

Lassen Sie mich zunächst vorstellen, was Lastausgleich ist (aus der Enzyklopädie)
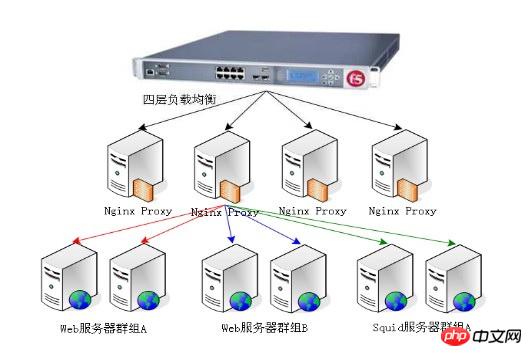
Der Lastausgleich basiert auf Mit der vorhandenen Netzwerkstruktur bietet es eine kostengünstige, effektive und transparente Methode zur Erweiterung der Bandbreite von Netzwerkgeräten und Servern, zur Erhöhung des Durchsatzes, zur Verbesserung der Netzwerkdatenverarbeitungsfunktionen sowie zur Verbesserung der Netzwerkflexibilität und -verfügbarkeit.
Lastausgleich, der englische Name ist Load Balance, was bedeutet, die Ausführung mehreren Betriebseinheiten wie Webservern, FTP-Servern, Unternehmensschlüsselanwendungsservern und anderen geschäftskritischen Servern usw. zuzuweisen um die Arbeit gemeinsam abzuschließen Aufgabe.
In diesem Artikel geht es um verschiedene Algorithmen zur „gleichmäßigen Verteilung von von außen an einen bestimmten Server gesendeten Anforderungen in einer symmetrischen Struktur“ und demonstriert die spezifische Implementierung jedes Algorithmus im Java-Code. OK, weiter unten Bevor wir zum Punkt kommen, schreiben Sie zunächst eine Klasse zur Simulation der IP-Liste:
import java.util.HashMap;
/**
* @author [email protected]
* @date 二月 07, 2017
*/
public class IpMap {
// 待路由的Ip列表,Key代表Ip,Value代表该Ip的权重
public static HashMap<String, Integer> serverWeightMap =
new HashMap<String, Integer>();
static
{
serverWeightMap.put("192.168.1.100", 1);
serverWeightMap.put("192.168.1.101", 1);
// 权重为4
serverWeightMap.put("192.168.1.102", 4);
serverWeightMap.put("192.168.1.103", 1);
serverWeightMap.put("192.168.1.104", 1);
// 权重为3
serverWeightMap.put("192.168.1.105", 3);
serverWeightMap.put("192.168.1.106", 1);
// 权重为2
serverWeightMap.put("192.168.1.107", 2);
serverWeightMap.put("192.168.1.108", 1);
serverWeightMap.put("192.168.1.109", 1);
serverWeightMap.put("192.168.1.110", 1);
}
}Das Prinzip des Round-Robin-Planungsalgorithmus besteht darin, Daten von zu senden Benutzeranfragen werden der Reihe nach internen Servern zugewiesen, beginnend bei 1 bis N (Anzahl der internen Server), und dann beginnt der Zyklus erneut. Der Vorteil des Algorithmus liegt in seiner Einfachheit. Er muss nicht den Status aller aktuellen Verbindungen aufzeichnen, es handelt sich also um eine zustandslose Planung.
Die Code-Implementierung sieht ungefähr wie folgt aus:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @author [email protected]
* @date 二月 07, 2017
*/
class RoundRobin {
private static Integer pos = 0;
public static String getServer()
{
// 重建一个Map,避免服务器的上下线导致的并发问题
Map<String, Integer> serverMap =
new HashMap<String, Integer>();
serverMap.putAll(IpMap.serverWeightMap);
// 取得Ip地址List
Set keySet = serverMap.keySet();
ArrayList keyList = new ArrayList();
keyList.addAll(keySet);
String server = null;
synchronized (pos)
{
if (pos > keySet.size())
pos = 0;
server = keyList.get(pos);
pos ++;
}
return server;
}
}Da die Adressliste in serverWeightMap dynamisch ist, können Maschinen jederzeit online, offline oder offline gehen, also in der Reihenfolge Um mögliche Parallelität zu vermeiden, besteht das Problem darin, dass eine neue lokale -Variable serverMap innerhalb der Methode erstellt werden muss. Kopieren Sie nun den Inhalt von serverMap in den lokalen Thread, um eine Änderung durch mehrere Threads zu vermeiden. Dies kann zu neuen Problemen führen, nachdem die Replikation nicht in serverMap berücksichtigt werden konnte. Das heißt, während dieser Serverauswahlrunde kann der Lastausgleichsalgorithmus nicht erkennen, ob neue Server oder Offline-Server hinzugefügt werden. Es spielt keine Rolle, ob Sie eine neue Adresse hinzufügen. Wenn ein Server offline geht oder abstürzt, greifen Sie möglicherweise auf eine nicht vorhandene Adresse zu. Daher muss der Dienstaufrufer über eine entsprechende Fehlertoleranzverarbeitung verfügen, z. B. die Neuinitiierung der Serverauswahl und des Anrufs.
Um die Reihenfolge der Serverauswahl sicherzustellen, muss die aktuell abgefragte Positionsvariable pos während des Betriebs gesperrt werden, sodass nur ein Thread gleichzeitig den Wert von pos ändern kann, andernfalls wann Die pos-Variable Wenn sie gleichzeitig geändert wird, kann die Reihenfolge der Serverauswahl nicht garantiert werden und es kann sogar dazu führen, dass das keyList-Array außerhalb der Grenzen liegt.
Der Vorteil der Polling-Methode besteht darin, dass sie versucht, ein absolutes Gleichgewicht bei der Anforderungsübertragung zu erreichen.
Der Nachteil der Abfragemethode besteht darin, dass ein erheblicher Preis gezahlt werden muss, um das absolute Gleichgewicht der Anforderungsübertragung zu erreichen, da eine schwere pessimistische Sperre synchronisiert werden muss, um den gegenseitigen Ausschluss von Pos-Variablenänderungen sicherzustellen Dies führt zu einem erheblichen Rückgang des gleichzeitigen Durchsatzes dieses Abfragecodes.
Durch den Zufallsalgorithmus des Systems wird einer der Server basierend auf dem Listengrößenwert des Back-End-Servers zufällig für den Zugriff ausgewählt. Aus der Wahrscheinlichkeitstheorie und der Statistik lässt sich erkennen, dass mit zunehmender Häufigkeit, mit der der Client den Server anruft,
der tatsächliche Effekt einer gleichmäßigeren Verteilung der Anrufe auf jeden Server im Backend immer näher kommt. Das ist das Ergebnis einer Umfrage.
Die Code-Implementierung der Zufallsmethode ist ungefähr wie folgt:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @author [email protected]
* @date 二月 07, 2017
*/
class Random {
public static String getServer()
{
// 重建一个Map,避免服务器的上下线导致的并发问题
Map<String, Integer> serverMap =
new HashMap<String, Integer>();
serverMap.putAll(IpMap.serverWeightMap);
// 取得Ip地址List
Set keySet = serverMap.keySet();
ArrayList keyList = new ArrayList();
keyList.addAll(keySet);
java.util.Random random = new java.util.Random();
int randomPos = random.nextInt(keyList.size());
return keyList.get(randomPos);
}
}Die allgemeine Codeidee stimmt mit der Abfragemethode überein. Zuerst wird die ServerMap und dann die Serverliste neu erstellt erhalten. Verwenden Sie bei der Auswahl eines Servers die Methode nextInt von Random, um einen Zufallswert im Bereich von 0~keyList.size() zu übernehmen und so zufällig eine Serveradresse aus der Serverliste abzurufen und zurückzugeben. Basierend auf der Wahrscheinlichkeits- und Statistiktheorie ist die Wirkung des Zufallsalgorithmus umso näher an der des Abfragealgorithmus, je größer der Durchsatz ist.
Die Idee des Quelladress-Hashs besteht darin, die IP-Adresse des Clients abzurufen, über die Hash-Funktion einen Wert zu berechnen und diesen Wert zum Vergleichen zu verwenden Serverliste Führen Sie eine Modulo-Operation für die Größe durch. Das Ergebnis ist die Seriennummer, mit der der Client auf den Server zugreifen möchte. Die Quelladress-Hash-Methode wird für den Lastausgleich verwendet. Clients mit derselben IP-Adresse werden für den Zugriff jedes Mal demselben Backend-Server zugeordnet, wenn die Backend-Serverliste unverändert bleibt.
Die Code-Implementierung des Quelladress-Hash-Algorithmus ist ungefähr wie folgt:
import java.util.ArrayList;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
/**
* @author [email protected]
* @date 二月 07, 2017
*/
class Hash {
public static String getServer()
{
// 重建一个Map,避免服务器的上下线导致的并发问题
Map<String, Integer> serverMap =
new HashMap<String, Integer>();
serverMap.putAll(IpMap.serverWeightMap);
// 取得Ip地址List
Set keySet = serverMap.keySet();
ArrayList keyList = new ArrayList();
keyList.addAll(keySet);
// 在Web应用中可通过HttpServlet的getRemoteIp方法获取
String remoteIp = "127.0.0.1";
int hashCode = remoteIp.hashCode();
int serverListSize = keyList.size();
int serverPos = hashCode % serverListSize;
return keyList.get(serverPos);
}
}Die ersten beiden Teile sind die gleichen wie die Abfragemethode und die Zufallsmethode. Der Unterschied liegt in der Routing-Teil. Erhalten Sie seinen Hash-Wert über die IP des Clients, also remoteIp, und modulieren Sie die Größe der Serverliste. Das Ergebnis ist der Index -Wert des ausgewählten Servers in der Serverliste.
Der Vorteil des Quelladressen-Hashings besteht darin, dass sichergestellt wird, dass dieselbe Client-IP-Adresse an denselben Backend-Server gehasht wird, bis sich die Backend-Serverliste ändert. Gemäß dieser Funktion kann eine zustandsbehaftete Sitzung zwischen Dienstkonsumenten und Dienstanbietern eingerichtet werden.
源地址哈希算法的缺点在于:除非集群中服务器的非常稳定,基本不会上下线,否则一旦有服务器上线、下线,那么通过源地址哈希算法路由到的服务器是服务器上线、下线前路由到的服务器的概率非常低,如果是session则取不到session,如果是缓存则可能引发"雪崩"。如果这么解释不适合明白,可以看我之前的一篇文章MemCache超详细解读,一致性Hash算法部分。
不同的后端服务器可能机器的配置和当前系统的负载并不相同,因此它们的抗压能力也不相同。给配置高、负载低的机器配置更高的权重,让其处理更多的请;而配置低、负载高的机器,给其分配较低的权重,降低其系统负载,加权轮询能很好地处理这一问题,并将请求顺序且按照权重分配到后端。加权轮询法的代码实现大致如下:
import java.util.*;
/**
* @author [email protected]
* @date 二月 07, 2017
*/
class WeightRoundRobin {
private static Integer pos;
public static String getServer()
{
// 重建一个Map,避免服务器的上下线导致的并发问题
Map<String, Integer> serverMap =
new HashMap<String, Integer>();
serverMap.putAll(IpMap.serverWeightMap);
// 取得Ip地址List
Set keySet = serverMap.keySet();
Iterator iterator = keySet.iterator();
List serverList = new ArrayList();
while (iterator.hasNext())
{
String server = iterator.next();
int weight = serverMap.get(server);
for (int i = 0; i < weight; i++)
serverList.add(server);
}
String server = null;
synchronized (pos)
{
if (pos > keySet.size())
pos = 0;
server = serverList.get(pos);
pos ++;
}
return server;
}
}与轮询法类似,只是在获取服务器地址之前增加了一段权重计算的代码,根据权重的大小,将地址重复地增加到服务器地址列表中,权重越大,该服务器每轮所获得的请求数量越多。
与加权轮询法一样,加权随机法也根据后端机器的配置,系统的负载分配不同的权重。不同的是,它是按照权重随机请求后端服务器,而非顺序。
import java.util.*;
/**
* @author [email protected]
* @date 二月 07, 2017
*/
class WeightRandom {
public static String getServer()
{
// 重建一个Map,避免服务器的上下线导致的并发问题
Map<String, Integer> serverMap =
new HashMap<String, Integer>();
serverMap.putAll(IpMap.serverWeightMap);
// 取得Ip地址List
Set keySet = serverMap.keySet();
Iterator iterator = keySet.iterator();
List serverList = new ArrayList();
while (iterator.hasNext())
{
String server = iterator.next();
int weight = serverMap.get(server);
for (int i = 0; i < weight; i++)
serverList.add(server);
}
java.util.Random random = new java.util.Random();
int randomPos = random.nextInt(serverList.size());
return serverList.get(randomPos);
}
}这段代码相当于是随机法和加权轮询法的结合,比较好理解,就不解释了。
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它是根据后端服务器当前的连接情况,动态地选取其中当前
积压连接数最少的一台服务器来处理当前的请求,尽可能地提高后端服务的利用效率,将负责合理地分流到每一台服务器。
前面几种方法费尽心思来实现服务消费者请求次数分配的均衡,当然这么做是没错的,可以为后端的多台服务器平均分配工作量,最大程度地提高服务器的利用率,但是实际情况是否真的如此?实际情况中,请求次数的均衡真的能代表负载的均衡吗?这是一个值得思考的问题。
上面的问题,再换一个角度来说就是:以后端服务器的视角来观察系统的负载,而非请求发起方来观察。最小连接数法便属于此类。
最小连接数算法比较灵活和智能,由于后端服务器的配置不尽相同,对于请求的处理有快有慢,它正是根据后端服务器当前的连接情况,动态地选取其中当前积压连接数最少的一台服务器来处理当前请求,尽可能地提高后端服务器的利用效率,将负载合理地分流到每一台机器。由于最小连接数设计服务器连接数的汇总和感知,设计与实现较为繁琐,此处就不说它的实现了。
Das obige ist der detaillierte Inhalt vonJava implementiert mehrere Lastausgleichsalgorithmen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



