
 Backend-Entwicklung
Python-Tutorial
Teilen Sie eine Python-Methode zum Crawlen beliebter Kommentare zu NetEase Cloud Music
Backend-Entwicklung
Python-Tutorial
Teilen Sie eine Python-Methode zum Crawlen beliebter Kommentare zu NetEase Cloud Music
Teilen Sie eine Python-Methode zum Crawlen beliebter Kommentare zu NetEase Cloud Music

In diesem Artikel wird ein Beispiel für die Verwendung von Python zum Erhalten beliebter Kommentare zu NetEase Cloud Music ausführlich vorgestellt. Es hat einen sehr guten Referenzwert. Schauen wir uns das unten an.
Ich habe kürzlich Inhalte im Zusammenhang mit Text Mining studiert. Es heißt, dass eine kluge Frau keine Mahlzeit ohne Reis zubereiten kann. Wenn Sie eine Textanalyse durchführen möchten, müssen Sie zunächst über Text verfügen. Es gibt viele Möglichkeiten, Text zu erhalten, z. B. das Herunterladen vorgefertigter Textdokumente aus dem Internet oder das Abrufen von Daten über von Dritten bereitgestellte APIs. Aber manchmal können die gewünschten Daten nicht direkt abgerufen werden, weil es keinen direkten Download-Kanal oder keine API gibt, über die wir die Daten erhalten könnten. Was sollen wir also zu diesem Zeitpunkt tun? Eine bessere Möglichkeit ist die Verwendung eines Webcrawlers, der ein Computerprogramm schreibt, das sich als Benutzer ausgibt, um die gewünschten Daten zu erhalten. Durch die Leistungsfähigkeit von Computern können wir Daten einfach und schnell abrufen.
Wie schreibt man also einen Crawler? Es gibt viele Sprachen, die zum Schreiben von Crawlern verwendet werden können, wie Java, PHP, Python usw. Ich persönlich bevorzuge die Verwendung von Python. Da Python nicht nur über eine integrierte leistungsstarke Netzwerkbibliothek verfügt, sondern auch über viele hervorragende Bibliotheken von Drittanbietern, können wir es einfach verwenden. Dies bringt großen Komfort beim Schreiben von Crawlern. Es ist keine Übertreibung zu sagen, dass Sie tatsächlich einen kleinen Crawler mit weniger als 10 Zeilen Python-Code schreiben können, während die Verwendung anderer Sprachen das Schreiben von viel mehr Code erfordert. Prägnant und leicht verständlich zu sein, ist ein großer Vorteil von Python.
Okay, kommen wir ohne weitere Umschweife zum Hauptthema von heute. NetEase Cloud Music ist in den letzten Jahren sehr beliebt geworden. Ich bin ein Benutzer von NetEase Cloud Music und verwende es seit mehreren Jahren. Ich habe früher QQ Music und Kugou verwendet. Aus eigener Erfahrung denke ich, dass die besten Eigenschaften von NetEase Cloud Music die genauen Songempfehlungen und einzigartigen Benutzerrezensionen sind (fürs Protokoll!!! Dies ist kein weicher Artikel), nicht- Werbung! Nur meine persönliche Meinung, bitte nicht kommentieren! Oft gibt es unter einem Lied einige Kommentare, die viele Likes erhalten haben. In Verbindung mit der Tatsache, dass NetEase Cloud Music vor einigen Tagen ausgewählte Benutzerbewertungen in die U-Bahn gestellt hat, sind die Bewertungen von NetEase Cloud Music wieder populär geworden. Deshalb möchte ich die Kommentare von NetEase Cloud analysieren und die Muster entdecken, insbesondere die gemeinsamen Merkmale einiger heißer Kommentare. Zu diesem Zweck habe ich mit dem Crawlen von NetEase Cloud-Kommentaren begonnen.
Python verfügt über zwei integrierte Netzwerkbibliotheken, urllib und urllib2, aber diese beiden Bibliotheken sind nicht besonders bequem zu verwenden, daher verwenden wir hier eine gut angenommene Bibliothek eines Drittanbieters, Requests. Mithilfe von Anfragen können Sie komplexere Crawler-Aufgaben wie das Einrichten von Agenten und das Simulieren von Anmeldungen mit nur wenigen Codezeilen erledigen. Wenn Pip bereits installiert ist, verwenden Sie einfach Pip-Installationsanfragen, um es zu installieren. Die chinesische Dokumentadresse finden Sie hier: http://docs.python-requests.org/zh_CN/latest/user/quickstart.html. Wenn Sie Fragen haben, können Sie sich auf das offizielle Dokument beziehen über. Die beiden Bibliotheken urllib und urllib2 sind ebenfalls sehr nützlich. Ich werde sie Ihnen bei Gelegenheit vorstellen.
Bevor wir den Crawler offiziell vorstellen, sprechen wir zunächst über das grundlegende Funktionsprinzip des Crawlers. Wir wissen, dass wir im Wesentlichen eine bestimmte Anfrage an den Server senden, wenn wir unseren Browser öffnen Anfrage, Die Daten werden gemäß unserer Anfrage zurückgegeben, und dann werden die Daten über den Browser analysiert und uns präsentiert. Wenn wir Code verwenden, müssen wir diesen Schritt des Browsers überspringen, bestimmte Daten direkt an den Server senden und dann die vom Server zurückgegebenen Daten abrufen, um die gewünschten Informationen zu extrahieren. Das Problem besteht jedoch darin, dass der Server manchmal die von uns gesendete Anfrage überprüfen muss. Wenn er der Meinung ist, dass unsere Anfrage illegal ist, werden keine oder falsche Daten zurückgegeben. Um diese Situation zu vermeiden, müssen wir das Programm manchmal als normalen Benutzer tarnen, um erfolgreich eine Antwort vom Server zu erhalten. Wie kann man es verbergen? Dies hängt vom Unterschied ab, ob Benutzer über einen Browser auf eine Webseite zugreifen und ob wir über ein Programm auf eine Webseite zugreifen. Wenn wir über einen Browser auf eine Webseite zugreifen, senden wir im Allgemeinen zusätzlich zum Senden der aufgerufenen URL auch zusätzliche Informationen an den Dienst, z. B. Header (Header-Informationen) usw. Dies entspricht dem Identitätszertifikat des Anfrage, und der Server sieht sie. Anhand dieser Daten wissen wir, dass wir über einen normalen Browser darauf zugreifen, und die Daten werden gehorsam an uns zurückgegeben. Unser Programm muss also wie ein Browser sein und diese Informationen, die unsere Identität kennzeichnen, beim Senden einer Anfrage bereitstellen, damit wir die Daten reibungslos abrufen können. Manchmal müssen wir angemeldet sein, um einige Daten zu erhalten, also müssen wir die Anmeldung simulieren. Im Wesentlichen bedeutet die Anmeldung über den Browser, dass wir einige Formularinformationen an den Server senden (einschließlich Benutzername, Passwort und anderen Informationen). Nachdem der Server diese überprüft hat, können wir uns problemlos anmelden, unabhängig von den Daten Browser-Beiträge, wir senden sie so, wie sie sind. Was die simulierte Anmeldung betrifft, werde ich sie später genauer vorstellen. Natürlich läuft es manchmal nicht so reibungslos, da einige Websites über Anti-Crawling-Maßnahmen verfügen. Wenn beispielsweise der Zugriff zu schnell erfolgt, wird die IP-Adresse manchmal blockiert (typischerweise Douban). Zu diesem Zeitpunkt müssen wir noch einen Proxyserver einrichten, d. h. unsere IP-Adresse ändern. Wie das konkret geht, wird später besprochen.
Lassen Sie mich abschließend noch einen kleinen Trick vorstellen, der meiner Meinung nach beim Schreiben von Crawlern sehr nützlich ist. Wenn Sie Firefox oder Chrome verwenden, ist Ihnen möglicherweise ein Ort namens Entwicklertools (Chrome) oder Webkonsole (Firefox) aufgefallen. Dieses Tool ist sehr nützlich, da wir beim Besuch einer Website deutlich sehen können, welche Informationen der Browser sendet und welche Informationen der Server zurückgibt. Diese Informationen sind der Schlüssel zum Schreiben eines Crawlers. Unten sehen Sie, wie nützlich es sein kann.
---------------- ------ --------Die offizielle Starttrennlinie------------------------------ ------ -
Öffnen Sie zunächst die Webversion von NetEase Cloud Music und wählen Sie einen Song aus, um dessen Webseite zu öffnen Nehmen Sie als Beispiel Jay Chous „Sunny Day“. Wie in Abbildung 1 unten gezeigt
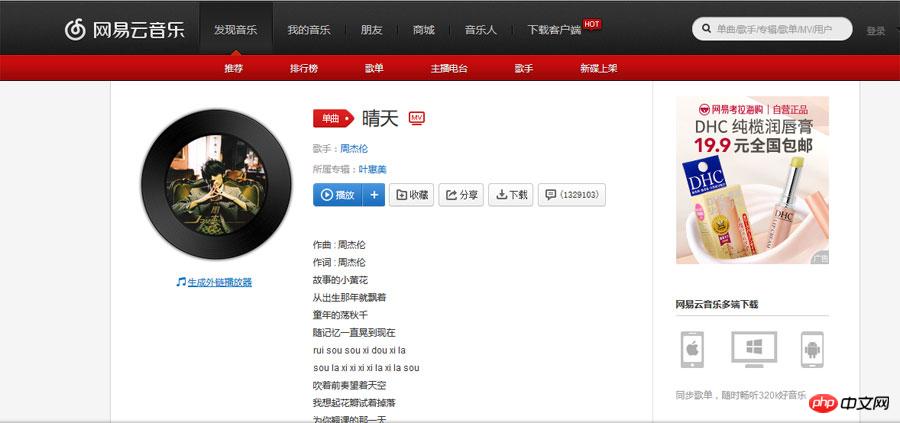
Abbildung 1
Öffnen Sie als Nächstes die Webkonsole (wenn Sie Chrom verwenden, öffnen Sie den Entwickler Tools, wenn es sich um einen anderen Browser handelt. Das Gerät sollte ähnlich sein), wie in Abbildung 2 unten gezeigt
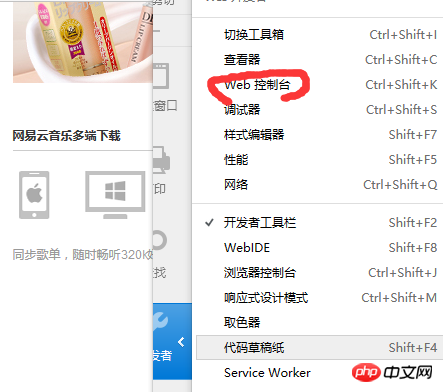
Abbildung 2
Dann Zu diesem Zeitpunkt müssen wir auf das Netzwerk klicken, alle Informationen löschen und dann auf „Erneut senden“ klicken (entspricht dem Aktualisieren des Browsers), damit wir intuitiv sehen können, welche Informationen der Browser gesendet hat und auf welche Informationen der Server geantwortet hat. Wie in Abbildung 3 unten gezeigt
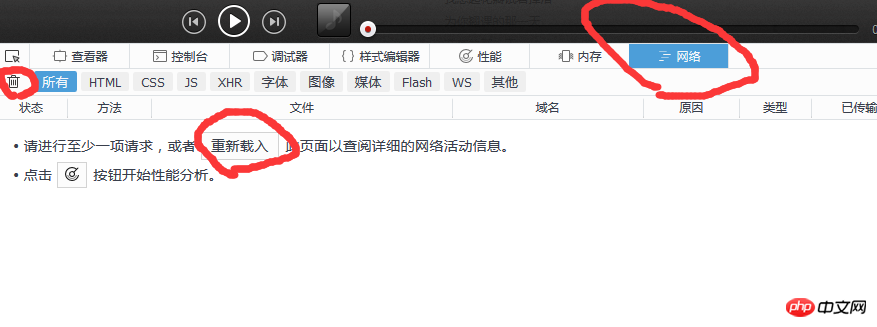
Abbildung 3
Die nach der Aktualisierung erhaltenen Daten sind in Abbildung 4 unten dargestellt:

Abbildung 4
Sie können sehen, dass der Browser viele Informationen sendet. Welche wollen wir also? Hier können wir anhand des Statuscodes eine vorläufige Beurteilung vornehmen. Der Statuscode ist hier 200, was bedeutet, dass die Anfrage normal ist, und 304, was bedeutet, dass sie abnormal ist (es gibt viele Typen). Wenn Sie mehr darüber erfahren möchten, können Sie selbst danach suchen. Auf die spezifische Bedeutung von 304 werde ich hier nicht eingehen. Daher müssen wir uns im Allgemeinen nur Anfragen mit dem Statuscode 200 ansehen. Außerdem können wir durch die Vorschau in der rechten Spalte grob beobachten, welche Informationen der Server zurückgibt (oder die Antwort anzeigen). Wie in Abbildung 5 unten gezeigt:
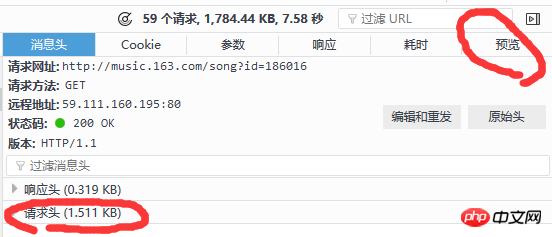
Abbildung 5
Durch die Kombination dieser beiden Methoden können wir schnell die Anfrage finden, die wir analysieren möchten. Beachten Sie, dass die Anforderungs-URL-Spalte in Abbildung 5 die URL ist, die wir anfordern möchten. Es gibt zwei Anforderungsmethoden: get und post. Eine weitere Sache, auf die man sich konzentrieren muss, ist der Anforderungsheader, der den Benutzeragenten (Clientinformationen) enthält. ), Referenz (woher man springen soll) und andere Informationen Im Allgemeinen bringen wir die Header-Informationen mit, unabhängig davon, ob es sich um die Get- oder Post-Methode handelt. Die Header-Informationen sind in Abbildung 6 unten dargestellt:
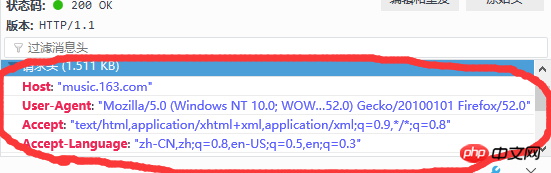
Abbildung 6
Darüber hinaus ist Folgendes zu beachten: Anfragen abrufen Sind die Anforderungsparameter im Allgemeinen direkt? Parameter1=Wert1&Parameter2=Wert2 usw. werden in dieser Form gesendet, sodass keine zusätzlichen Anforderungsparameter erforderlich sind. Bei Post-Anfragen müssen im Allgemeinen zusätzliche Parameter bereitgestellt werden, anstatt die Parameter direkt in die URL einzufügen. Daher müssen wir manchmal auch bezahlen Achten Sie auf die Parameterspalte. Nach sorgfältiger Suche haben wir schließlich die ursprüngliche kommentarbezogene Anfrage unter http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016?csrf_token= gefunden, wie in Abbildung 7 unten dargestellt:

Abbildung 7
Klicken Sie auf diese Anfrage, und wir stellen fest, dass es sich um eine Post-Anfrage handelt. Die Anfrage enthält zwei Parameter, einen Parameter. und der andere ist encSecKey. Die Werte dieser beiden Parameter sind sehr lang und es fühlt sich an, als wären sie verschlüsselt. Wie in Abbildung 8 unten dargestellt:
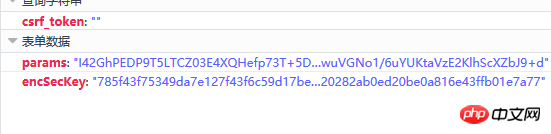
Abbildung 8
Die vom Server zurückgegebenen Daten zu Kommentaren liegen im JSON-Format vor. die sehr umfangreiche Informationen enthält (z. B. Informationen über Kommentatoren, Kommentardatum, Anzahl der Likes, Kommentarinhalt usw.), wie in Abbildung 9 unten dargestellt: (Tatsächlich ist hotComments ein heißer Kommentar, und comments ist ein Array von Kommentaren )
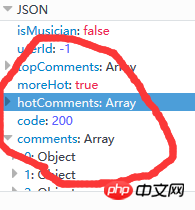
Abbildung 9
Zu diesem Zeitpunkt haben wir die Richtung festgelegt, das heißt, wir müssen nur noch die beiden bestimmen Parameterwerte von params und encSecKey Dieses Problem beschäftigt uns. Ich habe einen Nachmittag damit verbracht, die Verschlüsselungsmethode dieser beiden Parameter herauszufinden, aber ich habe ein Muster gefunden: http://music.163.com/weapi/v1/. resources/comments/R_SO_4_186016?csrf_token= Die Zahl nach R_SO_4_ ist der ID-Wert des Songs für die Parameter- und encSecKey-Werte verschiedener Songs, wenn die beiden Parameterwerte eines Songs wie A sind Wird an Lied B übergeben, ist dieser Parameter für dieselbe Seitenzahl universell, d. h. wenn die beiden Parameterwerte der ersten Seite von A an die beiden Parameter eines anderen Liedes übergeben werden, werden die Kommentare weitergegeben Die erste Seite des entsprechenden Songs kann abgerufen werden. Für die zweite Seite sind die Seiten der dritten Seite usw. ähnlich. Aber leider sind die verschiedenen Seitenparameter unterschiedlich. Diese Methode kann nur eine begrenzte Anzahl von Seiten erfassen (natürlich reicht es aus, die Gesamtzahl der Kommentare und beliebten Kommentare zu erfassen). wie diese beiden Parameterwerte verschlüsselt werden. Ich dachte, ich hätte es nicht verstanden, also bin ich gestern Abend zu Zhihu gegangen, um mit dieser Frage zu suchen, und habe tatsächlich die Antwort gefunden. Bisher haben wir erklärt, wie alle Daten der Kommentare von NetEase Cloud Music erfasst werden.
Wie üblich habe ich den Code zuletzt hochgeladen und er hat in meinem eigenen Test funktioniert:
#!/usr/bin/env python2.7
# -*- coding: utf-8 -*-
# @Time : 2017/3/28 8:46
# @Author : Lyrichu
# @Email : 919987476@qq.com
# @File : NetCloud_spider3.py
'''
@Description:
网易云音乐评论爬虫,可以完整爬取整个评论
部分参考了@平胸小仙女的文章(地址:https://www.zhihu.com/question/36081767)
post加密部分也给出了,可以参考原帖:
作者:平胸小仙女
链接:https://www.zhihu.com/question/36081767/answer/140287795
来源:知乎
'''
from Crypto.Cipher import AES
import base64
import requests
import json
import codecs
import time
# 头部信息
headers = {
'Host':"music.163.com",
'Accept-Language':"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
'Accept-Encoding':"gzip, deflate",
'Content-Type':"application/x-www-form-urlencoded",
'Cookie':"_ntes_nnid=754361b04b121e078dee797cdb30e0fd,1486026808627; _ntes_nuid=754361b04b121e078dee797cdb30e0fd; JSESSIONID-WYYY=yfqt9ofhY%5CIYNkXW71TqY5OtSZyjE%2FoswGgtl4dMv3Oa7%5CQ50T%2FVaee%2FMSsCifHE0TGtRMYhSPpr20i%5CRO%2BO%2B9pbbJnrUvGzkibhNqw3Tlgn%5Coil%2FrW7zFZZWSA3K9gD77MPSVH6fnv5hIT8ms70MNB3CxK5r3ecj3tFMlWFbFOZmGw%5C%3A1490677541180; _iuqxldmzr_=32; vjuids=c8ca7976.15a029d006a.0.51373751e63af8; vjlast=1486102528.1490172479.21; __gads=ID=a9eed5e3cae4d252:T=1486102537:S=ALNI_Mb5XX2vlkjsiU5cIy91-ToUDoFxIw; vinfo_n_f_l_n3=411a2def7f75a62e.1.1.1486349441669.1486349607905.1490173828142; P_INFO=m15527594439@163.com|1489375076|1|study|00&99|null&null&null#hub&420100#10#0#0|155439&1|study_client|15527594439@163.com; NTES_CMT_USER_INFO=84794134%7Cm155****4439%7Chttps%3A%2F%2Fsimg.ws.126.net%2Fe%2Fimg5.cache.netease.com%2Ftie%2Fimages%2Fyun%2Fphoto_default_62.png.39x39.100.jpg%7Cfalse%7CbTE1NTI3NTk0NDM5QDE2My5jb20%3D; usertrack=c+5+hljHgU0T1FDmA66MAg==; Province=027; City=027; _ga=GA1.2.1549851014.1489469781; __utma=94650624.1549851014.1489469781.1490664577.1490672820.8; __utmc=94650624; __utmz=94650624.1490661822.6.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; playerid=81568911; __utmb=94650624.23.10.1490672820",
'Connection':"keep-alive",
'Referer':'http://music.163.com/'
}
# 设置代理服务器
proxies= {
'http:':'http://121.232.146.184',
'https:':'https://144.255.48.197'
}
# offset的取值为:(评论页数-1)*20,total第一页为true,其余页为false
# first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}' # 第一个参数
second_param = "010001" # 第二个参数
# 第三个参数
third_param = "00e0b509f6259df8642dbc35662901477df22677ec152b5ff68ace615bb7b725152b3ab17a876aea8a5aa76d2e417629ec4ee341f56135fccf695280104e0312ecbda92557c93870114af6c9d05c4f7f0c3685b7a46bee255932575cce10b424d813cfe4875d3e82047b97ddef52741d546b8e289dc6935b3ece0462db0a22b8e7"
# 第四个参数
forth_param = "0CoJUm6Qyw8W8jud"
# 获取参数
def get_params(page): # page为传入页数
iv = "0102030405060708"
first_key = forth_param
second_key = 16 * 'F'
if(page == 1): # 如果为第一页
first_param = '{rid:"", offset:"0", total:"true", limit:"20", csrf_token:""}'
h_encText = AES_encrypt(first_param, first_key, iv)
else:
offset = str((page-1)*20)
first_param = '{rid:"", offset:"%s", total:"%s", limit:"20", csrf_token:""}' %(offset,'false')
h_encText = AES_encrypt(first_param, first_key, iv)
h_encText = AES_encrypt(h_encText, second_key, iv)
return h_encText
# 获取 encSecKey
def get_encSecKey():
encSecKey = "257348aecb5e556c066de214e531faadd1c55d814f9be95fd06d6bff9f4c7a41f831f6394d5a3fd2e3881736d94a02ca919d952872e7d0a50ebfa1769a7a62d512f5f1ca21aec60bc3819a9c3ffca5eca9a0dba6d6f7249b06f5965ecfff3695b54e1c28f3f624750ed39e7de08fc8493242e26dbc4484a01c76f739e135637c"
return encSecKey
# 解密过程
def AES_encrypt(text, key, iv):
pad = 16 - len(text) % 16
text = text + pad * chr(pad)
encryptor = AES.new(key, AES.MODE_CBC, iv)
encrypt_text = encryptor.encrypt(text)
encrypt_text = base64.b64encode(encrypt_text)
return encrypt_text
# 获得评论json数据
def get_json(url, params, encSecKey):
data = {
"params": params,
"encSecKey": encSecKey
}
response = requests.post(url, headers=headers, data=data,proxies = proxies)
return response.content
# 抓取热门评论,返回热评列表
def get_hot_comments(url):
hot_comments_list = []
hot_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容\n")
params = get_params(1) # 第一页
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
hot_comments = json_dict['hotComments'] # 热门评论
print("共有%d条热门评论!" % len(hot_comments))
for item in hot_comments:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userID'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = userID + " " + nickname + " " + avatarUrl + " " + comment_time + " " + likedCount + " " + comment + u"\n"
hot_comments_list.append(comment_info)
return hot_comments_list
# 抓取某一首歌的全部评论
def get_all_comments(url):
all_comments_list = [] # 存放所有评论
all_comments_list.append(u"用户ID 用户昵称 用户头像地址 评论时间 点赞总数 评论内容\n") # 头部信息
params = get_params(1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
comments_num = int(json_dict['total'])
if(comments_num % 20 == 0):
page = comments_num / 20
else:
page = int(comments_num / 20) + 1
print("共有%d页评论!" % page)
for i in range(page): # 逐页抓取
params = get_params(i+1)
encSecKey = get_encSecKey()
json_text = get_json(url,params,encSecKey)
json_dict = json.loads(json_text)
if i == 0:
print("共有%d条评论!" % comments_num) # 全部评论总数
for item in json_dict['comments']:
comment = item['content'] # 评论内容
likedCount = item['likedCount'] # 点赞总数
comment_time = item['time'] # 评论时间(时间戳)
userID = item['user']['userId'] # 评论者id
nickname = item['user']['nickname'] # 昵称
avatarUrl = item['user']['avatarUrl'] # 头像地址
comment_info = unicode(userID) + u" " + nickname + u" " + avatarUrl + u" " + unicode(comment_time) + u" " + unicode(likedCount) + u" " + comment + u"\n"
all_comments_list.append(comment_info)
print("第%d页抓取完毕!" % (i+1))
return all_comments_list
# 将评论写入文本文件
def save_to_file(list,filename):
with codecs.open(filename,'a',encoding='utf-8') as f:
f.writelines(list)
print("写入文件成功!")
if __name__ == "__main__":
start_time = time.time() # 开始时间
url = "http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016/?csrf_token="
filename = u"晴天.txt"
all_comments_list = get_all_comments(url)
save_to_file(all_comments_list,filename)
end_time = time.time() #结束时间
print("程序耗时%f秒." % (end_time - start_time))Ich habe den obigen Code verwendet, um zwei von Jay Chous beliebten Songs „Sunny Day“ auszuführen und aufzunehmen " (mit mehr als 1,3 Millionen Kommentaren) und "Confession Balloon" (mit mehr als 200.000 Kommentaren), ersteres lief etwa 20 Minuten und letzteres mehr als 6.600 Sekunden (also fast 2 Stunden). Die Screenshots sind wie folgt:

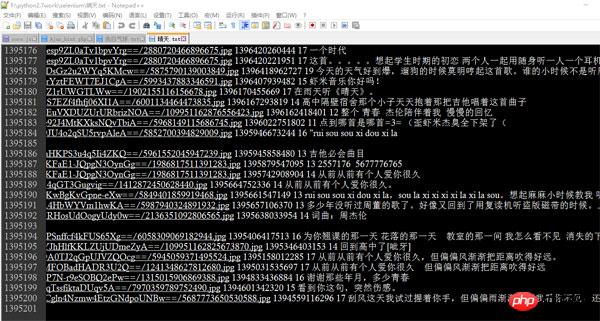
Beachten Sie, dass ich sie durch Leerzeichen getrennt habe. Jede Zeile enthält Benutzer-ID, Benutzer-Spitzname, Benutzer-Avatar, Adresse. Kommentarzeit, Gesamtzahl der Likes und Inhalt.
Das obige ist der detaillierte Inhalt vonTeilen Sie eine Python-Methode zum Crawlen beliebter Kommentare zu NetEase Cloud Music. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Python vs. C: Anwendungen und Anwendungsfälle verglichen
Apr 12, 2025 am 12:01 AM
Python vs. C: Anwendungen und Anwendungsfälle verglichen
Apr 12, 2025 am 12:01 AM
Python eignet sich für Datenwissenschafts-, Webentwicklungs- und Automatisierungsaufgaben, während C für Systemprogrammierung, Spieleentwicklung und eingebettete Systeme geeignet ist. Python ist bekannt für seine Einfachheit und sein starkes Ökosystem, während C für seine hohen Leistung und die zugrunde liegenden Kontrollfunktionen bekannt ist.
 Welche Arten von Dateien bestehen aus Oracle -Datenbanken?
Apr 11, 2025 pm 03:03 PM
Welche Arten von Dateien bestehen aus Oracle -Datenbanken?
Apr 11, 2025 pm 03:03 PM
Die Struktur der Oracle -Datenbankdatei umfasst: Datendatei: Speichern tatsächlicher Daten. Steuerdatei: Datenbankstrukturinformationen aufzeichnen. Protokolldateien neu wieder aufnehmen: Aktenübertragungsvorgänge aufzeichnen, um die Datenkonsistenz sicherzustellen. Parameterdatei: Enthält Datenbank, die über Parameter ausgeführt werden, um die Leistung zu optimieren. Archivprotokolldatei: Backup -Wiederherstellung der Protokolldatei für die Katastrophenwiederherstellung.
 So melden Sie sich in der Oracle -Datenbank an
Apr 11, 2025 pm 02:39 PM
So melden Sie sich in der Oracle -Datenbank an
Apr 11, 2025 pm 02:39 PM
Die Oracle -Datenbankanmeldung umfasst nicht nur Benutzername und Kennwort, sondern auch Verbindungszeichenfolgen (einschließlich Serverinformationen und Anmeldeinformationen) und Authentifizierungsmethoden. Es unterstützt SQL*Plus- und Programmiersprachanschlüsse und bietet Authentifizierungsoptionen wie Benutzername und Passwort, Kerberos und LDAP. Zu den häufigen Fehlern gehören Verbindungszeichenfolgenfehler und ungültige Benutzername/Passwörter, während sich Best Practices auf Verbindungspooling, parametrisierte Abfragen, Indizierung und Sicherheitsanmeldeinformationen konzentrieren.
 So verwenden Sie Debian Apache -Protokolle, um die Website der Website zu verbessern
Apr 12, 2025 pm 11:36 PM
So verwenden Sie Debian Apache -Protokolle, um die Website der Website zu verbessern
Apr 12, 2025 pm 11:36 PM
In diesem Artikel wird erläutert, wie die Leistung der Website verbessert wird, indem Apache -Protokolle im Debian -System analysiert werden. 1. Log -Analyse -Basics Apache Protokoll Datensätze Die detaillierten Informationen aller HTTP -Anforderungen, einschließlich IP -Adresse, Zeitstempel, URL, HTTP -Methode und Antwortcode. In Debian -Systemen befinden sich diese Protokolle normalerweise in /var/log/apache2/access.log und /var/log/apache2/error.log verzeichnis. Das Verständnis der Protokollstruktur ist der erste Schritt in der effektiven Analyse. 2. Tool mit Protokollanalyse Mit einer Vielzahl von Tools können Apache -Protokolle analysiert: Befehlszeilen -Tools: GREP, AWK, SED und andere Befehlszeilen -Tools.
 Python: Spiele, GUIs und mehr
Apr 13, 2025 am 12:14 AM
Python: Spiele, GUIs und mehr
Apr 13, 2025 am 12:14 AM
Python zeichnet sich in Gaming und GUI -Entwicklung aus. 1) Spielentwicklung verwendet Pygame, die Zeichnungen, Audio- und andere Funktionen bereitstellt, die für die Erstellung von 2D -Spielen geeignet sind. 2) Die GUI -Entwicklung kann Tkinter oder Pyqt auswählen. Tkinter ist einfach und einfach zu bedienen. PYQT hat reichhaltige Funktionen und ist für die berufliche Entwicklung geeignet.
 Was sind die Oracle -Datenbank auf der C -Festplatte?
Apr 11, 2025 pm 04:21 PM
Was sind die Oracle -Datenbank auf der C -Festplatte?
Apr 11, 2025 pm 04:21 PM
Der Versteckplatz der Oracle -Datenbank auf dem C -Laufwerk: Registrierung: Verwenden Sie den Registrierungseditor, um nach "Oracle" zu suchen, um Informationen einschließlich Installationspfad, Dienstname usw. zu finden Sorgfältige Aktion: Wenn Sie Oracle deinstallieren, müssen Sie nicht nur Dateien löschen, sondern auch die Registrierung und Dienste reinigen. Es wird empfohlen, das offizielle Deinstallieren -Tool zu verwenden oder professionelle Hilfe zu suchen. Space Management: Optimieren Sie den Speicherplatz, um die Installation von Oracle am C -Laufwerk zu vermeiden. Temporäre Dateien regelmäßig reinigen
 Laravel (PHP) gegen Python: Entwicklungsumgebungen und Ökosysteme
Apr 12, 2025 am 12:10 AM
Laravel (PHP) gegen Python: Entwicklungsumgebungen und Ökosysteme
Apr 12, 2025 am 12:10 AM
Der Vergleich zwischen Laravel und Python in der Entwicklungsumgebung und dem Ökosystem ist wie folgt: 1. Die Entwicklungsumgebung von Laravel ist einfach, nur PHP und Komponist sind erforderlich. Es bietet eine umfassende Auswahl an Erweiterungspaketen wie Laravelforge, aber die Wartung des Erweiterungspakets ist möglicherweise nicht rechtzeitig. 2. Die Entwicklungsumgebung von Python ist ebenfalls einfach, nur Python und PIP sind erforderlich. Das Ökosystem ist riesig und deckt mehrere Felder ab, aber das Versions- und Abhängigkeitsmanagement kann komplex sein.
 PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python: Vergleich von zwei beliebten Programmiersprachen
Apr 14, 2025 am 12:13 AM
PHP und Python haben jeweils ihre eigenen Vorteile und wählen nach den Projektanforderungen. 1.PHP ist für die Webentwicklung geeignet, insbesondere für die schnelle Entwicklung und Wartung von Websites. 2. Python eignet sich für Datenwissenschaft, maschinelles Lernen und künstliche Intelligenz mit prägnanter Syntax und für Anfänger.
