
 Datenbank
MySQL-Tutorial
Wie kann die Leistung optimiert werden? Detailliertes Beispiel für die Implementierung von Batch-Einfügungen durch MySQL zur Optimierung der Leistung
Datenbank
MySQL-Tutorial
Wie kann die Leistung optimiert werden? Detailliertes Beispiel für die Implementierung von Batch-Einfügungen durch MySQL zur Optimierung der Leistung
Wie kann die Leistung optimiert werden? Detailliertes Beispiel für die Implementierung von Batch-Einfügungen durch MySQL zur Optimierung der Leistung

In diesem Artikel wird hauptsächlich das MySQL-Tutorial zum Implementieren der Stapeleinfügung zur Optimierung der Leistung vorgestellt. Die Laufzeit wird angegeben, um den Vergleich nach der Leistungsoptimierung auszudrücken.
Für einige Daten mit großen Datenmengen Datenmengen. In großen Systemen ist die Datenbank nicht nur mit einer geringen Abfrageeffizienz, sondern auch mit einer langen Datenspeicherzeit konfrontiert. Insbesondere bei Berichtssystemen kann der Zeitaufwand für den Datenimport mehrere Stunden oder mehr als zehn Stunden pro Tag betragen. Daher ist es sinnvoll, die Leistung beim Einfügen in die Datenbank zu optimieren.
Nach einigen Leistungstests mit MySQL innodb habe ich als Referenz einige Methoden gefunden, die die Einfügeeffizienz verbessern können.
1. Fügen Sie mehrere Daten mit einer SQL-Anweisung ein.
Häufig verwendete Einfügeanweisungen wie
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1);
werden wie folgt geändert:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0), ('1', 'userid_1', 'content_1', 1);
Der geänderte Einfügevorgang kann die Einfügeeffizienz von verbessern das Programm. Der Hauptgrund für die hohe Effizienz der zweiten SQL-Ausführung besteht darin, dass die Anzahl der Protokolle nach dem Zusammenführen (Binlog von MySQL und Transaktionsprotokolle von Innodb) reduziert wird, wodurch die Menge und Häufigkeit des Protokolllöschens verringert und dadurch die Effizienz verbessert wird. Durch das Zusammenführen von SQL-Anweisungen kann auch die Anzahl der SQL-Anweisungsanalysen reduziert und die Netzwerkübertragungs-E/A reduziert werden.
Hier sind einige Testvergleichsdaten, mit denen ein einzelnes Datenelement importiert und für den Import in eine SQL-Anweisung umgewandelt und jeweils 100, 1.000 und 10.000 Datensätze getestet werden sollen.
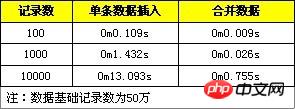
2. Führen Sie die Einfügeverarbeitung in der Transaktion durch.
Ändern Sie die Einfügung in:
START TRANSACTION; INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1); ... COMMIT;
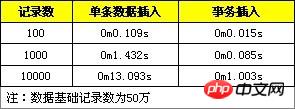
3. Geben Sie die Daten der Reihe nach ein.
Ordentliches Einfügen von Daten bedeutet, dass die eingefügten Datensätze in der Reihenfolge des Primärschlüssels angeordnet sind. Datum/Uhrzeit ist beispielsweise der Primärschlüssel des Datensatzes:
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('1', 'userid_1', 'content_1', 1); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('0', 'userid_0', 'content_0', 0); INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`) VALUES ('2', 'userid_2', 'content_2',2);
geändert in :
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('0', 'userid_0', 'content_0', 0);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('1', 'userid_1', 'content_1', 1);
INSERT INTO `insert_table` (`datetime`, `uid`, `content`, `type`)
VALUES ('2', 'userid_2', 'content_2',2);Da die Datenbank beim Einfügen Indexdaten verwalten muss, erhöhen ungeordnete Datensätze die Kosten für die Indexverwaltung. Wir können uns auf den von innodb verwendeten B+Tree-Index beziehen. Wenn sich jeder eingefügte Datensatz am Ende des Index befindet, ist die Indexpositionierungseffizienz sehr hoch, und die Indexanpassung ist gering Index, B+Tree erfordert mehr Rechenressourcen und die Indexpositionierungseffizienz der eingefügten Datensätze nimmt ab. Wenn die Datenmenge groß ist, kommt es zu häufigen Festplattenvorgängen.
Nachfolgend finden Sie einen Leistungsvergleich zwischen Zufallsdaten und sequentiellen Daten, die jeweils als 100, 1000, 10000, 100000 und 1 Million aufgezeichnet werden.
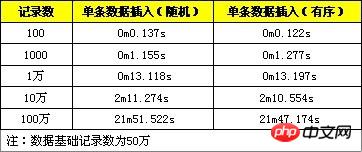
Aus den Testergebnissen geht hervor, dass sich die Leistung dieser Optimierungsmethode verbessert hat, die Verbesserung ist jedoch nicht sehr offensichtlich.
Umfassender Leistungstest:
Hier ist ein Test, der die oben genannten drei Methoden gleichzeitig verwendet, um die INSERT-Effizienz zu optimieren.
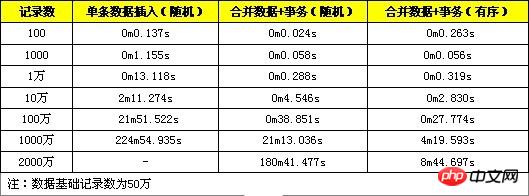
Aus den Testergebnissen geht hervor, dass die Leistungsverbesserung der Methode zum Zusammenführen von Daten + Transaktionen offensichtlich ist, wenn die Datenmenge klein ist Wenn die Datenmenge groß ist, ist die Leistungsverbesserung offensichtlich (mehr als 10 Millionen). Dies liegt daran, dass die Datenmenge zu diesem Zeitpunkt die Kapazität von innodb_buffer übersteigt Operationen, und die Leistung sinkt schnell. Die Methode, zusammengeführte Daten + Transaktionen + geordnete Daten zu verwenden, funktioniert immer noch gut, wenn das Datenvolumen mehrere zehn Millionen erreicht. Wenn das Datenvolumen groß ist, ist die Positionierung des geordneten Datenindex bequemer und erfordert keine häufigen Lese- und Schreibvorgänge auf der Festplatte Daher kann eine hohe Leistung aufrechterhalten werden.
Hinweise:
1. Beim Zusammenführen von Daten im selben SQL darf das SQL-Längenlimit nicht überschritten werden. Es kann über die max_allowed_packet-Konfiguration geändert werden . Der Standardwert ist 1M, wurde während des Tests auf 8M geändert.
2. Transaktionen müssen in ihrer Größe kontrolliert werden. Wenn eine Transaktion zu groß ist, kann dies die Ausführungseffizienz beeinträchtigen. MySQL verfügt über das Konfigurationselement innodb_log_buffer_size. Wenn dieser Wert überschritten wird, werden die Innodb-Daten auf die Festplatte geleert. Ein besserer Ansatz besteht daher darin, die Transaktion festzuschreiben, bevor die Daten diesen Wert erreichen.
Das obige ist der detaillierte Inhalt vonWie kann die Leistung optimiert werden? Detailliertes Beispiel für die Implementierung von Batch-Einfügungen durch MySQL zur Optimierung der Leistung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
PHPs Fähigkeiten zur Verarbeitung von Big-Data-Strukturen
May 08, 2024 am 10:24 AM
Fähigkeiten zur Verarbeitung von Big-Data-Strukturen: Chunking: Teilen Sie den Datensatz auf und verarbeiten Sie ihn in Blöcken, um den Speicherverbrauch zu reduzieren. Generator: Generieren Sie Datenelemente einzeln, ohne den gesamten Datensatz zu laden, geeignet für unbegrenzte Datensätze. Streaming: Lesen Sie Dateien oder fragen Sie Ergebnisse Zeile für Zeile ab, geeignet für große Dateien oder Remote-Daten. Externer Speicher: Speichern Sie die Daten bei sehr großen Datensätzen in einer Datenbank oder NoSQL.
 Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Wie optimiert man die MySQL-Abfrageleistung in PHP?
Jun 03, 2024 pm 08:11 PM
Die MySQL-Abfrageleistung kann durch die Erstellung von Indizes optimiert werden, die die Suchzeit von linearer Komplexität auf logarithmische Komplexität reduzieren. Verwenden Sie PreparedStatements, um SQL-Injection zu verhindern und die Abfrageleistung zu verbessern. Begrenzen Sie die Abfrageergebnisse und reduzieren Sie die vom Server verarbeitete Datenmenge. Optimieren Sie Join-Abfragen, einschließlich der Verwendung geeigneter Join-Typen, der Erstellung von Indizes und der Berücksichtigung der Verwendung von Unterabfragen. Analysieren Sie Abfragen, um Engpässe zu identifizieren. Verwenden Sie Caching, um die Datenbanklast zu reduzieren. Optimieren Sie den PHP-Code, um den Overhead zu minimieren.
 Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Wie verwende ich MySQL-Backup und -Wiederherstellung in PHP?
Jun 03, 2024 pm 12:19 PM
Das Sichern und Wiederherstellen einer MySQL-Datenbank in PHP kann durch Befolgen dieser Schritte erreicht werden: Sichern Sie die Datenbank: Verwenden Sie den Befehl mysqldump, um die Datenbank in eine SQL-Datei zu sichern. Datenbank wiederherstellen: Verwenden Sie den Befehl mysql, um die Datenbank aus SQL-Dateien wiederherzustellen.
 Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich mit PHP Daten in eine MySQL-Tabelle ein?
Jun 02, 2024 pm 02:26 PM
Wie füge ich Daten in eine MySQL-Tabelle ein? Mit der Datenbank verbinden: Stellen Sie mit mysqli eine Verbindung zur Datenbank her. Bereiten Sie die SQL-Abfrage vor: Schreiben Sie eine INSERT-Anweisung, um die einzufügenden Spalten und Werte anzugeben. Abfrage ausführen: Verwenden Sie die Methode query(), um die Einfügungsabfrage auszuführen. Bei Erfolg wird eine Bestätigungsmeldung ausgegeben.
 So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
So beheben Sie den Fehler „mysql_native_password nicht geladen' unter MySQL 8.4
Dec 09, 2024 am 11:42 AM
Eine der wichtigsten Änderungen, die in MySQL 8.4 (der neuesten LTS-Version von 2024) eingeführt wurden, besteht darin, dass das Plugin „MySQL Native Password“ nicht mehr standardmäßig aktiviert ist. Darüber hinaus entfernt MySQL 9.0 dieses Plugin vollständig. Diese Änderung betrifft PHP und andere Apps
 Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
Wie verwende ich gespeicherte MySQL-Prozeduren in PHP?
Jun 02, 2024 pm 02:13 PM
So verwenden Sie gespeicherte MySQL-Prozeduren in PHP: Verwenden Sie PDO oder die MySQLi-Erweiterung, um eine Verbindung zu einer MySQL-Datenbank herzustellen. Bereiten Sie die Anweisung zum Aufrufen der gespeicherten Prozedur vor. Führen Sie die gespeicherte Prozedur aus. Verarbeiten Sie die Ergebnismenge (wenn die gespeicherte Prozedur Ergebnisse zurückgibt). Schließen Sie die Datenbankverbindung.
 Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Wie erstelle ich eine MySQL-Tabelle mit PHP?
Jun 04, 2024 pm 01:57 PM
Das Erstellen einer MySQL-Tabelle mit PHP erfordert die folgenden Schritte: Stellen Sie eine Verbindung zur Datenbank her. Erstellen Sie die Datenbank, falls sie nicht vorhanden ist. Wählen Sie eine Datenbank aus. Tabelle erstellen. Führen Sie die Abfrage aus. Schließen Sie die Verbindung.
 Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Der Unterschied zwischen Oracle-Datenbank und MySQL
May 10, 2024 am 01:54 AM
Oracle-Datenbank und MySQL sind beide Datenbanken, die auf dem relationalen Modell basieren, aber Oracle ist in Bezug auf Kompatibilität, Skalierbarkeit, Datentypen und Sicherheit überlegen, während MySQL auf Geschwindigkeit und Flexibilität setzt und eher für kleine bis mittlere Datensätze geeignet ist. ① Oracle bietet eine breite Palette von Datentypen, ② bietet erweiterte Sicherheitsfunktionen, ③ ist für Anwendungen auf Unternehmensebene geeignet; ① MySQL unterstützt NoSQL-Datentypen, ② verfügt über weniger Sicherheitsmaßnahmen und ③ ist für kleine bis mittlere Anwendungen geeignet.
