

Sammlung häufig verwendeter SQL Server-Spezifikationen
Auswahl des allgemeinen Feldtyps
1. Es wird empfohlen, den Datentyp varchar/nvarchar für den Zeichentyp
zu verwenden
2. Es wird empfohlen, für die Betragswährung den Datentyp „Geld“ zu verwenden
3. Es wird empfohlen, für die wissenschaftliche Notation den numerischen Datentyp zu verwenden
4. Es wird empfohlen, den Bigint-Datentyp für sich selbst vergrößernde Logos zu verwenden (die Datenmenge ist groß und kann nicht mit dem Int-Typ geladen werden, und die Transformation wird dann in Zukunft problematisch sein)
5. Als Zeittyp wird der Datentyp datetime
empfohlen
6. Es ist verboten, die alten Datentypen text, ntext und image zu verwenden
7. Es ist verboten, den XML-Datentyp varchar(max), nvarchar(max)
zu verwenden Einschränkungen und Indizes
Jede Tabelle muss einen Primärschlüssel
haben Jede Tabelle muss einen Primärschlüssel haben, der zur Durchsetzung der Entitätsintegrität verwendet wird
Eine einzelne Tabelle kann nur einen Primärschlüssel haben (leere und doppelte Daten sind nicht zulässig)
Versuchen Sie, Einzelfeld-Primärschlüssel zu verwenden
Fremdschlüssel sind nicht erlaubt
Fremdschlüssel erhöhen die Komplexität von Tabellenstrukturänderungen und Datenmigration
Fremdschlüssel wirken sich auf die Leistung von Einfügungen und Aktualisierungen aus. Sie müssen die primären Fremdschlüsseleinschränkungen überprüfen
Die Datenintegrität wird vom Programm kontrolliert
NULL-Attribut
Für die neu hinzugefügte Tabelle ist NULL in allen Feldern verboten
(Warum erlaubt die neue Tabelle kein NULL?
Das Zulassen von NULL-Werten erhöht die Komplexität der Anwendung. Sie müssen spezifischen Logikcode hinzufügen, um verschiedene unerwartete Fehler zu verhindern
Bei der dreiwertigen Logik müssen alle Abfragen mit Gleichheitszeichen ("=") ein isnull-Urteil hinzufügen.
Null=Null, Null!=Null, not(Null=Null), not(Null!=Null) sind alle unbekannt, nicht wahr)
Lassen Sie uns dies anhand eines Beispiels veranschaulichen:
Wenn die Daten in der Tabelle wie in der Abbildung dargestellt sind:

Sie möchten alle Daten außer dem Namen finden, der aa entspricht, und verwenden dann versehentlich SELECT * FROM NULLTEST WHERE NAME<>’aa’
Das Ergebnis war anders als erwartet. Tatsächlich wurde nur der Datensatz mit name=bb gefunden, nicht jedoch der Datensatz mit name=NULL
Wie finden wir dann alle Daten außer dem Namen gleich aa? Wir können nur die ISNULL-Funktion
verwenden SELECT * FROM NULLTEST WHERE ISNULL(NAME,1)<>’aa’
Sie wissen jedoch möglicherweise nicht, dass ISNULL zu schwerwiegenden Leistungsengpässen führen kann. Daher ist es in vielen Fällen am besten, die Benutzereingaben auf Anwendungsebene zu begrenzen, um sicherzustellen, dass Benutzer vor der Abfrage gültige Daten eingeben.
Neue Felder, die der alten Tabelle hinzugefügt werden, müssen NULL sein dürfen (um Datenaktualisierungen in der gesamten Tabelle und Blockierungen durch langfristige Sperren zu vermeiden) (dies dient hauptsächlich der Berücksichtigung der Transformation der vorherigen Tabelle)
Richtlinien zur Indexgestaltung
Indizes sollten für Spalten erstellt werden, die häufig in WHERE-Klauseln
verwendet werden Indizes sollten für Spalten erstellt werden, die häufig zum Verknüpfen von Tabellen verwendet werden
Indizes sollten für Spalten erstellt werden, die häufig in ORDER BY-Klauseln
verwendet werden Indizes sollten nicht für kleine Tabellen (Tabellen, die nur wenige Seiten verwenden) erstellt werden, da ein vollständiger Tabellenscanvorgang möglicherweise schneller ist als eine Abfrage mithilfe eines Index
-
Die Anzahl der Indizes in einer einzelnen Tabelle überschreitet nicht 6
Erstellen Sie keine einspaltigen Indizes für Felder mit geringer Selektivität
Nutzen Sie die einzigartigen Einschränkungen voll aus
Der Index enthält nicht mehr als 5 Felder (einschließlich Include-Spalten)
Erstellen Sie keine einspaltigen Indizes für Felder mit geringer Selektivität
SQL SERVER stellt Anforderungen an die Selektivität von Indexfeldern. Wenn die Selektivität zu niedrig ist, gibt SQL SERVER die Verwendung von
- Felder, die nicht für die Indexerstellung geeignet sind: Geschlecht, 0/1, WAHR/FALSCH
- Für die Erstellung von Indizes geeignete Felder: ORDERID, UID usw.
- Indizes beschleunigen Abfragen, wirken sich jedoch auf die Schreibleistung aus
- Der Index einer Tabelle sollte umfassend erstellt werden, indem alle mit der Tabelle verbundenen SQL-Anweisungen kombiniert werden, und versuchen Sie,
- zusammenzuführen Das Prinzip des kombinierten Index besteht darin, dass die Felder mit besserer Filterbarkeit höher platziert werden
- Zu viele Indizes verlängern nicht nur die Kompilierungszeit, sondern beeinträchtigen auch die Fähigkeit der Datenbank, den besten Ausführungsplan auszuwählen
- Es ist verboten, komplexe Operationen in der Datenbank durchzuführen
SELECT *
ist verboten Verwenden Sie keine Funktionen oder Berechnungen für indizierte Spalten
Cursor sind verboten
Auslöser verboten
Es ist verboten, den Index
anzugeben Der Variable-/Parameter-/zugehörige Feldtyp muss mit dem Feldtyp
übereinstimmen Parametrisierte Abfrage
Begrenzen Sie die Anzahl der JOINs
Begrenzen Sie die Länge von SQL-Anweisungen und die Anzahl der IN-Klauseln
Vermeiden Sie große Transaktionsvorgänge
Durch Deaktivieren der betroffenen Zeilenanzahlinformationen wird
zurückgegeben Sofern nicht erforderlich, muss die SELECT-Anweisung mit NOLOCK
hinzugefügt werden Verwenden Sie UNION ALL, um UNION zu ersetzen
Fragen Sie große Datenmengen mithilfe von Paging oder TOP ab
Einschränkungen auf rekursiver Abfrageebene
NOT EXISTS ersetzt NOT IN
Temporäre Tabellen und Tabellenvariablen
Verwenden Sie lokale Variablen, um einen mittleren Ausführungsplan auszuwählen
Vermeiden Sie die Verwendung des ODER-Operators
Mechanismus zur Behandlung von Transaktionsausnahmen hinzufügen
Die Ausgabespalten verwenden das zweiteilige Namensformat
Es ist verboten, komplexe Operationen in der Datenbank durchzuführen
XML-Analyse
String-Ähnlichkeitsvergleich
String-Suche (Charindex)
Komplexe Vorgänge werden programmseitig erledigt
Es ist verboten, SELECT *
zu verwenden Reduzieren Sie den Speicherverbrauch und die Netzwerkbandbreite
Geben Sie dem Abfrageoptimierer die Möglichkeit, die erforderlichen Spalten aus dem Index zu lesen
Wenn sich die Tabellenstruktur ändert, kann es leicht zu Abfragefehlern kommen
Es ist verboten, Funktionen oder Berechnungen für Indexspalten zu verwenden
Es ist verboten, Funktionen oder Berechnungen für Indexspalten zu verwenden
Wenn in der where-Klausel der Index Teil der Funktion ist, verwendet der Optimierer den Index nicht mehr und führt einen vollständigen Tabellenscan durch
Unter der Annahme, dass ein Index für Feld Col1 vorhanden ist, wird der Index in den folgenden Szenarios nicht verwendet:
ABS[Col1]=1
[Col1]+1>9
Lassen Sie uns ein weiteres Beispiel geben

Eine Abfrage wie die obige kann den PrintTime-Index für die O_OrderProcess-Tabelle nicht verwenden, daher verwenden wir die folgende SQL-Abfrage
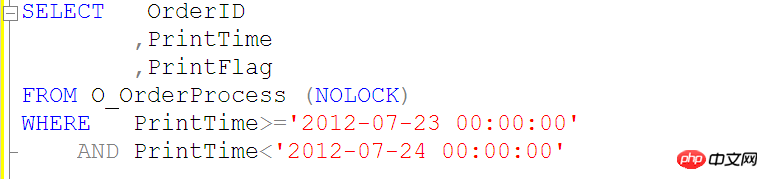
Es ist verboten, Funktionen oder Berechnungen für Indexspalten zu verwenden
Unter der Annahme, dass ein Index für Feld Col1 vorhanden ist, wird in den folgenden Szenarios der Index verwendet:
[Spalte1]=3,14
[Spalte1]>100
[Col1] ZWISCHEN 0 UND 99
[Col1] LIKE ‚abc%‘
[Col1] IN(2,3,5,7)
Indexproblem der LIKE-Abfrage
1.[Spalte1] wie „abc%“ – Indexsuche Dies verwendet eine Indexabfrage
2.[Spalte1] wie „%abc%“ – Index-Scan Und dies verwendet keine Indexabfrage
3.[Spalte1] wie „%abc“ – Index-Scan Hierbei wird auch keine Indexabfrage verwendet
Ich denke, aus den obigen drei Beispielen sollte jeder verstehen, dass es am besten ist, vor der LIKE-Bedingung keinen Fuzzy-Matching zu verwenden, da sonst die Indexabfrage nicht verwendet wird.
Die Verwendung von Cursorn ist verboten
Relationale Datenbanken eignen sich für Mengenoperationen, d. h. Mengenoperationen werden für die Ergebnismenge ausgeführt, die durch die WHERE-Klausel und die Auswahlspalte bestimmt wird. Der Cursor ist eine Möglichkeit, Nichtmengenoperationen bereitzustellen. Unter normalen Umständen entspricht die von einem Cursor implementierte Funktion häufig der Funktion, die von einer Schleife auf der Clientseite implementiert wird.
Der Cursor platziert die Ergebnismenge im Serverspeicher und verarbeitet die Datensätze einzeln in einer Schleife, was viele Datenbankressourcen verbraucht (insbesondere Speicher- und Sperrressourcen).
(Außerdem sind Cursor sehr kompliziert und schwierig zu verwenden, also verwenden Sie sie so wenig wie möglich)
Die Verwendung von Triggern ist verboten
Auslöser sind für die Anwendung undurchsichtig (die Anwendungsebene weiß weder, wann der Auslöser ausgelöst wird, noch weiß sie, wann er auftritt. Es fühlt sich unerklärlich an ...)
Es ist verboten, in der Abfrage
einen Index anzugeben With(index=XXX) (In Abfragen verwenden wir im Allgemeinen With(index=XXX), um den Index anzugeben)
Wenn sich die Daten ändern, ist die durch die Abfrageanweisung angegebene Indexleistung möglicherweise nicht optimal
Der Index sollte für die Anwendung transparent sein. Wenn der angegebene Index gelöscht wird, führt dies zu einem Abfragefehler, der der Fehlerbehebung nicht förderlich ist
Der neu erstellte Index kann nicht sofort von der Anwendung verwendet werden und muss veröffentlicht werden, um wirksam zu werden
Der Variable-/Parameter-/zugehörige Feldtyp muss mit dem Feldtyp konsistent sein (das ist etwas, worauf ich vorher nicht viel geachtet habe)
Vermeiden Sie den zusätzlichen CPU-Verbrauch der Typkonvertierung, der bei großen Tabellenscans besonders schwerwiegend ist
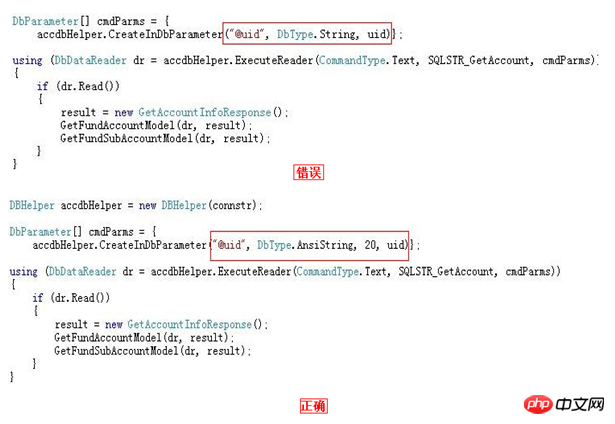
Nachdem ich mir die beiden Bilder oben angesehen habe, glaube ich nicht, dass ich es erklären muss, jeder sollte es bereits wissen.
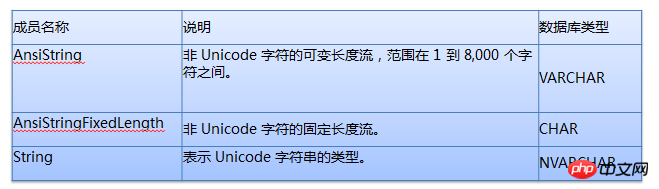
Wenn der Datenbankfeldtyp VARCHAR ist, ist es am besten, den Typ in der Anwendung als AnsiString anzugeben und seine Länge eindeutig anzugeben
Wenn der Datenbankfeldtyp CHAR ist, ist es am besten, den Typ in der Anwendung als AnsiStringFixedLength anzugeben und seine Länge eindeutig anzugeben
Wenn der Datenbankfeldtyp NVARCHAR ist, ist es am besten, den Typ in der Anwendung als String anzugeben und seine Länge eindeutig anzugeben
Parametrisierte Abfrage
Abfrage-SQL kann auf folgende Weise parametrisiert werden:
sp_executesql
Vorbereitete Abfragen
Gespeicherte Prozeduren
Lass es mich mit einem Bild erklären, haha.


Begrenzen Sie die Anzahl der JOINs
Die Anzahl der Tabellen-JOINs in einer einzelnen SQL-Anweisung darf 5
nicht überschreiten Zu viele JOINs führen dazu, dass der Abfrageanalysator in den falschen Ausführungsplan wechselt
Zu viele JOINs verschlingen viel Geld bei der Erstellung des Ausführungsplans
Begrenzen Sie die Anzahl der Bedingungen in der IN-Klausel
Das Einschließen einer sehr großen Anzahl von Werten (Tausende) in die IN-Klausel kann Ressourcen verbrauchen und den Fehler 8623 oder 8632 zurückgeben. Die Anzahl der Bedingungen in der IN-Klausel muss auf 100 begrenzt werden
Versuchen Sie, große Transaktionsvorgänge zu vermeiden
Starten Sie Transaktionen nur, wenn Daten aktualisiert werden müssen, wodurch die Haltezeit der Ressourcensperre verkürzt wird
Vorverarbeitungsmechanismus zur Erfassung von Transaktionsausnahmen hinzufügen
Die Verwendung verteilter Transaktionen in der Datenbank ist verboten
Verwenden Sie Bilder zur Erklärung
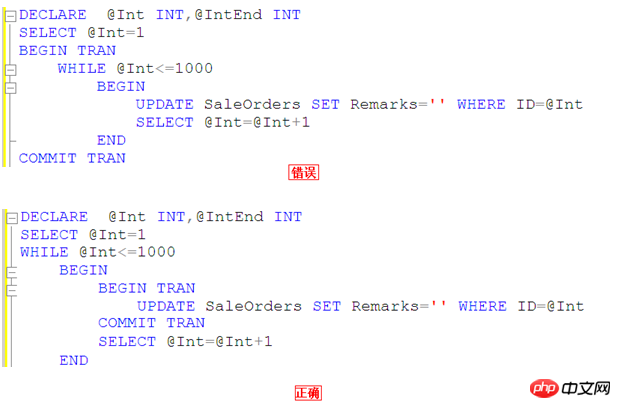
Mit anderen Worten, wir sollten Tran nicht festschreiben, nachdem alle 1.000 Datenzeilen aktualisiert wurden. Überlegen Sie, ob Sie beim Aktualisieren dieser 1.000 Datenzeilen Ressourcen monopolisieren, was dazu führt, dass andere Transaktionen nicht verarbeitet werden können.
Schließen Sie die Informationen zur Anzahl der betroffenen Zeilen und geben Sie
zurück Zeigen Sie Set Nocount On in der SQL-Anweisung an, brechen Sie die Rückgabe der betroffenen Zeilenanzahlinformationen ab und reduzieren Sie den Netzwerkverkehr
Sofern nicht erforderlich, muss die SELECT-Anweisung mit NOLOCK
hinzugefügt werden Sofern nicht erforderlich, versuchen Sie, alle ausgewählten Anweisungen mit NOLOCK
zu versehen Gibt an, dass Dirty Reads zulässig sind. Es werden keine gemeinsamen Sperren ausgegeben, um zu verhindern, dass andere Transaktionen die von der aktuellen Transaktion gelesenen Daten ändern, und von anderen Transaktionen festgelegte exklusive Sperren verhindern nicht, dass die aktuelle Transaktion die gesperrten Daten liest. Das Zulassen von Dirty Reads kann zu mehr gleichzeitigen Vorgängen führen, der Preis hierfür sind jedoch Datenänderungen, die später durch andere Transaktionen rückgängig gemacht werden. Dies kann dazu führen, dass bei Ihrer Transaktion ein Fehler auftritt, die Benutzerdaten angezeigt werden, die nie festgeschrieben wurden, oder dass der Benutzer den Datensatz zweimal sieht (oder den Datensatz überhaupt nicht sieht)
Verwenden Sie UNION ALL, um UNION zu ersetzen
Verwenden Sie UNION ALL, um UNION zu ersetzen
UNION wird die SQL-Ergebnismenge neu ordnen und den Verbrauch von CPU, Speicher usw. erhöhen.
Um große Datenmengen abzufragen, verwenden Sie Paging oder TOP
Begrenzen Sie die Anzahl der Datensatzrückgaben angemessen, um Engpässe bei E/A und Netzwerkbandbreite zu vermeiden
Einschränkungen auf rekursiver Abfrageebene
Verwenden Sie MAXRECURSION, um zu verhindern, dass unangemessener rekursiver CTE in eine Endlosschleife gerät
Temporäre Tabellen und Tabellenvariablen
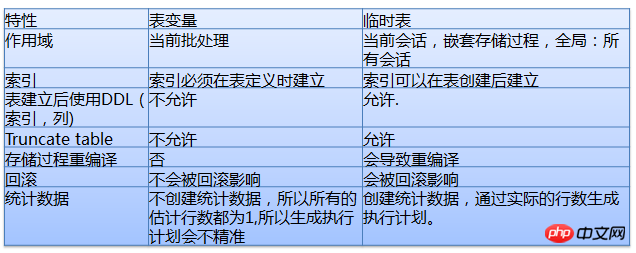
Verwenden Sie lokale Variablen, um einen durchschnittlichen Ausführungsplan auszuwählen
In einer gespeicherten Prozedur oder Abfrage führt der Zugriff auf eine Tabelle mit sehr ungleichmäßiger Datenverteilung häufig dazu, dass die gespeicherte Prozedur oder Abfrage einen suboptimalen oder sogar schlechten Ausführungsplan verwendet, was zu Problemen wie hoher CPU-Auslastung und einer großen Anzahl von E/A-Lesevorgängen führt Verhindern Sie falsche Ausführungspläne.
Bei Verwendung lokaler Variablen kennt SQL beim Kompilieren den Wert dieser lokalen Variablen nicht. Zu diesem Zeitpunkt „errät“ SQL einen Rückgabewert basierend auf der allgemeinen Datenverteilung in der Tabelle. Unabhängig davon, welche Variablenwerte der Benutzer beim Aufruf der gespeicherten Prozedur oder Anweisung ersetzt, ist der generierte Plan derselbe. Ein solcher Plan ist im Allgemeinen moderater und möglicherweise nicht der beste Plan, aber im Allgemeinen auch nicht der schlechteste Plan
Wenn die lokale Variable in der Abfrage den Ungleichheitsoperator verwendet, verwendet der Abfrageanalysator eine einfache 30-%-Berechnung, um
zu schätzen
Geschätzte Zeilen =(Gesamtzeilen * 30)/100
Wenn die lokale Variable in der Abfrage den Gleichheitsoperator verwendet, verwendet der Abfrageanalysator: Präzision * Gesamtzahl der zu schätzenden Tabellendatensätze
Geschätzte Zeilen = Dichte * Gesamtzeilen
Vermeiden Sie die Verwendung des ODER-Operators
Für den OR-Operator wird normalerweise ein vollständiger Tabellenscan verwendet. Erwägen Sie die Aufteilung in mehrere Abfragen und die Implementierung von UNION/UNION ALL. Hier müssen Sie bestätigen, dass die Abfrage zum Index gehen und eine kleinere Ergebnismenge zurückgeben kann > Mechanismus zur Behandlung von Transaktionsausnahmen hinzufügen
Die Anwendung sollte Unfälle gut bewältigen und rechtzeitig ein Rollback durchführen.
Verbindungseigenschaften festlegen „set xact_abort on“
Die Ausgabespalte verwendet das zweiteilige Namensformat
Zweistufiges Benennungsformat: Tabellenname.Feldname
In TSQL mit einer JOIN-Beziehung muss das Feld angeben, zu welcher Tabelle das Feld gehört. Andernfalls kann es nach einer zukünftigen Änderung der Tabellenstruktur zu Programmkompatibilitätsfehlern mit mehrdeutigen Spaltennamen kommen
Architekturdesign
-
Lese- und Schreibtrennung
- Trennung von Lesen und Schreiben
-
Die Trennung von Lesen und Schreiben wird von Beginn des Entwurfs an berücksichtigt. Auch wenn dieselbe Bibliothek gelesen und geschrieben wird, fördert sie eine schnelle Erweiterung
Bei der Trennung von Lesen und Schreiben sollte das automatische Umschalten auf die Schreibseite berücksichtigt werden, wenn das Lesen nicht möglich ist- Schema-Entkopplung
Datenbankübergreifender JOIN ist verboten
Datenlebenszyklus
Je nach Häufigkeit der Datennutzung werden große Tabellen in regulären Unterdatenbanken archiviert
Physische Trennung Hauptbibliothek/Archivbibliothek
Protokolltyptabellen sollten partitioniert oder Untertabellen sein
Bei großen Tabellen ist eine Partitionierung erforderlich, bei der die Tabelle und der Index in mehrere Partitionen unterteilt werden. Dies kann alte und neue Partitionen schnell ersetzen, die Datenbereinigung beschleunigen und den E/A-Ressourcenverbrauch erheblich reduzieren Häufig geschriebene Tabellen erfordern Partitionierung oder Untertabellen
Selbstwachstum und Verriegelung
Der Latch wird intern vom SQL Server angewendet und gesteuert. Er wird verwendet, um die Konsistenz der Datenstruktur im Speicher sicherzustellen
Das obige ist der detaillierte Inhalt vonSammlung häufig verwendeter SQL Server-Spezifikationen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Welche Software ist Microsoft SQL Server?
Feb 28, 2023 pm 03:00 PM
Welche Software ist Microsoft SQL Server?
Feb 28, 2023 pm 03:00 PM
Microsoft SQL Server ist ein relationales Datenbankverwaltungssystem, das von Microsoft eingeführt wurde. Es handelt sich um eine umfassende Datenbankplattform, die integrierte Business-Intelligence-Tools (BI) verwendet, um eine Datenverwaltung auf Unternehmensebene zu ermöglichen Grad der Integration mit verwandter Software. Die SQL Server-Datenbank-Engine bietet sicherere und zuverlässigere Speicherfunktionen für relationale Daten und strukturierte Daten und ermöglicht es Benutzern, hochverfügbare und leistungsstarke Datenanwendungen für Unternehmen zu erstellen und zu verwalten.
 SQL Server oder MySQL? Neue Forschungsergebnisse zeigen die besten Datenbankoptionen.
Sep 08, 2023 pm 04:34 PM
SQL Server oder MySQL? Neue Forschungsergebnisse zeigen die besten Datenbankoptionen.
Sep 08, 2023 pm 04:34 PM
SQLServer oder MySQL? Die neueste Forschung zeigt die beste Datenbankauswahl. Mit der rasanten Entwicklung des Internets und Big Data ist die Datenbankauswahl zu einem wichtigen Thema für Unternehmen und Entwickler geworden. Unter vielen Datenbanken sind SQL Server und MySQL als die beiden am weitesten verbreiteten und am weitesten verbreiteten relationalen Datenbanken äußerst umstritten. Welches sollten Sie also zwischen SQLServer und MySQL wählen? Die neuesten Forschungsergebnisse bringen für uns Licht in dieses Problem. Lassen Sie zunächst
 Entwicklung von PHP- und SQL Server-Datenbanken
Jun 20, 2023 pm 10:38 PM
Entwicklung von PHP- und SQL Server-Datenbanken
Jun 20, 2023 pm 10:38 PM
Mit der Popularität des Internets ist die Entwicklung von Websites und Anwendungen zum Hauptgeschäft vieler Unternehmen und Einzelpersonen geworden. PHP und SQLServer-Datenbank sind zwei sehr wichtige Tools. PHP ist eine serverseitige Skriptsprache, mit der dynamische Websites entwickelt werden können. SQL Server ist ein von Microsoft entwickeltes relationales Datenbankverwaltungssystem mit vielfältigen Anwendungsszenarien. In diesem Artikel besprechen wir die Entwicklung von PHP und SQL Server sowie deren Vor- und Nachteile sowie Anwendungsmethoden. Lassen Sie uns zunächst einmal
 So stellen Sie mithilfe von PDO eine Verbindung zu einer Microsoft SQL Server-Datenbank her
Jul 29, 2023 pm 01:49 PM
So stellen Sie mithilfe von PDO eine Verbindung zu einer Microsoft SQL Server-Datenbank her
Jul 29, 2023 pm 01:49 PM
Einführung in die Verwendung von PDO zum Herstellen einer Verbindung zu einer Microsoft SQL Server-Datenbank: PDO (PHPDataObjects) ist eine einheitliche Schnittstelle für den Zugriff auf von PHP bereitgestellte Datenbanken. Es bietet viele Vorteile, wie z. B. die Implementierung einer Abstraktionsschicht der Datenbank und die Erleichterung des Wechsels zwischen verschiedenen Datenbanktypen, ohne große Codemengen ändern zu müssen. In diesem Artikel wird erläutert, wie Sie mit PDO eine Verbindung zu einer Microsoft SQL Server-Datenbank herstellen, und es werden einige zugehörige Codebeispiele bereitgestellt. Schritt
 Eine kurze Analyse von fünf Methoden zur Verbindung von SQL Server mit PHP
Mar 21, 2023 pm 04:32 PM
Eine kurze Analyse von fünf Methoden zur Verbindung von SQL Server mit PHP
Mar 21, 2023 pm 04:32 PM
In der Webentwicklung ist die Kombination von PHP und MySQL sehr verbreitet. In einigen Fällen müssen wir jedoch eine Verbindung zu anderen Datenbanktypen herstellen, beispielsweise zu SQL Server. In diesem Artikel behandeln wir fünf verschiedene Möglichkeiten, mit PHP eine Verbindung zu SQL Server herzustellen.
 SQL Server und MySQL stehen im Wettbewerb. Wie wählt man die beste Datenbanklösung aus?
Sep 10, 2023 am 08:07 AM
SQL Server und MySQL stehen im Wettbewerb. Wie wählt man die beste Datenbanklösung aus?
Sep 10, 2023 am 08:07 AM
Mit der kontinuierlichen Entwicklung des Internets hat die Datenbankauswahl immer mehr an Bedeutung gewonnen. Unter den vielen Datenbanken sind SQLServer und MySQL zwei hochkarätige Optionen. SQLServer ist ein von Microsoft entwickeltes relationales Datenbankverwaltungssystem, während MySQL ein relationales Open-Source-Datenbankverwaltungssystem ist. Wie wählt man also die beste Datenbanklösung zwischen SQLServer und MySQL aus? Zunächst können wir diese beiden Datenbanken hinsichtlich der Leistung vergleichen. SQLServer verarbeitet
 SQL Server vs. MySQL: Welche Datenbank eignet sich besser für eine Hochverfügbarkeitsarchitektur?
Sep 10, 2023 pm 01:39 PM
SQL Server vs. MySQL: Welche Datenbank eignet sich besser für eine Hochverfügbarkeitsarchitektur?
Sep 10, 2023 pm 01:39 PM
SQL Server vs. MySQL: Welche Datenbank eignet sich besser für eine Hochverfügbarkeitsarchitektur? In der heutigen datengesteuerten Welt ist hohe Verfügbarkeit eine der notwendigen Voraussetzungen für den Aufbau zuverlässiger und stabiler Systeme. Als Kernkomponente der Datenspeicherung und -verwaltung ist die hohe Verfügbarkeit der Datenbank für den Geschäftsbetrieb des Unternehmens von entscheidender Bedeutung. Unter den vielen Datenbanken sind SQLServer und MySQL die gängige Wahl. Welche Datenbank ist im Hinblick auf eine Hochverfügbarkeitsarchitektur besser geeignet? In diesem Artikel werden die beiden verglichen und einige Vorschläge gemacht.
 SQL Server vs. MySQL: Was ist besser für die Entwicklung mobiler Apps?
Sep 09, 2023 pm 01:42 PM
SQL Server vs. MySQL: Was ist besser für die Entwicklung mobiler Apps?
Sep 09, 2023 pm 01:42 PM
SQLServer vs. MySQL: Was ist besser für die Entwicklung mobiler Apps? Mit der rasanten Entwicklung des Marktes für mobile Anwendungen wird es für Entwickler immer wichtiger, ein Datenbankverwaltungssystem auszuwählen, das für die Entwicklung mobiler Anwendungen geeignet ist. Unter den vielen Möglichkeiten sind SQLServer und MySQL zwei von Entwicklern bevorzugte Datenbanksysteme. Dieser Artikel konzentriert sich auf den Vergleich dieser beiden Datenbanksysteme, um festzustellen, welches für die Entwicklung mobiler Anwendungen besser geeignet ist, und zeigt ihre Unterschiede anhand von Codebeispielen auf. SQLServer ist Microsoft
