und können atomare Operationen auf nicht blockierende Weise ausführen. Der Code lautet wie folgt:
/**
ID序列生成器
*/
public class IdGenerator {
private final AtomicLong sequenceNumber = new AtomicLong(0);
public long next() {
return sequenceNumber.getAndIncrement();
}
}Anzeigesperre
Der Sperrmechanismus basiert auf Das synchronisierte Schlüsselwort lautet wie folgt. Problem:
Es gibt nur eine Art von Sperre, die auf alle Synchronisierungsvorgänge den gleichen Effekt hat.
Sperren kann nur in Codeblöcken oder Methoden verwendet werden. Am Anfang erfassen und am Ende freigeben
Der Thread erhält entweder die Sperre oder wird blockiert, es gibt keine andere Möglichkeit
Java 5-Paar Der Sperrmechanismus wurde rekonstruiert und bietet angezeigte Sperren, die den Sperrmechanismus in folgenden Aspekten verbessern können:
可以添加不同类型的锁,例如读取锁和写入锁
可以在一个方法中加锁,在另一个方法中解锁
可以使用tryLock方式尝试获得锁,如果得不到锁可以等待、回退或者干点别的事情,当然也可以在超时之后放弃操作
显示的锁都实现了java.util.concurrent.Lock接口,主要有两个实现类:
ReentrantLock – 比synchronized稍微灵活一些的重入锁
ReentrantReadWriteLock – 在读操作很多写操作很少时性能更好的一种重入锁
对于如何使用显示锁,可以参考我的Java面试系列文章《Java面试题集51-70》中第60题的代码。只有一点需要提醒,解锁的方法unlock的调用最好能够在finally块中,因为这里是释放外部资源最好的地方,当然也是释放锁的最佳位置,因为不管正常异常可能都要释放掉锁来给其他线程以运行的机会。
CountDownLatch
CountDownLatch是一种简单的同步模式,它让一个线程可以等待一个或多个线程完成它们的工作从而避免对临界资源并发访问所引发的各种问题。下面借用别人的一段代码(我对它做了一些重构)来演示CountDownLatch是如何工作的。
import java.util.concurrent.CountDownLatch;
/**
* 工人类
* @author 骆昊
*
*/
class Worker {
private String name; // 名字
private long workDuration; // 工作持续时间
/**
* 构造器
*/
public Worker(String name, long workDuration) {
this.name = name;
this.workDuration = workDuration;
}
/**
* 完成工作
*/
public void doWork() {
System.out.println(name + " begins to work...");
try {
Thread.sleep(workDuration); // 用休眠模拟工作执行的时间
} catch(InterruptedException ex) {
ex.printStackTrace();
}
System.out.println(name + " has finished the job...");
}
}
/**
* 测试线程
* @author 骆昊
*
*/
class WorkerTestThread implements Runnable {
private Worker worker;
private CountDownLatch cdLatch;
public WorkerTestThread(Worker worker, CountDownLatch cdLatch) {
this.worker = worker;
this.cdLatch = cdLatch;
}
@Override
public void run() {
worker.doWork(); // 让工人开始工作
cdLatch.countDown(); // 工作完成后倒计时次数减1
}
}
class CountDownLatchTest {
private static final int MAX_WORK_DURATION = 5000; // 最大工作时间
private static final int MIN_WORK_DURATION = 1000; // 最小工作时间
// 产生随机的工作时间
private static long getRandomWorkDuration(long min, long max) {
return (long) (Math.random() * (max - min) + min);
}
public static void main(String[] args) {
CountDownLatch latch = new CountDownLatch(2); // 创建倒计时闩并指定倒计时次数为2
Worker w1 = new Worker("骆昊", getRandomWorkDuration(MIN_WORK_DURATION, MAX_WORK_DURATION));
Worker w2 = new Worker("王大锤", getRandomWorkDuration(MIN_WORK_DURATION, MAX_WORK_DURATION));
new Thread(new WorkerTestThread(w1, latch)).start();
new Thread(new WorkerTestThread(w2, latch)).start();
try {
latch.await(); // 等待倒计时闩减到0
System.out.println("All jobs have been finished!");
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}ConcurrentHashMap
ConcurrentHashMap是HashMap在并发环境下的版本,大家可能要问,既然已经可以通过Collections.synchronizedMap获得线程安全的映射型容器,为什么还需要ConcurrentHashMap呢?因为通过Collections工具类获得的线程安全的HashMap会在读写数据时对整个容器对象上锁,这样其他使用该容器的线程无论如何也无法再获得该对象的锁,也就意味着要一直等待前一个获得锁的线程离开同步代码块之后才有机会执行。实际上,HashMap是通过哈希函数来确定存放键值对的桶(桶是为了解决哈希冲突而引入的),修改HashMap时并不需要将整个容器锁住,只需要锁住即将修改的“桶”就可以了。HashMap的数据结构如下图所示。
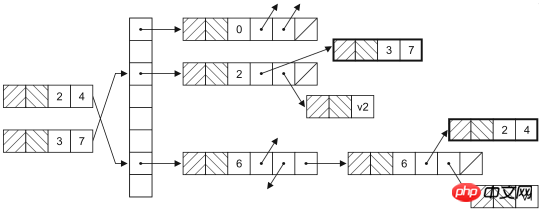
此外,ConcurrentHashMap还提供了原子操作的方法,如下所示:
putIfAbsent:如果还没有对应的键值对映射,就将其添加到HashMap中。
remove:如果键存在而且值与当前状态相等(equals比较结果为true),则用原子方式移除该键值对映射
replace:替换掉映射中元素的原子操作
CopyOnWriteArrayList
CopyOnWriteArrayList是ArrayList在并发环境下的替代品。CopyOnWriteArrayList通过增加写时复制语义来避免并发访问引起的问题,也就是说任何修改操作都会在底层创建一个列表的副本,也就意味着之前已有的迭代器不会碰到意料之外的修改。这种方式对于不要严格读写同步的场景非常有用,因为它提供了更好的性能。记住,要尽量减少锁的使用,因为那势必带来性能的下降(对数据库中数据的并发访问不也是如此吗?如果可以的话就应该放弃悲观锁而使用乐观锁),CopyOnWriteArrayList很明显也是通过牺牲空间获得了时间(在计算机的世界里,时间和空间通常是不可调和的矛盾,可以牺牲空间来提升效率获得时间,当然也可以通过牺牲时间来减少对空间的使用)。
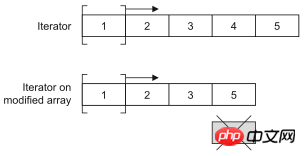
可以通过下面两段代码的运行状况来验证一下CopyOnWriteArrayList是不是线程安全的容器。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
class AddThread implements Runnable {
private List<Double> list;
public AddThread(List<Double> list) {
this.list = list;
}
@Override
public void run() {
for(int i = 0; i < 10000; ++i) {
list.add(Math.random());
}
}
}
public class Test05 {
private static final int THREAD_POOL_SIZE = 2;
public static void main(String[] args) {
List<Double> list = new ArrayList<>();
ExecutorService es = Executors.newFixedThreadPool(THREAD_POOL_SIZE);
es.execute(new AddThread(list));
es.execute(new AddThread(list));
es.shutdown();
}
}上面的代码会在运行时产生ArrayIndexOutOfBoundsException,试一试将上面代码25行的ArrayList换成CopyOnWriteArrayList再重新运行。
List<Double> list = new CopyOnWriteArrayList<>();
Queue
队列是一个无处不在的美妙概念,它提供了一种简单又可靠的方式将资源分发给处理单元(也可以说是将工作单元分配给待处理的资源,这取决于你看待问题的方式)。实现中的并发编程模型很多都依赖队列来实现,因为它可以在线程之间传递工作单元。
Java 5中的BlockingQueue就是一个在并发环境下非常好用的工具,在调用put方法向队列中插入元素时,如果队列已满,它会让插入元素的线程等待队列腾出空间;在调用take方法从队列中取元素时,如果队列为空,取出元素的线程就会阻塞。
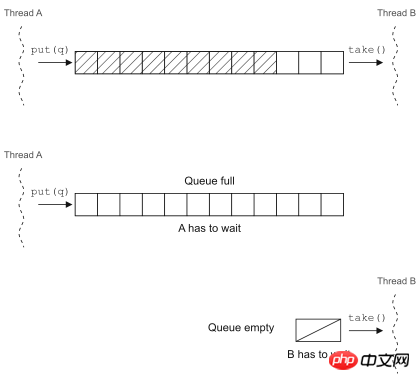
可以用BlockingQueue来实现生产者-消费者并发模型(下一节中有介绍),当然在Java 5以前也可以通过wait和notify来实现线程调度,比较一下两种代码就知道基于已有的并发工具类来重构并发代码到底好在哪里了。
基于wait和notify的实现
import java.util.ArrayList;
import java.util.List;
import java.util.UUID;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
/**
* 公共常量
* @author 骆昊
*
*/
class Constants {
public static final int MAX_BUFFER_SIZE = 10;
public static final int NUM_OF_PRODUCER = 2;
public static final int NUM_OF_CONSUMER = 3;
}
/**
* 工作任务
* @author 骆昊
*
*/
class Task {
private String id; // 任务的编号
public Task() {
id = UUID.randomUUID().toString();
}
@Override
public String toString() {
return "Task[" + id + "]";
}
}
/**
* 消费者
* @author 骆昊
*
*/
class Consumer implements Runnable {
private List<Task> buffer;
public Consumer(List<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
synchronized(buffer) {
while(buffer.isEmpty()) {
try {
buffer.wait();
} catch(InterruptedException e) {
e.printStackTrace();
}
}
Task task = buffer.remove(0);
buffer.notifyAll();
System.out.println("Consumer[" + Thread.currentThread().getName() + "] got " + task);
}
}
}
}
/**
* 生产者
* @author 骆昊
*
*/
class Producer implements Runnable {
private List<Task> buffer;
public Producer(List<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
synchronized (buffer) {
while(buffer.size() >= Constants.MAX_BUFFER_SIZE) {
try {
buffer.wait();
} catch(InterruptedException e) {
e.printStackTrace();
}
}
Task task = new Task();
buffer.add(task);
buffer.notifyAll();
System.out.println("Producer[" + Thread.currentThread().getName() + "] put " + task);
}
}
}
}
public class Test06 {
public static void main(String[] args) {
List<Task> buffer = new ArrayList<>(Constants.MAX_BUFFER_SIZE);
ExecutorService es = Executors.newFixedThreadPool(Constants.NUM_OF_CONSUMER + Constants.NUM_OF_PRODUCER);
for(int i = 1; i <= Constants.NUM_OF_PRODUCER; ++i) {
es.execute(new Producer(buffer));
}
for(int i = 1; i <= Constants.NUM_OF_CONSUMER; ++i) {
es.execute(new Consumer(buffer));
}
}
}基于BlockingQueue的实现
import java.util.UUID;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.LinkedBlockingQueue;
/**
* 公共常量
* @author 骆昊
*
*/
class Constants {
public static final int MAX_BUFFER_SIZE = 10;
public static final int NUM_OF_PRODUCER = 2;
public static final int NUM_OF_CONSUMER = 3;
}
/**
* 工作任务
* @author 骆昊
*
*/
class Task {
private String id; // 任务的编号
public Task() {
id = UUID.randomUUID().toString();
}
@Override
public String toString() {
return "Task[" + id + "]";
}
}
/**
* 消费者
* @author 骆昊
*
*/
class Consumer implements Runnable {
private BlockingQueue<Task> buffer;
public Consumer(BlockingQueue<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
try {
Task task = buffer.take();
System.out.println("Consumer[" + Thread.currentThread().getName() + "] got " + task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
/**
* 生产者
* @author 骆昊
*
*/
class Producer implements Runnable {
private BlockingQueue<Task> buffer;
public Producer(BlockingQueue<Task> buffer) {
this.buffer = buffer;
}
@Override
public void run() {
while(true) {
try {
Task task = new Task();
buffer.put(task);
System.out.println("Producer[" + Thread.currentThread().getName() + "] put " + task);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Test07 {
public static void main(String[] args) {
BlockingQueue<Task> buffer = new LinkedBlockingQueue<>(Constants.MAX_BUFFER_SIZE);
ExecutorService es = Executors.newFixedThreadPool(Constants.NUM_OF_CONSUMER + Constants.NUM_OF_PRODUCER);
for(int i = 1; i <= Constants.NUM_OF_PRODUCER; ++i) {
es.execute(new Producer(buffer));
}
for(int i = 1; i <= Constants.NUM_OF_CONSUMER; ++i) {
es.execute(new Consumer(buffer));
}
}
}使用BlockingQueue后代码优雅了很多。
并发模型
在继续下面的探讨之前,我们还是重温一下几个概念:
| 概念 | 解释 |
|---|---|
| 临界资源 | 并发环境中有着固定数量的资源 |
| 互斥 | 对资源的访问是排他式的 |
| 饥饿 | 一个或一组线程长时间或永远无法取得进展 |
| 死锁 | 两个或多个线程相互等待对方结束 |
| 活锁 | 想要执行的线程总是发现其他的线程正在执行以至于长时间或永远无法执行 |
重温了这几个概念后,我们可以探讨一下下面的几种并发模型。
生产者-消费者
一个或多个生产者创建某些工作并将其置于缓冲区或队列中,一个或多个消费者会从队列中获得这些工作并完成之。这里的缓冲区或队列是临界资源。当缓冲区或队列放满的时候,生产这会被阻塞;而缓冲区或队列为空的时候,消费者会被阻塞。生产者和消费者的调度是通过二者相互交换信号完成的。
读者-写者
当存在一个主要为读者提供信息的共享资源,它偶尔会被写者更新,但是需要考虑系统的吞吐量,又要防止饥饿和陈旧资源得不到更新的问题。在这种并发模型中,如何平衡读者和写者是最困难的,当然这个问题至今还是一个被热议的问题,恐怕必须根据具体的场景来提供合适的解决方案而没有那种放之四海而皆准的方法(不像我在国内的科研文献中看到的那样)。
哲学家进餐
1965年,荷兰计算机科学家图灵奖得主Edsger Wybe Dijkstra提出并解决了一个他称之为哲学家进餐的同步问题。这个问题可以简单地描述如下:五个哲学家围坐在一张圆桌周围,每个哲学家面前都有一盘通心粉。由于通心粉很滑,所以需要两把叉子才能夹住。相邻两个盘子之间放有一把叉子如下图所示。哲学家的生活中有两种交替活动时段:即吃饭和思考。当一个哲学家觉得饿了时,他就试图分两次去取其左边和右边的叉子,每次拿一把,但不分次序。如果成功地得到了两把叉子,就开始吃饭,吃完后放下叉子继续思考。
把上面问题中的哲学家换成线程,把叉子换成竞争的临界资源,上面的问题就是线程竞争资源的问题。如果没有经过精心的设计,系统就会出现死锁、活锁、吞吐量下降等问题。
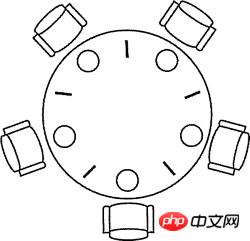
下面是用信号量原语来解决哲学家进餐问题的代码,使用了Java 5并发工具包中的Semaphore类(代码不够漂亮但是已经足以说明问题了)。
//import java.util.concurrent.ExecutorService;
//import java.util.concurrent.Executors;
import java.util.concurrent.Semaphore;
/**
* 存放线程共享信号量的上下问
* @author 骆昊
*
*/
class AppContext {
public static final int NUM_OF_FORKS = 5; // 叉子数量(资源)
public static final int NUM_OF_PHILO = 5; // 哲学家数量(线程)
public static Semaphore[] forks; // 叉子的信号量
public static Semaphore counter; // 哲学家的信号量
static {
forks = new Semaphore[NUM_OF_FORKS];
for (int i = 0, len = forks.length; i < len; ++i) {
forks[i] = new Semaphore(1); // 每个叉子的信号量为1
}
counter = new Semaphore(NUM_OF_PHILO - 1); // 如果有N个哲学家,最多只允许N-1人同时取叉子
}
/**
* 取得叉子
* @param index 第几个哲学家
* @param leftFirst 是否先取得左边的叉子
* @throws InterruptedException
*/
public static void putOnFork(int index, boolean leftFirst) throws InterruptedException {
if(leftFirst) {
forks[index].acquire();
forks[(index + 1) % NUM_OF_PHILO].acquire();
}
else {
forks[(index + 1) % NUM_OF_PHILO].acquire();
forks[index].acquire();
}
}
/**
* 放回叉子
* @param index 第几个哲学家
* @param leftFirst 是否先放回左边的叉子
* @throws InterruptedException
*/
public static void putDownFork(int index, boolean leftFirst) throws InterruptedException {
if(leftFirst) {
forks[index].release();
forks[(index + 1) % NUM_OF_PHILO].release();
}
else {
forks[(index + 1) % NUM_OF_PHILO].release();
forks[index].release();
}
}
}
/**
* 哲学家
* @author 骆昊
*
*/
class Philosopher implements Runnable {
private int index; // 编号
private String name; // 名字
public Philosopher(int index, String name) {
this.index = index;
this.name = name;
}
@Override
public void run() {
while(true) {
try {
AppContext.counter.acquire();
boolean leftFirst = index % 2 == 0;
AppContext.putOnFork(index, leftFirst);
System.out.println(name + "正在吃意大利面(通心粉)..."); // 取到两个叉子就可以进食
AppContext.putDownFork(index, leftFirst);
AppContext.counter.release();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
public class Test04 {
public static void main(String[] args) {
String[] names = { "骆昊", "王大锤", "张三丰", "杨过", "李莫愁" }; // 5位哲学家的名字
// ExecutorService es = Executors.newFixedThreadPool(AppContext.NUM_OF_PHILO); // 创建固定大小的线程池
// for(int i = 0, len = names.length; i < len; ++i) {
// es.execute(new Philosopher(i, names[i])); // 启动线程
// }
// es.shutdown();
for(int i = 0, len = names.length; i < len; ++i) {
new Thread(new Philosopher(i, names[i])).start();
}
}
}现实中的并发问题基本上都是这三种模型或者是这三种模型的变体。
测试并发代码
对并发代码的测试也是非常棘手的事情,棘手到无需说明大家也很清楚的程度,所以这里我们只是探讨一下如何解决这个棘手的问题。我们建议大家编写一些能够发现问题的测试并经常性的在不同的配置和不同的负载下运行这些测试。不要忽略掉任何一次失败的测试,线程代码中的缺陷可能在上万次测试中仅仅出现一次。具体来说有这么几个注意事项:
不要将系统的失效归结于偶发事件,就像拉不出屎的时候不能怪地球没有引力。
先让非并发代码工作起来,不要试图同时找到并发和非并发代码中的缺陷。
编写可以在不同配置环境下运行的线程代码。
编写容易调整的线程代码,这样可以调整线程使性能达到最优。
让线程的数量多于CPU或CPU核心的数量,这样CPU调度切换过程中潜在的问题才会暴露出来。
让并发代码在不同的平台上运行。
通过自动化或者硬编码的方式向并发代码中加入一些辅助测试的代码。
Java 7的并发编程
Java 7中引入了TransferQueue,它比BlockingQueue多了一个叫transfer的方法,如果接收线程处于等待状态,该操作可以马上将任务交给它,否则就会阻塞直至取走该任务的线程出现。可以用TransferQueue代替BlockingQueue,因为它可以获得更好的性能。
刚才忘记了一件事情,Java 5中还引入了Callable接口、Future接口和FutureTask接口,通过他们也可以构建并发应用程序,代码如下所示。
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.Callable;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.Future;
public class Test07 {
private static final int POOL_SIZE = 10;
static class CalcThread implements Callable<Double> {
private List<Double> dataList = new ArrayList<>();
public CalcThread() {
for(int i = 0; i < 10000; ++i) {
dataList.add(Math.random());
}
}
@Override
public Double call() throws Exception {
double total = 0;
for(Double d : dataList) {
total += d;
}
return total / dataList.size();
}
}
public static void main(String[] args) {
List<Future<Double>> fList = new ArrayList<>();
ExecutorService es = Executors.newFixedThreadPool(POOL_SIZE);
for(int i = 0; i < POOL_SIZE; ++i) {
fList.add(es.submit(new CalcThread()));
}
for(Future<Double> f : fList) {
try {
System.out.println(f.get());
} catch (Exception e) {
e.printStackTrace();
}
}
es.shutdown();
}
}Callable接口也是一个单方法接口,显然这是一个回调方法,类似于函数式编程中的回调函数,在Java 8 以前,Java中还不能使用Lambda表达式来简化这种函数式编程。和Runnable接口不同的是Callable接口的回调方法call方法会返回一个对象,这个对象可以用将来时的方式在线程执行结束的时候获得信息。上面代码中的call方法就是将计算出的10000个0到1之间的随机小数的平均值返回,我们通过一个Future接口的对象得到了这个返回值。目前最新的Java版本中,Callable接口和Runnable接口都被打上了@FunctionalInterface的注解,也就是说它可以用函数式编程的方式(Lambda表达式)创建接口对象。
下面是Future接口的主要方法:
get():获取结果。如果结果还没有准备好,get方法会阻塞直到取得结果;当然也可以通过参数设置阻塞超时时间。
cancel():在运算结束前取消。
isDone():可以用来判断运算是否结束。
Java 7中还提供了分支/合并(fork/join)框架,它可以实现线程池中任务的自动调度,并且这种调度对用户来说是透明的。为了达到这种效果,必须按照用户指定的方式对任务进行分解,然后再将分解出的小型任务的执行结果合并成原来任务的执行结果。这显然是运用了分治法(pide-and-conquer)的思想。下面的代码使用了分支/合并框架来计算1到10000的和,当然对于如此简单的任务根本不需要分支/合并框架,因为分支和合并本身也会带来一定的开销,但是这里我们只是探索一下在代码中如何使用分支/合并框架,让我们的代码能够充分利用现代多核CPU的强大运算能力。
import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;
class Calculator extends RecursiveTask<Integer> {
private static final long serialVersionUID = 7333472779649130114L;
private static final int THRESHOLD = 10;
private int start;
private int end;
public Calculator(int start, int end) {
this.start = start;
this.end = end;
}
@Override
public Integer compute() {
int sum = 0;
if ((end - start) < THRESHOLD) { // 当问题分解到可求解程度时直接计算结果
for (int i = start; i <= end; i++) {
sum += i;
}
} else {
int middle = (start + end) >>> 1;
// 将任务一分为二
Calculator left = new Calculator(start, middle);
Calculator right = new Calculator(middle + 1, end);
left.fork();
right.fork();
// 注意:由于此处是递归式的任务分解,也就意味着接下来会二分为四,四分为八...
sum = left.join() + right.join(); // 合并两个子任务的结果
}
return sum;
}
}
public class Test08 {
public static void main(String[] args) throws Exception {
ForkJoinPool forkJoinPool = new ForkJoinPool();
Future<Integer> result = forkJoinPool.submit(new Calculator(1, 10000));
System.out.println(result.get());
}
}伴随着Java 7的到来,Java中默认的数组排序算法已经不再是经典的快速排序(双枢轴快速排序)了,新的排序算法叫TimSort,它是归并排序和插入排序的混合体,TimSort可以通过分支合并框架充分利用现代处理器的多核特性,从而获得更好的性能(更短的排序时间)。
Das obige ist der detaillierte Inhalt vonEine detaillierte Einführung in die Zusammenfassung und das Denken der gleichzeitigen Java-Programmierung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Quadratwurzel in Java
Aug 30, 2024 pm 04:26 PM
Quadratwurzel in Java
Aug 30, 2024 pm 04:26 PM
Leitfaden zur Quadratwurzel in Java. Hier diskutieren wir anhand eines Beispiels und seiner Code-Implementierung, wie Quadratwurzel in Java funktioniert.
 Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur perfekten Zahl in Java. Hier besprechen wir die Definition, Wie prüft man die perfekte Zahl in Java?, Beispiele mit Code-Implementierung.
 Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Leitfaden zum Zufallszahlengenerator in Java. Hier besprechen wir Funktionen in Java anhand von Beispielen und zwei verschiedene Generatoren anhand ihrer Beispiele.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden für Weka in Java. Hier besprechen wir die Einführung, die Verwendung von Weka Java, die Art der Plattform und die Vorteile anhand von Beispielen.
 Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur Smith-Zahl in Java. Hier besprechen wir die Definition: Wie überprüft man die Smith-Nummer in Java? Beispiel mit Code-Implementierung.
 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Anleitung zum TimeStamp to Date in Java. Hier diskutieren wir auch die Einführung und wie man Zeitstempel in Java in ein Datum konvertiert, zusammen mit Beispielen.
