

Codierungsprobleme haben Programmentwicklern schon immer Probleme bereitet, insbesondere in Java, da Java eine plattformübergreifende Sprache ist und häufig zwischen der Codierung auf verschiedenen Plattformen gewechselt wird. Als nächstes werden wir die Ursachen von Java-Codierungsproblemen vorstellen; die Unterschiede zwischen mehreren Codierungsformaten, die häufig in Java auftreten, erfordern eine Analyse der möglichen Codierungsprobleme bei der Entwicklung von Java; wie man das Codierungsformat einer HTTP-Anfrage steuert; wie man chinesische Codierungsprobleme usw. vermeidet.
kodieren Die kleinste Einheit zum Speichern von Informationen in einem Computer ist 1 Byte, also 8 Bit, sodass der Bereich der darstellbaren Zeichen 0 bis 255 beträgt.
Es sind zu viele Symbole zur Darstellung vorhanden und können nicht vollständig in 1 Byte dargestellt werden.
Computer bieten eine Vielzahl von Übersetzungsmethoden. Zu den gängigen gehören ASCII, ISO-8859-1, GB2312, GBK, UTF-8, UTF-16 usw. Diese legen alle die Konvertierungsregeln fest. Nach diesen Regeln kann der Computer unsere Charaktere korrekt darstellen. Diese Kodierungsformate werden im Folgenden vorgestellt:
ASCII-Code
Insgesamt gibt es 128, dargestellt durch die unteren 7 Bits von 1 Byte, 0 bis 31 sind Steuerzeichen wie Zeilenvorschub, Wagenrücklauf, Löschen usw., 32 bis 126 sind Druckzeichen, die über die Tastatur eingegeben werden können angezeigt.
ISO-8859-1
128 Zeichen reichen offensichtlich nicht aus, daher wurde die ISO-Organisation auf Basis von ASCII erweitert. Sie sind ISO-8859-1 bis ISO-8859-15. Ersteres deckt die meisten Zeichen ab und wird am häufigsten verwendet. Bei ISO-8859-1 handelt es sich weiterhin um eine Einzelbyte-Kodierung, die insgesamt 256 Zeichen darstellen kann.
GB2312
Es handelt sich um eine Doppelbyte-Codierung, und der gesamte Codierungsbereich beträgt A1 bis F7, wobei A1 bis A9 der Symbolbereich mit insgesamt 682 Symbolen ist. B0 bis F7 ist der Bereich für chinesische Zeichen mit 6763 chinesischen Zeichen.
GBk
GBK ist die „Chinese Character Internal Code Extension Specification“, die eine Erweiterung von GB2312 ist (ohne XX7F). Es gibt insgesamt 23940 Codepunkte, die 21003 chinesische Zeichen darstellen können mit der Codierung von GB2312 und weist keine verstümmelten Zeichen auf.
UTF-16
Es definiert speziell, wie auf Unicode-Zeichen im Computer zugegriffen wird. UTF-16 verwendet zwei Bytes zur Darstellung des Unicode-Konvertierungsformats. Es verwendet eine Darstellungsmethode mit fester Länge, d. h. es wird unabhängig vom Zeichen durch zwei Bytes dargestellt. Zwei Bytes sind 16 Bit, daher wird es UTF-16 genannt. Es ist sehr praktisch, Zeichen darzustellen, da keine zwei Bytes ein Zeichen darstellen, was die Zeichenfolgenoperationen erheblich vereinfacht.
UTF-8
Obwohl es für UTF-16 einfach und bequem ist, einheitlich zwei Bytes zur Darstellung eines Zeichens zu verwenden, kann ein großer Teil der Zeichen durch ein Byte dargestellt werden. Wenn es durch zwei Bytes dargestellt wird, wird der Speicherplatz verdoppelt Ein Problem, wenn die Netzwerkbandbreite begrenzt ist. In diesem Fall wird der Datenverkehr der Netzwerkübertragung erhöht. UTF-8 verwendet eine Technologie mit variabler Länge. Jeder Kodierungsbereich hat unterschiedliche Zeichenlängen, die aus 1 bis 6 Bytes bestehen können.
UTF-8 hat die folgenden Kodierungsregeln:
Wenn es 1 Byte ist, ist das höchste Bit (8. Bit) 0, was bedeutet, dass es sich um ein ASCII-Zeichen (00 ~ 7F) handelt
Wenn es 1 Byte ist, beginnend mit 11, dann gibt die Anzahl der aufeinanderfolgenden Einsen die Anzahl der Bytes dieses Zeichens an
Wenn es 1 Byte ist, bedeutet es, wenn es mit 10 beginnt. Wenn nicht Beim ersten Byte müssen Sie sich darauf freuen, das erste Byte des aktuellen Zeichens zu erhalten
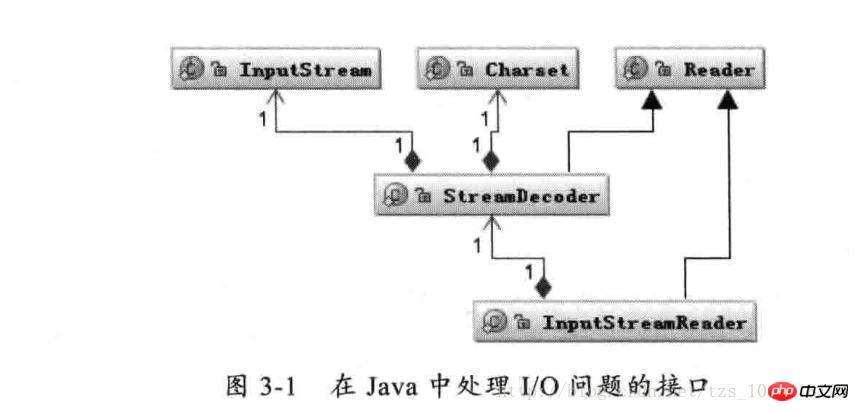
Wie oben gezeigt: Die Reader-Klasse ist die übergeordnete Klasse zum Lesen von Zeichen in Java I/O, und die InputStream-Klasse ist die übergeordnete Klasse zum Lesen von Bytes. Die InputStreamReader-Klasse ist die Brücke, die Bytes mit Zeichen verknüpft Während des E/A-Prozesses übernimmt es die Konvertierung gelesener Bytes in Zeichen und beauftragt StreamDecoder mit der Implementierung der Decodierung bestimmter Bytes in Zeichen. Während des Decodierungsprozesses von StreamDecoder muss das Zeichensatz-Codierungsformat vom Benutzer angegeben werden. Beachten Sie, dass der Standardzeichensatz in der lokalen Umgebung verwendet wird, wenn Sie keinen Zeichensatz angeben. In der chinesischen Umgebung wird beispielsweise die GBK-Codierung verwendet.
Beispielsweise implementiert der folgende Code die Funktion zum Lesen und Schreiben von Dateien:
String file = "c:/stream.txt";
String charset = "UTF-8";
// 写字符换转成字节流
FileOutputStream outputStream = new FileOutputStream(file);
OutputStreamWriter writer = new OutputStreamWriter(
outputStream, charset);
try {
writer.write("这是要保存的中文字符");
} finally {
writer.close();
}
// 读取字节转换成字符
FileInputStream inputStream = new FileInputStream(file);
InputStreamReader reader = new InputStreamReader(
inputStream, charset);
StringBuffer buffer = new StringBuffer();
char[] buf = new char[64];
int count = 0;
try {
while ((count = reader.read(buf)) != -1) {
buffer.append(buffer, 0, count);
}
} finally {
reader.close();
}Wenn unsere Anwendung E/A-Vorgänge umfasst, treten im Allgemeinen keine Probleme mit verstümmeltem Code auf, solange wir auf die Angabe eines einheitlichen Zeichensatzes für die Codierung und Decodierung achten.
Führen Sie eine Datentypkonvertierung von Zeichen in Bytes im Speicher durch.
1. Die String-Klasse stellt Methoden zum Konvertieren von Zeichenfolgen in Bytes bereit und unterstützt außerdem Konstruktoren zum Konvertieren von Bytes in Zeichenfolgen.
String s = "字符串";
byte[] b = s.getBytes("UTF-8");
String n = new String(b, "UTF-8");2. Charset bietet Kodierung und Dekodierung, die der Kodierung von char[] zu byte[] bzw. der Dekodierung von byte[] zu char[] entsprechen.
Charset charset = Charset.forName("UTF-8");
ByteBuffer byteBuffer = charset.encode(string);
CharBuffer charBuffer = charset.decode(byteBuffer);...
Diagramm der Java-Codierungsklasse
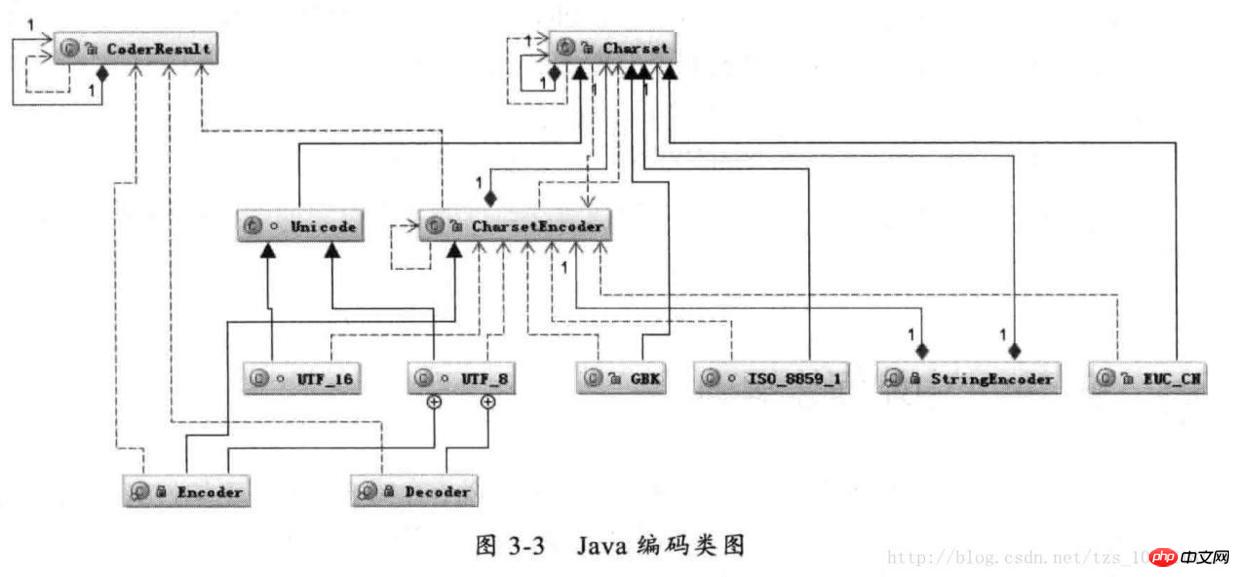
Legen Sie zuerst die Charset-Klasse gemäß dem angegebenen CharsetName über Charset.forName (CharsetName) fest, erstellen Sie dann ein CharsetEncoder-Objekt gemäß Charset und rufen Sie dann CharsetEncoder.encode auf, um die Zeichenfolge zu codieren. Die tatsächliche Codierung entspricht einer Klasse Der Prozess wird in diesen Klassen durchgeführt. Das Folgende ist das Zeitdiagramm des String.getBytes(charsetName)-Codierungsprozesses
Java-Codierungssequenzdiagramm
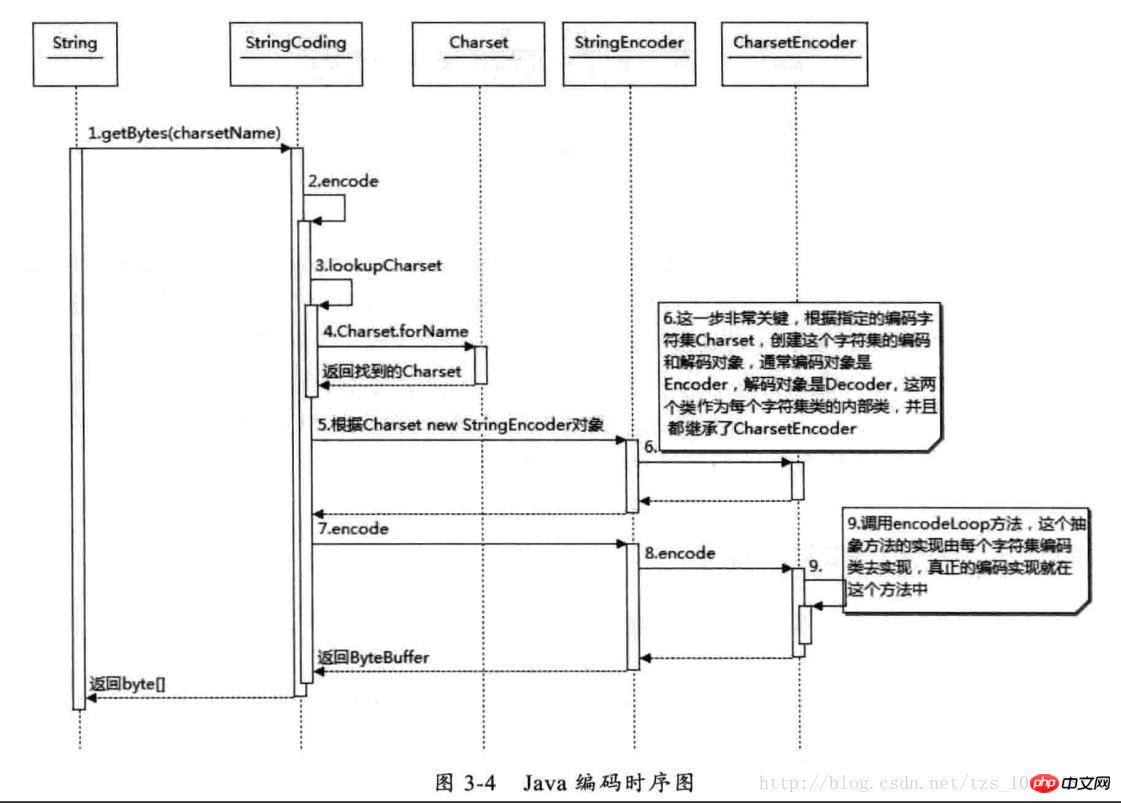
Wie aus der obigen Abbildung ersichtlich ist, wird die Charset-Klasse basierend auf charsetName gefunden und dann CharsetEncoder basierend auf dieser Zeichensatzkodierung generiert. Diese Klasse ist die übergeordnete Klasse aller Zeichenkodierungssätze und definiert, wie Um die Codierung in ihren Unterklassen zu implementieren, können Sie nach Erhalt des CharsetEncoder-Objekts die Methode encode aufrufen, um die Codierung zu implementieren. Dies ist die Codierungsmethode String.getBytes. Andere Methoden wie StreamEncoder sind ähnlich.
Es kommt oft vor, dass chinesische Zeichen zu „?“ werden, was durch eine falsche Verwendung der ISO-8859-1-Kodierung verursacht werden kann. Chinesische Zeichen verlieren nach der ISO-8859-1-Kodierung Informationen. Wir nennen es normalerweise ein „Schwarzes Loch“, das unbekannte Zeichen absorbiert. Da die Standardzeichensatzkodierung der meisten grundlegenden Java-Frameworks oder -Systeme ISO-8859-1 ist, kann es leicht zu verstümmelten Zeichen kommen. Wir werden später analysieren, wie verschiedene Formen von verstümmelten Zeichen auftreten.
Es kann die folgenden vier Kodierungsformate für chinesische Zeichen verarbeiten. Die Kodierungsregeln von GB2312 und GBK sind ähnlich, aber GBK hat einen größeren Bereich und kann alle chinesischen Zeichen verarbeiten. Daher sollte beim Vergleich von GB2312 und GBK GBK ausgewählt werden. UTF-16 und UTF-8 befassen sich beide mit der Unicode-Codierung, und ihre Codierungsregeln sind nicht dieselben. Relativ gesehen ist die UTF-16-Codierung am effizientesten, es ist einfacher, Zeichen in Bytes umzuwandeln, und es ist besser, Zeichenfolgen auszuführen Operationen. Es eignet sich für die Verwendung zwischen lokaler Festplatte und Speicher und kann schnell zwischen Zeichen und Bytes wechseln. Beispielsweise verwendet die Speichercodierung von Java die UTF-16-Codierung. Es ist jedoch nicht für die Übertragung zwischen Netzwerken geeignet, da die Netzwerkübertragung den Bytestrom leicht beschädigen kann. Sobald der Bytestrom beschädigt ist, ist die Wiederherstellung schwieriger. Im Vergleich dazu ist UTF-8 besser für die Netzwerkübertragung geeignet und verwendet Single -Byte-Speicherung für ASCII-Zeichen. Darüber hinaus hat die Beschädigung eines einzelnen Zeichens keine Auswirkungen auf andere nachfolgende Zeichen. Die Codierungseffizienz liegt zwischen GBK und UTF-16. Daher ist UTF-8 eine ideale chinesische Codierung Verfahren.
Für die Verwendung von Chinesisch, wo E/A vorhanden ist, ist eine Codierung erforderlich. Wie bereits erwähnt, verursachen E/A-Vorgänge eine Codierung, und die meisten durch E/A verursachten verstümmelten Codes sind Netzwerk-E/A, da es sich jetzt um fast alle handelt Alle Die meisten Anwendungen beinhalten Netzwerkvorgänge, und die über das Netzwerk übertragenen Daten werden in Bytes übermittelt, daher müssen alle Daten in Bytes serialisiert werden. Daten, die in Java serialisiert werden sollen, müssen die Serializable-Schnittstelle erben.
Wie soll die tatsächliche Größe eines Textes berechnet werden? Ich bin einmal auf ein Problem gestoßen: Ich wollte einen Weg finden, die Cookie-Größe zu komprimieren und den Umfang der Netzwerkübertragung zu reduzieren, und habe das gefunden Die Anzahl der Zeichen wurde nach der Komprimierung reduziert, jedoch nicht. Keine Reduzierung der Bytezahl. Bei der sogenannten Komprimierung werden mehrere Einzelbyte-Zeichen durch Kodierung lediglich in ein Mehrbyte-Zeichen umgewandelt. Reduziert wird String.length(), jedoch nicht die endgültige Anzahl an Bytes. Beispielsweise werden die beiden Zeichen „ab“ durch eine Codierung in ein seltsames Zeichen umgewandelt. Obwohl sich die Anzahl der Zeichen von zwei auf eins ändert, kann es nach der Codierung zu drei werden, wenn UTF-8 zum Codieren verwendet wird mehr Bytes. Wenn beispielsweise die Ganzzahl 1234567 als Zeichen gespeichert wird, belegt die Codierung mit UTF-8 aus dem gleichen Grund 7 Bytes und die Codierung mit UTF-16 14 Bytes, die Speicherung jedoch nur als int-Zahl erfordert 4 Bytes zum Speichern. Daher ist es sinnlos, auf die Größe eines Textstücks und die Länge der Zeichen selbst zu achten. Selbst wenn dieselben Zeichen in unterschiedlichen Codierungen gespeichert werden, ist die endgültige Speichergröße unterschiedlich, sodass Sie auf den Codierungstyp achten müssen von Zeichen bis Bytes.
我们能够看到的汉字都是以字符形式出现的,例如在 Java 中“淘宝”两个字符,它在计算机中的数值 10 进制是 28120 和 23453,16 进制是 6bd8 和 5d9d,也就是这两个字符是由这两个数字唯一表示的。Java 中一个 char 是 16 个 bit 相当于两个字节,所以两个汉字用 char 表示在内存中占用相当于四个字节的空间。
这两个问题搞清楚后,我们看一下 Java Web 中那些地方可能会存在编码转换?
用户从浏览器端发起一个 HTTP 请求,需要存在编码的地方是 URL、Cookie、Parameter。服务器端接受到 HTTP 请求后要解析 HTTP 协议,其中 URI、Cookie 和 POST 表单参数需要解码,服务器端可能还需要读取数据库中的数据,本地或网络中其它地方的文本文件,这些数据都可能存在编码问题,当 Servlet 处理完所有请求的数据后,需要将这些数据再编码通过 Socket 发送到用户请求的浏览器里,再经过浏览器解码成为文本。这些过程如下图所示:
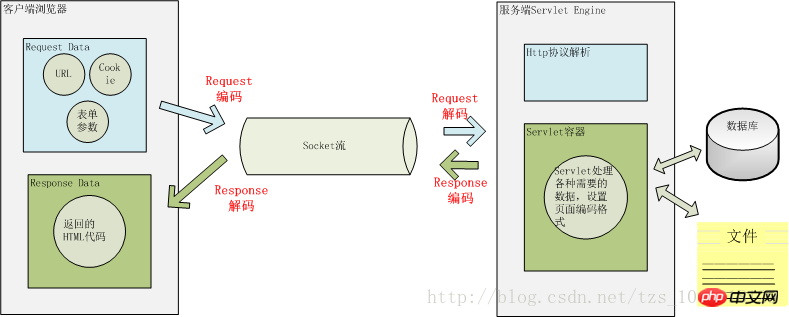
一次 HTTP 请求的编码示例
用户提交一个 URL,这个 URL 中可能存在中文,因此需要编码,如何对这个 URL 进行编码?根据什么规则来编码?有如何来解码?如下图一个 URL:

上图中以 Tomcat 作为 Servlet Engine 为例,它们分别对应到下面这些配置文件中:
Port 对应在 Tomcat 的
<servlet-mapping>
<servlet-name>junshanExample</servlet-name>
<url-pattern>/servlets/servlet/*</url-pattern>
</servlet-mapping>
上图中 PathInfo 和 QueryString 出现了中文,当我们在浏览器中直接输入这个 URL 时,在浏览器端和服务端会如何编码和解析这个 URL 呢?为了验证浏览器是怎么编码 URL 的我选择的是360极速浏览器并通过 Postman 插件观察我们请求的 URL 的实际的内容,以下是 URL:
HTTP://localhost:8080/examples/servlets/servlet/君山?author=君山
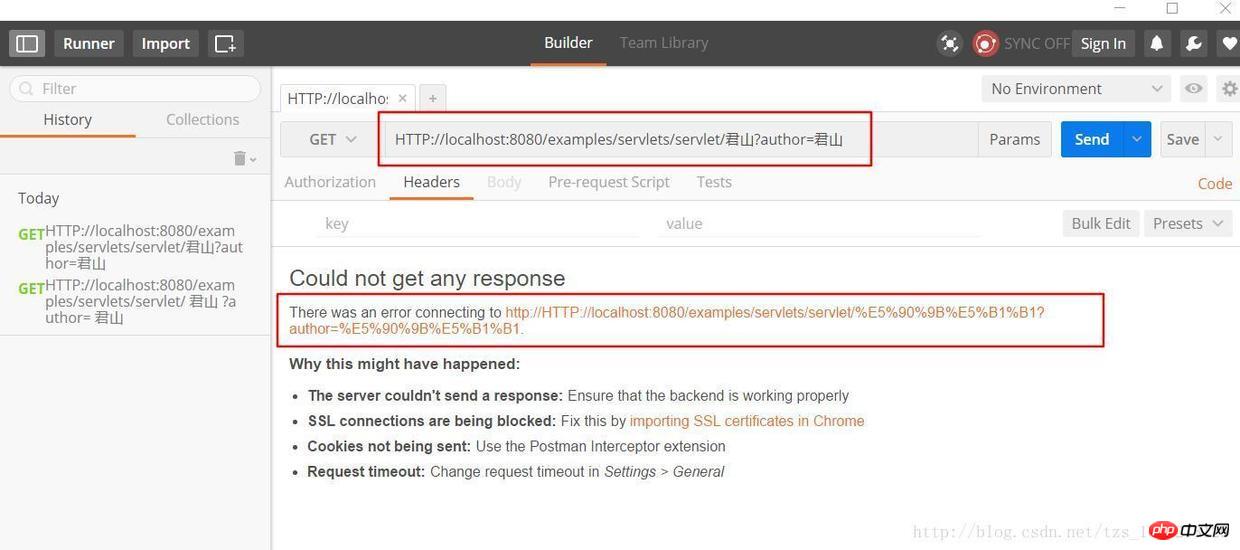
君山的编码结果是:e5 90 9b e5 b1 b1,和《深入分析 Java Web 技术内幕》中的结果不一样,这是因为我使用的浏览器和插件和原作者是有区别的,那么这些浏览器之间的默认编码是不一样的,原文中的结果是:

君山的编码结果分别是:e5 90 9b e5 b1 b1,be fd c9 bd,查阅上一届的编码可知,PathInfo 是 UTF-8 编码而 QueryString 是经过 GBK 编码,至于为什么会有“%”?查阅 URL 的编码规范 RFC3986 可知浏览器编码 URL 是将非 ASCII 字符按照某种编码格式编码成 16 进制数字然后将每个 16 进制表示的字节前加上“%”,所以最终的 URL 就成了上图的格式了。
从上面测试结果可知浏览器对 PathInfo 和 QueryString 的编码是不一样的,不同浏览器对 PathInfo 也可能不一样,这就对服务器的解码造成很大的困难,下面我们以 Tomcat 为例看一下,Tomcat 接受到这个 URL 是如何解码的。
解析请求的 URL 是在 org.apache.coyote.HTTP11.InternalInputBuffer 的 parseRequestLine 方法中,这个方法把传过来的 URL 的 byte[] 设置到 org.apache.coyote.Request 的相应的属性中。这里的 URL 仍然是 byte 格式,转成 char 是在 org.apache.catalina.connector.CoyoteAdapter 的 convertURI 方法中完成的:
protected void convertURI(MessageBytes uri, Request request)
throws Exception {
ByteChunk bc = uri.getByteChunk();
int length = bc.getLength();
CharChunk cc = uri.getCharChunk();
cc.allocate(length, -1);
String enc = connector.getURIEncoding();
if (enc != null) {
B2CConverter conv = request.getURIConverter();
try {
if (conv == null) {
conv = new B2CConverter(enc);
request.setURIConverter(conv);
}
} catch (IOException e) {...}
if (conv != null) {
try {
conv.convert(bc, cc, cc.getBuffer().length -
cc.getEnd());
uri.setChars(cc.getBuffer(), cc.getStart(),
cc.getLength());
return;
} catch (IOException e) {...}
}
}
// Default encoding: fast conversion
byte[] bbuf = bc.getBuffer();
char[] cbuf = cc.getBuffer();
int start = bc.getStart();
for (int i = 0; i < length; i++) {
cbuf[i] = (char) (bbuf[i + start] & 0xff);
}
uri.setChars(cbuf, 0, length);
}
从上面的代码中可以知道对 URL 的 URI 部分进行解码的字符集是在 connector 的
Wie analysiere ich QueryString? Der QueryString der GET-HTTP-Anfrage und die Formularparameter der POST-HTTP-Anfrage werden als Parameter gespeichert und die Parameterwerte werden über request.getParameter abgerufen. Sie werden beim ersten Aufruf der Methode request.getParameter dekodiert. Wenn die Methode request.getParameter aufgerufen wird, ruft sie die Methode parseParameters von org.apache.catalina.connector.Request auf. Diese Methode dekodiert die von GET und POST übergebenen Parameter, ihre Dekodierungszeichensätze können jedoch unterschiedlich sein. Die Dekodierung des POST-Formulars wird später vorgestellt. Wo ist der Dekodierungszeichensatz von QueryString definiert? Es wird über den HTTP-Header an den Server übertragen und ist auch in der URL enthalten. Ist es dasselbe wie der Dekodierungszeichensatz der URI? Da die vorherigen Browser unterschiedliche Codierungsformate für PathInfo und QueryString verwendeten, können wir davon ausgehen, dass die decodierten Zeichensätze definitiv nicht konsistent sein werden. Tatsächlich ist der Decodierungszeichensatz von QueryString entweder der in ContentType im Header definierte Zeichensatz oder der Standardwert ISO-8859-1. Um die in ContentType definierte Codierung zu verwenden, müssen Sie
Dem obigen URL-Kodierungs- und Dekodierungsprozess nach zu urteilen, ist er relativ kompliziert und die Kodierung und Dekodierung können von uns in der Anwendung nicht vollständig kontrolliert werden. Daher sollten wir versuchen, die Verwendung von Nicht-ASCII-Zeichen in der URL in unserer Anwendung zu vermeiden Es kann sehr schwierig sein, auf verstümmelte Zeichen zu stoßen. Natürlich ist es am besten, die beiden Parameter URIEncoding und useBodyEncodingForURI in
Wenn der Client eine HTTP-Anfrage initiiert, kann er neben der oben genannten URL auch andere Parameter wie Cookie, RedirectPath usw. im Header übergeben. Bei diesen vom Benutzer festgelegten Werten kann es auch zu Codierungsproblemen kommen. Wie dekodiert Tomcat sie? ?
Die Dekodierung der Elemente im Header erfolgt ebenfalls durch den Aufruf von request.getHeader. Wenn das angeforderte Header-Element nicht dekodiert wird, wird die toString-Methode von MessageBytes aufgerufen. Die von dieser Methode für die Konvertierung von Byte in Char verwendete Standardkodierung ist ebenfalls ISO-8859 -1, und wir können keine anderen Dekodierungsformate für den Header festlegen. Wenn Sie also die Dekodierung von Nicht-ASCII-Zeichen im Header festlegen, werden auf jeden Fall verstümmelte Zeichen angezeigt.
Das Gleiche gilt, wenn wir einen Header hinzufügen. Wenn wir sie übergeben müssen, können wir diese Zeichen zuerst mit org.apache.catalina.util.URLEncoder codieren und sie dann zum Header hinzufügen Auf diese Weise gehen Informationen während der Übertragung vom Browser zum Server nicht verloren. Es wäre schön, wenn wir sie entsprechend dem entsprechenden Zeichensatz dekodieren würden, wenn wir auf diese Elemente zugreifen möchten.
Wie bereits erwähnt, erfolgt die Dekodierung der vom POST-Formular übermittelten Parameter beim ersten Aufruf. Die POST-Formularparameterübertragungsmethode unterscheidet sich von QueryString. Sie wird über den BODY von HTTP an den Server übergeben. Wenn wir auf der Seite auf die Schaltfläche „Senden“ klicken, kodiert der Browser zunächst die im Formular ausgefüllten Parameter gemäß dem Zeichensatzkodierungsformat von ContentType und sendet sie dann an den Server. Der Server verwendet auch den Zeichensatz in ContentType zur Dekodierung. Daher gibt es im Allgemeinen kein Problem mit Parametern, die über das POST-Formular übermittelt werden. Die Zeichensatzcodierung wird von uns selbst festgelegt und kann über request.setCharacterEncoding (charset) festgelegt werden.
Darüber hinaus verwendet die Codierung der hochgeladenen Datei für Multipart-/Formulardatentypparameter auch die durch ContentType definierte Zeichensatzcodierung. Es ist zu beachten, dass die hochgeladene Datei in einem Byte an das lokale temporäre Verzeichnis des Servers übertragen wird Dieser Prozess beinhaltet keine Zeichenkodierung, aber die eigentliche Kodierung besteht darin, den Dateiinhalt zu Parametern hinzuzufügen. Wenn er mit dieser Kodierung nicht kodiert werden kann, wird die Standardkodierung ISO-8859-1 verwendet.
Wenn die vom Benutzer angeforderten Ressourcen erfolgreich abgerufen wurden, wird der Inhalt über die Antwort an den Client-Browser zurückgegeben. Dieser Vorgang muss zunächst vom Browser codiert und dann decodiert werden. Der Codierungs- und Decodierungszeichensatz dieses Prozesses kann über Response.setCharacterEncoding festgelegt werden, wodurch der Wert von request.getCharacterEncoding überschrieben und über den Content-Type des Headers an den Client zurückgegeben wird übergibt den Content-Type-Zeichensatz zum Dekodieren. Wenn der Content-Type im zurückgegebenen HTTP-Header keinen Zeichensatz festlegt, dekodiert der Browser ihn entsprechend dem
除了 URL 和参数编码问题外,在服务端还有很多地方可能存在编码,如可能需要读取 xml、velocity 模版引擎、JSP 或者从数据库读取数据等。
xml 文件可以通过设置头来制定编码格式
<?xml version="1.0" encoding="UTF-8"?>
Velocity 模版设置编码格式:
services.VelocityService.input.encoding=UTF-8
JSP 设置编码格式:
<%@page contentType="text/html; charset=UTF-8"%>
访问数据库都是通过客户端 JDBC 驱动来完成,用 JDBC 来存取数据要和数据的内置编码保持一致,可以通过设置 JDBC URL 来制定如 MySQL:url="jdbc:mysql://localhost:3306/DB?useUnicode=true&characterEncoding=GBK"。
下面看一下,当我们碰到一些乱码时,应该怎么处理这些问题?出现乱码问题唯一的原因都是在 char 到 byte 或 byte 到 char 转换中编码和解码的字符集不一致导致的,由于往往一次操作涉及到多次编解码,所以出现乱码时很难查找到底是哪个环节出现了问题,下面就几种常见的现象进行分析。
例如,字符串“淘!我喜欢!”变成了“Ì Ô £ ¡Î Ò Ï²»¶ £ ¡”编码过程如下图所示:
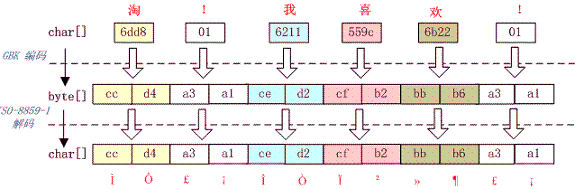
字符串在解码时所用的字符集与编码字符集不一致导致汉字变成了看不懂的乱码,而且是一个汉字字符变成两个乱码字符。
例如,字符串“淘!我喜欢!”变成了“??????”编码过程如下图所示:
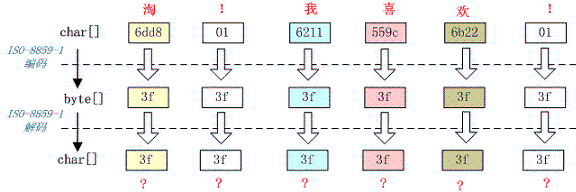
将中文和中文符号经过不支持中文的 ISO-8859-1 编码后,所有字符变成了“?”,这是因为用 ISO-8859-1 进行编解码时遇到不在码值范围内的字符时统一用 3f 表示,这也就是通常所说的“黑洞”,所有 ISO-8859-1 不认识的字符都变成了“?”。
例如,字符串“淘!我喜欢!”变成了“????????????”编码过程如下图所示:
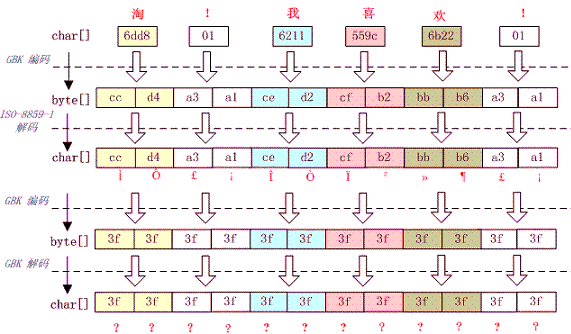
这种情况比较复杂,中文经过多次编码,但是其中有一次编码或者解码不对仍然会出现中文字符变成“?”现象,出现这种情况要仔细查看中间的编码环节,找出出现编码错误的地方。
还有一种情况是在我们通过 request.getParameter 获取参数值时,当我们直接调用
String value = request.getParameter(name); 会出现乱码,但是如果用下面的方式
String value = String(request.getParameter(name).getBytes(" ISO-8859-1"), "GBK");
解析时取得的 value 会是正确的汉字字符,这种情况是怎么造成的呢?
看下如所示:
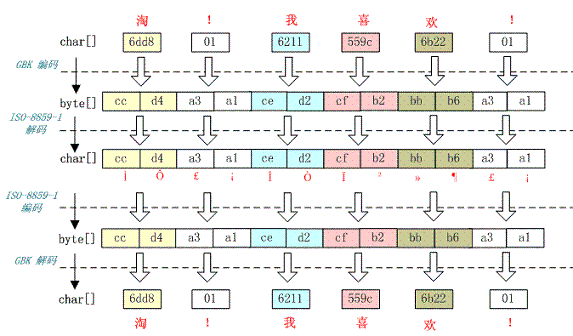
这种情况是这样的,ISO-8859-1 字符集的编码范围是 0000-00FF,正好和一个字节的编码范围相对应。这种特性保证了使用 ISO-8859-1 进行编码和解码可以保持编码数值“不变”。虽然中文字符在经过网络传输时,被错误地“拆”成了两个欧洲字符,但由于输出时也是用 ISO-8859-1,结果被“拆”开的中文字的两半又被合并在一起,从而又刚好组成了一个正确的汉字。虽然最终能取得正确的汉字,但是还是不建议用这种不正常的方式取得参数值,因为这中间增加了一次额外的编码与解码,这种情况出现乱码时因为 Tomcat 的配置文件中 useBodyEncodingForURI 配置项没有设置为”true”,从而造成第一次解析式用 ISO-8859-1 来解析才造成乱码的。
Dieser Artikel fasst zunächst die Unterschiede zwischen mehreren gängigen Codierungsformaten zusammen, stellt dann mehrere Codierungsformate vor, die Chinesisch unterstützen, und vergleicht deren Verwendungsszenarien. Anschließend werden die Stellen in Java vorgestellt, an denen es zu Codierungsproblemen kommt, und wie die Codierung in Java unterstützt wird. Am Beispiel von Netzwerk-E/A konzentriert es sich auf die Codierung von HTTP-Anforderungen sowie auf die Analyse des HTTP-Protokolls durch Tomcat und analysiert schließlich die Gründe für die Probleme mit verstümmeltem Code, auf die wir normalerweise stoßen.
Zusammenfassend lässt sich sagen, dass wir zur Lösung des chinesischen Problems zunächst herausfinden müssen, wo die Zeichen-zu-Byte-Kodierung und die Byte-zu-Zeichen-Dekodierung stattfinden. Die häufigsten Orte sind das Lesen und Speichern von Daten auf der Festplatte oder Daten, die über das Netzwerk übertragen werden . Übertragung. Finden Sie dann für diese Stellen heraus, wie das Framework oder System, das diese Daten verwaltet, die Kodierung steuert, stellen Sie das Kodierungsformat richtig ein und vermeiden Sie die Verwendung des Standardkodierungsformats der Software oder der Betriebssystemplattform.
Das obige ist der detaillierte Inhalt vonAnalyse chinesischer Codierungsprobleme in Java Web. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



