

Grafische Codeanalyse der Migration von MySQL-Daten nach Oracle

In diesem Artikel wird hauptsächlich die korrekte Methode zur Migration von MySQL-Daten nach Oracle vorgestellt. Interessierte Freunde können sich
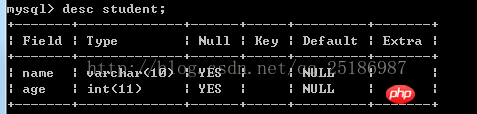
in Es gibt eine Tabelle student in der MySQL-Datenbank , und seine Struktur ist wie folgt:
Es gibt eine Tabelle from_mysql in der Oracle-Datenbank, und ihre Struktur ist wie folgt :

Jetzt müssen wir die Daten von mysql student zu Oracles from_mysql übertragen. Hier kann ich diese Funktion mit Hilfe des Spoon-Tools von Kettle schnell implementieren.
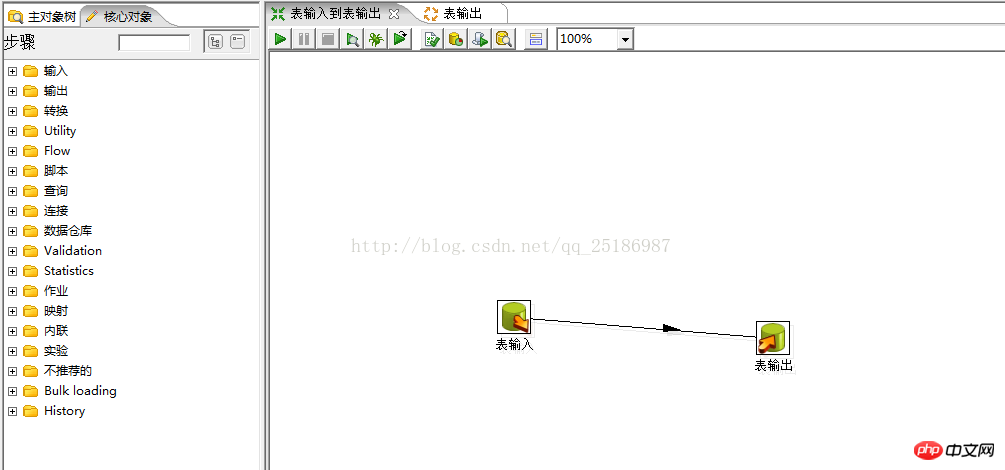
Öffnen Sie zunächst den Löffel, erstellen Sie eine neue Transformation und nennen Sie sie Tabelleneingabe bis Tabellenausgabe. Suchen Sie dann die Tabelleneingabe von der Eingabe im Kernobjekt , ziehen Sie sie auf die Bearbeitungsoberfläche, suchen Sie dann die Ausgabe von der Ausgabe und ziehen Sie sie auf die Bearbeitungsoberfläche, verbinden Sie die Tabelleneingabe und die Tabellenausgabe wie folgt In der Abbildung dargestellt:
Rechtsklick auf die Tabelleneingabe und Auswahl des Bearbeitungsschritts. Das folgende Fenster wird angezeigt:
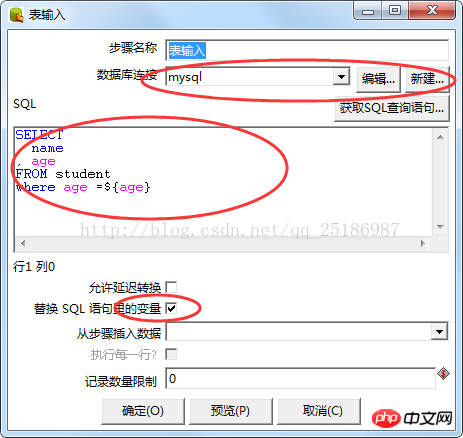
Mit der Datenbank verbinden Wählen Sie dort die verbundenen Daten aus, wählen Sie hier MySQL aus und klicken Sie auf Bearbeiten, um die Datenbank zu ändern. Wenn die Datenbank noch nicht konfiguriert wurde, klicken Sie auf „Neu“ und die Datenbank wird konfiguriert. Informationen zur spezifischen Konfiguration finden Sie in der Kettle-Configuration-Ressourcenbibliothek.
Geben Sie die SQL-Anweisung in das SQL-Eingabefeld ein, um die zu migrierenden Daten zu filtern. Wenn die SQL-Anweisung die Variable enthält, aktivieren Sie das Kontrollkästchen unten, um die Variablen in der SQL-Anweisung zu ersetzen.
Klicken Sie mit der rechten Maustaste auf die Tabellenausgabe, wählen Sie den Bearbeitungsschritt aus und das folgende Fenster wird angezeigt:
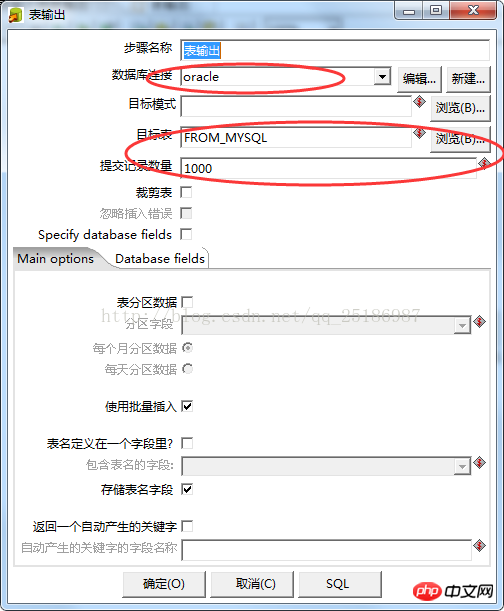
Die Datenbankverbindung ähnelt die Tabelleneingabe, außer dass hier Oracle ausgewählt ist, da wir Testdaten ausgewählt haben und die Datenmenge nicht groß ist, kann die Anzahl der übermittelten Datensätze hier als Standard beibehalten werden.
Als nächstes erstellen Sie einen neuen Job und nennen ihn „Tabellenausgabe“. Suchen Sie im allgemeinen Bereich des Kernobjekts nach Start, Festlegen von Variablen und Transformation, ziehen Sie es auf die Bearbeitungsoberfläche und verbinden Sie die drei Objekte, wie in der Abbildung gezeigt:
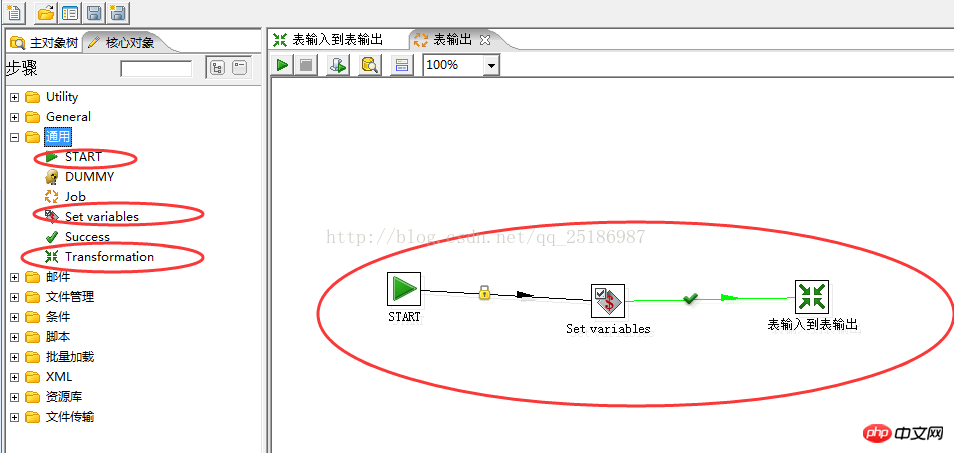
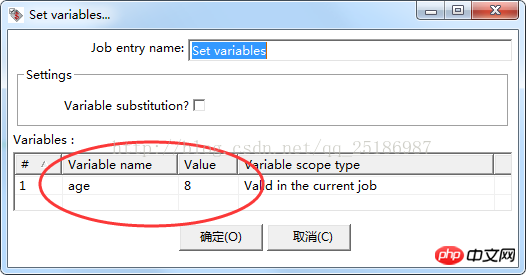
Klicken Sie mit der rechten Maustaste auf „Variablen festlegen“, wählen Sie den Eintrag „Job bearbeiten“ aus, bearbeiten Sie den Variablennamen Namen und den Variablenwert im Popup-Fenster, wie unten gezeigt:
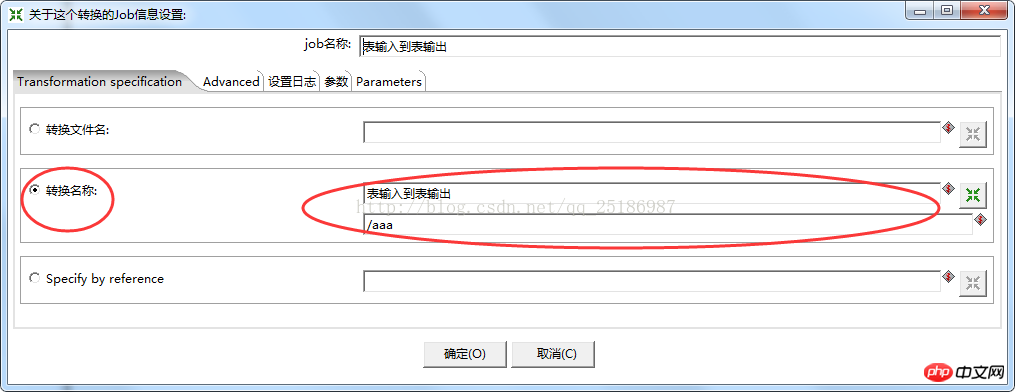
Klicken Sie mit der rechten Maustaste auf die Transformation, wählen Sie den Jobeintrag bearbeiten aus, wählen Sie den Transformationsnamen im Popup-Fenster aus und suchen Sie die Transformation, die Sie gerade gespeichert haben: Tabelleneingabe in Ausdruck. Wie unten gezeigt:
Zu diesem Zeitpunkt sind alle Arbeiten abgeschlossen. Klicken Sie auf „Ausführen“, um Daten aus MySQL zu extrahieren und an Oracle zu übertragen.
Das obige ist der detaillierte Inhalt vonGrafische Codeanalyse der Migration von MySQL-Daten nach Oracle. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1206
24
52
1206
24

 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So erstellen Sie Cursor in Oracle Loop
Apr 12, 2025 am 06:18 AM
So erstellen Sie Cursor in Oracle Loop
Apr 12, 2025 am 06:18 AM
In Oracle kann die For -Loop -Schleife Cursors dynamisch erzeugen. Die Schritte sind: 1. Definieren Sie den Cursortyp; 2. Erstellen Sie die Schleife; 3.. Erstellen Sie den Cursor dynamisch; 4. Führen Sie den Cursor aus; 5. Schließen Sie den Cursor. Beispiel: Ein Cursor kann mit dem Zyklus für Kreislauf erstellt werden, um die Namen und Gehälter der Top 10 Mitarbeiter anzuzeigen.
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
 So installieren Sie MySQL in CentOS7
Apr 14, 2025 pm 08:30 PM
So installieren Sie MySQL in CentOS7
Apr 14, 2025 pm 08:30 PM
Der Schlüssel zur eleganten Installation von MySQL liegt darin, das offizielle MySQL -Repository hinzuzufügen. Die spezifischen Schritte sind wie folgt: Laden Sie den offiziellen GPG -Schlüssel von MySQL herunter, um Phishing -Angriffe zu verhindern. Add MySQL repository file: rpm -Uvh https://dev.mysql.com/get/mysql80-community-release-el7-3.noarch.rpm Update yum repository cache: yum update installation MySQL: yum install mysql-server startup MySQL service: systemctl start mysqld set up booting
 Welche Schritte sind erforderlich, um CentOs in HDFs zu konfigurieren
Apr 14, 2025 pm 06:42 PM
Welche Schritte sind erforderlich, um CentOs in HDFs zu konfigurieren
Apr 14, 2025 pm 06:42 PM
Das Erstellen eines Hadoop -verteilten Dateisystems (HDFS) auf einem CentOS -System erfordert mehrere Schritte. Dieser Artikel enthält einen kurzen Konfigurationshandbuch. 1. Bereiten Sie sich auf die Installation von JDK in der frühen Stufe vor: Installieren Sie JavadevelopmentKit (JDK) auf allen Knoten, und die Version muss mit Hadoop kompatibel sein. Das Installationspaket kann von der offiziellen Oracle -Website heruntergeladen werden. Konfiguration der Umgebungsvariablen: Bearbeiten /etc /Profildatei, setzen Sie Java- und Hadoop -Umgebungsvariablen, damit das System den Installationspfad von JDK und Hadoop ermittelt. 2. Sicherheitskonfiguration: SSH-Kennwortfreie Anmeldung zum Generieren von SSH-Schlüssel: Verwenden Sie den Befehl ssh-keygen auf jedem Knoten
 MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
MySQLs Rolle: Datenbanken in Webanwendungen
Apr 17, 2025 am 12:23 AM
Die Hauptaufgabe von MySQL in Webanwendungen besteht darin, Daten zu speichern und zu verwalten. 1.Mysql verarbeitet effizient Benutzerinformationen, Produktkataloge, Transaktionsunterlagen und andere Daten. 2. Durch die SQL -Abfrage können Entwickler Informationen aus der Datenbank extrahieren, um dynamische Inhalte zu generieren. 3.Mysql arbeitet basierend auf dem Client-Server-Modell, um eine akzeptable Abfragegeschwindigkeit sicherzustellen.
