
 Backend-Entwicklung
Python-Tutorial
Grundlegende Operationen von DataFrame, eingeführt von der Pandas-Bibliothek
Backend-Entwicklung
Python-Tutorial
Grundlegende Operationen von DataFrame, eingeführt von der Pandas-Bibliothek
Grundlegende Operationen von DataFrame, eingeführt von der Pandas-Bibliothek

Wie lösche ich Listen leeren Zeichen?
Die einfachste Methode: new_list = [ x for x in li if x != '' ]
Heute ist der 1. Mai.
In diesem Teil werden hauptsächlich die grundlegenden Operationen in Pandas basierend auf den beiden vorherigen Datenstrukturen untersucht.
设有DataFrame结果的数据a如下所示: a b c one 4 1 1 two 6 2 0 three 6 1 6
1. Daten anzeigen (die Methode zum Anzeigen von Objekten gilt auch für Serien)
1. Zeigen Sie die ersten xx Zeilen an von DataFrame Oder die letzten xx Zeilen
a=DataFrame(data);
a.head(6) bedeutet, dass die ersten 6 Datenzeilen angezeigt werden head() werden alle Daten angezeigt.
a.tail(6) bedeutet, dass die letzten 6 Datenzeilen angezeigt werden. Wenn in tail() keine Parameter vorhanden sind, werden alle Daten angezeigt.
2. Zeigen Sie den Index, die Spalten und die Werte von DataFrame an
a.index a.values und dann
3.describe()FunktionFür eine schnelle statistische Zusammenfassung von Daten
a.describe() führt Statistiken für jede Datenspalte durch, einschließlich Anzahl, Mittelwert, Standard, jedes Quantil usw .
4. Transponieren Sie die Daten
a.T
5. Sortieren Sie die Achse
a.sortieren _index(axis=1,ascending=False);
wobei axis=1 bedeutet, alle Spalten von zu sortieren, und die folgenden Zahlen werden ebenfalls entsprechend verschoben. Das folgende aufsteigende = Falsch bedeutet, dass in absteigender Reihenfolge sortiert wird. Wenn der Parameter fehlt, ist die Standardeinstellung die aufsteigende Reihenfolge.
6. Sortieren Sie die Werte im DataFrame
a.sort(columns='x')
Das heißt, sortieren Sie die x-Spalte in a von klein nach groß . Beachten Sie, dass es sich nur um die x-Spalte handelt und die obige Sortierung nach Achse für alle Spalten gilt.
2. Wählen Sie Objekte aus
1. Wählen Sie die Daten bestimmter Spalten und Zeilen aus
a['x'] Dann wird die Spalte sein, deren Spalten x sind zurückgegeben, Beachten Sie, dass diese Methode jeweils nur eine Spalte zurückgeben kann. a.x bedeutet dasselbe wie a['x'].
Zeilendaten abrufen und
durch Aufteilen von [] auswählen. Beispiel: a[0:3] gibt die Daten der ersten drei Zeilen zurück.
2.loc wählt Daten über Tags aus
a.loc['one'] zeigt standardmäßig an, dass die Zeile mit Verhalten 'one' ausgewählt ist ;
a.loc[:,['a','b'] ] bedeutet, dass alle Zeilen und Spalten mit den Spalten a und b ausgewählt werden
a.loc[['one' , 'two'],['a','b']] bedeutet die Auswahl der beiden Zeilen 'one' und 'two' und der Spalten, deren Spalten a und b sind
a.loc['one'; ,'a'] hat die gleiche Wirkung wie a.loc[['one'],['a']], ersteres zeigt jedoch nur den entsprechenden Wert an, während letzteres die entsprechenden Zeilen- und Spaltenbeschriftungen anzeigt.
3.iloc wählt Daten direkt nach Standort aus
Dies ähnelt der Auswahl nach Beschriftung
a.iloc[1:2,1:2] wird angezeigt Die Daten in der ersten Zeile und der ersten Spalte; (der Wert nach dem Slice kann nicht abgerufen werden)
a.iloc[1:2] bedeutet, dass, wenn in der nachfolgenden Spalte kein Wert vorhanden ist, die Zeile Position ist standardmäßig als 1 ausgewählt. Die Daten;
a.iloc[[0,2],[1,2]] bedeuten, dass Sie die Daten entsprechend der Zeilenposition und Spaltenposition frei auswählen können .
4. Verwenden Sie Bedingungen, um
Verwenden Sie eine separate Spalte , um Daten auszuwählen.
a[a.c>0] bedeutet, Spalte c Daten auszuwählen größer als 0
Verwenden Sie where, um Daten auszuwählen
a[a>0] Tabelle wählt direkt alle Daten größer als 0 in a aus
Verwenden Sie isin(), um bestimmte Zeilen auszuwählen enthält bestimmte Werte in der Spalte
a1=a.copy()
a1[a1['one'].isin(['2','3']) ] In der Tabelle werden alle Zeilen angezeigt, die die Bedingung erfüllen: Der Wert in Spalte eins enthält „2“, „3“.
3. Einstellungswert (Zuweisung)
Die Zuweisungsoperation kann basierend auf der obigen Auswahloperation direkt zugewiesen werden.
Beispiel a.loc[:,['a','c']]=9 bedeutet, dass die Werte in allen Zeilen der Spalten a und c auf 9 gesetzt werden
a.iloc[:,[1, 3] ]=9 bedeutet auch, die Werte in allen Zeilen der Spalten a und c auf 9 zu setzen
Gleichzeitig können Sie weiterhin Bedingungen verwenden, um Werte direkt zuzuweisen
a[ a>0]=-a bedeutet, a zu setzen. Alle Zahlen größer als 0 werden in negative Werte umgewandelt
4. Verarbeitung fehlender Werte
Verwenden Sie in Pandas np.nan zum Ersetzen Fehlende Werte werden standardmäßig nicht in die Berechnung einbezogen.
1.reindex()-Methode
wird verwendet, um den Index auf der angegebenen Achse zu ändern/hinzufügen/zu löschen, dies A Eine Kopie der Originaldaten wird zurückgegeben.
a.reindex(index=list(a.index)+['fünf'],columns=list(a.columns)+['d'])
a.reindex(index=['one','five'],columns=list(a.columns)+['d'])
即用index=[]表示对index进行操作,columns表对列进行操作。
2.对缺失值进行填充
a.fillna(value=x)
表示用值为x的数来对缺失值进行填充
3.去掉包含缺失值的行
a.dropna(how='any')
表示去掉所有包含缺失值的行
五、合并
1.contact
contact(a1,axis=0/1,keys=['xx','xx','xx',...]),其中a1表示要进行进行连接的列表数据,axis=1时表横着对数据进行连接。axis=0或不指定时,表将数据竖着进行连接。a1中要连接的数据有几个则对应几个keys,设置keys是为了在数据连接以后区分每一个原始a1中的数据。
例:a1=[b['a'],b['c']]
result=pd.concat(a1,axis=1,keys=['1','2'])
2.Append 将一行或多行数据连接到一个DataFrame上
a.append(a[2:],ignore_index=True)
表示将a中的第三行以后的数据全部添加到a中,若不指定ignore_index参数,则会把添加的数据的index保留下来,若ignore_index=Ture则会对所有的行重新自动建立索引。
3.merge类似于SQL中的join
设a1,a2为两个dataframe,二者中存在相同的键值,两个对象连接的方式有下面几种:
(1)内连接,pd.merge(a1, a2, on='key')
(2)左连接,pd.merge(a1, a2, on='key', how='left')
(3)右连接,pd.merge(a1, a2, on='key', how='right')
(4)外连接, pd.merge(a1, a2, on='key', how='outer')
至于四者的具体差别,具体学习参考sql中相应的语法。
六、分组(groupby)
用pd.date_range函数生成连续指定天数的的日期
pd.date_range('20000101',periods=10)
def shuju():
data={
'date':pd.date_range('20000101',periods=10),
'gender':np.random.randint(0,2,size=10),
'height':np.random.randint(40,50,size=10),
'weight':np.random.randint(150,180,size=10)
}
a=DataFrame(data)
print(a)
date gender height weight
0 2000-01-01 0 47 165
1 2000-01-02 0 46 179
2 2000-01-03 1 48 172
3 2000-01-04 0 45 173
4 2000-01-05 1 47 151
5 2000-01-06 0 45 172
6 2000-01-07 0 48 167
7 2000-01-08 0 45 157
8 2000-01-09 1 42 157
9 2000-01-10 1 42 164
用a.groupby('gender').sum()得到的结果为: #注意在python中groupby(''xx)后要加sum(),不然显示
不了数据对象。
gender height weight
0 256 989
1 170 643此外用a.groupby('gender').size()可以对各个gender下的数目进行计数。
所以可以看到groupby的作用相当于:
按gender对gender进行分类,对应为数字的列会自动求和,而为字符串类型的列则不显示;当然也可以同时groupby(['x1','x2',...])多个字段,其作用与上面类似。
七、Categorical按某一列重新编码分类
如六中要对a中的gender进行重新编码分类,将对应的0,1转化为male,female,过程如下:
a['gender1']=a['gender'].astype('category')
a['gender1'].cat.categories=['male','female'] #即将0,1先转化为category类型再进行编码。
print(a)得到的结果为:
date gender height weight gender1
0 2000-01-01 1 40 163 female
1 2000-01-02 0 44 177 male
2 2000-01-03 1 40 167 female
3 2000-01-04 0 41 161 male
4 2000-01-05 0 48 177 male
5 2000-01-06 1 46 179 female
6 2000-01-07 1 42 154 female
7 2000-01-08 1 43 170 female
8 2000-01-09 0 46 158 male
9 2000-01-10 1 44 168 female所以可以看出重新编码后的编码会自动增加到dataframe最后作为一列。
八、相关操作
描述性统计:
1.a.mean() 默认对每一列的数据求平均值;若加上参数a.mean(1)则对每一行求平均值;
2.统计某一列x中各个值出现的次数:a['x'].value_counts();
3.对数据应用函数
a.apply(lambda x:x.max()-x.min())
表示返回所有列中最大值-最小值的差。
4.字符串相关操作
a['gender1'].str.lower() 将gender1中所有的英文大写转化为小写,注意dataframe没有str属性,只有series有,所以要选取a中的gender1字段。
九、时间序列
在六中用pd.date_range('xxxx',periods=xx,freq='D/M/Y....')函数生成连续指定天数的的日期列表。
例如pd.date_range('20000101',periods=10),其中periods表示持续频数;
pd.date_range('20000201','20000210',freq='D')也可以不指定频数,只指定起始日期。
此外如果不指定freq,则默认从起始日期开始,频率为day。其他频率表示如下:
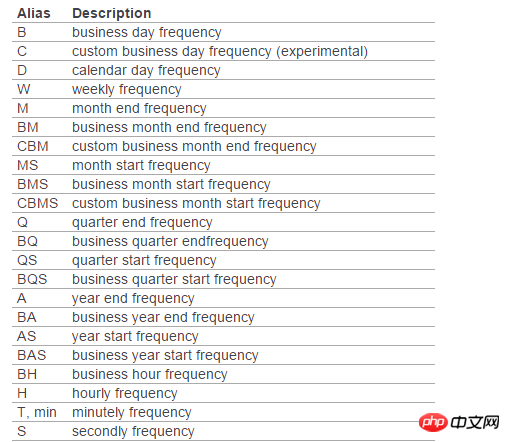
1.png
十、画图(plot)
在pycharm中首先要:import matplotlib.pyplot as plt
a=Series(np.random.randn(1000),index=pd.date_range('20100101',periods=1000))
b=a.cumsum()
b.plot()
plt.show() #最后一定要加这个plt.show(),不然不会显示出图来。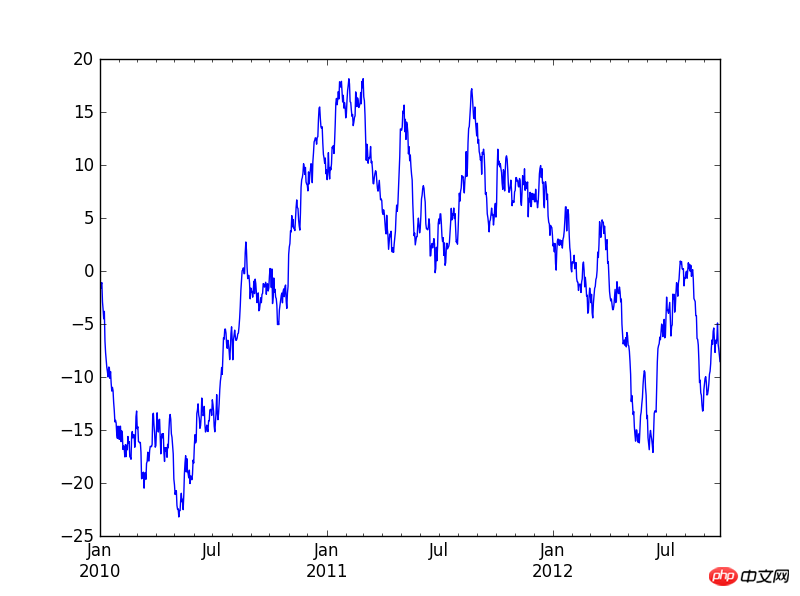
2.PNG
也可以使用下面的代码来生成多条时间序列图:
a=DataFrame(np.random.randn(1000,4),index=pd.date_range('20100101',periods=1000),columns=list('ABCD'))
b=a.cumsum()
b.plot()
plt.show()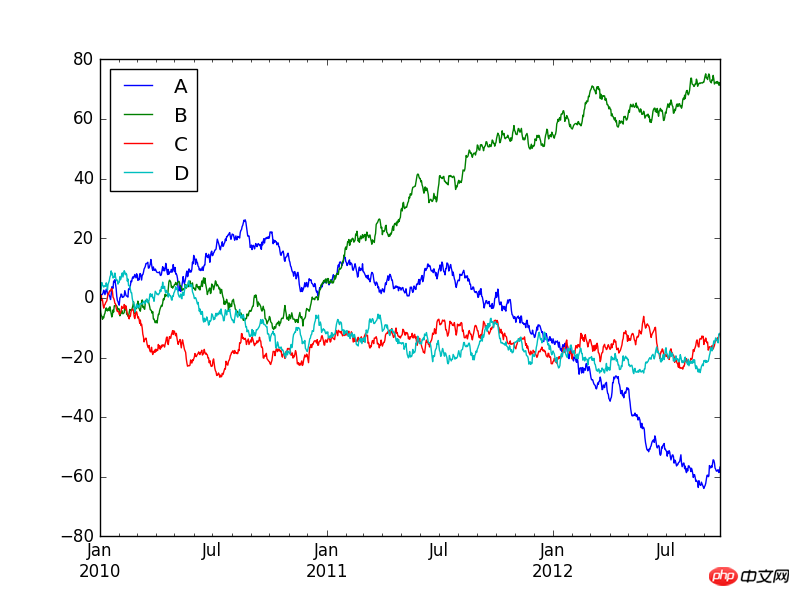
3.png
十一、导入和导出文件
写入和读取excel文件
虽然写入excel表时有两种写入xls和csv,但建议少使用csv,不然在表中调整数据格式时,保存时一直询问你是否保存新格式,很麻烦。而在读取数据时,如果指定了哪一张sheet,则在pycharm又会出现格式不对齐。
还有将数据写入表格中时,excel会自动给你在表格最前面增加一个字段,对数据行进行编号。
a.to_excel(r'C:\\Users\\guohuaiqi\\Desktop\\2.xls',sheet_name='Sheet1') a=pd.read_excel(r'C:\\Users\\guohuaiqi\\Desktop\\2.xls','Sheet1',na_values=['NA']) 注意sheet_name后面的Sheet1中的首字母大写;读取数据时,可以指定读取哪一张表中的数据,而 且对缺失值补上NA。 最后再附上写入和读取csv格式的代码: a.to_csv(r'C:\\Users\\guohuaiqi\\Desktop\\1.csv',sheet_name='Sheet1') a=pd.read_csv(r'C:\\Users\\guohuaiqi\\Desktop\\1.csv',na_values=['NA'])
Das obige ist der detaillierte Inhalt vonGrundlegende Operationen von DataFrame, eingeführt von der Pandas-Bibliothek. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1381
1381
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Wie man ein Pytorch -Modell auf CentOS trainiert
Apr 14, 2025 pm 03:03 PM
Effizientes Training von Pytorch -Modellen auf CentOS -Systemen erfordert Schritte, und dieser Artikel bietet detaillierte Anleitungen. 1.. Es wird empfohlen, YUM oder DNF zu verwenden, um Python 3 und Upgrade PIP zu installieren: Sudoyumupdatepython3 (oder sudodnfupdatepython3), PIP3Install-upgradepip. CUDA und CUDNN (GPU -Beschleunigung): Wenn Sie Nvidiagpu verwenden, müssen Sie Cudatool installieren
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Minio-Objektspeicherung: Hochleistungs-Bereitstellung im Rahmen von CentOS System Minio ist ein hochleistungsfähiges, verteiltes Objektspeichersystem, das auf der GO-Sprache entwickelt wurde und mit Amazons3 kompatibel ist. Es unterstützt eine Vielzahl von Kundensprachen, darunter Java, Python, JavaScript und Go. In diesem Artikel wird kurz die Installation und Kompatibilität von Minio zu CentOS -Systemen vorgestellt. CentOS -Versionskompatibilitätsminio wurde in mehreren CentOS -Versionen verifiziert, einschließlich, aber nicht beschränkt auf: CentOS7.9: Bietet einen vollständigen Installationshandbuch für die Clusterkonfiguration, die Umgebungsvorbereitung, die Einstellungen von Konfigurationsdateien, eine Festplattenpartitionierung und Mini
 So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
So wählen Sie die Pytorch -Version unter CentOS aus
Apr 14, 2025 pm 02:51 PM
Bei der Auswahl einer Pytorch -Version unter CentOS müssen die folgenden Schlüsselfaktoren berücksichtigt werden: 1. Cuda -Version Kompatibilität GPU -Unterstützung: Wenn Sie NVIDIA -GPU haben und die GPU -Beschleunigung verwenden möchten, müssen Sie Pytorch auswählen, der die entsprechende CUDA -Version unterstützt. Sie können die CUDA-Version anzeigen, die unterstützt wird, indem Sie den Befehl nvidia-smi ausführen. CPU -Version: Wenn Sie keine GPU haben oder keine GPU verwenden möchten, können Sie eine CPU -Version von Pytorch auswählen. 2. Python Version Pytorch
 So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
So installieren Sie Nginx in CentOS
Apr 14, 2025 pm 08:06 PM
Die Installation von CentOS-Installationen erfordert die folgenden Schritte: Installieren von Abhängigkeiten wie Entwicklungstools, PCRE-Devel und OpenSSL-Devel. Laden Sie das Nginx -Quellcode -Paket herunter, entpacken Sie es, kompilieren Sie es und installieren Sie es und geben Sie den Installationspfad als/usr/local/nginx an. Erstellen Sie NGINX -Benutzer und Benutzergruppen und setzen Sie Berechtigungen. Ändern Sie die Konfigurationsdatei nginx.conf und konfigurieren Sie den Hörport und den Domänennamen/die IP -Adresse. Starten Sie den Nginx -Dienst. Häufige Fehler müssen beachtet werden, z. B. Abhängigkeitsprobleme, Portkonflikte und Konfigurationsdateifehler. Die Leistungsoptimierung muss entsprechend der spezifischen Situation angepasst werden, z. B. das Einschalten des Cache und die Anpassung der Anzahl der Arbeitsprozesse.
