

In diesem Artikel wird hauptsächlich das Paging -Beispiel für die Implementierung erweiterter Cassandra-Operationen in Java vorgestellt (mit spezifischen Projektanforderungen). Interessierte Freunde können sich darauf beziehen.
Im letzten Blog ging es um Cassandra-Paging. Ich glaube, jeder wird darauf achten: Die nächste Abfrage hängt von der vorherigen Abfrage ab (alle Primärschlüssel des letzten Datensatzes in der vorherigen Abfrage). . Es ist nicht so flexibel wie mysql, daher kann es nur Funktionen wie die vorherige Seite und die nächste Seite implementieren, aber keine Funktionen wie die Seitennummer (die Leistung ist zu gering, wenn dies erzwungen wird). umgesetzt).
Sehen wir uns zunächst die offizielle Paging-Methode des Treibers an
Wenn die Anzahl der durch eine Abfrage erhaltenen Datensätze zu groß ist und auf einmal zurückgegeben wird, ist die Effizienz sehr hoch niedrig und sehr Es kann zu einem Speicherüberlauf und zum Absturz der gesamten Anwendung kommen. Daher paginiert der Treiber die Ergebnismenge und gibt die entsprechende Datenseite zurück.
1. Festlegen der Abrufgröße
Die Abrufgröße bezieht sich auf die Anzahl der gleichzeitig von Cassandra abgerufenen Datensätze, mit anderen Worten: Dies ist die Anzahl der Datensätze auf jeder Seite. Wir können beim Erstellen einer Clusterinstanz einen Standardwert für die Abrufgröße angeben in der Anweisung festgelegt werden
// At initialization:
Cluster cluster = Cluster.builder()
.addContactPoint("127.0.0.1")
.withQueryOptions(new QueryOptions().setFetchSize(2000))
.build();
// Or at runtime:
cluster.getConfiguration().getQueryOptions().setFetchSize(2000);Wenn die Abrufgröße in der Anweisung festgelegt ist, wird die Abrufgröße der Anweisung wirksam, andernfalls wird die Abrufgröße im Cluster wirksam.
Statement statement = new SimpleStatement("your query");
statement.setFetchSize(2000);Abrufgröße begrenzt die Anzahl der pro Seite zurückgegebenen Ergebnismengen, Der Treiber erfasst automatisch die nächste Seite mit Datensätzen im Hintergrund. Wie im folgenden Beispiel ist die Abrufgröße = 20:
Standardmäßig erfolgt der automatische Abruf im Hintergrund im letzten Moment, d. h. wenn die Datensätze einer bestimmten Seite abgerufen wurden iteriert. Wenn Sie eine bessere Kontrolle benötigen, bietet die ResultSet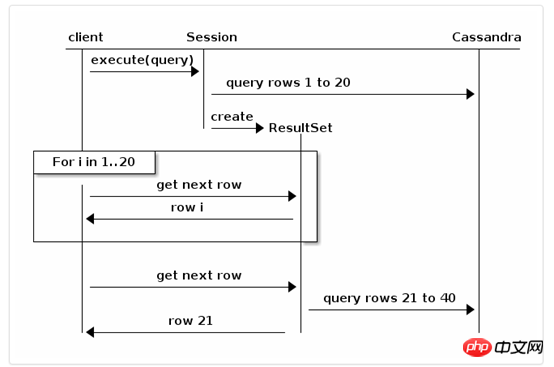 Schnittstelle
Schnittstelle
Hier erfahren Sie, wie Sie diese Methoden verwenden, um die nächste Seite im Voraus zu leeren, um eine Iteration über einen bestimmten Wert zu vermeiden Seite. Leistungseinbußen nur durch das Crawlen der nächsten Seite:
getAvailableWithoutFetching() and isFullyFetched() to check the current state; fetchMoreResults() to force a page fetch;
ResultSet rs = session.execute("your query");
for (Row row : rs) {
if (rs.getAvailableWithoutFetching() == 100 && !rs.isFullyFetched())
rs.fetchMoreResults(); // this is asynchronous
// Process the row ...
System.out.println(row);
}-Status Manchmal ist es sehr nützlich, den Paginierungsstatus für eine spätere Wiederherstellung zu speichern. Stellen Sie sich vor: Es gibt einen zustandslosen Webdienst, der eine Ergebnisliste und einen Link zur nächsten Seite anzeigt Führen Sie genau die gleiche Abfrage wie zuvor aus, außer dass die Iteration dort beginnen sollte, wo die vorherige Seite aufgehört hat. Dies entspricht dem Merken, wohin die vorherige Seite iteriert hat. Dann kann die nächste Seite von hier aus beginnen.
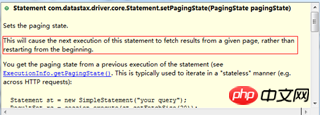
Dazu stellt der Treiber ein PagingState-Objekt
bereit, das unsere Position im Ergebnissatz darstellt, wenn die nächste Seite abgerufen wird.Der serialisierte Inhalt des PagingState-Objekts kann dauerhaft gespeichert und auch als Parameter für Paging-Anfragen verwendet werden, um ihn für die spätere Wiederverwendung vorzubereiten:
ResultSet resultSet = session.execute("your query");
// iterate the result set...
PagingState pagingState = resultSet.getExecutionInfo().getPagingState();
// PagingState对象可以被序列化成字符串或字节数组
String string = pagingState.toString();
byte[] bytes = pagingState.toBytes();Bitte beachten Sie, dass der paginierte Zustand nur wiederholt mit genau derselben Anweisung (gleiche Abfrage, gleiche Parameter) verwendet werden kann. Darüber hinaus handelt es sich um einen undurchsichtigen Wert, der lediglich zum Speichern eines Zustandswerts verwendet wird, der wiederverwendet werden kann. Wenn Sie versuchen, seinen Inhalt zu ändern oder ihn für eine andere Anweisung zu verwenden, gibt der Treiber einen Fehler aus.
PagingState.fromBytes(byte[] bytes); PagingState.fromString(String str);
each
er-Tabelle:Hauptcode:
import java.util.Map;
import com.datastax.driver.core.PagingState;
public interface ICassandraPage
{
Map<String, Object> page(PagingState pagingState);
}Testcode:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import com.datastax.driver.core.PagingState;
import com.datastax.driver.core.ResultSet;
import com.datastax.driver.core.Row;
import com.datastax.driver.core.Session;
import com.datastax.driver.core.SimpleStatement;
import com.datastax.driver.core.Statement;
import com.huawei.cassandra.dao.ICassandraPage;
import com.huawei.cassandra.factory.SessionRepository;
import com.huawei.cassandra.model.Teacher;
public class CassandraPageDao implements ICassandraPage
{
private static final Session session = SessionRepository.getSession();
private static final String CQL_TEACHER_PAGE = "select * from mycas.teacher;";
@Override
public Map<String, Object> page(PagingState pagingState)
{
final int RESULTS_PER_PAGE = 2;
Map<String, Object> result = new HashMap<String, Object>(2);
List<Teacher> teachers = new ArrayList<Teacher>(RESULTS_PER_PAGE);
Statement st = new SimpleStatement(CQL_TEACHER_PAGE);
st.setFetchSize(RESULTS_PER_PAGE);
// 第一页没有分页状态
if (pagingState != null)
{
st.setPagingState(pagingState);
}
ResultSet rs = session.execute(st);
result.put("pagingState", rs.getExecutionInfo().getPagingState());
//请注意,我们不依赖RESULTS_PER_PAGE,因为fetch size并不意味着cassandra总是返回准确的结果集
//它可能返回比fetch size稍微多一点或者少一点,另外,我们可能在结果集的结尾
int remaining = rs.getAvailableWithoutFetching();
for (Row row : rs)
{
Teacher teacher = this.obtainTeacherFromRow(row);
teachers.add(teacher);
if (--remaining == 0)
{
break;
}
}
result.put("teachers", teachers);
return result;
}
private Teacher obtainTeacherFromRow(Row row)
{
Teacher teacher = new Teacher();
teacher.setAddress(row.getString("address"));
teacher.setAge(row.getInt("age"));
teacher.setHeight(row.getInt("height"));
teacher.setId(row.getInt("id"));
teacher.setName(row.getString("name"));
return teacher;
}
}Werfen wir einen Blick auf die setPagingState(pagingState)-Methode von Statement:
import java.util.Map;
import com.datastax.driver.core.PagingState;
import com.huawei.cassandra.dao.ICassandraPage;
import com.huawei.cassandra.dao.impl.CassandraPageDao;
public class PagingTest
{
public static void main(String[] args)
{
ICassandraPage cassPage = new CassandraPageDao();
Map<String, Object> result = cassPage.page(null);
PagingState pagingState = (PagingState) result.get("pagingState");
System.out.println(result.get("teachers"));
while (pagingState != null)
{
// PagingState对象可以被序列化成字符串或字节数组
System.out.println("==============================================");
result = cassPage.page(pagingState);
pagingState = (PagingState) result.get("pagingState");
System.out.println(result.get("teachers"));
}
}
}
Durch das Speichern des Paging-Status kann sichergestellt werden, dass der Wechsel von einer Seite zur nächsten gut funktioniert (die vorherige Seite kann ebenfalls implementiert werden), aber zufällige Sprünge wie das direkte Springen zu Seite 10 werden dadurch nicht erfüllt, da wir dies nicht tun Ich kenne den Paging-Status der vorherigen Seite von Seite 10. Funktionen wie diese, die Offset-Abfragen erfordern, werden von Cassandra nicht nativ unterstützt. Der Grund dafür ist, dass Offset-Abfragen ineffizient sind (die Leistung ist linear umgekehrt proportional zur Anzahl der übersprungenen Zeilen), weshalb Cassandra offiziell von der Verwendung von Offsets abrät. Wenn wir eine Offset-Abfrage implementieren müssen, können wir sie auf dem Client simulieren. Die Leistung ist jedoch immer noch linear umgekehrt proportional, was bedeutet, dass die Leistung umso geringer ist, je größer der Offset ist. Wenn die Leistung innerhalb unseres Akzeptanzbereichs liegt, kann sie immer noch erreicht werden. Beispielsweise werden auf jeder Seite 10 Zeilen angezeigt, und es können maximal 20 Seiten angezeigt werden. Dies bedeutet, dass bei der Anzeige der 20. Seite bis zu 190 zusätzliche Zeilen abgerufen werden müssen, was jedoch keine große Leistungseinbuße zur Folge hat Wenn die Datenmenge nicht groß ist, ist es dennoch möglich, eine Offset-Abfrage zu simulieren. Angenommen, dass auf jeder Seite 10 Datensätze angezeigt werden und die Abrufgröße 50 beträgt, fordern wir Seite 12 (d. h. Zeilen 110 bis 119) an: 1 Zuerst ausführen Abfrage einmal, und die Ergebnismenge enthält die Zeilen 0 bis 49. Wir brauchen ihn nicht, wir brauchen nur den Paging-Status 2. Verwenden Sie den Paging-Status, der aus der ersten Abfrage erhalten wurde, um die zweite auszuführen Abfrage; 3. Verwenden Sie den aus der zweiten Abfrage erhaltenen Paging-Status, um die dritte Abfrage auszuführen. Der Ergebnissatz enthält 100 bis 149 Zeilen. 4 Filtern Sie anhand des durch die dritte Abfrage erhaltenen Ergebnissatzes zunächst die ersten 10 Datensätze heraus, lesen Sie dann 10 Datensätze und verwerfen Sie schließlich die verbleibenden Datensätze und lesen Sie die 10 Datensätze sind die Datensätze, die auf Seite 12 angezeigt werden müssen. Wir müssen versuchen, die beste Abrufgröße zu finden, um das beste Gleichgewicht zu erreichen: zu klein bedeutet mehr Abfragen im Hintergrund; zu groß bedeutet, dass eine größere Menge an Informationen und mehr unnötige OK zurückgegeben werden. Darüber hinaus unterstützt Cassandra selbst keine Offset-Abfragen. Unter der Voraussetzung einer zufriedenstellenden Leistung ist die Implementierung eines clientseitigen Simulationsoffsets nur ein Kompromiss. Die offiziellen Empfehlungen lauten wie folgt: 1. Testen Sie den Code anhand erwarteter Abfragemuster, um sicherzustellen, dass die Annahmen korrekt sind 2. Legen Sie eine feste Grenze für die maximale Seitenzahl fest, um böswillige Benutzer davon abzuhalten Auslösen einer großen Abfrage zum Überspringen von Zeilen 5. Zusammenfassung Cassandra bietet nur begrenzte Unterstützung für Paging und die vorherige und nächste Seite sind einfacher zu implementieren . Wenn Sie darauf bestehen, die Offset-Abfrage zu implementieren, können Sie die Client-Simulation verwenden. Es ist jedoch besser, dieses Szenario nicht für Cassandra zu verwenden, da Cassandra im Allgemeinen zur Lösung von Big-Data-Problemen verwendet wird Wenn die Abfrage zu groß ist, kann die Leistung nicht gelobt werden. In meinem Projekt verwendet Index die Paging-Funktion von Cassandra. Das Szenario ist wie folgt: Die Cassandra-Tabelle hat keinen Sekundärindex und Elasticsearch wird verwendet, um den Sekundärindex von Cassandra zu implementieren Dann geht es um die Reparatur der Indexkonsistenz. Hier wird die gesamte Tabelle einer Cassandra-Tabelle durchsucht und nacheinander mit den Daten in Elasticsearch abgeglichen in Elasticsearch. Fügen Sie hinzu. Wenn es existiert, aber inkonsistent ist, beheben Sie es in Elasticsearch. Wie Elasticsearch die Indexierungsfunktion von Cassandra implementiert, wird in meinem nächsten Blog speziell erläutert, daher werde ich hier nicht näher darauf eingehen. Beim Durchlaufen der gesamten Cassandra-Tabelle ist Paging erforderlich, da die Datenmenge in der Tabelle zu groß ist und es unmöglich ist, Hunderte Millionen Daten gleichzeitig in den Speicher zu laden.
Das obige ist der detaillierte Inhalt vonJava implementiert ein Paging-Beispiel für die erweiterte Cassandra-Operation (Bild). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



