

Im vorherigen Artikel „Node-Entry-Szenario – Crawler“ haben wir die einfachste Node-Crawler-Implementierung vorgestellt. Dieser Artikel geht einen Schritt weiter und erläutert, wie man die Anmeldung umgeht und die Daten im Anmeldebereich crawlt .
Theoretische Grundlagen
So behalten Sie den Anmeldestatus bei
Wie macht der Browser das? >://www.php.cn/php/php-TVOS-denglu.html" target="_blank">Anmelden
So unterbrechen Sie, wenn eine Verifizierung vorliegt Code
http als A-Protokoll ohne
StatusDer Kern dieses Mechanismus ist die Sitzungs-ID (sessionId):
Wenn der Client den Server anfordert, stellt der Server fest, dass der Client die Sitzungs-ID nicht übergeben hat. Okay, dieser Typ ist neu , generieren Sie dafür eine Sitzungs-ID, speichern Sie sie im Speicher und geben Sie diese Sitzungs-ID an den Client zurück. 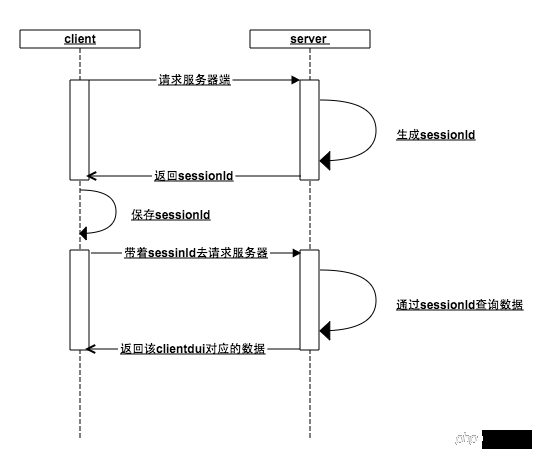
Der Client erhält die Sitzungs-ID vom Server, speichert sie lokal und bringt diese Sitzungs-ID mit nächste Anfrage, und der Server prüft den Speicher. Existiert diese Sitzungs-ID (Wenn der Benutzer in einem vorherigen Schritt auf die Anmeldeschnittstelle zugegriffen hat, wurde in diesem Moment die Seesions-ID im Speicher als Schlüssel
gespeichert , und die Benutzerdaten wurden im Speicher als Wert gespeichert), kann der Server die dem Client entsprechenden Daten basierend auf der eindeutigen Kennung von sessionId zurückgeben
Ob der Client oder der Server verliert die Sitzungs-ID, die vorherigen Schritte werden wiederholt. Niemand kennt jemanden mehr, beginnen Sie von vorne
Zuerst stellt der Client über die Sitzungs-ID eine Verbindung mit dem Server her. und dann stellt der Benutzer über den Client (Schlüssel-Wert-Paar aus Sitzungs-ID und Benutzerdaten) eine Verbindung mit dem Server her und behält so den Anmeldestatus bei Wie macht der Browser das? 🎜>
Tatsächlich folgt der Browser dem oben Gesagten. Was ist mit dem Mechanismusdesign? Es ist wahr!bs-sid.pngWas macht der Browser:1. Der Browser macht eine HTTP-Anfrage , wird das Cookie, das dem Domänennamen der Anforderungsadresse entspricht, zum HTTP-Anforderungsheader hinzugefügt (sofern das Cookie vom Benutzer nicht deaktiviert wurde). In der Abbildung oben enthält die erste Anforderung an den Server auch ein Cookie Header, aber es gibt noch keine SessionId im Cookie
-Cookie im Server-Antwortheader. Zu diesem Zweck stellt der Server die generierte SessionId ein in Set-cookieWenn der Browser die Set-Cookie-Anweisung empfängt, setzt er im Allgemeinen ein lokales Cookie mit dem Domänennamen der Anforderungsadresse als Schlüssel, wenn der Server die Set-Cookie-Anweisung zurückgibt. Cookie, die Ablaufzeit der SessionId ist so eingestellt, dass der Browser standardmäßig geschlossen wird. Sie läuft ab, wenn der Browser geöffnet wird, weshalb es sich um eine Sitzung vom Öffnen bis zum Schließen des Browsers handelt (einige Websites können auch so eingestellt werden, dass sie angemeldet bleiben). , und das Cookie läuft nicht lange ab)
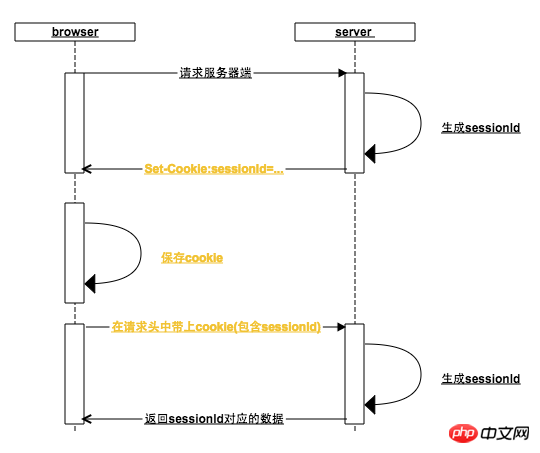
3. Wenn der Browser erneut geöffnet wird, enthält das Cookie im Anforderungsheader bereits die Sitzungs-ID Wenn der Benutzer die Anmeldeschnittstelle schon einmal besucht hat, können die Benutzerdaten anhand der Sitzungs-ID
Es gibt keinen Beweis, hier ein Beispiel:
1). Anmeldeseite, die vonchr
ome geöffnet wurde, um alle Dateien unter http://www.jianshu.com im Anwendungs-Cookie zu finden, geben Sie das Netzwerkelement ein und aktivieren Sie das Kontrollkästchen „Protokoll beibehalten“ (sonst können Sie es nicht sehen). (das vorherige Protokoll, nachdem die Seite umgeleitet wurde)
2). Aktualisieren Sie dann die Seite und suchen Sie die Anmeldeoberfläche. Der Antwortheader enthält viele Set-CookiesAnmelden
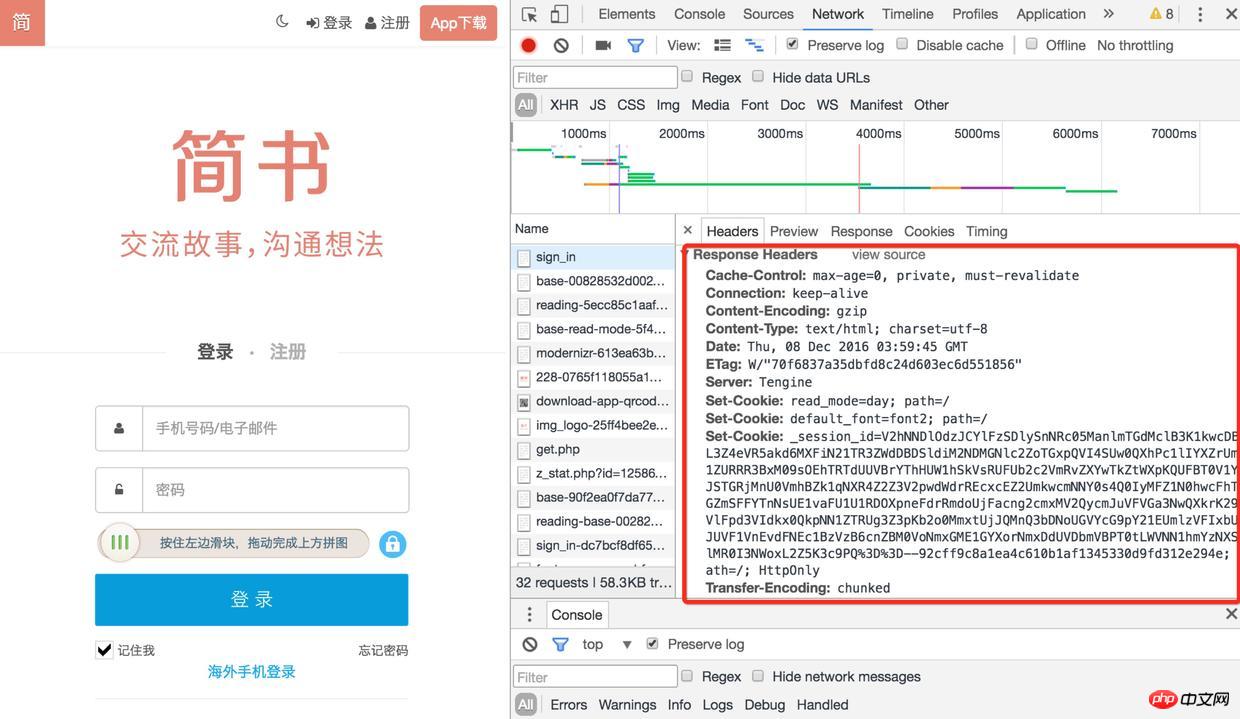
Anmelden
3). Wenn Sie das Cookie erneut überprüfen, wurde die Sitzungs-ID gespeichert und Sie können sie beim nächsten Mal anfordernSonstiges Bei der Nutzung der Schnittstelle (z. B. Abrufen des Bestätigungscodes, Anmelden) wird diese Sitzungs-ID angezeigt. Nach dem Anmelden werden die Informationen des Benutzers auch mit der Sitzungs-ID verknüpft
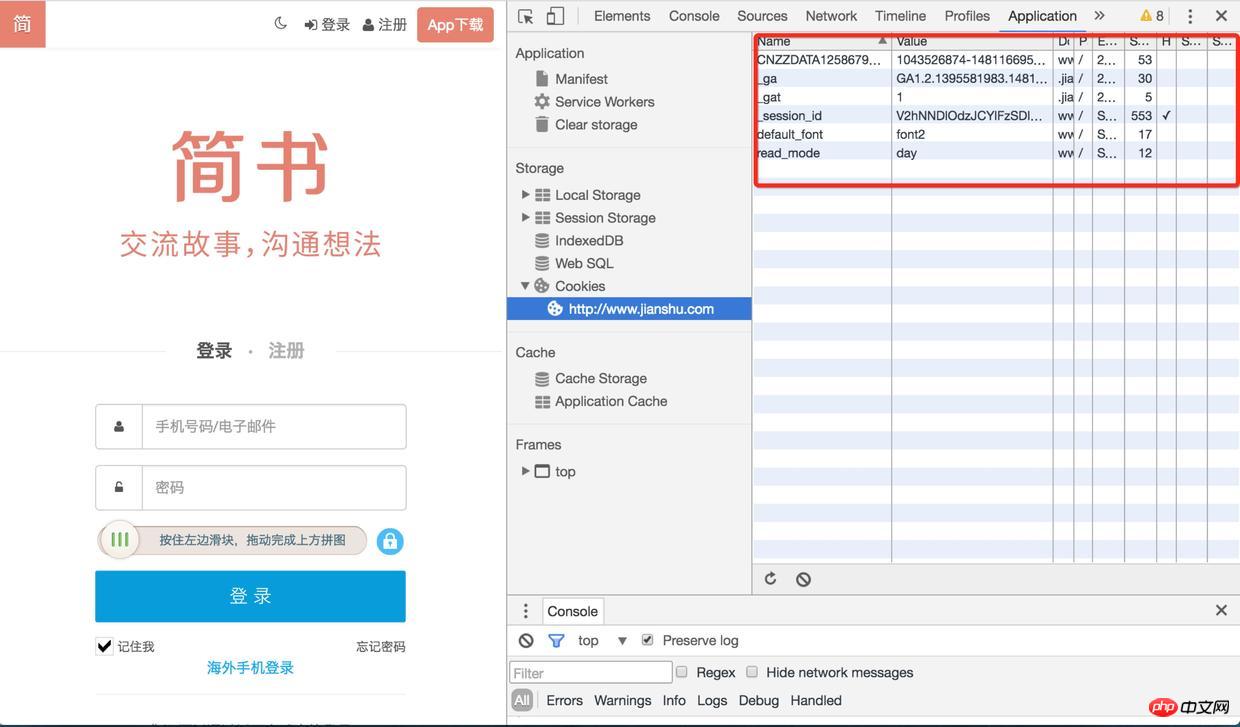
Anmelden
Wir müssen den Arbeitsmodus des Browsers simulieren und die Daten im Login crawlen Bereich der Website
Ich habe einen ohne Verifizierung gefunden. Testen Sie die Website mit dem Verifizierungscode. Wenn ein Verifizierungscode vorhanden ist, ist die Identifizierung des Verifizierungscodes beteiligt (die Anmeldung wird nicht berücksichtigt, die Komplexität des Verifizierungscodes ist beeindruckend). . Im nächsten Abschnitt wird erklärt:
// 浏览器请求报文头部部分信息
var browserMsg={
"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.71 Safari/537.36",
'Content-Type':'application/x-www-form-urlencoded'
};
//访问登录接口获取cookie
function getLoginCookie(userid, pwd) {
userid = userid.toUpperCase();
return new Promise(function(resolve, reject) {
superagent.post(url.login_url).set(browserMsg).send({
userid: userid,
pwd: pwd,
timezoneOffset: '0'
}).redirects(0).end(function (err, response) {
//获取cookie
var cookie = response.headers["set-cookie"];
resolve(cookie);
});
});
}Sie müssen eine Anfrage unter Chrome erfassen, um einige Anfrage-Header-Informationen zu erhalten , da der Server diese Anforderungsheaderinformationen möglicherweise überprüfen kann. Beispielsweise habe ich auf der Website, mit der ich experimentiert habe, den User-Agent zunächst nicht übergeben. Der Server stellte fest, dass die Anfrage nicht vom Server stammte, und gab eine Reihe von Fehlermeldungen zurück Richten Sie den User-Agent ein und geben Sie vor, ein Chrome-Browser zu sein. ~~
Superagent ist eine clientseitige HTTP-Anforderungsbibliothek, mit der Sie problemlos Anfragen senden und Cookies verarbeiten können (Rufen Sie http.request selbst auf, um die Header-Felddaten zu bedienen. Dies ist nicht so praktisch. Nachdem Sie das Set-Cookie erhalten haben, müssen Sie es in ein geeignetes Format-Cookie zusammensetzen.) weitergeleitet(0) ist hauptsächlich so eingestellt, dass keine Weiterleitung erfolgt
function getData(cookie) {
return new Promise(function(resolve, reject) {
//传入cookie
superagent.get(url.target_url).set("Cookie",cookie).set(browserMsg).end(function(err,res) {
var $ = cheerio.load(res.text);
resolve({
cookie: cookie,
doc: $
});
});
});
}Nachdem Sie im vorherigen Schritt das Set-Cookie erhalten haben, übergeben Sie es es in der getData-Methode, nachdem sie über den Superagenten auf die Anforderung festgelegt wurde (set-cookie wird in ein Cookie formatiert), können Sie normalerweise die Daten im Login abrufen
In tatsächlichen Szenarien Es kann sein, dass es nicht so reibungslos läuft. Da verschiedene Websites unterschiedliche Sicherheitsmaßnahmen haben, müssen einige Websites möglicherweise zuerst ein Token anfordern, andere müssen Parameter verschlüsseln und andere verfügen über höhere Sicherheit und Anti-Replay Mechanismen. Bei direktionalen Crawlern erfordert dies eine detaillierte Analyse des Verarbeitungsmechanismus der Website. Wenn Sie es nicht umgehen können, stoppen Sie es~~
Aber es reicht immer noch aus, um mit allgemeinen Inhalten und Informationswebsites umzugehen
Was über die obige Methode angefordert wird, ist nur ein Stück HTMLString Hier ist die alte Methode, um den String zu laden, und Sie können ein jquery dom. >Object, Sie können dom wie jquery bedienen. Dies ist wirklich ein Artefakt, das mit Gewissen gemacht wurde! 3. Wie kann ich den Bestätigungscode knacken, wenn es einen gibt?
Zhihu Login
Tesseract ist das Open-Source-OCR-Erkennungstool von Google. Obwohl es nichts mit Node zu tun hat, kann es mit Node geplant und verwendet werden 🎜 >node.js
implementiert die einfache Erkennung von VerifizierungscodesAuch wenn Graphicsmagick zur Vorverarbeitung von Bildern
verwendet wird, kann es aus diesem Grund keine hohe Erkennungsrate garantieren ist immer noch möglich. Um Tesseract zu trainieren, lesen Sie: Verwenden Sie das jTessBoxEditor-Tool, um Tesseract3.02.02-Beispiele zu trainieren, um die Erkennungsrate des Bestätigungscodes zu verbessernOb Sie eine hohe Erkennungsrate erreichen können, hängt von Ihrem Charakter ab~~~
4. Erweiterung Es gibt eine einfachere Möglichkeit, den Anmeldestatus zu umgehen, nämlich PhantomJS, einen Open-Source-Server, der auf WebkitDa es das Verhalten
des Browsers vollständig simuliert, müssen Sie sich überhaupt nicht um set-cookie und cookie kümmern. Sie müssen nur den Klickvorgang des Benutzers simulieren (natürlich, wenn Es gibt einen Bestätigungscode, den Sie noch identifizieren müssen)Diese Methode ist nicht ohne Mängel. Sie simuliert das Verhalten des Browsers vollständig, was bedeutet, dass keine Anfrage verpasst wird und JS, CSS und Bilder geladen werden müssen, die Sie möglicherweise nicht benötigen 🎜> Für Ressourcen müssen Sie auf mehrere Seiten klicken, um zur Zielseite zu gelangen, was weniger effizient ist als der direkte Zugriff auf die Ziel-URL
Suchen Sie bei Interesse5. Zusammenfassung
Sie können gerne eine Nachricht zur Diskussion hinterlassen ein Like~~
Das obige ist der detaillierte Inhalt vonNode-Crawler für Fortgeschrittene – Anmelden. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So stellen Sie den binauralen Modus des Bluetooth-Headsets wieder her
So stellen Sie den binauralen Modus des Bluetooth-Headsets wieder her
 Welcher Browser ist Edge?
Welcher Browser ist Edge?
 Win10 unterstützt die Festplattenlayoutlösung der Uefi-Firmware nicht
Win10 unterstützt die Festplattenlayoutlösung der Uefi-Firmware nicht
 So verwenden Sie die Diktatfunktion in Python
So verwenden Sie die Diktatfunktion in Python
 Was sind die Unterschiede zwischen Hibernate und Mybatis?
Was sind die Unterschiede zwischen Hibernate und Mybatis?
 Was soll ich tun, wenn iS nicht starten kann?
Was soll ich tun, wenn iS nicht starten kann?
 Was bedeutet BBS?
Was bedeutet BBS?
 Vor- und Nachteile kostenloser Website-Server im Ausland
Vor- und Nachteile kostenloser Website-Server im Ausland








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



