
 Backend-Entwicklung
C#.Net-Tutorial
Ausführliche Erläuterung der Thread-Synchronisation im C#-Multithreading (Bild und Text)
Backend-Entwicklung
C#.Net-Tutorial
Ausführliche Erläuterung der Thread-Synchronisation im C#-Multithreading (Bild und Text)
Ausführliche Erläuterung der Thread-Synchronisation im C#-Multithreading (Bild und Text)

In diesem Artikel werden hauptsächlich die relevanten Kenntnisse der C#-Thread-Synchronisation vorgestellt. Es hat einen sehr guten Referenzwert. Schauen wir es uns mit dem Editor unten an.
Der Multithreading-Inhalt ist grob in zwei Teile unterteilt, die über einen dedizierten Thread-Pool erfolgen können. Task, Parallel, PLINQ usw. Dies betrifft Worker-Threads und IO-Threads; das zweite ist das Problem der Thread-Synchronisierung. Was ich jetzt studiere und erforsche, ist das Problem der Thread-Synchronisierung.
Durch das Studium des Inhalts in „CLR über C#“ habe ich eine klarere Architektur für die Thread-Synchronisation entwickelt. Die Thread-Synchronisationsstruktur ist in zwei Kategorien unterteilt Das eine ist eine primitive Struktur und das andere ist eine Hybridstruktur. Die sogenannten Primitive sind die einfachsten Konstrukte, die im Code verwendet werden. Die Grundstruktur ist in zwei Kategorien unterteilt, eine ist der Benutzermodus und die andere ist der Kernelmodus. Das Hybridkonstrukt verwendet intern den Benutzermodus und den Kernelmodus. Es gibt bestimmte Strategien für die Verwendung seines Modus, da der Benutzermodus und der Kernelmodus ihre eigenen Vor- und Nachteile haben und das Hybridkonstrukt die Vor- und Nachteile der beiden ausgleichen soll Zweitens: Entwickelt, um Nachteile zu vermeiden. Im Folgenden wird die gesamte Thread-Synchronisationsarchitektur aufgeführt
Grundelemente
1.1 Benutzermodus
1.1.1 flüchtig
1.1.2 Interlock
1.2 Kernel-Modus
1.2.1 WaitHandle
1.2.2 ManualResetEvent und AutoResetEvent
1.2.3 Semaphor
1.2.4 Mutex
Gemischt
2.1 Verschiedene Slim
2.2 Monitor
2.3 MethodImplAttribute und SynchronizationAttribute
2.4 ReaderWriterLock
2.5 Barier (selten verwendet)
2.6 CoutdownEvent (selten verwendet)
Beginnen wir mit der Ursache von Thread-Synchronisationsproblemen Variable A, der darin gespeicherte Wert ist 2. Wenn Thread 1 ausgeführt wird, nimmt er den Wert von A aus dem Speicher, speichert ihn im CPU-Register und weist den Wert von A 3 zu. Zu diesem Zeitpunkt , der Wert von Thread 1 ist zufällig Die Zeitscheibe endet, dann weist die CPU die Zeitscheibe Thread 2 zu. Thread 2 entnimmt jedoch auch den Wert von A aus dem Speicher und legt ihn in den Speicher ab Wenn der neue Wert 3 der Variablen A nicht zurück in den Speicher gelegt wird, liest Thread 2 2 immer noch den alten Wert (d. h. schmutzige Daten) 2, und wenn Thread 2 dann einige Beurteilungen über den A-Wert vornehmen muss, werden einige unerwartete Ergebnisse erzielt geschehen.
Um das oben genannte Problem der gemeinsamen Nutzung von Ressourcen zu lösen, werden häufig verschiedene Methoden verwendet. Im Folgenden wird nacheinander vorgestellt
Lassen Sie uns zunächst über den Benutzermodus in der Grundstruktur sprechen. Der Vorteil des Benutzermodus besteht darin, dass seine Ausführung relativ schnell ist, da er durch eine Reihe von CPU-Anweisungen koordiniert wird. und die dadurch verursachte Blockierung ist nur eine sehr kurzfristige Blockierung, die für das Betriebssystem bedeutet, dass dieser Thread immer läuft und nie blockiert wurde. Der Nachteil besteht darin, dass nur der Systemkernel die Ausführung eines solchen Threads stoppen kann. Da sich der Thread andererseits dreht und nicht blockiert, belegt er auch CPU-Zeit, was zu einer Verschwendung von CPU-Zeit führt.
Die erste ist die flüchtige Struktur in der primitiven Benutzermodusstruktur. Viele Theorien im Internet zu dieser Struktur ermöglichen es der CPU, das angegebene Feld (Feld, also die Variable) aus dem Speicher zu lesen Beim Schreiben handelt es sich um das Schreiben in den Speicher. Es hat jedoch etwas mit der Codeoptimierung des Compilers zu tun. Schauen Sie sich zunächst den folgenden Code an
public class StrageClass
{
vo int mFlag = 0;
int mValue = 0;
public void Thread1()
{
mValue = 5;
mFlag = 1;
}
public void Thread2()
{
if (mFlag == 1)
Console.WriteLine(mValue);
}
}Studenten, die sich mit Multithread-Synchronisationsproblemen auskennen, wissen, dass es zwei Ergebnisse gibt, wenn zwei Threads zum Ausführen der beiden oben genannten Methoden verwendet werden:
1. Gibt nichts aus
2. Wenn der CSC-Compiler jedoch in die IL-Sprache kompiliert oder JIT in die Maschinensprache kompiliert, wird die Codeoptimierung in Methode Thread1 durchgeführt. Der Compiler geht davon aus, dass die Zuweisung von Werten zu zwei Feldern keine Rolle spielt und nur in ausgeführt wird Ein einzelner Thread berücksichtigt das Problem des Multithreadings überhaupt nicht und kann daher die Ausführungsreihenfolge der beiden Codezeilen durcheinander bringen, was dazu führt, dass mFlag zuerst der Wert 1 zugewiesen wird , und dann wird mValue der Wert 5 zugewiesen, was zum dritten führt. Als Ergebnis wird 0 ausgegeben. Leider konnte ich dieses Ergebnis nicht testen.
Die Lösung für dieses Phänomen ist das flüchtige Konstrukt. Die Verwendung dieses Konstrukts hat zur Folge, dass jedes Mal, wenn ein Lesevorgang für ein Feld mithilfe dieses Konstrukts ausgeführt wird, die Operation garantiert zuerst in der ursprünglichen Codesequenz ausgeführt wird ; Oder wann immer eine Schreiboperation für ein Feld mit diesem Konstrukt ausgeführt wird, wird die Operation garantiert als letztes in der ursprünglichen Codesequenz ausgeführt.
Es gibt derzeit drei Konstrukte, die volatile implementieren. Eines sind die beiden statischen Methoden VolatileRead und VolatileWrite. Die Analyse auf MSND ist wie folgt:
Thread liest Feldwerte . Dieser Wert ist der zuletzt von einem der Prozessoren des Computers geschriebene Wert, unabhängig von der Anzahl der Prozessoren oder dem Zustand des Prozessorcaches.
Thread.VolatileWrite Schreibt sofort einen Wert in ein Feld und macht den Wert für alle Prozessoren im Computer sichtbar.
在多处理器系统上, VolatileRead 获得由任何处理器写入的内存位置的最新值。 这可能需要刷新处理器缓存;VolatileWrite 确保写入内存位置的值立即可见的所有处理器。 这可能需要刷新处理器缓存。
即使在单处理器系统上, VolatileRead 和 VolatileWrite 确保值为读取或写入内存,并不缓存 (例如,在处理器寄存器中)。 因此,您可以使用它们可以由另一个线程,或通过硬件更新的字段对访问进行同步。
从上面的文字看不出他和代码优化有任何关联,那接着往下看。
volatile关键字则是volatile构造的另外一种实现方式,它是VolatileRead和VolatileWrite的简化版,使用 volatile 修饰符对字段可以保证对该字段的所有访问都使用 VolatileRead 或 VolatileWrite。MSDN中对volatile关键字的说明是
volatile 关键字指示一个字段可以由多个同时执行的线程修改。 声明为 volatile 的字段不受编译器优化(假定由单个线程访问)的限制。 这样可以确保该字段在任何时间呈现的都是最新的值。
从这里可以看出跟代码优化有关系了。而纵观上面的介绍得出两个结论:
1.使用了volatile构造的字段读写都是直接对内存操作,不涉及CPU寄存器,使得所有线程对它的读写都是同步,不存在脏读了。读操作是原子的,写操作也是原子的。
2.使用了volatile构造修饰(或访问)字段,它会严格按照代码编写的顺序执行,读操作将会在最早执行,写操作将会最迟执行。
最后一个volatile构造是在.NET Framework中新增的,里面包含的方法都是Read和Write,它实际上就相当于Thread的VolatileRead 和VolatileWrite 。这需要拿源码来说明了,随便拿一个Volatile的Read方法来看
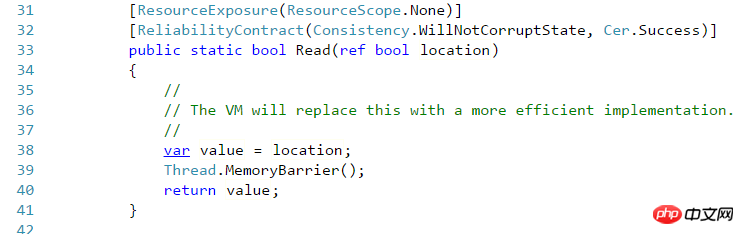
而再看看Thraed的VolatileRead方法

另一个用户模式构造是Interlocked,这个构造是保证读和写都是在原子操作里面,这是与上面volatile最大的区别,volatile只能确保单纯的读或者单纯的写。
为何Interlocked是这样,看一下Interlocaked的方法就知道了
Add(ref int,int)// 调用ExternAdd 外部方法 CompareExchange(ref Int32,Int32,Int32)//1与3是否相等,相等则替换2,返回1的原始值 Decrement(ref Int32)//递减并返回 调用add Exchange(ref Int32,Int32)//将2设置到1并返回 Increment(ref Int32)//自增 调用add
就随便拿其中一个方法Add(ref int,int)来说(Increment和Decrement这两个方法实际上内部调用了Add方法),它会先读到第一个参数的值,在与第二个参数求和后,把结果写到给第一参数中。首先这整个过程是一个原子操作,在这个操作里面既包含了读,也包含了写。至于如何保证这个操作的原子性,估计需要查看Rotor源码才行。在代码优化方面来说,它确保了所有写操作都在Interlocked之前去执行,这保证了Interlocked里面用到的值是最新的;而任何变量的读取都在Interlocked之后读取,这保证了后面用到的值都是最新更改过的。
CompareExchange方法相当重要,虽然Interlocked提供的方法甚少,但基于这个可以扩展出其他更多方法,下面就是个例子,求出两个值的最大值,直接抄了Jeffrey的源码

查看上面代码,在进入循环之前先声明每次循环开始时target的值,在求出最值之后,核对一下target的值是否有变化,如果有变化则需要再记录新值,按照新值来再求一次最值,直到target不变为止,这就满足了Interlocked中所说的,写都在Interlocked之前发生,Interlocked往后就能读到最新的值。
基元内核模式
Der Kernel-Modus basiert auf dem Kernel-Objekt des Betriebssystems, um Thread-Synchronisierungsprobleme zu behandeln. Lassen Sie uns zunächst über seine Nachteile sprechen. Seine Geschwindigkeit wird relativ langsam sein. Es gibt zwei Gründe dafür, dass es vom Betriebssystemkernelobjekt implementiert wird und eine Koordination innerhalb des Betriebssystems erfordert. Der andere Grund ist, dass es sich bei den Kernelobjekten um nicht verwaltete Objekte handelt. Nach dem Verständnis von AppDo wird wissen, dass, wenn sich das Objekt, auf das zugegriffen wird, nicht in der aktuellen AppDomain befindet, es entweder nach Wert oder nach Referenz gemarshallt wird. Es wurde beobachtet, dass dieser Teil der nicht verwalteten Ressourcen per Referenz gemarshallt wird, was Auswirkungen auf die Leistung hat. Durch die Kombination der beiden oben genannten Punkte können wir die Nachteile des Kernelmodus ermitteln. Es hat aber auch Vorteile: 1. Der Thread „dreht“ sich nicht, sondern blockiert, wenn er auf Ressourcen wartet. Dies spart CPU-Zeit und für diese Blockierung kann ein Timeout-Wert festgelegt werden. 2. Die Synchronisierung von Windows-Threads und CLR-Threads kann erreicht werden, und Threads in verschiedenen Prozessen können ebenfalls synchronisiert werden (ersteres wurde noch nicht erlebt, aber für letzteres ist bekannt, dass es in Semaphoren Grenzwertressourcen gibt). 3. Sicherheitseinstellungen können angewendet werden, um den Zugriff für autorisierte Konten zu verhindern (ich weiß nicht, was los ist).
Die Basisklasse für alle Objekte im Kernelmodus ist WaitHandle. Alle Klassenhierarchien im Kernelmodus lauten wie folgt: >
AutoResetEvent
ManualResetEvent
Semaphore
MutexWaitHandle erbt MarshalByRefObject, das nicht verwaltete Objekte per Referenz marshallt. WaitHandle enthält hauptsächlich verschiedene Wait-Methoden. Wenn die Wait-Methode aufgerufen wird, wird sie blockiert, bevor das Signal empfangen wird. WaitOne wartet auf ein Signal, WaitAny(WaitHandle[] waitHandles) empfängt das Signal aller WaitHandles und WaitAll(WaitHandle[] waitHandles) wartet auf das Signal aller WaitHandles. Es gibt eine Version dieser Methoden, die das Festlegen eines Timeouts ermöglicht. Andere Kernelmodus-Konstrukte verfügen über ähnliche Wait-Methoden.
EventWaitHandle verwaltet intern einen booleschen Wert, und die Wait-Methode blockiert den Thread, wenn der boolesche Wert falsch ist, und der Thread wird erst freigegeben, wenn der boolesche Wert wahr ist. Zu den Methoden zum Bearbeiten dieses booleschen Werts gehören Set() und Reset(). Ersteres setzt den booleschen Wert auf „true“, letzteres setzt ihn auf „false“. Dies entspricht einem Schalter. Nach dem Aufruf von „Reset“ führt der Thread „Wait“ aus und wird angehalten und erst dann wieder aufgenommen, wenn „Set“ ausgeführt wird. Es gibt zwei Unterklassen, die auf ähnliche Weise verwendet werden. Der Unterschied besteht darin, dass AutoResetEvent nach dem Aufruf von Set automatisch Reset aufruft, sodass der Schalter sofort in den geschlossenen Zustand zurückkehrt, während ManualResetEvent einen manuellen Aufruf von Set erfordert, um den Schalter zu schließen. Dadurch wird im Allgemeinen erreicht, dass AutoResetEvent bei jeder Freigabe einen Thread passieren lässt, während ManualResetEvent möglicherweise mehrere Threads passieren lässt, bevor Reset manuell aufgerufen wird. Semaphore verwaltet intern eine Ganzzahl. Bei jedem Aufruf von WaitOne wird der maximale Semaphorwert und der anfängliche Semaphorwert um 1 erhöht Maximaler Wert, der Thread wird blockiert. Wenn Release aufgerufen wird, werden ein oder mehrere Semaphore freigegeben. Zu diesem Zeitpunkt werden der oder die blockierten Threads freigegeben. Dies steht im Einklang mit dem Problem von Produzenten und Konsumenten. Wenn der Produzent weiterhin Produkte zur Produkt--Warteschlange hinzufügt, ist dies gleichbedeutend mit einem vollen Semaphor Der Produzent wird blockiert. Wenn der Verbraucher ein Produkt verbraucht, gibt Release einen Platz in der Produktwarteschlange frei. Zu diesem Zeitpunkt kann der Produzent, der keinen Platz zum Speichern des Produkts hat, mit der Speicherung des Produkts in der Produktwarteschlange beginnen.
Die Interna und Regeln von Mutex sind etwas komplizierter als die beiden vorherigen. Erstens besteht die Ähnlichkeit mit den vorherigen darin, dass der aktuelle Thread über WaitOne blockiert wird und der Thread blockiert wird veröffentlicht über ReleaseMutex. Der Unterschied besteht darin, dass WaitOne den ersten aufrufenden Thread passieren lässt und andere nachfolgende Threads blockiert werden, wenn WaitOne aufgerufen wird. Der Thread, der WaitOne durchläuft, kann WaitOne mehrmals aufrufen, muss jedoch ReleaseMutex genauso oft aufrufen, um es freizugeben, andernfalls wird dies der Fall sein Die ungleiche Häufigkeit führt dazu, dass andere Threads blockiert bleiben. Im Vergleich zu den vorherigen Konstrukten verfügt dieses Konstrukt über zwei Konzepte: Thread-Besitz und Rekursion. Dies kann nicht einfach durch die Verwendung der vorherigen Konstrukte erreicht werden, außer durch zusätzliche Kapselung.
MischbauweiseDie obige primitive Struktur verwendet die einfachste Implementierungsmethode. Der Benutzermodus ist schneller als der Benutzermodus, verursacht jedoch eine Verschwendung von CPU-Zeit. Er löst dieses Problem, führt jedoch zu Leistungseinbußen. und die Hybridstruktur kombiniert die Vorteile beider. Sie verwendet intern den Benutzermodus zum richtigen Zeitpunkt und in einer anderen Situation den Kernelmodus. Aber diese Schichten von Urteilen belasten die Erinnerung. Es gibt keine perfekte Struktur bei der Multithread-Synchronisation. Jede Struktur hat Vor- und Nachteile, und ihre Existenz ist sinnvoll. In Kombination mit bestimmten Anwendungsszenarien ist die optimale Struktur verfügbar. Es kommt nur darauf an, ob wir die Vor- und Nachteile je nach Szenario abwägen können.
Verschiedene Klassen mit Slim-Suffix Im System.Threading-Namespace können Sie mehrere Klassen sehen, die mit dem Slim-Suffix enden: ManualResetEventSlim, SemaphoreSlim, ReaderWriterLockSlim. Mit Ausnahme der letzten haben die anderen beiden im primitiven Kernelmodus die gleiche Struktur, aber diese drei Klassen sind vereinfachte Versionen der ursprünglichen Strukturen, insbesondere der ersten beiden. Sie werden auf die gleiche Weise wie die ursprünglichen verwendet, aber versuchen Sie es Vermeiden Sie die Verwendung der Kernelobjekte des Betriebssystems und erzielen Sie einen schlanken Effekt. Beispielsweise wird in SemaphoreSlim das Kernel-Konstrukt ManualResetEvent verwendet, dieses Konstrukt wird jedoch durch Verzögerung initialisiert und nur dann verwendet, wenn dies erforderlich ist. Was ReaderWriterLockSlim betrifft, werden wir es später vorstellen.
Überwachen und sperren, das Schlüsselwort lock ist das bekannteste Mittel zur Erzielung einer Multithread-Synchronisation. Beginnen wir also mit einem Codeabschnitt

Diese Methode ist recht einfach und bedeutungslos. Es geht nur darum, zu sehen, in was der Compiler diesen Code kompiliert. Schauen Sie sich die IL wie folgt an:

Achten Sie auf den IL-Code. Der try...finally-Anweisungsblock sowie die Methoden Monitor.Enter und Monotor.Exit werden hinzugefügt. Ändern Sie dann den Code und kompilieren Sie ihn erneut, um den IL-Code zu sehen Codevergleich Ähnlich, aber nicht gleichwertig. Tatsächlich lautet der Code, der dem Lock-Anweisungsblock entspricht, wie folgt:

Wie übergibt Monitor also einen The, da Lock im Wesentlichen Monitor aufruft? Das Objekt wird gesperrt und dann wird die Thread-Synchronisierung erreicht. Es stellt sich heraus, dass jedes Objekt im verwalteten Heap zwei feste Mitglieder hat, von denen eines auf den Zeiger des Objekttyps zeigt und das andere auf einen Thread-Synchronisationsblock Index . Dieser Index zeigt auf ein Element eines synchronisierten Block-
-Arrays. Monitor verlässt sich auf diesen synchronisierten Block, um den Thread zu sperren. Laut Jeffrey (dem Autor von CLR über C#) gibt es im Synchronisationsblock drei Felder: die Eigentümer-Thread-ID, die Anzahl der wartenden Threads und die Anzahl der Rekursionen. Durch eine weitere Reihe von Artikeln habe ich jedoch erfahren, dass es sich bei den Mitgliedern des Thread-Synchronisationsblocks nicht nur um diese wenigen handelt. Interessierte Schüler können die beiden Artikel „Enthüllung des Synchronisationsblockindex“ lesen. Wenn der Monitor ein Objekt obj sperren muss, prüft er, ob der Synchronisationsblockindex von obj ein Index des Arrays ist. Wenn er -1 ist, findet er einen freien Synchronisationsblock aus dem Array, der ihm zugeordnet werden kann Gleichzeitig zeichnet die Eigentümer-Thread-ID des Synchronisationsblocks die ID des aktuellen Threads auf. Wenn ein Thread den Monitor erneut aufruft, prüft er, ob die Eigentümer-ID des Synchronisationsblocks mit der aktuellen Thread-ID übereinstimmt. Lassen Sie es passieren. Addieren Sie 1 zur Anzahl der Threads, werfen Sie den Thread in eine Bereitschaftswarteschlange (diese Warteschlange existiert tatsächlich im Synchronisationsblock) und blockieren Sie ihn von Rekursionen beim Aufruf von Exit, um sicherzustellen, dass nach Abschluss der Rekursion die Eigentümer-Thread-ID gelöscht wird. Anhand der Anzahl der wartenden Threads wissen wir, ob Threads vorhanden sind. Wenn dies der Fall ist, werden die Threads aus der Warteschlange entfernt und freigegeben. Andernfalls wird die Zuordnung zum Synchronisationsblock aufgehoben und der Synchronisationsblock wartet auf die Verwendung durch den nächsten gesperrtes Objekt. 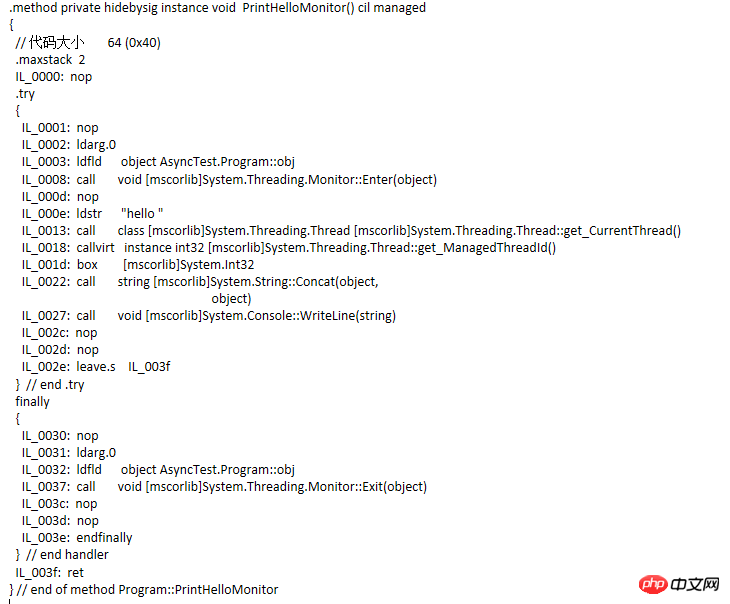
而ReaderWriterLock对互斥资源的加的锁分读锁与写锁,类似于数据库中提到的共享锁和排他锁。大致情况是加了读锁的资源允许多个线程对其访问,而加了写锁的资源只有一个线程可以对其访问。两种加了不同缩的线程都不能同时访问资源,而严格来说,加了读锁的线程只要在同一个队列中的都能访问资源,而不同队列的则不能访问;加了写锁的资源只能在一个队列中,而写锁队列中只有一个线程能访问资源。区分读锁的线程是否在于统一个队列中的判断标准是,本次加读锁的线程与上次加读锁的线程这个时间段中,有否别的线程加了写锁,没没别的线程加写锁,则这两个线程都在同一个读锁队列中。
ReaderWriterLockSlim和ReaderWriterLock类似,是后者的升级版,出现在.NET Framework3.5,据说是优化了递归和简化了操作。在此递归策略我尚未深究过。目前大概列举一下它们通常用的方法
ReaderWriterLock常用的方法
Acqurie或Release ReaderLock或WriteLock 的排列组合
UpGradeToWriteLock/DownGradeFromWriteLock 用于在读锁中升级到写锁。当然在这个升级的过程中也涉及到线程从读锁队列切换到写锁队列中,因此需要等待。
ReleaseLock/RestoreLock 释放所有锁和恢复锁状态
ReaderWriterLock实现IDispose接口,其方法则是以下模式
TryEnter/Enter/Exit ReadLock/WriteLock/UpGradeableReadLock
CoutdownEvent比较少用的混合构造,这个跟Semaphore相反,体现在Semaphore是在内部计数(也就是信号量)达到最大值的时候让线程阻塞,而CountdownEvent是在内部计数达到0的时候才让线程阻塞。其方法有
AddCount //计数递增; Signal //计数递减; Reset //计数重设为指定或初始; Wait //当且仅当计数为0才不阻塞,否则就阻塞。
Barrier也是一个比较少用的混合构造,用于处理多线程在分步骤的操作中协作问题。它内部维护着一个计数,该计数代表这次协作的参与者数量,当不同的线程调用SignalAndWait的时候会给这个计数加1并且把调用的线程阻塞,直到计数达到最大值的时候,才会释放所有被阻塞的线程。假设还是不明白的话就看一下MSND上面的示例代码
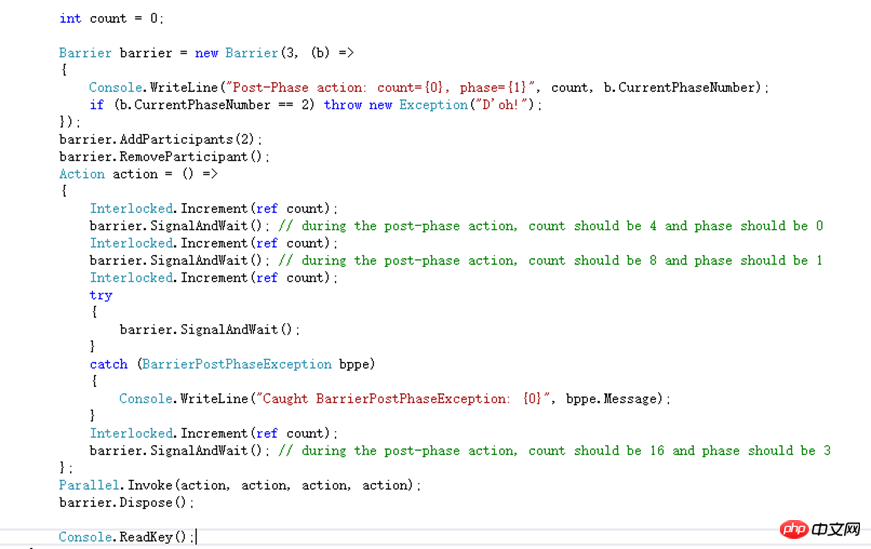
这里给Barrier初始化的参与者数量是3,同时每完成一个步骤的时候会调用委托,该方法是输出count的值步骤索引。参与者数量后来增加了两个又减少了一个。每个参与者的操作都是相同,给count进行原子自增,自增完则调用SgnalAndWait告知Barrier当前步骤已完成并等待下一个步骤的开始。但是第三次由于回调方法里抛出了一个异常,每个参与者在调用SignalAndWait的时候都会抛出一个异常。通过Parallel开始了一个并行操作。假设并行开的作业数跟Barrier参与者数量不一样就会导致在SignalAndWait会有非预期的情况出现。
接下来说两个Attribute,这个估计不算是同步构造,但是也能在线程同步中发挥作用
MethodImplAttribute这个Attribute适用于方法的,当给定的参数是MethodImplOptions.Synchronized,它会对整个方法的方法体进行加锁,凡是调用这个方法的线程在没有获得锁的时候就会被阻塞,直到拥有锁的线程释放了才将其唤醒。对静态方法而言它就相当于把该类的类型对象给锁了,即lock(typeof(ClassType));对于实例方法他就相当于把该对象的实例给锁了,即lock(this)。最开始对它内部调用了lock这个结论存在猜疑,于是用IL编译了一下,发现方法体的代码没啥异样,查看了一些源码也好无头绪,后来发现它的IL方法头跟普通的方法有区别,多了一个synchronized
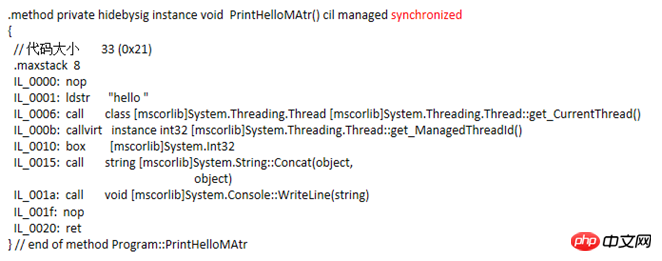
于是网上找各种资料,最后发现"junchu25"的博客[1][2]里提到用WinDbg来查看JIT生成的代码。
调用Attribute的
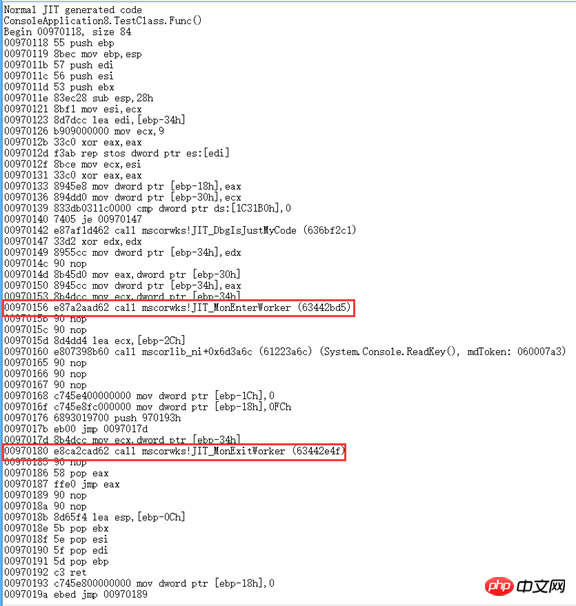
调用lock的
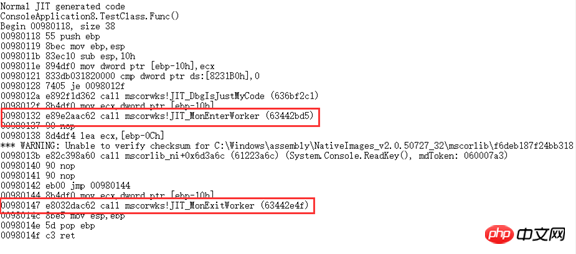
对于用这个Attribute实现的线程同步连Jeffrey都不推荐使用。
System.Runtime.Remoting.Contexts.SynchronizationAttribute ist auf Klassen anwendbar. Fügen Sie dieses Attribut zur Klassendefinition hinzu und erben Sie die Klasse von ContextBoundOject. Dadurch wird die gleiche Sperre für alle Methoden in der Klasse hinzugefügt Wenn ein Thread eine Methode dieser Klasse aufruft und die Sperre nicht erreicht wird, wird der Thread blockiert. Es gibt ein Sprichwort, dass es im Wesentlichen noch schwieriger ist, diese Aussage zu überprüfen. Es gibt nur sehr wenige inländische Ressourcen, die auch den AppDomain- und Thread-Kontext umfassen. AppDomain sollte in einem separaten Artikel vorgestellt werden. Aber ich möchte hier ein wenig darüber sprechen. Früher dachte ich, dass es Thread-Stacks und Heap-Speicher im Speicher gibt, und das ist nur eine sehr grundlegende Unterteilung. Der Heap-Speicher ist auch in mehrere AppDomains unterteilt Mindestens ein Kontext in jeder AppDomain. Jedes Objekt gehört zu einem Kontext innerhalb einer AppDomain. Auf Objekte über AppDomains hinweg kann nicht direkt zugegriffen werden. Sie müssen nach Wert gemarshallt werden (entspricht dem tiefen Kopieren eines Objekts in die aufrufende AppDomain) oder nach Referenz gemarshallt werden. Für das Marshalling per Referenz muss die Klasse MarshalByRefObject erben. Wenn ein Objekt aufgerufen wird, das diese Klasse erbt, ruft es nicht die Klasse selbst auf, sondern ruft sie über einen Proxy auf. Dann ist auch kontextübergreifendes Marshalling nach Wertoperation erforderlich. Ein normalerweise erstelltes Objekt befindet sich im Standardkontext unter der Standard-AppDomain des Prozesses, und die Instanz einer Klasse, die das SynchronizationAttribute-Attribut verwendet, gehört zu einem anderen Kontext. Klassen, die die ContextBoundObject-Basisklasse erben, greifen auch über einen Proxy auf Objekte zu Beim Objekt-by-Reference-Marshalling wird nicht auf das Objekt selbst zugegriffen. Ob kontextübergreifend auf das Objekt zugegriffen werden soll, können Sie mithilfe der Methode RemotingServices.IsObjectOutOfContext(obj) beurteilen. SynchronizedServerContextSink ist eine interne Klasse von mscorlib. Wenn ein Thread ein kontextübergreifendes Objekt aufruft, wird der Aufruf von SynchronizedServerContextSink, einer internen Klasse in mscorlib, gekapselt. Das SynchronizationAttribute-Attribut bestimmt die aktuelle Ausführungsanforderung basierend darauf, ob mehrere WorkItem-Ausführungsanforderungen vorliegen . Wird das verarbeitete WorkItem sofort ausgeführt oder zur Ausführung in eine First-In-First-Out-Warteschlange gestellt? Diese Warteschlange ist Mitglied des SynchronizationAttribute oder wenn das Attribut bestimmt, ob Um das WorkItem sofort auszuführen, müssen sie eine Sperre erhalten. Das gesperrte Objekt ist auch die Warteschlange dieses WorkItem. Dies beinhaltet das Zusammenspiel mehrerer Klassen. Ich habe es noch nicht vollständig verstanden. Nach einer klaren Analyse werde ich weitere Fehler hinzufügen. Die über dieses Attribut implementierte Thread-Synchronisation wird jedoch aufgrund starker Intuition nicht empfohlen, was hauptsächlich auf Leistungseinbußen und einen relativ großen Sperrbereich zurückzuführen ist.
Das obige ist der detaillierte Inhalt vonAusführliche Erläuterung der Thread-Synchronisation im C#-Multithreading (Bild und Text). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Active Directory mit C#
Sep 03, 2024 pm 03:33 PM
Active Directory mit C#
Sep 03, 2024 pm 03:33 PM
Leitfaden zu Active Directory mit C#. Hier besprechen wir die Einführung und die Funktionsweise von Active Directory in C# sowie die Syntax und das Beispiel.
 C#-Serialisierung
Sep 03, 2024 pm 03:30 PM
C#-Serialisierung
Sep 03, 2024 pm 03:30 PM
Leitfaden zur C#-Serialisierung. Hier besprechen wir die Einführung, die Schritte des C#-Serialisierungsobjekts, die Funktionsweise bzw. das Beispiel.
 Zufallszahlengenerator in C#
Sep 03, 2024 pm 03:34 PM
Zufallszahlengenerator in C#
Sep 03, 2024 pm 03:34 PM
Leitfaden zum Zufallszahlengenerator in C#. Hier besprechen wir die Funktionsweise des Zufallszahlengenerators, das Konzept von Pseudozufallszahlen und sicheren Zahlen.
 C#-Datenrasteransicht
Sep 03, 2024 pm 03:32 PM
C#-Datenrasteransicht
Sep 03, 2024 pm 03:32 PM
Leitfaden zur C#-Datenrasteransicht. Hier diskutieren wir die Beispiele, wie eine Datenrasteransicht aus der SQL-Datenbank oder einer Excel-Datei geladen und exportiert werden kann.
 Muster in C#
Sep 03, 2024 pm 03:33 PM
Muster in C#
Sep 03, 2024 pm 03:33 PM
Leitfaden zu Mustern in C#. Hier besprechen wir die Einführung und die drei wichtigsten Arten von Mustern in C# zusammen mit ihren Beispielen und der Code-Implementierung.
 Fakultät in C#
Sep 03, 2024 pm 03:34 PM
Fakultät in C#
Sep 03, 2024 pm 03:34 PM
Leitfaden zur Fakultät in C#. Hier diskutieren wir die Einführung in die Fakultät in C# zusammen mit verschiedenen Beispielen und Code-Implementierungen.
 Primzahlen in C#
Sep 03, 2024 pm 03:35 PM
Primzahlen in C#
Sep 03, 2024 pm 03:35 PM
Leitfaden zu Primzahlen in C#. Hier besprechen wir die Einführung und Beispiele von Primzahlen in C# sowie die Codeimplementierung.
 Der Unterschied zwischen Multithreading und asynchronem C#
Apr 03, 2025 pm 02:57 PM
Der Unterschied zwischen Multithreading und asynchronem C#
Apr 03, 2025 pm 02:57 PM
Der Unterschied zwischen Multithreading und Asynchron besteht darin, dass Multithreading gleichzeitig mehrere Threads ausführt, während asynchron Operationen ausführt, ohne den aktuellen Thread zu blockieren. Multithreading wird für rechenintensive Aufgaben verwendet, während asynchron für die Benutzerinteraktion verwendet wird. Der Vorteil des Multi-Threading besteht darin, die Rechenleistung zu verbessern, während der Vorteil von Asynchron nicht darin besteht, UI-Threads zu blockieren. Die Auswahl von Multithreading oder Asynchron ist von der Art der Aufgabe abhängt: Berechnungsintensive Aufgaben verwenden Multithreading, Aufgaben, die mit externen Ressourcen interagieren und die UI-Reaktionsfähigkeit asynchron verwenden müssen.
