
 Datenbank
MySQL-Tutorial
Teilen Sie einen Beispielcode für die Optimierung eines mehrspaltigen MySQL-Index
Datenbank
MySQL-Tutorial
Teilen Sie einen Beispielcode für die Optimierung eines mehrspaltigen MySQL-Index
Teilen Sie einen Beispielcode für die Optimierung eines mehrspaltigen MySQL-Index

Da die von Crawlern erfassten Daten weiter zunehmen, wurden die Datenbank- und Abfrageanweisungen in den letzten zwei Tagen kontinuierlich optimiert. Eine der Tabellenstrukturen lautet wie folgt:
CREATE TABLE `newspaper_article` ( `id` varchar(50) NOT NULL COMMENT '编号', `title` varchar(190) NOT NULL COMMENT '标题', `author` varchar(255) DEFAULT NULL COMMENT '作者', `date` date NULL DEFAULT NULL COMMENT '发表时间', `content` longtext COMMENT '正文', `status` tinyint(4) DEFAULT '0', PRIMARY KEY (`id`), KEY `idx_status_date` (`status`,`date`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='文章表';
Entsprechend den Geschäftsanforderungen wurde der idx_status_date-Index hinzugefügt. Es ist besonders zeitaufwändig, das folgende SQL auszuführen:
SELECT id, title, status, date FROM article WHERE status > -2 AND date = '2016-01-07';
Beobachtungen zufolge ist Die Anzahl der täglich hinzugefügten neuen Daten beträgt etwa 2.500. Ich dachte, dass hier ein bestimmtes Datum '2016-01-07' angegeben wurde und die tatsächliche Menge der zu scannenden Daten innerhalb von 2.500 liegen sollte, aber das ist nicht der Fall: 
Es wurden tatsächlich insgesamt 185589 gescannte Daten erhalten, viel mehr als die geschätzten 2500 Teile, und die tatsächliche Ausführungszeit betrug fast 3 Sekunden:

Warum ist das so?
Lösung
Nachdem Sie idx_status_date (status, date) in idx_status (status) geändert haben, sehen Sie sich den MySQL-Ausführungsplan an:

Sie können sehen, dass sich nach der Änderung des mehrspaltigen Index in einen einspaltigen Index keine Änderung an der Gesamtmenge der vom Ausführungsplan zu scannenden Daten ergibt. In Kombination mit der Tatsache, dass mehrspaltige Indizes dem Präfixprinzip ganz links folgen, wird spekuliert, dass die obige Abfrageanweisung nur den Index ganz links idx_status_date von status verwendet.
Ich habe „High Performance MySQL“ durchgeblättert und die folgende Passage gefunden, die meine Idee bestätigt hat:
Wenn es eine Bereichsabfrage für eine bestimmte Spalte in der Abfrage gibt, dann die rechte Seite Alle Spalten können nicht mithilfe der Indexoptimierung nachgeschlagen werden. Beispielsweise gibt es eine Abfrage
WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23'. Diese Abfrage kann nur die ersten beiden Spalten des Index verwenden, daLIKEhier eine Bereichsbedingung ist (der Server kann die restlichen Spalten jedoch für andere Zwecke verwenden). Wenn die Anzahl der Bereichsabfragespaltenwerte begrenzt ist, können Sie die Bereichsbedingung durch die Verwendung mehrerer gleicher Bedingungen ersetzen.
Daher gibt es hier zwei Lösungen:
Sie können die Bereichsbedingung durch die Verwendung mehrerer gleicher Bedingungen ersetzen
-
Ändern Sie
idx_status_date (status, date), umidx_date_status (date, status)zu indizieren, und erstellen Sie einen neuenidx_status-Index, um den gleichen Effekt zu erzielen.
Optimierter Ausführungsplan:

Tatsächliches Ausführungsergebnis:
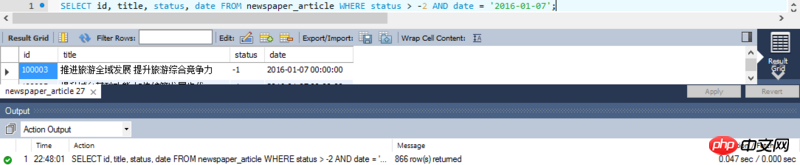
Zusammenfassung
Wenn Leute über Indizes sprechen und den Typ nicht angeben, sprechen sie wahrscheinlich von B-Tree-Indizes, die B-Tree-Daten verwenden Struktur zum Speichern von Daten. Wir verwenden den Begriff „B-Tree“, da MySQL dieses Schlüsselwort auch in CREATE TABLE und anderen Anweisungen verwendet. Die zugrunde liegende Speicher-Engine kann jedoch auch andere Speicherstrukturen verwenden. InnoDB verwendet B+Tree.
Angenommen, es gibt die folgende Datentabelle:
CREATE TABLE People ( last_name varchar(50) not null, first_name varchar(50) not null, dob date not null, gender enum('m', 'f') not null, key(last_name, first_name, dob) );
Der B-Tree-Index ist für die folgenden Arten von Abfragen gültig
Vollständige Werteübereinstimmung
Der vollständige Wertabgleich bedeutet, alle Spalten im Index abzugleichen. Der Index in der obigen Tabelle kann beispielsweise verwendet werden, um Personen mit dem Namen Cuba Allen zu finden, die am 01.01.1960 geboren wurden.Entspricht dem Präfix ganz links
Der Index in der obigen Tabelle kann verwendet werden, um alle Personen mit dem Nachnamen Allen zu finden, d. h. es wird nur die erste Spalte des Index verwendet .Spaltenpräfix anpassen
Entspricht nur dem Anfang des Werts einer Spalte. Beispielsweise kann der Index in der obigen Tabelle verwendet werden, um alle Personen zu finden, deren Nachnamen mit J beginnen. Hier wird nur die erste Spalte des Index verwendet.Übereinstimmungsbereichswert
Der Index in der obigen Tabelle kann beispielsweise verwendet werden, um Personen mit Nachnamen zwischen Allen und Barrymore zu finden. Hier wird nur die erste Spalte des Index verwendet.Genaue Übereinstimmung mit einer bestimmten Spalte und Bereichsübereinstimmung mit einer anderen Spalte
Der Index in der obigen Tabelle kann auch verwendet werden, um alle Personen zu finden, deren Nachname Allen ist und deren Vorname mit beginnt der Buchstabe K (wie Kim, Karl usw.) Menschen. Das heißt, die erste Spalte „last_name“ stimmt vollständig überein und die zweite Spalte „first_name“ stimmt mit dem Bereich überein.Abfrage, die nur auf den Index zugreift
B-Tree kann normalerweise „Abfragen, die nur auf den Index zugreifen“ unterstützen, d. h. die Abfrage muss nur auf den Index zugreifen, ohne darauf zuzugreifen Datenzeilen.
Einige Einschränkungen des B-Tree-Index
Der Index kann nicht verwendet werden, wenn die Suche nicht in der Spalte ganz links im Index beginnt. Beispielsweise kann der Index in der obigen Tabelle nicht verwendet werden, um eine Person namens Bill zu finden, noch kann er eine Person mit einem bestimmten Geburtstag finden, da keine der beiden Spalten die Datenspalte ganz links ist. Ebenso gibt es keine Möglichkeit, Personen zu finden, deren Nachnamen mit einem bestimmten Buchstaben enden.
Spalten im Index können nicht übersprungen werden. Das heißt, der Index in der Tabelle oben kann nicht verwendet werden, um Personen mit dem Nachnamen Smith zu finden, die an einem bestimmten Datum geboren wurden. Wenn Sie keinen Namen (Vorname) angeben, kann MySQL nur die erste Spalte des Index verwenden.
Wenn in der Abfrage eine Bereichsabfrage für eine bestimmte Spalte vorhanden ist, können alle Spalten rechts davon nicht mithilfe der Indexoptimierung durchsucht werden. Beispielsweise gibt es eine Abfrage
WHERE last_name = 'Smith' AND first_name LIKE 'J%' AND dob = '1976-12-23'. Diese Abfrage kann nur die ersten beiden Spalten des Index verwenden, daLIKEhier eine Bereichsbedingung ist (der Server kann die restlichen Spalten jedoch für andere Zwecke verwenden). Wenn die Anzahl der Bereichsabfragespaltenwerte begrenzt ist, können Sie die Bereichsbedingung durch die Verwendung mehrerer gleicher Bedingungen ersetzen.
Das obige ist der detaillierte Inhalt vonTeilen Sie einen Beispielcode für die Optimierung eines mehrspaltigen MySQL-Index. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
52

 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
