
Memcached und Redis sind meiner Meinung nach die am häufigsten verwendeten Cache-Server der letzten Jahre und jeder kennt sie. Als ich vor zwei Jahren noch in der Schule war, habe ich ihre wichtigsten Quellcodes gelesen, um ihre Implementierungsmethoden kurz aus einer persönlichen Perspektive zu vergleichen Verständnis, ich freue mich über Korrekturen.
Die meisten in diesem Artikel verwendeten Architekturbilder stammen aus dem Internet. Einige der Bilder unterscheiden sich von der neuesten Implementierung, auf die im Artikel hingewiesen wurde.
Um den Quellcode einer Software zu lesen, müssen Sie zunächst verstehen, wofür die Software verwendet wird. Wofür werden Memcached und Redis verwendet? Wie wir alle wissen, werden Daten im Allgemeinen in einer Datenbank abgelegt, die Abfrage der Daten ist jedoch relativ langsam. Insbesondere bei vielen Benutzern nehmen häufige Abfragen viel Zeit in Anspruch. Was zu tun? Wo werden die Daten abgelegt, damit sie schnell abgefragt werden können? Das muss in Erinnerung bleiben. Memcached und Redis speichern Daten im Speicher und fragen sie auf Schlüsselwert-Weise ab, was die Effizienz erheblich verbessern kann. Daher werden sie im Allgemeinen als Cache-Server zum Zwischenspeichern häufig verwendeter Daten verwendet. Wenn Abfragen erforderlich sind, werden sie direkt von ihnen abgerufen, was die Anzahl der Datenbankabfragen reduziert und die Abfrageeffizienz verbessert.
Wie stellen Memcached und Redis Dienste bereit? Es handelt sich um unabhängige Prozesse, die bei Bedarf in Daemon-Prozesse umgewandelt werden können. Wenn unser Benutzerprozess die Dienste Memcached und Redis nutzen möchte, ist eine Kommunikation zwischen Prozessen erforderlich. Da sich der Benutzerprozess, Memcached und Redis nicht unbedingt auf demselben Computer befinden, muss die Kommunikation zwischen Netzwerken unterstützt werden. Daher sind Memcached und Redis selbst Netzwerkserver, und Benutzerprozesse übertragen mit ihnen Daten über das Netzwerk. Die einfachste und am häufigsten verwendete Methode ist natürlich die Verwendung einer TCP-Verbindung. Darüber hinaus unterstützen sowohl Memcached als auch Redis das UDP-Protokoll. Und wenn sich der Benutzerprozess auf demselben Computer wie Memcached und Redis befindet, kann auch die Unix-Domain-Socket-Kommunikation verwendet werden.
Beginnen wir damit, wie sie es umsetzen. Werfen wir zunächst einen Blick auf ihre Veranstaltungsmodelle.
Seit der Veröffentlichung von Epoll haben fast alle Netzwerkserver Select und Poll aufgegeben und durch Epoll ersetzt. Das Gleiche gilt für Redis, mit der Ausnahme, dass es auch Select und Poll unterstützt. Sie können konfigurieren, welches verwendet werden soll, im Allgemeinen wird jedoch Epoll verwendet. Darüber hinaus wird für BSD auch die Verwendung von kqueue unterstützt. Memcached basiert auf Libevent, aber die unterste Ebene von Libevent verwendet auch Epoll, sodass davon ausgegangen werden kann, dass alle Epoll verwenden. Die Eigenschaften von Epoll werden hier nicht vorgestellt. Es gibt viele Einführungsartikel online.
Sie alle verwenden Epoll für die Ereignisschleife, aber Redis ist ein Single-Thread-Server (Redis ist auch Multi-Threaded, aber mit Ausnahme des Hauptthreads haben andere Threads keine Ereignisschleife, sondern führen nur einige Hintergrundspeicherarbeiten aus), während Memcached ist Multi-Threaded von. Das Ereignismodell von Redis ist sehr einfach, mit nur einer Ereignisschleife, was eine einfache Reaktorimplementierung darstellt. Es gibt jedoch einen Lichtblick im Redis-Ereignismodell. Wir wissen, dass Epoll für fd ist und das zurückgegebene Ready-Ereignis nur fd ist. Das fd in Redis ist das fd des Sockets, das den Server und den Client verbindet Bei der Verarbeitung muss es auf dieser fd basieren. Wie finde ich bestimmte Kundeninformationen? Die übliche Verarbeitungsmethode besteht darin, einen Rot-Schwarz-Baum zum Speichern von FD- und Client-Informationen zu verwenden und FD zu durchsuchen. Die Effizienz ist lgn. Redis ist jedoch etwas Besonderes. Die Obergrenze der Anzahl der Redis-Clients kann festgelegt werden, das heißt, die Obergrenze des von Redis geöffneten fd kann gleichzeitig bekannt sein gleichzeitig wiederholt werden (das fd kann nur wiederhergestellt werden, nachdem es geschlossen wurde (), also verwendet redis ein Array und verwendet fd als Index des Arrays. Auf diese Weise sind die Elemente des Arrays , die Client-Informationen können direkt über fd gefunden werden. Die Sucheffizienz ist O(1), was auch die Komplexität beseitigt entsprechende Beziehung zwischen fd und connect, und ich wollte den rot-schwarzen Baum nicht selbst schreiben und habe ihn dann in STL verwendet, was dazu führte, dass das Projekt am Ende zu c++ wurde. Wer weiß, ob ich Sag es dir nicht?) Offensichtlich kann diese Methode nur für Netzwerkserver verwendet werden, bei denen die Obergrenze der Anzahl der Verbindungen nicht zu groß ist. HTTP-Server wie Nginx sind nicht geeignet, um einen eigenen rot-schwarzen Baum zu schreiben.
Memcached ist multithreaded und verwendet die Master-Worker-Methode. Der Hauptthread lauscht am Port, stellt eine Verbindung her und weist sie dann nacheinander jedem Worker-Thread zu. Jeder Slave-Thread verfügt über eine Ereignisschleife, die verschiedene Clients bedient. Die Pipeline-Kommunikation wird zwischen dem Master-Thread und dem Worker-Thread verwendet. Jeder Worker-Thread erstellt eine Pipe, speichert dann das Schreibende und das Leseende und fügt das Leseende zur Ereignisschleife hinzu, um auf lesbare Ereignisse zu warten. Gleichzeitig verfügt jeder Slave-Thread über eine bereitstehende Verbindungswarteschlange. Nachdem der Haupt-Thread eine Verbindung hergestellt hat, stellt er das verbundene Element in diese Warteschlange und schreibt dann einen Verbindungsbefehl an das Schreibende der Thread-Pipe, sodass die Pipe hinzugefügt wird Das Leseende der Ereignisschleife ist bereit, liest den Befehl aus dem Thread, analysiert den Befehl und stellt fest, dass eine Verbindung besteht. Anschließend wird die Verbindung aus seiner eigenen Bereitschaftswarteschlange abgerufen und verarbeitet. Der Vorteil von Multi-Threading besteht darin, dass die Vorteile von Multi-Core voll ausgenutzt werden können. Das Schreiben eines Programms ist jedoch etwas mühsamer und verfügt über verschiedene Sperren und Bedingungsvariablen für die Thread-Synchronisierung.
Die Kernaufgaben von Memcached und Redis bestehen darin, Daten im Speicher zu verwalten, und die Speicherverwaltung ist natürlich der Kerninhalt.
Schauen Sie sich zunächst an, wie sie Speicher zuweisen. Memcached verfügt über einen eigenen Speicherpool, was bedeutet, dass es im Voraus einen großen Speicherblock zuweist und dann den Speicher aus dem Speicherpool zuweist. Dadurch kann die Anzahl der Speicherzuweisungen reduziert und die Effizienz verbessert werden implementiert. Die Verwaltungsmethoden jedes Speicherpools variieren jedoch je nach spezifischen Umständen. Redis verfügt nicht über einen eigenen Speicherpool, sondern weist ihn bei Verwendung direkt zu, d Hat es keinen eigenen Speicherpool? Ist die Implementierung zu einfach, weil sie sich auf das Datenbankmodul konzentriert? Redis unterstützt jedoch die Verwendung von tcmalloc als Ersatz für malloc von glibc. Ersteres ist ein Google-Produkt und schneller als malloc von glibc.
Da Redis nicht über einen eigenen Speicherpool verfügt, ist die Verwaltung von Speicheranwendungen und -freigaben viel einfacher. Nur Malloc und Free können direkt durchgeführt werden, was sehr praktisch ist. Memcached unterstützt Speicherpools, sodass Speicheranforderungen aus dem Speicherpool abgerufen und frei an den Speicherpool zurückgegeben werden. Daher sind viele zusätzliche Verwaltungsvorgänge erforderlich und die Implementierung ist sehr mühsam. Die Details des Slab-Mechanismus von Memcached werden erläutert später analysieren.
Werfen wir als Nächstes einen Blick auf ihren Kerninhalt, die Implementierung ihrer jeweiligen Datenbanken.
Memcached unterstützt nur Schlüsselwerte, d. h. nur ein Schlüssel kann einem Wert entsprechen. Seine Daten werden auch in Schlüssel-Wert-Paaren im Speicher gespeichert und es wird der Slab-Mechanismus verwendet.
Schauen wir uns zunächst an, wie Memcached Daten speichert, also Schlüssel-Wert-Paare speichert. Wie in der folgenden Abbildung dargestellt, wird jedes Schlüssel-Wert-Paar in einer Elementstruktur gespeichert, einschließlich zugehöriger Attribute sowie Schlüssel- und Wertwerte.
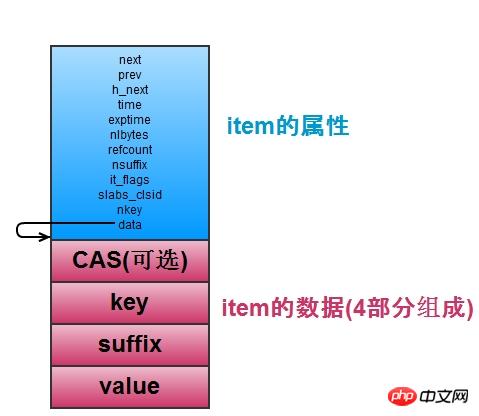
Elemente speichern Schlüssel-Wert-Paare. Wenn es viele Elemente gibt, ist es ein Problem, bestimmte Elemente zu finden. Daher verwaltet memcached eine Hash-Tabelle, die zum schnellen Auffinden von Elementen verwendet wird. Die Hash-Tabelle wendet die Open-Chain-Methode an (die gleiche wie Redis), um Schlüsselkonflikte zu lösen. Der verknüpfte Listenknoten ist der Zeiger des Elements Nächster Knoten der verknüpften Liste im Bucket. Die Hash-Tabelle unterstützt die Erweiterung (Erweiterung, wenn die Anzahl der Elemente mehr als das 1,5-fache der Anzahl der Buckets beträgt). Normalerweise wird die primäre_hashtable verwendet, aber beim Erweitern wird old_hashtable = Primary_hashtable festgelegt Primary_hashtable wird auf die neu angewendete Hash-Tabelle gesetzt (multiplizieren Sie die Anzahl der Buckets mit 2), und verschieben Sie dann die Daten in der old_hashtable der Reihe nach in die neue Hash-Tabelle und verwenden Sie eine Variable expand_bucket, um aufzuzeichnen, wie viele Buckets es gab Nachdem die Verschiebung abgeschlossen ist, geben Sie die ursprüngliche old_hashtable frei (Redis hat auch zwei Hash-Tabellen, die ebenfalls verschoben werden, aber nicht durch den Hintergrund-Thread abgeschlossen werden, sondern jeweils einen Bucket verschieben). Der Erweiterungsvorgang wird von einem Hintergrunderweiterungsthread abgeschlossen. Wenn eine Erweiterung erforderlich ist, werden Bedingungsvariablen verwendet, um dies zu benachrichtigen. Nach Abschluss der Erweiterung wird die Bedingungsvariable blockiert, die auf die Erweiterung wartet. Auf diese Weise kann ein Element beim Erweitern entweder in „primary_hashtable“ oder „old_hashtable“ gefunden werden. Sie müssen die Position seines Buckets und die Größe von „expand_bucket“ vergleichen, um festzustellen, in welcher Tabelle es sich befindet.
Woher stammt der Artikel? aus Platte. Wie in der Abbildung unten gezeigt, verfügt Memcached über viele Plattenklassen, die Platten verwalten. Jede Platte ist tatsächlich eine Sammlung von Stämmen. Die tatsächlichen Elemente werden im Stamm zugeordnet, und jedem Stamm wird ein Element zugewiesen. Die Größe des Stammes in einer Platte ist gleich. Bei verschiedenen Platten nimmt die Größe des Stammes proportional zu. Wenn Sie einen neuen Artikel beantragen müssen, gilt die Regel als der kleinste Stamm größer als es. Auf diese Weise werden Artikel unterschiedlicher Größe in verschiedene Slabs eingeteilt und von verschiedenen Slab-Klassen verwaltet. Der Nachteil besteht darin, dass etwas Speicher verschwendet wird, da ein Stamm möglicherweise größer als das Element ist, wie in Abbildung 2 dargestellt. Wählen Sie bei der Zuweisung eines 100-B-Elements den Stamm 112 aus, es werden jedoch 12 B verschwendet, und das ist der Fall Ein Teil der Speicherressource wird nicht verwendet.
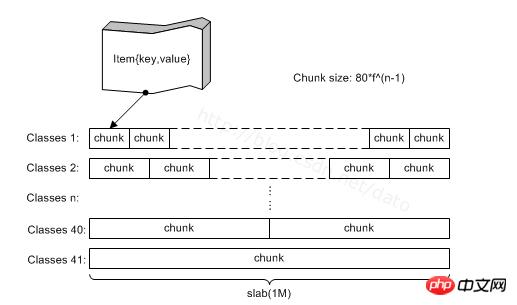
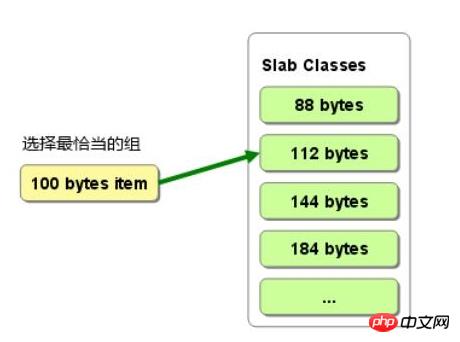
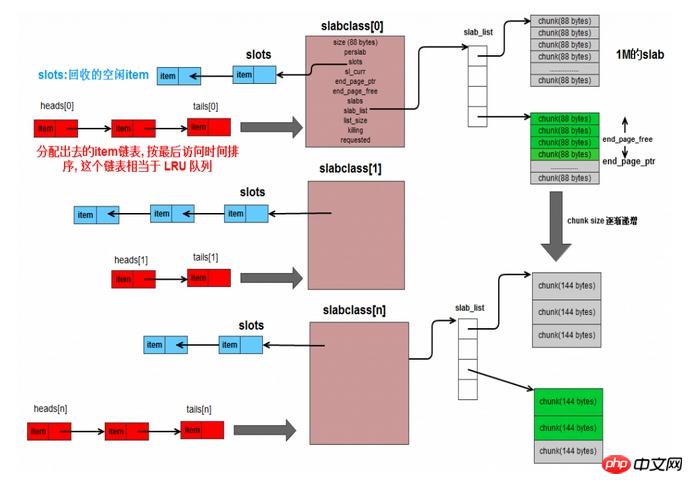
Wie im Bild oben gezeigt, ist die gesamte Struktur wie folgt: Eine Plattenklasse verfügt über eine Plattenliste, die mehrere Platten in derselben Plattenklasse verwalten kann. Die Slab-Klasse verfügt über einen Zeiger-Slot, der die nicht zugewiesenen Elemente speichert, die freigegeben wurden (nicht wirklich freier Speicher, sondern nur nicht mehr verwendet). Zeit, die sie benötigen. Wenn Sie ein Element in der aktuellen Platte zuweisen, können Sie direkt auf den Slot zugreifen, unabhängig davon, ob die Zuordnung des Elements aufgehoben oder freigegeben wurde.
Dann entspricht jede Slab-Klasse einer verknüpften Liste mit einem Kopfarray und einem Endarray, in denen der Kopfknoten bzw. der Endknoten der verknüpften Liste gespeichert sind. Die Knoten in der verknüpften Liste sind die von der geänderten Plattenklasse zugewiesenen Elemente. Die neu zugewiesenen Elemente werden an der Spitze platziert. Die Elemente weiter hinten in der verknüpften Liste bedeuten, dass sie schon lange nicht mehr verwendet wurden. Wenn die Slabclass nicht über genügend Speicher verfügt und einige abgelaufene Elemente gelöscht werden muss, kann sie am Ende der verknüpften Liste gelöscht werden. Ja, diese verknüpfte Liste ist für die Implementierung von LRU konzipiert. Es reicht nicht aus, sich allein darauf zu verlassen, da die Abfrage der verknüpften Liste O(n) ist. Verwenden Sie daher beim Auffinden des Elements die Hash-Tabelle. Diese ist bereits in der Hash-Tabelle verfügbar Hash wird verwendet, um das Element zu finden, und dann kann die verknüpfte Liste die zuletzt verwendete Reihenfolge der Elemente speichern, was auch die Standardimplementierungsmethode von lru ist.
Suchen Sie jedes Mal, wenn Sie ein neues Element zuweisen müssen, nach der verknüpften Liste, die der Plattenklasse entspricht, und suchen Sie vom Ende nach vorne, um festzustellen, ob das Element abgelaufen ist. Wenn es abgelaufen ist, verwenden Sie das abgelaufene Element direkt als neues Element. Wenn es nicht abgelaufen ist, müssen Sie den Stamm von der Platte abtrennen. Wenn die Platte aufgebraucht ist, müssen Sie der Plattenklasse eine Platte hinzufügen.
Memcached unterstützt das Festlegen der Ablaufzeit, d. h. der Ablaufzeit, überprüft jedoch nicht regelmäßig, ob die Daten intern abgelaufen sind. Stattdessen überprüft Memcached die Ablaufzeit und wenn sie abläuft direkt einen Fehler zurückgeben. Dies hat den Vorteil, dass keine zusätzliche CPU zur Überprüfung der Ablaufzeit erforderlich ist. Der Nachteil besteht darin, dass die abgelaufenen Daten möglicherweise längere Zeit nicht verwendet werden und nicht freigegeben werden und Speicher belegen.
Memcached ist multithreaded und verwaltet nur eine Datenbank, sodass möglicherweise mehrere Clientprozesse mit denselben Daten arbeiten, was zu Problemen führen kann. Wenn beispielsweise A die Daten geändert hat und dann auch B die Daten geändert hat, wird die Operation von A überschrieben, und A weiß möglicherweise nicht, dass der aktuelle Status der Aufgabendaten von A der Wert ist, nachdem er sie geändert hat, was zu Problemen führen kann . Um dieses Problem zu lösen, verwendet memcached einfach das CAS-Protokoll: Das Element speichert bei jeder Aktualisierung (Änderung des Datenwerts) einen vorzeichenlosen 64-Bit-Int-Wert erhöht sich, und dann werden die Daten jedes Mal geändert. Zum Betrieb müssen Sie vergleichen, ob die vom Client-Prozess gesendete Versionsnummer mit der Versionsnummer des Elements auf der Serverseite übereinstimmt Ändern Sie den Vorgang, andernfalls werden fehlerhafte Daten angezeigt.
Das Obige ist eine Einführung in die Implementierung einer Schlüsselwertdatenbank durch memcached.
Erstens ist die Redis-Datenbank leistungsfähiger, da Redis im Gegensatz zu Memcached, das nur das Speichern von Zeichenfolgen unterstützt, fünf Datenstrukturen unterstützt: Zeichenfolge, Liste, Menge, sortierte Menge und Hash-Tabelle. Um beispielsweise die Informationen einer Person zu speichern, können Sie eine Hash-Tabelle verwenden, den Namen der Person als Schlüssel verwenden und dann Super, Alter 24, nennen. Über Schlüssel und Name können Sie den Namen Super erhalten, oder über Schlüssel und Alter. Sie können das Alter von 24 Jahren erreichen. Auf diese Weise müssen Sie, wenn Sie nur das Alter ermitteln müssen, nicht die gesamten Informationen der Person abrufen und dann von innen nach dem Alter suchen, sondern das Alter einfach direkt abrufen, was effizient und bequem ist.
Um diese Datenstrukturen zu implementieren, definiert Redis das abstrakte Objekt Redis-Objekt, wie unten gezeigt. Jedes Objekt hat einen Typ, insgesamt 5 Typen: Zeichenfolge, verknüpfte Liste, Menge, geordnete Menge, Hash-Tabelle. Um die Effizienz zu verbessern, bereitet Redis gleichzeitig mehrere Implementierungsmethoden für jeden Typ vor und wählt die geeignete Implementierungsmethode entsprechend dem spezifischen Szenario aus. Die Codierung stellt die Implementierungsmethode des Objekts dar. Anschließend wird die LRU des Objekts erfasst, also der Zeitpunkt des letzten Zugriffs. Gleichzeitig wird eine aktuelle Uhrzeit im Redis-Server erfasst (ungefährer Wert, da diese Uhrzeit nur in bestimmten Abständen aktualisiert wird, wenn der Server ausgeführt wird). Automatische Wartung). Aus der Differenz zwischen beiden kann berechnet werden, wie lange auf das Objekt nicht zugegriffen wurde. Dann gibt es auch eine Referenzzählung im Redis-Objekt, die zum Teilen des Objekts und zum Bestimmen der Löschzeit des Objekts verwendet wird. Schließlich wird ein void*-Zeiger verwendet, um auf den tatsächlichen Inhalt des Objekts zu zeigen. Offiziell ist es aufgrund der Verwendung abstrakter Redis-Objekte viel bequemer, Daten in der Datenbank zu verwalten. Alle Redis-Objektobjekte können einheitlich verwendet werden, wenn Objekttypen anhand des Typs unterschieden werden müssen. Und offiziell sieht der Redis-Code aufgrund der Übernahme dieses objektorientierten Ansatzes C++-Code sehr ähnlich, tatsächlich ist er jedoch vollständig in C geschrieben.
//#define REDIS_STRING 0 // 字符串类型
//#define REDIS_LIST 1 // 链表类型
//#define REDIS_SET 2 // 集合类型(无序的),可以求差集,并集等
//#define REDIS_ZSET 3 // 有序的集合类型
//#define REDIS_HASH 4 // 哈希类型
//#define REDIS_ENCODING_RAW 0 /* Raw representation */ //raw 未加工
//#define REDIS_ENCODING_INT 1 /* Encoded as integer */
//#define REDIS_ENCODING_HT 2 /* Encoded as hash table */
//#define REDIS_ENCODING_ZIPMAP 3 /* Encoded as zipmap */
//#define REDIS_ENCODING_LINKEDLIST 4 /* Encoded as regular linked list */
//#define REDIS_ENCODING_ZIPLIST 5 /* Encoded as ziplist */
//#define REDIS_ENCODING_INTSET 6 /* Encoded as intset */
//#define REDIS_ENCODING_SKIPLIST 7 /* Encoded as skiplist */
//#define REDIS_ENCODING_EMBSTR 8 /* Embedded sds
string encoding */
typedef struct redisObject {
unsigned type:4; // 对象的类型,包括 /* Object types */
unsigned encoding:4; // 底部为了节省空间,一种type的数据,
// 可 以采用不同的存储方式
unsigned lru:REDIS_LRU_BITS; /* lru time (relative to server.lruclock) */
int refcount; // 引用计数
void *ptr;
} robj;Schließlich ist Redis immer noch eine Schlüsselwertdatenbank, egal wie viele Datenstrukturen es unterstützt, der endgültige Speicher befindet sich immer noch im Schlüsselwertmodus, aber der Wert kann eine verknüpfte Liste, ein Satz, ein sortierter Satz, eine Hash-Tabelle usw. sein . Wie bei Memcached sind alle Schlüssel Zeichenfolgen, und Zeichenfolgen werden auch für bestimmte Speicherzwecke wie Sätze, sortierte Sätze, Hash-Tabellen usw. verwendet. In C gibt es keine vorgefertigte Zeichenfolge, daher besteht die erste Aufgabe von Redis darin, eine Zeichenfolge mit dem Namen sds (einfache dynamische Zeichenfolge) zu implementieren. Der folgende Code ist eine sehr einfache Struktur, in der die Gesamtspeicherlänge der Zeichenfolge gespeichert wird free bedeutet, dass es immer noch so viele Bytes gibt, die nicht verwendet werden, und dass buf bestimmte Daten speichert. Offensichtlich ist len-free die aktuelle Länge der Zeichenfolge.
struct sdshdr {
int len;
int free;
char buf[];
};字符串解决了,所有的key都存成sds就行了,那么key和value怎么关联呢?key-value的格式在脚本语言中很好处理,直接使用字典即可,C没有字典,怎么办呢?自己写一个呗(redis十分热衷于造轮子)。看下面的代码,privdata存额外信息,用的很少,至少我们发现。 dictht是具体的哈希表,一个dict对应两张哈希表,这是为了扩容(包括rehashidx也是为了扩容)。dictType存储了哈希表的属性。redis还为dict实现了迭代器(所以说看起来像c++代码)。
哈希表的具体实现是和mc类似的做法,也是使用开链法来解决冲突,不过里面用到了一些小技巧。比如使用dictType存储函数指针,可以动态配置桶里面元素的操作方法。又比如dictht中保存的sizemask取size(桶的数量)-1,用它与key做&操作来代替取余运算,加快速度等等。总的来看,dict里面有两个哈希表,每个哈希表的桶里面存储dictEntry链表,dictEntry存储具体的key和value。
前面说过,一个dict对于两个dictht,是为了扩容(其实还有缩容)。正常的时候,dict只使用dictht[0],当dict[0]中已有entry的数量与桶的数量达到一定的比例后,就会触发扩容和缩容操作,我们统称为rehash,这时,为dictht[1]申请rehash后的大小的内存,然后把dictht[0]里的数据往dictht[1]里面移动,并用rehashidx记录当前已经移动万的桶的数量,当所有桶都移完后,rehash完成,这时将dictht[1]变成dictht[0], 将原来的dictht[0]变成dictht[1],并变为null即可。不同于memcached,这里不用开一个后台线程来做,而是就在event loop中完成,并且rehash不是一次性完成,而是分成多次,每次用户操作dict之前,redis移动一个桶的数据,直到rehash完成。这样就把移动分成多个小移动完成,把rehash的时间开销均分到用户每个操作上,这样避免了用户一个请求导致rehash的时候,需要等待很长时间,直到rehash完成才有返回的情况。不过在rehash期间,每个操作都变慢了点,而且用户还不知道redis在他的请求中间添加了移动数据的操作,感觉redis太贱了 :-D
typedef struct dict {
dictType *type; // 哈希表的相关属性
void *privdata; // 额外信息
dictht ht[2]; // 两张哈希表,分主和副,用于扩容
int rehashidx; /* rehashing not in progress if rehashidx == -1 */ // 记录当前数据迁移的位置,在扩容的时候用的
int iterators; /* number of iterators currently running */ // 目前存在的迭代器的数量
} dict;
typedef struct dictht {
dictEntry **table; // dictEntry是item,多个item组成hash桶里面的链表,table则是多个链表头指针组成的数组的指针
unsigned long size; // 这个就是桶的数量
// sizemask取size - 1, 然后一个数据来的时候,通过计算出的hashkey, 让hashkey & sizemask来确定它要放的桶的位置
// 当size取2^n的时候,sizemask就是1...111,这样就和hashkey % size有一样的效果,但是使用&会快很多。这就是原因
unsigned long sizemask;
unsigned long used; // 已经数值的dictEntry数量
} dictht;
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); // hash的方法
void *(*keyDup)(void *privdata, const void *key); // key的复制方法
void *(*valDup)(void *privdata, const void *obj); // value的复制方法
int (*keyCompare)(void *privdata, const void *key1, const void *key2); // key之间的比较
void (*keyDestructor)(void *privdata, void *key); // key的析构
void (*valDestructor)(void *privdata, void *obj); // value的析构
} dictType;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
struct dictEntry *next;
} dictEntry;有了dict,数据库就好实现了。所有数据读存储在dict中,key存储成dictEntry中的key(string),用void* 指向一个redis object,它可以是5种类型中的任何一种。如下图,结构构造是这样,不过这个图已经过时了,有一些与redis3.0不符合的地方。
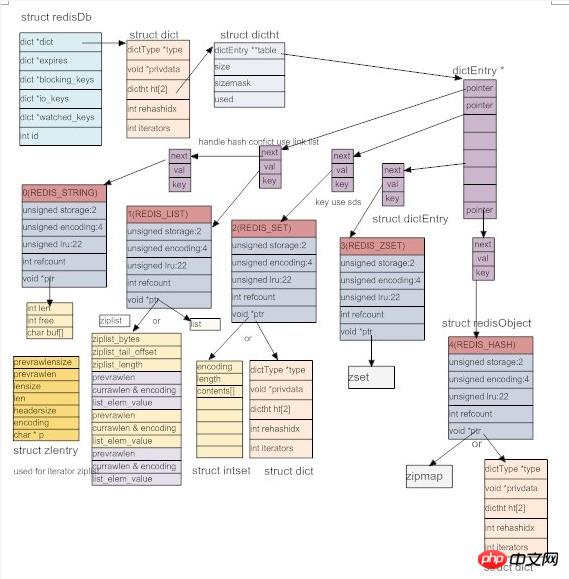
Jedes der Objekte vom Typ 5 verfügt über mindestens zwei zugrunde liegende Implementierungen. Es gibt drei Arten von Zeichenfolgen: REDIS_ENCODING_RAW, REDIS_ENCIDING_INT, REDIS_ENCODING_EMBSTR. Zu den Listen gehören: gewöhnliche bidirektionale verknüpfte Listen und komprimierte verknüpfte Listen. Komprimierte verknüpfte Listen bedeuten einfach, das Array in eine verknüpfte Liste umzuwandeln, einen kontinuierlichen Speicherplatz zu verwenden und dann die verknüpfte Liste zu simulieren Durch das Speichern der Größeninformationen der Zeichenfolge kann Platz gespart werden, es gibt jedoch Nebenwirkungen. Da es sich um einen kontinuierlichen Speicherplatz handelt, muss dieser beim Ändern der Speichergröße neu zugewiesen werden Wenn die Zeichenfolge gespeichert wird, kann es zu kontinuierlichen Aktualisierungen kommen (spezifische Implementierung. Bitte schauen Sie sich den Code im Detail an). Set hat dict und intset (verwenden Sie es, um alle Ganzzahlen zu speichern), sortiertes Set hat: Skiplist und Ziplist und die Hashtable-Implementierung hat komprimierte Liste, dict und Ziplist. Skiplist ist eine Sprungliste. Sie hat eine Effizienz, die der eines Rot-Schwarz-Baums nahe kommt, ist aber viel einfacher zu implementieren als ein Rot-Schwarz-Baum und wird daher übernommen (seltsam, hier wird das Rad nicht neu erfunden. Liegt es daran? dieses Rad ist etwas schwierig?). Die Hash-Tabelle kann mit dict implementiert werden. Der Schlüssel in jedem Diktat speichert den Schlüssel (der Schlüssel des Schlüssel-Wert-Paares in der Hash-Tabelle) und der Wert speichert den Wert. Beides sind Zeichenfolgen. Was das Diktat in der Menge betrifft, so speichert der Schlüssel in jedem Diktat den Wert eines bestimmten Elements in der Menge, und der Wert ist null. Das Zset (geordnete Menge) im Bild ist falsch. Zunächst ist Skiplist leicht zu verstehen, also stellen Sie es sich einfach als Ersatz für rot-schwarze Bäume vor. es kann auch sortiert werden. Wie verwende ich Ziplist zum Speichern von Zset? Erstens hat in zset jedes Element in der Menge eine Punktzahl, die zum Sortieren verwendet wird. Daher wird in der Ziplist entsprechend der Bewertung zuerst das Element gespeichert, dann seine Bewertung, dann das nächste Element und dann die Bewertung. Da es sich um einen kontinuierlichen Speicher handelt, muss der Speicher beim Einfügen oder Löschen neu zugewiesen werden. Wenn also die Anzahl der Elemente eine bestimmte Anzahl überschreitet oder die Anzahl der Zeichen eines Elements eine bestimmte Anzahl überschreitet, wählt Redis die Verwendung von Skiplist zum Implementieren von Zset (wenn derzeit Ziplist verwendet wird, werden die Daten in der Ziplist herausgenommen und in einer neuen Skiplist speichern und dann die Ziplist löschen und ändern. Dies ist die zugrunde liegende Konvertierung, und andere Arten von Redis-Objekten können ebenfalls konvertiert werden. Wie implementiert Ziplist außerdem Hashtable? Tatsächlich ist es sehr einfach: Speichern Sie einfach einen Schlüssel, speichern Sie einen Wert, speichern Sie dann einen Schlüssel und speichern Sie dann einen Wert. Es wird weiterhin sequentiell gespeichert, ähnlich wie bei der zset-Implementierung. Wenn also die Elemente eine bestimmte Anzahl überschreiten oder die Anzahl der Zeichen eines Elements eine bestimmte Anzahl überschreitet, wird es zur Implementierung in eine Hashtabelle konvertiert. Verschiedene zugrunde liegende Implementierungsmethoden können konvertiert werden, und Redis kann je nach Situation die am besten geeignete Implementierungsmethode auswählen. Dies ist auch der Vorteil der Verwendung einer ähnlichen objektorientierten Implementierungsmethode.
Es sollte darauf hingewiesen werden, dass bei der Verwendung von Skiplist zur Implementierung von Zset tatsächlich ein Diktat verwendet wird, das dieselben Schlüssel-Wert-Paare speichert. Warum? Da die Suche nach Skiplist nur lgn ist (kann n werden) und Diktat O (1) sein kann, wird ein Diktat verwendet, um die Suche zu beschleunigen. Da Skiplist und Diktat auf dasselbe Redis-Objekt verweisen können, wird zu viel Speicher benötigt nicht verschwendet werden. Warum nicht auch dict verwenden, um die Suche zu beschleunigen, wenn Sie ziplist zum Implementieren von zset verwenden? Da die Ziplist eine kleine Anzahl von Elementen unterstützt (wenn die Anzahl groß ist, wird sie in eine Skiplist umgewandelt) und die sequentielle Durchquerung ebenfalls schnell ist, ist kein Diktat erforderlich.
Aus dieser Sicht sind die oben genannten Objekte dict, dictType, dictHt, dictEntry und redis alle sehr durchdacht. Zusammen implementieren sie eine flexible und effiziente Datenbank mit objektorientierten Farben. Ich muss sagen, dass das Design der Redis-Datenbank immer noch sehr leistungsstark ist.
Im Gegensatz zu Memcached verfügt Redis über mehr als eine Datenbank, und standardmäßig sind es 16, nummeriert von 0-15. Kunden können wählen, welche Datenbank sie verwenden möchten. Standardmäßig wird Datenbank Nr. 0 verwendet. Unterschiedliche Datenbankdaten werden nicht gemeinsam genutzt, das heißt, derselbe Schlüssel kann in verschiedenen Datenbanken vorhanden sein, aber in derselben Datenbank muss der Schlüssel eindeutig sein.
Redis unterstützt auch die Einstellung der Ablaufzeit. Schauen wir uns das Redis-Objekt oben an. Es gibt kein Feld zum Speichern der Ablaufzeit. Redis fügt jeder Datenbank ein weiteres Diktat hinzu. Der Schlüssel im Diktateintrag ist ein Redis-Objekt, dessen Daten ein 64-Bit-Int sind. . Auf diese Weise können Sie bei der Feststellung, ob ein Schlüssel abgelaufen ist, ihn im Expire-Dikt finden, die Ablaufzeit herausnehmen und mit der aktuellen Zeit vergleichen. Warum das tun? Da nicht für alle Schlüssel eine Ablaufzeit festgelegt ist, wird bei Schlüsseln, für die keine Ablaufzeit festgelegt ist, Speicherplatz verschwendet. Verwenden Sie stattdessen ein Ablaufzeitdikt, um sie separat zu speichern, und Sie können den Speicher je nach Bedarf flexibel nutzen (. erkannt Wenn der Schlüssel abläuft, wird er aus dem Expire-Dikt gelöscht.
redis的expire 机制是怎样的呢? 与memcahed类似,redis也是惰性删除,即要用到数据时,先检查key是否过期,过期则删除,然后返回错误。单纯的靠惰性删除,上面说过可能会导致内存浪费,所以redis也有补充方案,redis里面有个定时执行的函数,叫servercron,它是维护服务器的函数,在它里面,会对过期数据进行删除,注意不是全删,而是在一定的时间内,对每个数据库的expire dict里面的数据随机选取出来,如果过期,则删除,否则再选,直到规定的时间到。即随机选取过期的数据删除,这个操作的时间分两种,一种较长,一种较短,一般执行短时间的删除,每隔一定的时间,执行一次长时间的删除。这样可以有效的缓解光采用惰性删除而导致的内存浪费问题。
以上就是redis的数据的实现,与memcached不同,redis还支持数据持久化,这个下面介绍。
redis和memcached的最大不同,就是redis支持数据持久化,这也是很多人选择使用redis而不是memcached的最大原因。 redis的持久化,分为两种策略,用户可以配置使用不同的策略。
4.1 RDB持久化
用户执行save或者bgsave的时候,就会触发RDB持久化操作。RDB持久化操作的核心思想就是把数据库原封不动的保存在文件里。
那如何存储呢?如下图, 首先存储一个REDIS字符串,起到验证的作用,表示是RDB文件,然后保存redis的版本信息,然后是具体的数据库,然后存储结束符EOF,最后用检验和。关键就是databases,看它的名字也知道,它存储了多个数据库,数据库按照编号顺序存储,0号数据库存储完了,才轮到1,然后是2, 一直到最后一个数据库。

每一个数据库存储方式如下,首先一个1字节的常量SELECTDB,表示切换db了,然后下一个接上数据库的编号,它的长度是可变的,然后接下来就是具体的key-value对的数据了。

int rdbSaveKeyValuePair(rio *rdb, robj *key, robj *val,
long long expiretime, long long now)
{
/* Save the expire time */
if (expiretime != -1) {
/* If this key is already expired skip it */
if (expiretime < now) return 0;
if (rdbSaveType(rdb,REDIS_RDB_OPCODE_EXPIRETIME_MS) == -1) return -1;
if (rdbSaveMillisecondTime(rdb,expiretime) == -1) return -1;
}
/* Save type, key, value */
if (rdbSaveObjectType(rdb,val) == -1) return -1;
if (rdbSaveStringObject(rdb,key) == -1) return -1;
if (rdbSaveObject(rdb,val) == -1) return -1;
return 1;
}由上面的代码也可以看出,存储的时候,先检查expire time,如果已经过期,不存就行了,否则,则将expire time存下来,注意,及时是存储expire time,也是先存储它的类型为REDIS_RDB_OPCODE_EXPIRETIME_MS,然后再存储具体过期时间。接下来存储真正的key-value对,首先存储value的类型,然后存储key(它按照字符串存储),然后存储value,如下图。

在rdbsaveobject中,会根据val的不同类型,按照不同的方式存储,不过从根本上来看,最终都是转换成字符串存储,比如val是一个linklist,那么先存储整个list的字节数,然后遍历这个list,把数据取出来,依次按照string写入文件。对于hash table,也是先计算字节数,然后依次取出hash table中的dictEntry,按照string的方式存储它的key和value,然后存储下一个dictEntry。 总之,RDB的存储方式,对一个key-value对,会先存储expire time(如果有的话),然后是value的类型,然后存储key(字符串方式),然后根据value的类型和底层实现方式,将value转换成字符串存储。这里面为了实现数据压缩,以及能够根据文件恢复数据,redis使用了很多编码的技巧,有些我也没太看懂,不过关键还是要理解思想,不要在意这些细节。
保存了RDB文件,当redis再启动的时候,就根据RDB文件来恢复数据库。由于以及在RDB文件中保存了数据库的号码,以及它包含的key-value对,以及每个key-value对中value的具体类型,实现方式,和数据,redis只要顺序读取文件,然后恢复object即可。由于保存了expire time,发现当前的时间已经比expire time大了,即数据已经超时了,则不恢复这个key-value对即可。
Das Speichern von RDB-Dateien ist ein riesiges Projekt, daher bietet Redis auch einen Mechanismus zum Speichern im Hintergrund. Das heißt, wenn bgsave ausgeführt wird, gibt Redis einen untergeordneten Prozess ab, damit der untergeordnete Prozess die gespeicherte Arbeit ausführen kann, während der übergeordnete Prozess weiterhin die normalen Datenbankdienste von redis bereitstellt. Da der untergeordnete Prozess den Adressraum des übergeordneten Prozesses kopiert, d. h. der untergeordnete Prozess besitzt die Datenbank, wenn der übergeordnete Prozess eine Verzweigung durchführt, führt der untergeordnete Prozess einen Speichervorgang aus und schreibt die Datenbank, die er vom übergeordneten Prozess geerbt hat, in eine temporäre Datei. Während des Kopierens des untergeordneten Prozesses zeichnet Redis die Anzahl der Änderungen (Dirty) der Datenbank auf. Wenn der untergeordnete Prozess abgeschlossen ist, wird das Signal SIGUSR1 an den übergeordneten Prozess gesendet. Wenn der übergeordnete Prozess dieses Signal abfängt, weiß er, dass der untergeordnete Prozess die Kopie abgeschlossen hat. Anschließend benennt der übergeordnete Prozess die vom untergeordneten Prozess gespeicherte temporäre Datei um die echte RDB-Datei (d. h. die eigentliche Speicherung erfolgt erst dann in die Zieldatei, das ist die sichere Vorgehensweise). Notieren Sie dann die Endzeit dieser Speicherung.
Hier liegt ein Problem vor. Während des Speicherzeitraums des untergeordneten Prozesses wurde die Datenbank des übergeordneten Prozesses geändert, und der übergeordnete Prozess zeichnet nur die Anzahl der Änderungen (ungültig) ohne Korrekturvorgänge auf. Es scheint, dass das, was RDB speichert, keine Echtzeitdatenbank ist, was etwas unprätentiös ist. Die AOF-Persistenz, die später eingeführt wird, löst dieses Problem jedoch.
Zusätzlich zur Ausführung des Befehls sava oder bgsave durch den Kunden können auch die RDB-Speicherbedingungen konfiguriert werden. Das heißt, es wird in der Konfigurationsdatei konfiguriert. Wenn die Datenbank innerhalb von t geändert wird, wird sie im Hintergrund gespeichert. Wenn Redis Cron bereitstellt, beurteilt es anhand der Anzahl der schmutzigen Elemente und des Zeitpunkts der letzten Speicherung, ob die Bedingungen erfüllt sind. Beachten Sie, dass es nur einen untergeordneten Prozess geben kann zum Speichern im Hintergrund, da das Speichern ein sehr teurer E/A-Vorgang ist. Eine große Anzahl von E/A-Vorgängen in mehreren Prozessen ist ineffizient und schwer zu verwalten.
4.2 AOF-Persistenz
Denken Sie zunächst über eine Frage nach: Erfordert das Speichern einer Datenbank das Speichern aller Daten in der Datenbank wie bei RDB? Gibt es eine andere Möglichkeit?
RDB speichert nur die endgültige Datenbank, also das Ergebnis. Wie kam es zu dem Ergebnis? Es wird durch verschiedene Befehle des Benutzers festgelegt, sodass das Ergebnis nicht gespeichert werden muss, sondern nur der Befehl gespeichert wird, der das Ergebnis erstellt hat. Im Gegensatz zu RDB speichert AOF die Datenbankdaten einzeln.
Schauen wir uns zunächst das Format der AOF-Datei an. Zuerst wird die Befehlslänge gespeichert, und dann wird der Befehl selbst im Detail gespeichert Sie wissen, wie die AOF-Datei gespeichert wird. Dies ist der vom Redis-Client ausgeführte Befehl.
Es gibt einen sds aof_buf auf dem Redis-Server. Wenn die aof-Persistenz aktiviert ist, wird jeder Befehl zum Ändern der Datenbank in diesem aof_buf gespeichert (die Zeichenfolge im Befehlsformat wird in der aof-Datei gespeichert), und dann wird die Ereignisschleife ausgeführt Rufen Sie im Server-Cron „flushaofbuf“ auf, schreiben Sie den Befehl in „aof_buf“ in die aof-Datei (eigentlich schreiben Sie, was tatsächlich geschrieben wird, ist der Kernelpuffer), löschen Sie dann „aof_buf“ und geben Sie die nächste Schleife ein. Auf diese Weise können alle Datenbankänderungen über die Befehle in der AOF-Datei wiederhergestellt werden, wodurch der Effekt einer Speicherung der Datenbank erzielt wird.
Es ist zu beachten, dass der in „flushaofbuf“ aufgerufene Schreibvorgang nur die Daten in den Kernelpuffer schreibt. Das tatsächliche Schreiben der Datei wird vom Kernel selbst entschieden und muss möglicherweise um einen bestimmten Zeitraum verzögert werden. Allerdings unterstützt Redis die Konfiguration nach jedem Schreibvorgang und ruft dann Sync in Redis auf, um die Daten im Kernel in die Datei zu schreiben. Sie können die Richtlinie auch so konfigurieren, dass die Synchronisierung einmal pro Sekunde erfolgt. Anschließend startet Redis einen Hintergrundthread (Redis ist also kein einzelner Thread, sondern nur eine einzelne Ereignisschleife) und dieser Hintergrundthread ruft die Synchronisierung jede Sekunde auf. Hier muss ich fragen, warum die Synchronisierung bei der Verwendung von RDB nicht berücksichtigt wurde. Da RDB im Gegensatz zu AOF mehrmals gespeichert wird, hat ein einmaliger Aufruf von sync während RDB keine Auswirkung. Bei Verwendung von bg save wird der untergeordnete Prozess von selbst beendet (exitiert) und der Puffer wird zu diesem Zeitpunkt in der Exit-Funktion geleert .-Bereich wird automatisch in die Datei geschrieben.
Wenn Sie es sich noch einmal ansehen: Wenn Sie nicht jeden Änderungsbefehl mit aof_buf speichern möchten, können Sie auch aof persistence verwenden. Redis stellt aof_rewrite bereit, das Befehle basierend auf der vorhandenen Datenbank generiert und die Befehle dann in die aof-Datei schreibt. Sehr seltsam, oder? Ja, es ist so toll. Bei der Ausführung von aof_rewrite wird die Redis-Variable in jeder Datenbank verwendet. Anschließend werden verschiedene Befehle basierend auf dem spezifischen Werttyp im Schlüssel-Wert-Paar generiert, z. B. Liste. Anschließend wird ein Befehl zum Speichern der Liste generiert, die Folgendes enthält Die zum Speichern der Liste erforderlichen Informationen werden in mehrere Befehle unterteilt. Erstellen Sie dann die Liste und fügen Sie dann Elemente zur Liste hinzu umgekehrt, basierend auf den Daten. Speichern Sie diese Befehle dann in der aof-Datei. Würde dies nicht den gleichen Effekt erzielen wie aof append?
再来看,aof格式也支持后台模式。执行aof_bgrewrite的时候,也是fork一个子进程,然后让子进程进行aof_rewrite,把它复制的数据库写入一个临时文件,然后写完后用新号通知父进程。父进程判断子进程的退出信息是否正确,然后将临时文件更名成最终的aof文件。好了,问题来了。在子进程持久化期间,可能父进程的数据库有更新,怎么把这个更新通知子进程呢?难道要用进程间通信么?是不是有点麻烦呢?你猜redis怎么做的?它根本不通知子进程。什么,不通知?那更新怎么办? 在子进程执行aof_bgrewrite期间,父进程会保存所有对数据库有更改的操作的命令(增,删除,改等),把他们保存在aof_rewrite_buf_blocks中,这是一个链表,每个block都可以保存命令,存不下时,新申请block,然后放入链表后面即可,当子进程通知完成保存后,父进程将aof_rewrite_buf_blocks的命令append 进aof文件就可以了。多么优美的设计,想一想自己当初还考虑用进程间通信,别人直接用最简单的方法就完美的解决了问题,有句话说得真对,越优秀的设计越趋于简单,而复杂的东西往往都是靠不住的。
至于aof文件的载入,也就是一条一条的执行aof文件里面的命令而已。不过考虑到这些命令就是客户端发送给redis的命令,所以redis干脆生成了一个假的客户端,它没有和redis建立网络连接,而是直接执行命令即可。首先搞清楚,这里的假的客户端,并不是真正的客户端,而是存储在redis里面的客户端的信息,里面有写和读的缓冲区,它是存在于redis服务器中的。所以,如下图,直接读入aof的命令,放入客户端的读缓冲区中,然后执行这个客户端的命令即可。这样就完成了aof文件的载入。
// 创建伪客户端
fakeClient = createFakeClient();
while(命令不为空) {
// 获取一条命令的参数信息 argc, argv
...
// 执行
fakeClient->argc = argc;
fakeClient->argv = argv;
cmd->proc(fakeClient);
}整个aof持久化的设计,个人认为相当精彩。其中有很多地方,值得膜拜。
redis另一个比memcached强大的地方,是它支持简单的事务。事务简单说就是把几个命令合并,一次性执行全部命令。对于关系型数据库来说,事务还有回滚机制,即事务命令要么全部执行成功,只要有一条失败就回滚,回到事务执行前的状态。redis不支持回滚,它的事务只保证命令依次被执行,即使中间一条命令出错也会继续往下执行,所以说它只支持简单的事务。
首先看redis事务的执行过程。首先执行multi命令,表示开始事务,然后输入需要执行的命令,最后输入exec执行事务。 redis服务器收到multi命令后,会将对应的client的状态设置为REDIS_MULTI,表示client处于事务阶段,并在client的multiState结构体里面保持事务的命令具体信息(当然首先也会检查命令是否能否识别,错误的命令不会保存),即命令的个数和具体的各个命令,当收到exec命令后,redis会顺序执行multiState里面保存的命令,然后保存每个命令的返回值,当有命令发生错误的时候,redis不会停止事务,而是保存错误信息,然后继续往下执行,当所有的命令都执行完后,将所有命令的返回值一起返回给客户。redis为什么不支持回滚呢?网上看到的解释出现问题是由于客户程序的问题,所以没必要服务器回滚,同时,不支持回滚,redis服务器的运行高效很多。在我看来,redis的事务不是传统关系型数据库的事务,要求CIAD那么非常严格,或者说redis的事务都不是事务,只是提供了一种方式,使得客户端可以一次性执行多条命令而已,就把事务当做普通命令就行了,支持回滚也就没必要了。

我们知道redis是单event loop的,在真正执行一个事物的时候(即redis收到exec命令后),事物的执行过程是不会被打断的,所有命令都会在一个event loop中执行完。但是在用户逐个输入事务的命令的时候,这期间,可能已经有别的客户修改了事务里面用到的数据,这就可能产生问题。所以redis还提供了watch命令,用户可以在输入multi之前,执行watch命令,指定需要观察的数据,这样如果在exec之前,有其他的客户端修改了这些被watch的数据,则exec的时候,执行到处理被修改的数据的命令的时候,会执行失败,提示数据已经dirty。 这是如何是实现的呢? 原来在每一个redisDb中还有一个dict watched_keys,watched_kesy中dictentry的key是被watch的数据库的key,而value则是一个list,里面存储的是watch它的client。同时,每个client也有一个watched_keys,里面保存的是这个client当前watch的key。在执行watch的时候,redis在对应的数据库的watched_keys中找到这个key(如果没有,则新建一个dictentry),然后在它的客户列表中加入这个client,同时,往这个client的watched_keys中加入这个key。当有客户执行一个命令修改数据的时候,redis首先在watched_keys中找这个key,如果发现有它,证明有client在watch它,则遍历所有watch它的client,将这些client设置为REDIS_DIRTY_CAS,表面有watch的key被dirty了。当客户执行的事务的时候,首先会检查是否被设置了REDIS_DIRTY_CAS,如果是,则表明数据dirty了,事务无法执行,会立即返回错误,只有client没有被设置REDIS_DIRTY_CAS的时候才能够执行事务。 需要指出的是,执行exec后,该client的所有watch的key都会被清除,同时db中该key的client列表也会清除该client,即执行exec后,该client不再watch任何key(即使exec没有执行成功也是一样)。所以说redis的事务是简单的事务,算不上真正的事务。
以上就是redis的事务,感觉实现很简单,实际用处也不是太大。
redis支持频道,即加入一个频道的用户相当于加入了一个群,客户往频道里面发的信息,频道里的所有client都能收到。
实现也很简单,也watch_keys实现差不多,redis server中保存了一个pubsub_channels的dict,里面的key是频道的名称(显然要唯一了),value则是一个链表,保存加入了该频道的client。同时,每个client都有一个pubsub_channels,保存了自己关注的频道。当用用户往频道发消息的时候,首先在server中的pubsub_channels找到改频道,然后遍历client,给他们发消息。而订阅,取消订阅频道不够都是操作pubsub_channels而已,很好理解。
同时,redis还支持模式频道。即通过正则匹配频道,如有模式频道p, 1, 则向普通频道p1发送消息时,会匹配p,1,除了往普通频道发消息外,还会往p,1模式频道中的client发消息。注意,这里是用发布命令里面的普通频道来匹配已有的模式频道,而不是在发布命令里制定模式频道,然后匹配redis里面保存的频道。实现方式也很简单,在redis server里面有个pubsub_patterns的list(这里为什么不用dict?因为pubsub_patterns的个数一般较少,不需要使用dict,简单的list就好了),它里面存储的是pubsubPattern结构体,里面是模式和client信息,如下所示,一个模式,一个client,所以如果有多个clint监听一个pubsub_patterns的话,在list面会有多个pubsubPattern,保存client和pubsub_patterns的对应关系。 同时,在client里面,也有一个pubsub_patterns list,不过里面存储的就是它监听的pubsub_patterns的列表(就是sds),而不是pubsubPattern结构体。
typedef struct pubsubPattern {
redisClient *client; // 监听的client
robj *pattern; // 模式
} pubsubPattern;当用户往一个频道发送消息的时候,首先会在redis server中的pubsub_channels里面查找该频道,然后往它的客户列表发送消息。然后在redis server里面的pubsub_patterns里面查找匹配的模式,然后往client里面发送消息。 这里并没有去除重复的客户,在pubsub_channels可能已经给某一个client发过message了,然后在pubsub_patterns中可能还会给用户再发一次(甚至更多次)。 估计redis认为这是客户程序自己的问题,所以不处理。
/* Publish a message */
int pubsubPublishMessage(robj *channel, robj *message) {
int receivers = 0;
dictEntry *de;
listNode *ln;
listIter li;
/* Send to clients listening for that channel */
de = dictFind(server.pubsub_channels,channel);
if (de) {
list *list = dictGetVal(de);
listNode *ln;
listIter li;
listRewind(list,&li);
while ((ln = listNext(&li)) != NULL) {
redisClient *c = ln->value;
addReply(c,shared.mbulkhdr[3]);
addReply(c,shared.messagebulk);
addReplyBulk(c,channel);
addReplyBulk(c,message);
receivers++;
}
}
/* Send to clients listening to matching channels */
if (listLength(server.pubsub_patterns)) {
listRewind(server.pubsub_patterns,&li);
channel = getDecodedObject(channel);
while ((ln = listNext(&li)) != NULL) {
pubsubPattern *pat = ln->value;
if (stringmatchlen((char*)pat->pattern->ptr,
sdslen(pat->pattern->ptr),
(char*)channel->ptr,
sdslen(channel->ptr),0)) {
addReply(pat->client,shared.mbulkhdr[4]);
addReply(pat->client,shared.pmessagebulk);
addReplyBulk(pat->client,pat->pattern);
addReplyBulk(pat->client,channel);
addReplyBulk(pat->client,message);
receivers++;
}
}
decrRefCount(channel);
}
return receivers;
}总的来看,redis比memcached的功能多很多,实现也更复杂。 不过memcached更专注于保存key-value数据(这已经能满足大多数使用场景了),而redis提供更丰富的数据结构及其他的一些功能。不能说redis比memcached好,不过从源码阅读的角度来看,redis的价值或许更大一点。 另外,redis3.0里面支持了集群功能,这部分的代码还没有研究,后续再跟进。
Das obige ist der detaillierte Inhalt vonVergleich zwischen Memcached und Redis. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Häufig verwendete Datenbanksoftware
Häufig verwendete Datenbanksoftware
 Was sind In-Memory-Datenbanken?
Was sind In-Memory-Datenbanken?
 Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
Welches hat eine schnellere Lesegeschwindigkeit, Mongodb oder Redis?
 So verwenden Sie Redis als Cache-Server
So verwenden Sie Redis als Cache-Server
 Wie Redis die Datenkonsistenz löst
Wie Redis die Datenkonsistenz löst
 Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
Wie stellen MySQL und Redis die Konsistenz beim doppelten Schreiben sicher?
 Welche Daten speichert der Redis-Cache im Allgemeinen?
Welche Daten speichert der Redis-Cache im Allgemeinen?
 Was sind die 8 Datentypen von Redis?
Was sind die 8 Datentypen von Redis?








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



