

1. Einführung
Letzte Woche musste ich einige allgemeine Inhalte des Projekts verstehen, aber ich war verwirrt über den xml-Parsing-Teil, also hier Ich werde einige der Kenntnisse aufzeichnen, die ich über das XML-Parsen gelernt habe.
2. Analyse
android Es gibt drei Haupttypen von XML-Parsern in , DOM-Parser, SAX-Parser und Pull-Parser
DOM(Dokument
Object Model) ist ein ObjectModel für XML-Dokumente, mit dem direkt auf XML-Dokumente in jedem Teil zugegriffen werden kann. Es lädt den Inhalt sofort in den Speicher und generiert keine Rückrufe und keine komplexe Statusverwaltung. Der Nachteil besteht darin, dass das Laden großer Dokumente nicht empfohlen wird Große Dokumente. Das Parsen dieser Struktur erfordert normalerweise das Laden des gesamten Dokuments und das Erstellen einer Baumstruktur vor dem Abrufen und Aktualisieren von Knoteninformationen Lesen, suchen, ändern, hinzufügen und
löschenusw. So funktioniert DOM: Bei der Bearbeitung einer XML-Datei muss die Datei zunächst analysiert und in unabhängige Elemente unterteilt werden, Attribute und Kommentare usw., und dann kann die XML-Datei im Speicher in Form eines Knotenbaums verarbeitet werden, was bedeutet, dass Sie über den Knotenbaum auf den Inhalt des Dokuments zugreifen können und ändern Sie das Dokument nach Bedarf Häufig verwendete DOM-Schnittstellen
und Klassen:Dokument: Die Schnittstelle definiert eine Reihe von Methoden zum Analysieren und Erstellen von DOM-Dokumenten Wurzel des Dokumentenbaums und die Basis für den Betrieb von
Knoten: Diese Schnittstelle ermöglicht die Verarbeitung und den Erhalt von Knoten- und Unterknotenwerten Element: Diese Schnittstelle erbt die Node-Schnittstelle und stellt Methoden zum Abrufen und Ändern von XML-Elementnamen und -Attributen bereit.
ListDOMParser: Diese Klasse ist die DOM-Parser-Klasse in Apaches Xerces, die XML-Dateien direkt analysieren kann
2. SAX-Analyse
SAX (Einfache API
für XML) Bei Verwendung der Streaming-Verarbeitung werden keine Informationen aufgezeichnet über den gelesenen Inhalt. Es handelt sich um eine XML-API, die -Ereignisse als
-Treiber verwendet. Sie verfügt über eine schnelle Analysegeschwindigkeit und benötigt weniger Speicher. Verwenden Sie dazu dieRückruffunktion
. Der Nachteil besteht darin, dass ein Rollback nicht möglich ist, da es ereignisgesteuert ist.Ereignisverarbeitungsmodus, der hauptsächlich mit Ereignisquellen und Ereignisprozessoren arbeitet. Wenn die Ereignisquelle ein Ereignis generiert, rufen Sie die entsprechende Verarbeitungsmethode des Ereignisprozessors auf, und ein Ereignis kann verarbeitet werden. Wenn die Ereignisquelle eine bestimmte Methode im Ereignishandler aufruft, muss sie auch die Statusinformationen des entsprechenden Ereignisses an den Ereignishandler übergeben, damit der Ereignishandler sein eigenes Verhalten
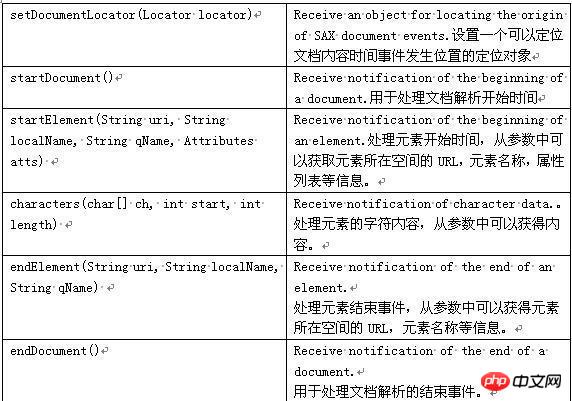
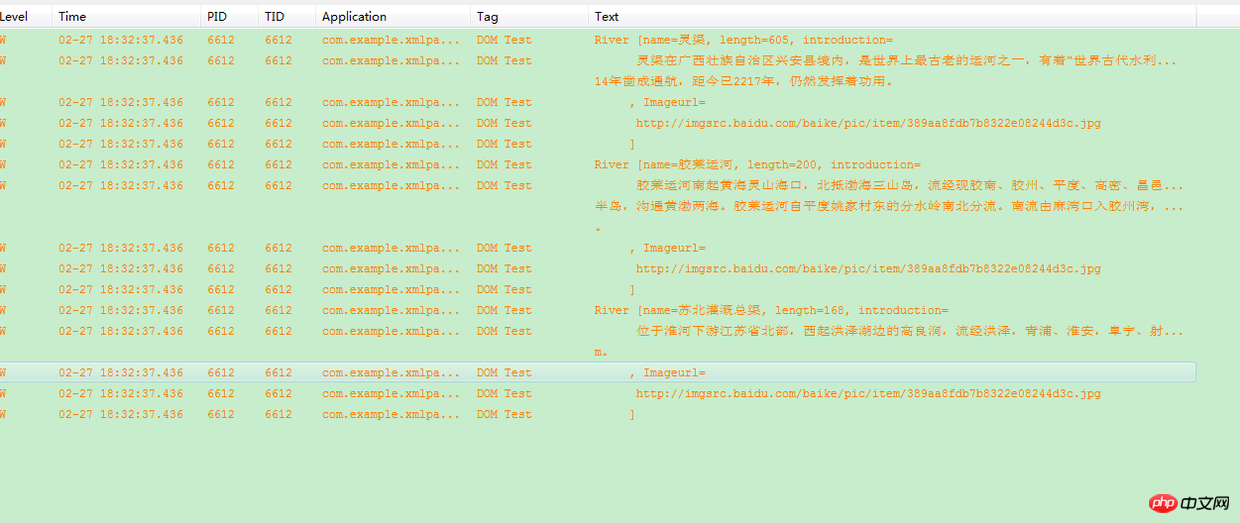
basierend auf dem bereitgestellten Ereignis entscheiden kann Information. Funktionsprinzip von SAX: SAX scannt das Dokument nacheinander und benachrichtigt die Ereignisverarbeitungsmethode beim Scannen über den Anfang und das Ende des Dokuments, den Anfang und das Ende des Elements sowie den Inhalt des Elements (Zeichen). usw. Methode zum Durchführen der entsprechenden Verarbeitung und anschließendes Weiterscannen, um das Scannen des Dokuments zu beenden. Häufig verwendete SAX-Schnittstellen und -Klassen: Attribute: werden verwendet, um die Anzahl, den Namen und den Wert von Attributen abzurufen. ContentHandler: Definiert Ereignisse, die mit dem Dokument selbst verknüpft sind (z. B. öffnende und schließende Tags). Die meisten Bewerbungen melden sich für diese Veranstaltungen an. DTDHandler: Definiert Ereignisse, die mit DTD verknüpft sind. Es werden nicht genügend Ereignisse definiert, um die DTD vollständig zu melden. Wenn eine Analyse der DTD erforderlich ist, verwenden Sie den optionalen DeclHandler. DeclHandler ist eine Erweiterung von SAX. Nicht alle Parser unterstützen es. EntityResolver: Definiert Ereignisse, die mit dem Laden von Entitäten verbunden sind. Für diese Veranstaltungen melden sich nur wenige Anmeldungen an. ErrorHandler: Fehlerereignisse definieren. Viele Anwendungen registrieren diese Ereignisse, um Fehler auf ihre eigene Weise zu melden. DefaultHandler: Stellt die Standardimplementierung dieser Schnittstellen bereit. In den meisten Fällen ist es für eine Anwendung einfacher, DefaultHandler zu erweitern und die relevanten Methoden zu überschreiben, als eine Schnittstelle direkt zu implementieren. Das Folgende ist eine Teilbeschreibung: SAX-Prozessorbeschreibung Erklärung einiger gängiger Methoden Daher verwenden wir normalerweise XmlReader und DefaultHandler, um XML-Dokumente zu analysieren. SAX-Parsing-Prozess: 3. Pull-Analyse Pull ist in das Android-System integriert. Es ist auch die offizielle Methode zum Parsen von Layoutdateien. Pull ähnelt in gewisser Weise SAX und beide bieten ähnliche Ereignisse, wie z. B. Startelemente und Endelemente. Der Unterschied besteht darin, dass der Ereignistreiber von SAX die entsprechende Methode zurückruft. Sie müssen die Rückrufmethode bereitstellen und dann automatisch die entsprechende Methode innerhalb von SAX aufrufen. Der Pull-Parser muss keine Auslösemethode bereitstellen. Denn das von ihm ausgelöste Ereignis ist keine Methode, sondern eine Zahl. Es ist einfach zu bedienen und effizient. Android empfiehlt Entwicklern offiziell die Verwendung der Pull-Parsing-Technologie. Die Pull-Parsing-Technologie ist eine von Dritten entwickelte Open-Source-Technologie und kann auch auf die JavaSE-Entwicklung angewendet werden. Die von Pull zurückgegebene : liest die Anweisung von XML und gibt START_DOCUMENT zurück; Lesen Sie das End-Tag von XML und geben Sie END_TAG zurück; Lesen Sie den Text von XML und geben Sie TEXT zurück; So funktioniert Pull: Pull stellt ein Startelement und ein Endelement bereit. Wenn ein Element startet, können wir den Parser aufrufen. Text extrahiert alle Zeichendaten aus dem XML-Dokument. Wenn die Interpretation eines Dokuments endet, wird automatisch das EndDocument-Ereignis generiert. Häufig verwendete XML-Pull-Schnittstellen und -Klassen: XmlPullParserFactory: Diese Klasse wird zum Erstellen von XML-Pull-Parsern in der XMPULL V1-API verwendet. XmlPullParser : Löst einen einzelnen Fehler im Zusammenhang mit dem XML-Pull-Parser aus. Pull-Parsing-Prozess: start_document --> end_tag -->end_tag In Android gibt es einen vierten Weg: android.util.Xml-Klasse In der Android-API, Android. util. Die XML-Klasse kann auch XML-Dateien analysieren. Sie müssen auch einen Handler schreiben, um die XML-Analyse durchzuführen, aber sie ist einfacher zu verwenden als SAX, wie unten gezeigt: Mit Android . util. XML implementiert XML-Parsing: MyHandler myHandler=new MyHandler0 android. util. Xm1. parse(url.openC0nnection().getlnputStream(), set Der Lingqu-Kanal liegt im Kreis Xing'an in der Autonomen Region Guangxi der Zhuang. Er ist einer der ältesten Kanäle der Welt und gilt als „die Perle der antiken Wasserschutzarchitektur der Welt“. In der Antike war der Ling-Kanal als Qin-Zhuo-Kanal, Ling-Kanal, Dou-Fluss und Xing'an-Kanal bekannt. Er wurde 214 v. Chr. gebaut und für die Schifffahrt freigegeben. db7b8322e08244d3c.jpg & lt; Die Insel Sea Sanshan, die durch Jiaoan, Jiaozhou, Pingdu, Gao Mi, Changyi, Laizhou usw. fließt, mit einer Beckenfläche von 5.400 Quadratkilometern verläuft von Norden nach Süden durch die Shandong-Halbinsel und verbindet das Gelbe und das Bohai-Meer . Der Jiaolai-Kanal teilt sich an der Wasserscheide östlich des Dorfes Pingdu Yaojia von Norden nach Süden. Der südliche Fluss fließt von Mawankou in die Jiaozhou-Bucht und ist der 30 Kilometer lange Nanjiolai-Fluss. Der Nordstrom fließt von Haicangkou in die Laizhou-Bucht und ist der mehr als 100 Kilometer lange Beijiaolai-Fluss. 🎜> Distrikt), ein großer künstlicher Flusskanal, der das Meer vom Biandang -Hafen im Osten vom Meer erreicht. Die Gesamtlänge beträgt 168 km. http://imgsrc.baidu.com/baike/pic/item/389aa8fdb7b8322e08244d3c.jpg Wir müssen zum Speichern ein Flussobjekt verwenden Daten zur Erleichterung der Beobachtung von Knoteninformationen und zur Abstraktion der River-Klasse class String Ganzzahl url public String getName() { } } public void setLength(Integer length) { this.introduction = Introduction; Die spezifischen Verarbeitungsschritte bei der Verwendung der DOM-Analyse sind: 1 Verwenden Sie zuerst DocumentBuilderFactory, um eine DocumentBuilderFactory-Instanz zu erstellen 2 Verwenden Sie dann DocumentBuilderFactory, um DocumentBuilder zu erstellen 3 und dann das XML-Dokument (Dokument) laden, 4 und dann den Wurzelknoten (Element) des Dokuments abrufen, 5 und dann den Wurzelknoten abrufen Liste aller untergeordneten Knoten (NodeList), 6 und verwenden Sie sie dann, um den Knoten abzurufen, der in der Liste der untergeordneten Knoten gelesen werden muss. Als nächstes beginnen wir, das XML-Dokumentobjekt zu lesen und es zur Liste hinzuzufügen: Der Code lautet wie folgt: Hier verwenden wir river.xml in Assets-Datei, dann müssen Sie diese XML-Datei lesen und den Eingabestream zurückgeben. Die Lesemethode lautet: inputStream=this.context.getResources().getAssets().open(fileName); Der Parameter ist natürlich der XML-Dateipfad Der Standardwert ist Assets. Das Verzeichnis ist das Stammverzeichnis. Dann können Sie die Parse-Methode des DocumentBuilder-Objekts verwenden, um den Eingabestream zu analysieren und das Dokumentobjekt zurückzugeben, und dann die Knotenattribute des Dokumentobjekts durchlaufen. /*** DOM-Parsing-XML-Methode * @param filePath * @return */ private ListDOMfromXML(String filePath) { ArrayListlist = new ArrayList(); DocumentBuilderFactory Factory = null; DocumentBuilder builder = null; Document document = null ; InputStream inputStream = null; //Parser erstellen factory = DocumentBuilderFactory.newInstance(); try { builder = Factory.newDocumentBuilder(); //Suchen Sie die XML-Datei und laden Sie sie inputStream = this.getResources().getAssets().open(filePath);//Standard nach getAssets Das Stammverzeichnis ist asset document = builder.parse(inputStream); //Suche das Stammelement Element root=document.getDocumentElement(); NodeList nodes=root.getElementsByTagName(RIVER); //Alle untergeordneten Knoten des Wurzelknotens durchlaufen, alle Flüsse unter Flüssen River river = null; for (int i = 0; i < nodes.getLength(); i++) { river = new River(); //Fluss abrufen element node Element riverElement = (Element) nodes.item(i); //Legen Sie die Namens- und Längenattributwerte in river river fest. setName(riverElement.getAttribute("name") ); river.setLength(Integer.parseInt(riverElement.getAttribute("length"))); //Untertags abrufen Element Introduction = (Element) riverElement.getElementsByTagName(INTRODUCTION).item(0); Element imageurl = (Element) riverElement.getElementsByTagName(IMAGEURL).item(0); //Legen Sie die Einführungs- und Bildurl-Attribute fest river.setIntroduction(introduction.getFirstChild().getNodeValue()); river.setImageurl(imageurl.getFirstChild().getNodeValue( )); list.add (river); } } Catch (ParserConfigurationException e) { // TODO Automatisch generierter Catch-Block e.print StackTrace(); } Catch (IOException e) { // TODO Automatisch generierter Catch-Block e.printStackTrace(); } Catch (SAXException e) { // TODO Automatisch generierter Catch-Block e.printStackTrace(); } for ( River river : list) { Log.w("DOM Test", river.toString()); } Rückgabeliste; } wird hier zur Liste hinzugefügt, und dann drucken wir sie mit log aus. Wie in der Abbildung gezeigt: XML-Analyseergebnisse Verwenden Sie SAX Parsen Die spezifischen Verarbeitungsschritte sind: 1 Erstellen Sie ein SAXParserFactory-Objekt 2 Geben Sie einen SAXParser-Parser gemäß der Methode SAXParserFactory.newSAXParser() zurück 3 Gemäß SAXParser Der Parser erhält das Ereignisquellobjekt XMLReader 4 Instanziiert ein DefaultHandler-Objekt 5 Verbindet das Ereignisquellobjekt XMLReader mit der Ereignisverarbeitungsklasse DefaultHandler 6 Aufrufe Die Parse-Methode von XMLReader aus den aus der Eingabequelle 7 erhaltenen XML-Daten gibt die Datensatz-Kombination zurück, die wir über DefaultHandler benötigen. Der Code lautet wie folgt: /** * SAX analysiertes XML * @param filePath * @return */ private ListSAXfromXML(String filePath) { ArrayListlist = new ArrayList(); //Parser erstellen SAXParserFactory Factory = SAXParserFactory.newInstance(); SAXParser parser = null; XMLReader xReader = null; versuchen Sie { parser = Factory.newSAXParser(); //Holen Sie sich die Datenquelle xReader = parser.getXMLReader(); //Setzen Sie den Prozessor RiverHandler handler = new RiverHandler(); xReader.setContentHandler(handler); //Xml-Datei analysieren xReader.parse(new InputSource(this.getAssets().open(filePath)))); list = handler.getList(); } Catch (ParserConfigurationException e) { e.printStackTrace(); } Catch (SAXException e) { e.printStackTrace(); } Catch (IOException e) { e.printStackTrace(); } for (River river : list) { Log.w("DOM Test", river.toString() ); } Rückgabeliste; }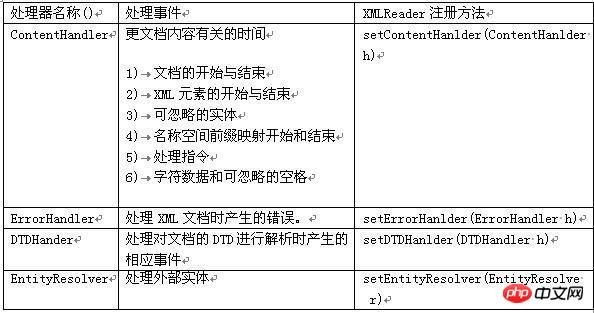
Lesen Sie das Start-Tag von XML und geben Sie START_TAG zurück;
XmlSerializer: Es handelt sich um eine Schnittstelle, die die Reihenfolge von XML-Informationssätzen definiert.
(Ich habe sie nicht verwendet)
String Imageurl ;//
return
Das obige ist der detaillierte Inhalt vonXML-Analyse in Android. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Was tun, wenn das Installationssystem die Festplatte nicht findet?
Was tun, wenn das Installationssystem die Festplatte nicht findet?
 Zu welcher Marke gehört das OnePlus-Handy?
Zu welcher Marke gehört das OnePlus-Handy?
 So behalten Sie die Anzahl der Dezimalstellen in C++ bei
So behalten Sie die Anzahl der Dezimalstellen in C++ bei
 MySQL-Backup-Datenmethode
MySQL-Backup-Datenmethode
 So richten Sie den virtuellen Speicher Ihres Computers ein
So richten Sie den virtuellen Speicher Ihres Computers ein
 Ist ein WLAN-Signalverstärker nützlich?
Ist ein WLAN-Signalverstärker nützlich?
 Drei Möglichkeiten, einen Thread in Java zu beenden
Drei Möglichkeiten, einen Thread in Java zu beenden
 Welche Datentypen gibt es?
Welche Datentypen gibt es?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



