
 Java
javaLernprogramm
Eine ausführliche Einführung in die Verwendung von Java-Protokollen zum Schreiben von Gedichten
Java
javaLernprogramm
Eine ausführliche Einführung in die Verwendung von Java-Protokollen zum Schreiben von Gedichten
Eine ausführliche Einführung in die Verwendung von Java-Protokollen zum Schreiben von Gedichten

Wenn Sie Ihre Arbeit gut machen wollen, müssen Sie zuerst Ihre Werkzeuge schärfen
Viele Programmierer haben möglicherweise vergessen, wie wichtig es ist, das Verhalten der Anwendung bei Parallelitätsfehlern aufzuzeichnen durch hohen Druck in einer Thread-Umgebung verursacht werden, können Sie erkennen, wie wichtig es ist, Protokolle aufzuzeichnen.
Einige Leute haben freudig diesen Satz zum Code hinzugefügt:
log.info("Happy and carefree logging");Er erkennt möglicherweise nicht, dass das Anwendungsprotokoll eine wichtige Rolle bei der Wartung, Optimierung und Fehlererkennung spielt.
Ich denke, slf4j ist die beste Protokollierungs-API, vor allem weil es eine großartige Möglichkeit der Musterinjektion unterstützt:
log.debug("Found {} records matching filter: '{}'", records, filter);log4j Für , Sie können nur Folgendes tun:
log.debug("Found " + records + " recordsmatching filter: '" + filter + "'");Auf diese Weise zu schreiben ist nicht nur ausführlicher und weniger lesbar, sondern auch das String-Spleißen wirkt sich auf die Effizienz aus (wenn auf dieser Ebene keine Ausgabe erforderlich ist).
slf4j führt die {}-Injektionsfunktion ein. Da das Spleißen von Zeichenfolgen jedes Mal vermieden wird, wird die toString-Methode nicht aufgerufen und isDebugEnabled wird nicht mehr benötigt.
slf4j ist eine Anwendung des Erscheinungsmodus, es ist nur eine Fassade. Für die konkrete Umsetzung empfehle ich anstelle des bereits fertigen log4j das bereits einmal angekündigte Logback-Framework. Es verfügt über viele interessante Funktionen und befindet sich im Gegensatz zu log4j noch in der aktiven Entwicklung und Verbesserung.
Ein weiteres zu empfehlendes Tool ist perf4j:
Perf4J ist für System.currentTimeMillis() wie log4j für System.out.println()
So wie log4j ein besserer Ersatz für System.out.println ist, ist perf4j eher ein Ersatz für System.currentTimeMillis().
Ich habe perf4j in einem Projekt eingeführt und seine Leistung unter hoher Last beobachtet. Sowohl Administratoren als auch Geschäftsanwender sind von den wunderschönen Diagrammen, die dieses Gadget bietet, verblüfft.
Wir können Leistungsprobleme jederzeit überprüfen. Es sollte einen eigenen Artikel über perf4j geben. Im Moment können Sie zuerst den Entwicklerleitfaden lesen.
Auch Ceki Gülcü (Ersteller der Projekte log4j, slf4j und logback) bietet uns eine einfache Methode, um die Abhängigkeit von der Commons-Protokollierung zu beseitigen.
Vergessen Sie nicht die Protokollebene
Jedes Mal, wenn Sie eine Protokollzeile hinzufügen möchten, werden Sie sich fragen: Welche Protokollebene sollte hier verwendet werden? Ungefähr 90 % der Programmierer schenken diesem Problem keine große Aufmerksamkeit. Sie alle verwenden eine Ebene zum Aufzeichnen von Protokollen, normalerweise entweder INFO oder DEBUG. Warum?
Das Protokollierungsframework hat zwei große Vorteile gegenüber System.out: Klassifizierung und Ebene. Beide ermöglichen es Ihnen, Protokolle gezielt zu filtern, dauerhaft oder nur bei der Fehlerbehebung.
FEHLER Es ist ein schwerwiegender Fehler aufgetreten, der sofort behoben werden muss. Dieses Fehlerniveau kann von keinem System toleriert werden. Beispiel: Nullzeiger-Ausnahme, die Datenbank ist nicht verfügbar und Anwendungsfälle auf dem kritischen Pfad können nicht weiter ausgeführt werden.
WARN wird weiterhin die folgenden Prozesse ausführen, sollte aber ernst genommen werden. Tatsächlich hoffe ich, dass es hier zwei Ebenen gibt: Eine ist das offensichtliche Problem mit einer Lösung (z. B. „Die aktuellen Daten sind nicht verfügbar, verwenden Sie Cache-Daten“), und die andere sind potenzielle Probleme und Vorschläge (z. B. „Das Programm läuft im Entwicklungsmodus“ oder „Das Passwort für die Verwaltungskonsole ist nicht sicher genug“). Anwendungen können diese Meldungen tolerieren, sie sollten jedoch überprüft und repariert werden.
DEBUG ist für Entwickler ein Anliegen. Ich werde später darüber sprechen, welche Dinge auf dieser Ebene aufgezeichnet werden sollten.
TRACE Detailliertere Informationen werden nur während der Entwicklungsphase verwendet. Möglicherweise müssen Sie diese Informationen noch für einen kurzen Zeitraum nach dem Start des Produkts im Auge behalten, diese Protokollaufzeichnungen sind jedoch nur vorübergehend und sollten irgendwann deaktiviert werden. Der Unterschied zwischen DEBUG und TRACE ist schwer zu erkennen, aber wenn Sie eine Protokollzeile hinzufügen und diese dann nach der Entwicklung und dem Test löschen, sollte das Protokoll die TRACE-Ebene haben.
Die obige Liste ist nur ein Vorschlag. Sie können nach Ihren eigenen Regeln loggen, aber es ist am besten, bestimmte Regeln zu haben. Meine persönliche Erfahrung ist: Filtern Sie Protokolle nicht auf Codeebene, sondern filtern Sie mithilfe der richtigen Protokollebene schnell die gewünschten Informationen heraus, was Ihnen viel Zeit sparen kann.
Das Letzte, worüber ich sprechen möchte, ist die berüchtigte bedingte Anweisung is*Enabled. Manche Leute fügen dies gerne vor jedem Protokoll hinzu:
if(log.isDebugEnabled())
log.debug("Place for your commercial");Persönlich denke ich, dass Sie es vermeiden sollten, dieses chaotische Ding zum Code hinzuzufügen. Es scheint keine Leistungsverbesserung zu geben (insbesondere nach der Verwendung von slf4j), sondern eher eine vorzeitige Optimierung. Ist Ihnen auch nicht klar, dass das etwas überflüssig ist? Selten besteht ein klarer Bedarf für solch explizite Beurteilungsaussagen, es sei denn, wir beweisen, dass die Erstellung der Protokollnachricht selbst zu teuer ist. Andernfalls merken Sie sich einfach, was Sie möchten, und überlassen Sie dies dem Protokollierungsframework.
Wissen Sie, was Sie aufnehmen?
Nehmen Sie sich jedes Mal, wenn Sie eine Protokollzeile schreiben, einen Moment Zeit, um zu sehen, was genau Sie in die Protokolldatei drucken. Lesen Sie Ihre Protokolle durch und suchen Sie nach Anomalien. Vermeiden Sie zunächst zumindest Nullzeigerausnahmen:
log.debug("Processing request with id: {}", request.getId());你确认过request不是null了吗?
记录集合也是一个大坑。如果你用Hibernate从数据库里获取领域对象的集合的时候,不小心写成了这样:
log.debug("Returning users: {}", users);slf4j只会在这条语句确实会打印的时候调用toString方法,当然这个很酷。不过如果内存溢出了,N+1选择问题,线程饿死,延迟初始化异常,日志存储空间用完了…这些都有可能发生。
最好的方式是只记录对象的ID(或者只记录集合的大小)。不过收集ID需要对每个对象调用getId方法,这个在Java里可真不是件简单的事。Groovy有个很棒的展开操作符(users*.id),在Java里我们可以用Commons Beanutils库来模拟下:
log.debug("Returning user ids: {}", collect(users, "id"));collect方法大概是这么实现的:
public static Collection collect(Collection collection, String propertyName) {
return CollectionUtils.collect(collection, new BeanToPropertyValueTransformer(propertyName));
}最后要说的是,toString方法可能没有正确的实现或者使用。
首先,为了记录日志,为每个类创建一个toString的做法比比皆是,最好用 ToStringBuilder来生成(不过不是它的反射实现的那个版本)。
第二,注意数组和非典型的集合。数组和一些另类的集合的toString实现可能没有挨个调用每个元素的toString方法。可以使用JDK提供的Arrays#deepToString方法。经常检查一下你自己打印的日志,看有没有格式异常的一些信息。
避免副作用
日志打印一般对程序的性能没有太大影响。最近我一个朋友在一些特殊的平台上运行的一个系统抛出了Hibernate的LazyInitializationException异常。你可能从这已经猜到了,当会话连接进来的时候,一些日志打印导致延迟初始化的集合被加载。在这种情况下,把日志级别提高了,集合也就不再被初始化了。如果你不知道这些上下文信息,你得花多长时间来发现这个BUG。
另一个副作用就是影响程序的运行速度。快速回答一下这个问题:如果日志打印的过多或者没有正确的使用toString和字符串拼接,日志打印就会对性能产生负面影响。能有多大?好吧,我曾经见过一个程序每15分钟就重启一次,因为太多的日志导致的线程饿死。这就是副作用!从我的经验来看,一小时打印百来兆差不多就是上限了。
当然如果由于日志打印异常导致的业务进程中止,这个副作用就大了。我经常见到有人为了避免这个而这么写:
try {
log.trace("Id=" + request.getUser().getId() + " accesses " + manager.getPage().getUrl().toString())
} catch(NullPointerException e) {}这是段真实的代码,但是为了让世界清净点,请不要这么写。
描述要清晰
每个日志记录都会包含数据和描述。看下这个例子:
log.debug("Message processed");
log.debug(message.getJMSMessageID());
log.debug("Message with id '{}' processed", message.getJMSMessageID());当在一个陌生的系统里排查错误的时候,你更希望看到哪种日志?相信我,上面这些例子都很常见。还有一个反面模式:
if(message instanceof TextMessage)
//...
else
log.warn("Unknown message type");在这个警告日志里加上消息类型,消息ID等等这些难道很困难吗?我是知道发生错误了,不过到底是什么错误?上下文信息是什么?
第三个反面例子是“魔法日志”。一个真实的例子:团队里的很多程序员都知道,3个&号后面跟着!号再跟着一个#号,再跟着一个伪随机数的日志意味着”ID为XYZ的消息收到了”。没人愿意改这个日志,某人敲下键盘,选中某个唯一的”&&&!#”字符串,他就能很快找到想要的信息。
结果是,整个日志文件看起来像一大串随机字符。有人不禁会怀疑这是不是一个perl程序。
日志文件应当是可读性强的,清晰的,自描述的。不要用一些魔数,记录值,数字,ID还有它们的上下文。记录处理的数据以及它的含义。记录程序正在干些什么。好的日志应该是程序代码的一份好的文档。
我有提过不要打印密码还有个人信息吗?相信没有这么傻的程序员。
调整你的格式
日志格式是个很有用的工具,无形中在日志添加了很有价值的上下文信息。不过你应该想清楚,在你的格式中包含什么样的信息。比如说,在每小时循环写入的日志中记录日期是没有意义的,因为你的日志名就已经包含了这个信息。相反的,如果你没记录线程名的话当两个线程并行的工作的时候,你就无法通过日志跟踪线程了——日志已经重叠到一起了。在单线程的应用程序中,这样做没问题,不过那个已经是过去的事儿了。
从我的经验来看,理想的日志格式应当包括(当然除了日志信息本身了):当前时间(无日期,毫秒级精度),日志级别,线程名,简单的日志名称(不用全称)还有消息。在logback里会是这样的:
<appender name="STDOUT" class="ch.qos.logback.core.ConsoleAppender">
<encoder>
<pattern>%d{HH:mm:ss.SSS} %-5level [%thread][%logger{0}] %m%n</pattern>
</encoder>
</appender>文件名,类名,行号,都不用列进来,尽管它们看起来很有用。我还在代码里见过空的日志记录:
log.info(“”);
因为程序员认为行号会作为日志格式的一部分,并且他知道如果空日志消息出现在这个文件的67行的话,意味着这个用户是认证过的。不仅这样,记录类名方法名,或者行号对性能都有很大的影响。
日志框架的一个比较高级的特性是诊断上下文映射(Mapped Diagnostic Context)。MDC只是一个线程本地的一个map。你可以把任何键值对放到这个map里,这样的话这个线程的所有日志记录都能从这个map里取到相应的信息作为输出格式的一部分。
记录方法的参数和返回值
如果你在开发阶段发现了一个BUG,你通常会用调试器来跟踪具体的原因。现在假设不让你用调试器了,比如,因为这个BUG几天前在用户的环境里出现了,你能拿到的只有一些日志。你能从中发现些什么?
如果你遵循打印每个方法的入参和出参这个简单的原则,你根本不需要调试器。当然每个方法可能访问外部系统,阻塞,等待,等等,这些都应该考虑进来。就参考以下这个格式就好:
public String printDocument(Document doc, Mode mode) {
log.debug("Entering printDocument(doc={}, mode={})", doc, mode);
String id = ...; //Lengthy printing operation
log.debug("Leaving printDocument(): {}", id);
return id;
}由于你在方法的开始和结束都记录了日志,所以你可以人工找出效率不高的代码,甚至还可以检测到可能会引起死锁和饥饿的诱因——你只需看一下“Entering”后面是不是没有”Leaving“就明白了。如果你的方法名的含义很清晰,清日志将是一件愉快的事情。同样的,分析异常也更得更简单了,因为你知道每一步都在干些什么。代码里要记录的方法很多的话,可以用AOP切面来完成。这样减少了重复的代码,不过使用它得特别小心,不注意的话可能会导致输出大量的日志。
这种日志最合适的级别就是DEBUG和TRACE了。如果你发现某个方法调用 的太频繁,记录它的日志可能会影响性能的话,只需要调低它的日志级别就可以了,或者把日志直接删了(或者整个方法调用只留一个?)不过日志多了总比少了要强。把日志记录当成单元测试来看,你的代码应该布满了日志就像它的单元测试到处都是一样。系统没有任何一部分是完全不需要日志的。记住,有时候要知道你的系统是不是正常工作,你只能查看不断刷屏的日志。
观察外部系统
这条建议和前面的有些不同:如果你和一个外部系统通信的话,记得记录下你的系统传出和读入的数据。系统集成是一件苦差事,而诊断两个应用间的问题(想像下不同的公司,环境,技术团队)尤其困难。最近我们发现记录完整的消息内容,包括Apache CXF的SOAP和HTTP头,在系统的集成和测试阶段非常有效。
这样做开销很大,如果影响到了性能的话,你只能把日志关了。不过这样你的系统可能跑的很快,挂的也很快,你还无能为力?当和外部系统进行集成的时候,你只能格外小心并做好牺牲一定开销的准备。如果你运气够好,系统集成由ESB处理了,那在总线把请求和响应给记录下来就最好不过了。可以参考下Mule的这个日志组件。
有时候和外部系统交换的数据量决定了你不可能什么都记下来。另一方面,在测试阶段和发布初期,最好把所有东西都记到日志里,做好牺牲性能的准备。可以通过调整日志级别来完成这个。看下下面这个小技巧:
Collection<Integer> requestIds = //...
if(log.isDebugEnabled())
log.debug("Processing ids: {}", requestIds);
else
log.info("Processing ids size: {}", requestIds.size());如果这个logger是配置成DEBUG级别,它会打印完整的请求ID的集合。如果它配置成了打印INFO信息的话,就只会输出集合的大小。你可能会问我是不是忘了isInfoEnabled条件了,看下第二点建议吧。这里还有一个值得注意的是ID的集合不能为null。尽管在DEBUG下,它为NULL也能正常打印,但是当配置成INFO的时候一个大大的空指针。还记得第4点建议中提到的副作用吧?
正确的记录异常
首先,不要记录异常,让框架或者容器来干这个。当然有一个例外:如果你从远程服务中抛出了异常(RMI,EJB等),异常会被序列化,确保它们能返回给客户端 (API中的一部分)。不然的话,客户端会收到NoClassDefFoundError或者别的古怪的异常,而不是真正的错误信息。
异常记录是日志记录的最重要的职责之一,不过很多程序员都倾向于把记录日志当作处理异常的方式。他们通常只是返回默认值(一般是null,0或者空字符串),装作什么也没发生一样。还有的时候,他们会先记录异常,然后把异常包装了下再抛出去:
log.error("IO exception", e);
throw new CustomException(e);这样写通常会把栈信息打印两次,因为捕获了MyCustomException异常的地方也会再打印一次。日志记录,或者包装后再抛出去,不要同时使用,否则你的日志看起来会让人很迷惑。
如果我们真的想记录日志呢?由于某些原因(大概是不读API和文档?),大约有一半的日志记录我认为是错误的。做个小测试,下面哪个日志语句能够正确的打印空指针异常?
try {
Integer x = null;
++x;
} catch (Exception e) {
log.error(e); //A
log.error(e, e); //B
log.error("" + e); //C
log.error(e.toString()); //D
log.error(e.getMessage()); //E
log.error(null, e); //F
log.error("", e); //G
log.error("{}", e); //H
log.error("{}", e.getMessage()); //I
log.error("Error reading configuration file: " + e); //J
log.error("Error reading configuration file: " + e.getMessage()); //K
log.error("Error reading configuration file", e); //L
}很奇怪吧,只有G和L(这个更好)是对的!A和B在slf4j下面根本就编译不过,其它的会把栈跟踪信息给丢掉了或者打印了不正确的信息。比如,E什么也不打印,因为空指针异常本身没有提供任何异常信息而栈信息又没打印出来 .记住,第一个参数通常都是文本信息,关于这个错误本身的。不要把异常信息给写进来,打印日志后它会自动出来的,在栈信息的前面。不过想要打印这个,你当然还得把异常传到第二个参数里面才行。
日志应当可读性强且易于解析
现在有两组用户对你的日志感兴趣:我们人类(不管你同不同意,码农也是在这里边),还有计算机(通常就是系统管理员写的shell脚本)。日志应当适合这两种用户来理解。如果有人在你后边看你的程序的日志却看到了这个:
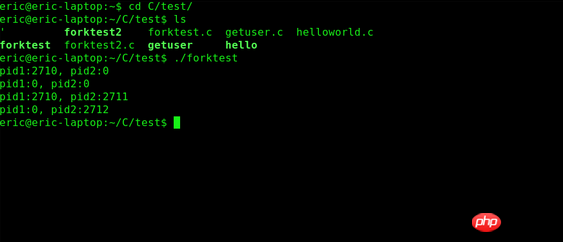
那你肯定没听从我的建议。日志应该像代码一样易于阅读和理解。
另一方面,如果你的程序每小时就生成了半GB的日志,没有谁或者任何图形化的文本编辑器能把它们看完。这时候我们的老家伙们,grep,sed和awk这些上场的时候就来了。如果有可能的话,你记录的日志最好能让人和计算机都能看明白 ,不要将数字格式化,用一些能让正则容易匹配的格式等等。如果不可能的,用两个格式来打印数据:
log.debug("Request TTL set to: {} ({})", new Date(ttl), ttl);
// Request TTL set to: Wed Apr 28 20:14:12 CEST 2010 (1272478452437)
final String duration = DurationFormatUtils.formatDurationWords(durationMillis, true, true);
log.info("Importing took: {}ms ({})", durationMillis, duration);
//Importing took: 123456789ms (1 day 10 hours 17 minutes 36 seconds)计算机看到”ms after 1970 epoch“这样的的时间格式会感谢你的,而人们则乐于看到”1天10小时17分36秒“这样的东西。
总之,日志也可以写得像诗一样优雅,如果你愿意琢磨的话。
Das obige ist der detaillierte Inhalt vonEine ausführliche Einführung in die Verwendung von Java-Protokollen zum Schreiben von Gedichten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1376
1376
 52
52

 Quadratwurzel in Java
Aug 30, 2024 pm 04:26 PM
Quadratwurzel in Java
Aug 30, 2024 pm 04:26 PM
Leitfaden zur Quadratwurzel in Java. Hier diskutieren wir anhand eines Beispiels und seiner Code-Implementierung, wie Quadratwurzel in Java funktioniert.
 Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur perfekten Zahl in Java. Hier besprechen wir die Definition, Wie prüft man die perfekte Zahl in Java?, Beispiele mit Code-Implementierung.
 Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Leitfaden zum Zufallszahlengenerator in Java. Hier besprechen wir Funktionen in Java anhand von Beispielen und zwei verschiedene Generatoren anhand ihrer Beispiele.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden für Weka in Java. Hier besprechen wir die Einführung, die Verwendung von Weka Java, die Art der Plattform und die Vorteile anhand von Beispielen.
 Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur Smith-Zahl in Java. Hier besprechen wir die Definition: Wie überprüft man die Smith-Nummer in Java? Beispiel mit Code-Implementierung.
 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Anleitung zum TimeStamp to Date in Java. Hier diskutieren wir auch die Einführung und wie man Zeitstempel in Java in ein Datum konvertiert, zusammen mit Beispielen.
