

Detaillierte Erläuterung der MySQL-Indizes

Der Index von MySQL erfolgt über B+tree. B+tree ist eine Variante des ausgeglichenen Binärbaums, daher ist die Abfragegeschwindigkeit sehr hoch.
Indizes werden hauptsächlich in Clustered-Indizes und Hilfsindizes unterteilt:
Clustered-Index: Die Daten in MySQL werden über den Clustered-Index des Primärschlüssels gespeichert Im Blattknoten werden die Daten jeder Zeile gespeichert, daher fragen wir über den Primärschlüssel ab
Der Grund, warum es so schnell ist wie zuvor, liegt darin, dass der Primärschlüssel ein Clustered-Index ist und in der tatsächlichen Verwendung nur einer vorhanden ist Ein solcher B+-Baum wird erstellt, was erklären kann, warum der Primärschlüssel der Einzige ist.
Zitat aus dem Bild im Internet:
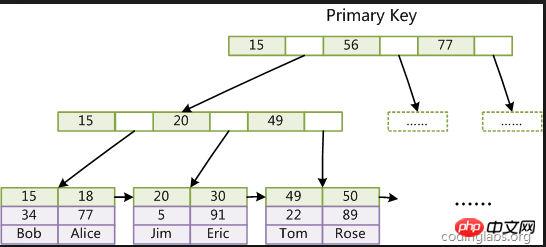
Die Suche auf jeder Ebene ist eine E/A-Operation, und im Allgemeinen beträgt die Anzahl der B + Baumschichten 2 -4. Im schlimmsten Fall sind also nur 4 IO-Operationen erforderlich.
Hilfsindex : Der Unterschied zwischen Hilfsindex und Clustered-Index besteht darin, dass nicht alle Daten in Blattknoten gespeichert werden, sondern der Speicherort der Daten. Dies entspricht der Verwendung des Hilfsindex
zum Suchen der Daten. Anschließend müssen wir detaillierte Informationen über den Baum des Clustered-Index finden.
Zitat aus dem Diagramm im Internet:
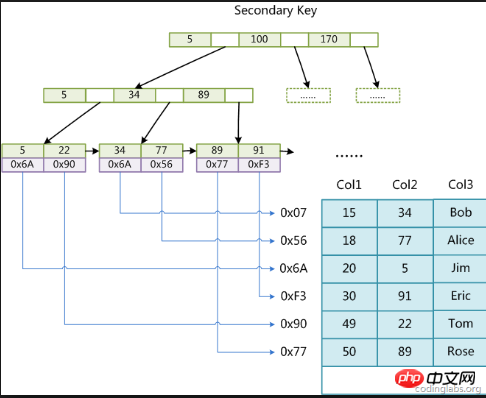
Dieses Diagramm ist ein logisches Diagramm, aber die unterste Ebene zeigt über die Blattknoten auf den Clustered-Index. Das heißt, als nächstes müssen Sie die
-Logik des ersten Diagrammtyps durchgehen.
Das Endergebnis ist also, dass mehrere Hilfsindexbäume auf einen Clustered-Indexbaum verweisen
(Die Zeichnung ist wirklich hässlich)
Über den Zeitpunkt der Erstellung eines Index
Da es sich um einen Baum handelt, wird er durch eine binäre Suche abgerufen, sodass er als Bedingung hinter wo und diesem The anwendbar ist Die Werte liegen in einem weiten Bereich und eignen sich für die Indexerstellung. Es ist nicht für Personen mit einem kleinen Bereich geeignet (is_delete, sex usw. Aufzählungen).
Für bestimmte Situationen können wir nach Showindex analysieren:
show index from company_related_person
Ergebnis:

Dann nach Kardinalität berechnen
select 105/(select count(*) from company_related_person) from DUAL
Das hier erhaltene Ergebnis ist 0,913 (dieser Wert hängt von der Speicherkapazität ab, es ist am besten, eine bestimmte Datenmenge zu haben, je näher dieser Wert an 1 liegt, desto höher ist die Indexeffizienz). Wenn der berechnete Wert sehr klein ist, wird empfohlen, keinen Index zu erstellen
Wir können die Verwendung des Index auch über „explain“ anzeigen
EXPLAIN select * from company_related_person where company_id='2'
Ausgabe

Schlüssel dargestellt Ist die aktuell verwendete Indexspalte. Das letzte Extra stellt die verwendete Methode dar. Die Verwendung eines Index stellt die Verwendung eines Index dar.
Für komplexe SQL-Anweisungen mit langsamen Abfragen können Sie diese Methoden zur Analyse verwenden .
Das Ziel der SQL-Leistungsoptimierung: mindestens die Bereichsebene erreichen, die Anforderung ist die Ref-Ebene, wenn es Konstanten sein kann, ist es am besten.
1) Konstanten In einer einzelnen Tabelle gibt es höchstens eine passende Zeile (Primärschlüssel oder eindeutiger Index) und die Daten können während der Optimierungsphase gelesen werden.
2) Ref bezieht sich auf die Verwendung eines normalen Index.
3) „Range“ führt einen Bereichsabruf für den Index durch
4) „Index“ bedeutet, direkt von der Festplatte zu lesen
Aus der obigen Abbildung können wir auch ersehen, dass wir die Referenz verwenden
Über den Unterschied zwischen Index und Schlüssel:
Wenn wir einen Index erstellen, haben wir oft die Frage: Was ist der Unterschied zwischen Index und Schlüssel? . Schlüssel ist ein Schlüsselwert, der Teil der relationalen Modelltheorie ist, z. B. Primärschlüssel (Primärschlüssel), Fremdschlüssel (Fremdschlüssel) usw., der zur Überprüfung der Datenintegrität und zur Eindeutigkeitsbeschränkung verwendet wird. Der Index befindet sich auf der Implementierungsebene. Sie können beispielsweise jede Spalte einer Tabelle indizieren. Wenn sich die indizierte Spalte dann in der SQL-Anweisung in der Where-Bedingung befindet, können Sie eine schnelle Datenlokalisierung und damit einen schnellen Abruf erhalten. Beim Unique Index handelt es sich lediglich um einen Indextyp. Die Einrichtung des Unique Index bedeutet, dass die Daten in dieser Spalte nicht wiederholt werden können
Das obige ist der detaillierte Inhalt vonDetaillierte Erläuterung der MySQL-Indizes. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
Die Beziehung zwischen MySQL -Benutzer und Datenbank
Apr 08, 2025 pm 07:15 PM
In der MySQL -Datenbank wird die Beziehung zwischen dem Benutzer und der Datenbank durch Berechtigungen und Tabellen definiert. Der Benutzer verfügt über einen Benutzernamen und ein Passwort, um auf die Datenbank zuzugreifen. Die Berechtigungen werden über den Zuschussbefehl erteilt, während die Tabelle durch den Befehl create table erstellt wird. Um eine Beziehung zwischen einem Benutzer und einer Datenbank herzustellen, müssen Sie eine Datenbank erstellen, einen Benutzer erstellen und dann Berechtigungen erfüllen.
 RDS MySQL -Integration mit RedShift Zero ETL
Apr 08, 2025 pm 07:06 PM
RDS MySQL -Integration mit RedShift Zero ETL
Apr 08, 2025 pm 07:06 PM
Vereinfachung der Datenintegration: AmazonRDSMYSQL und Redshifts Null ETL-Integration Die effiziente Datenintegration steht im Mittelpunkt einer datengesteuerten Organisation. Herkömmliche ETL-Prozesse (Extrakt, Konvertierung, Last) sind komplex und zeitaufwändig, insbesondere bei der Integration von Datenbanken (wie AmazonRDSMysQL) in Data Warehouses (wie Rotverschiebung). AWS bietet jedoch keine ETL-Integrationslösungen, die diese Situation vollständig verändert haben und eine vereinfachte Lösung für die Datenmigration von RDSMysQL zu Rotverschiebung bietet. Dieser Artikel wird in die Integration von RDSMYSQL Null ETL mit RedShift eintauchen und erklärt, wie es funktioniert und welche Vorteile es Dateningenieuren und Entwicklern bringt.
 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 So füllen Sie MySQL Benutzername und Passwort aus
Apr 08, 2025 pm 07:09 PM
So füllen Sie MySQL Benutzername und Passwort aus
Apr 08, 2025 pm 07:09 PM
Ausfüllen des MySQL -Benutzernamens und des Kennworts: 1. Bestimmen Sie den Benutzernamen und das Passwort; 2. Verbinden Sie eine Verbindung zur Datenbank; 3. Verwenden Sie den Benutzernamen und das Passwort, um Abfragen und Befehle auszuführen.
 Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
Die Abfrageoptimierung in MySQL ist für die Verbesserung der Datenbankleistung von wesentlicher Bedeutung, insbesondere im Umgang mit großen Datensätzen
Apr 08, 2025 pm 07:12 PM
1. Verwenden Sie den richtigen Index, um das Abrufen von Daten zu beschleunigen, indem die Menge der skanierten Datenmenge ausgewählt wird. Wenn Sie mehrmals eine Spalte einer Tabelle nachschlagen, erstellen Sie einen Index für diese Spalte. Wenn Sie oder Ihre App Daten aus mehreren Spalten gemäß den Kriterien benötigen, erstellen Sie einen zusammengesetzten Index 2. Vermeiden Sie aus. Auswählen * Nur die erforderlichen Spalten. Wenn Sie alle unerwünschten Spalten auswählen, konsumiert dies nur mehr Serverspeicher und veranlasst den Server bei hoher Last oder Frequenzzeiten, beispielsweise die Auswahl Ihrer Tabelle, wie beispielsweise die Spalten wie innovata und updated_at und Zeitsteuer und dann zu entfernen.
 Wie kopieren und fügen Sie MySQL ein und fügen Sie sie ein
Apr 08, 2025 pm 07:18 PM
Wie kopieren und fügen Sie MySQL ein und fügen Sie sie ein
Apr 08, 2025 pm 07:18 PM
Kopieren und einfügen in MySQL die folgenden Schritte: Wählen Sie die Daten aus, kopieren Sie mit Strg C (Windows) oder CMD C (MAC). Klicken Sie mit der rechten Maustaste auf den Zielort, wählen Sie ein Einfügen oder verwenden Sie Strg V (Windows) oder CMD V (MAC). Die kopierten Daten werden in den Zielort eingefügt oder ersetzen vorhandene Daten (je nachdem, ob die Daten bereits am Zielort vorhanden sind).
 Wie man MySQL sieht
Apr 08, 2025 pm 07:21 PM
Wie man MySQL sieht
Apr 08, 2025 pm 07:21 PM
Zeigen Sie die MySQL -Datenbank mit dem folgenden Befehl an: Verbindung zum Server: MySQL -U -Benutzername -P -Kennwort ausführen STEILE -Datenbanken; Befehl zum Abrufen aller vorhandenen Datenbanken auswählen Datenbank: Verwenden Sie den Datenbanknamen. Tabelle Ansicht: Tabellen anzeigen; Tabellenstruktur anzeigen: Beschreiben Sie den Tabellennamen; Daten anzeigen: Wählen Sie * aus Tabellenname;
