
 Backend-Entwicklung
XML/RSS-Tutorial
Teilen Sie eine Methode zum Parsen einer XML-Zeichenfolge über dom4j
Backend-Entwicklung
XML/RSS-Tutorial
Teilen Sie eine Methode zum Parsen einer XML-Zeichenfolge über dom4j
Teilen Sie eine Methode zum Parsen einer XML-Zeichenfolge über dom4j

DOM4J
Im Vergleich zur Verwendung von DOM-, SAX- und JAXP-Mechanismen zum Parsen von XML bietet DOM4J eine bessere Leistung, hervorragende Leistung, leistungsstarke Funktionen und ist extrem Einfach zu verwenden, solange Sie die Grundkonzepte von DOM verstehen, können Sie XML über das API-Dokument von dom4j analysieren. dom4j ist eine Reihe von Open-Source-APIs. In tatsächlichen Projekten wird dom4j häufig als Tool zum Parsen von XML ausgewählt.
Werfen wir zunächst einen Blick auf die Vererbung-Beziehung, die durch den DOM-Baum entsprechend XML in dom4j hergestellt wird
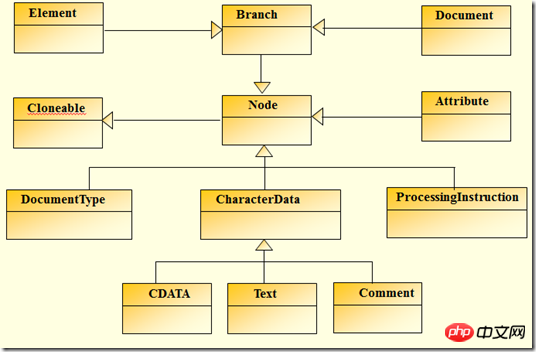
Für die XML-Standarddefinition, entsprechend dem in Abbildung 2-1 aufgeführten Inhalt, stellt dom4j die folgende Implementierung bereit:
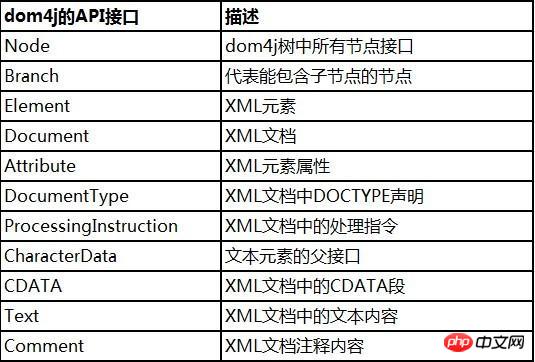
Gleichzeitig implementiert die NodeType-Enumeration von dom4j den in der XML-Spezifikation definierten Knotentyp. Auf diese Weise kann der Knotentyp beim Durchlaufen des XML-Dokuments über die -Konstante bestimmt werden.
Gemeinsame API
Klasse org.dom4j.io.SAXReader
read bietet mehrere Möglichkeiten zum Lesen von XML-Dateien und gibt ein Domcument-Objekt zurück
Schnittstelle org.dom4j.Dokument
iterator Verwenden Sie diese Methode, um den Knoten
- abzurufen
getRootElement Holen Sie sich den Stammknoten
interface org.dom4j.Node
getName Ruft den Knotennamen ab, zum Beispiel ist der Name des Stammknotens Buchhandlung.
getNodeType Ruft den konstanten Wert des Knotentyps ab, zum Beispiel den Buchhandlungstyp ist 1 - Element
getNodeTypeName Ruft den Namen des Knotentyps ab. Der erhaltene Buchladentypname lautet beispielsweise Element
interface org.dom4j.Element
attributes Gibt die AttributeListe des Elements
attributeValue Ruft den Attributwert basierend auf dem übergebenen Attributnamen ab
elementIterator Gibt einen Iterator zurück, der untergeordnete Elemente enthält
elements Gibt eine Liste mit untergeordneten Elementen
interface org.dom4j.Attribute
- getName Den Attributnamen abrufen
- getValue Den Attributwert abrufen
- getText Den Textknotenwert abrufen
- getText Den CDATA-Abschnittswert abrufen
getText 获取注释 实例一: 【相关推荐】 1. XML免费视频教程 2. XML技术手册 1 //先加入dom4j.jar包 2 import java.util.HashMap; 3 import java.util.Iterator; 4 import java.util.Map; 5 6 import org.dom4j.Document; 7 import org.dom4j.DocumentException; 8 import org.dom4j.DocumentHelper; 9 import org.dom4j.Element; 10 11 /** 12 * @Title: TestDom4j.java 13 * @Package
14 * @Description: 解析xml字符串 15 * @author 无处不在 16 * @date 2012-11-20 下午05:14:05 17 * @version V1.0
18 */ 19 public class TestDom4j { 20 21 public void readStringXml(String xml) { 22 Document doc = null; 23 try { 24 25 // 读取并解析XML文档 26 // SAXReader就是一个管道,用一个流的方式,把xml文件读出来 27 // 28 // SAXReader reader = new SAXReader(); //User.hbm.xml表示你要解析的xml文档 29 // Document document = reader.read(new File("User.hbm.xml")); 30 // 下面的是通过解析xml字符串的 31 doc = DocumentHelper.parseText(xml); // 将字符串转为XML 32 33 Element rootElt = doc.getRootElement(); // 获取根节点 34 System.out.println("根节点:" + rootElt.getName()); // 拿到根节点的名称 35 36 Iterator iter = rootElt.elementIterator("head"); // 获取根节点下的子节点head 37 38 // 遍历head节点 39 while (iter.hasNext()) { 40 41 Element recordEle = (Element) iter.next(); 42 String title = recordEle.elementTextTrim("title"); // 拿到head节点下的子节点title值 43 System.out.println("title:" + title); 44 45 Iterator iters = recordEle.elementIterator("script"); // 获取子节点head下的子节点script 46 47 // 遍历Header节点下的Response节点 48 while (iters.hasNext()) { 49 50 Element itemEle = (Element) iters.next(); 51 52 String username = itemEle.elementTextTrim("username"); // 拿到head下的子节点script下的字节点username的值 53 String password = itemEle.elementTextTrim("password"); 54 55 System.out.println("username:" + username); 56 System.out.println("password:" + password); 57 } 58 } 59 Iterator iterss = rootElt.elementIterator("body"); ///获取根节点下的子节点body 60 // 遍历body节点 61 while (iterss.hasNext()) { 62 63 Element recordEless = (Element) iterss.next(); 64 String result = recordEless.elementTextTrim("result"); // 拿到body节点下的子节点result值 65 System.out.println("result:" + result); 66 67 Iterator itersElIterator = recordEless.elementIterator("form"); // 获取子节点body下的子节点form 68 // 遍历Header节点下的Response节点 69 while (itersElIterator.hasNext()) { 70 71 Element itemEle = (Element) itersElIterator.next(); 72 73 String banlce = itemEle.elementTextTrim("banlce"); // 拿到body下的子节点form下的字节点banlce的值 74 String subID = itemEle.elementTextTrim("subID"); 75 76 System.out.println("banlce:" + banlce); 77 System.out.println("subID:" + subID); 78 } 79 } 80 } catch (DocumentException e) { 81 e.printStackTrace(); 82 83 } catch (Exception e) { 84 e.printStackTrace(); 85 86 } 87 } 88 89 /** 90 * @description 将xml字符串转换成map 91 * @param xml 92 * @return Map 93 */ 94 public static Map readStringXmlOut(String xml) { 95 Map map = new HashMap(); 96 Document doc = null; 97 try { 98 // 将字符串转为XML 99 doc = DocumentHelper.parseText(xml);
100 // 获取根节点101 Element rootElt = doc.getRootElement();
102 // 拿到根节点的名称103 System.out.println("根节点:" + rootElt.getName());
104 105 // 获取根节点下的子节点head106 Iterator iter = rootElt.elementIterator("head");
107 // 遍历head节点108 while (iter.hasNext()) {109 110 Element recordEle = (Element) iter.next();111 // 拿到head节点下的子节点title值112 String title = recordEle.elementTextTrim("title");
113 System.out.println("title:" + title);114 map.put("title", title);115 // 获取子节点head下的子节点script116 Iterator iters = recordEle.elementIterator("script");
117 // 遍历Header节点下的Response节点118 while (iters.hasNext()) {119 Element itemEle = (Element) iters.next();120 // 拿到head下的子节点script下的字节点username的值121 String username = itemEle.elementTextTrim("username");
122 String password = itemEle.elementTextTrim("password");123 124 System.out.println("username:" + username);125 System.out.println("password:" + password);126 map.put("username", username);127 map.put("password", password);128 }129 }130 131 //获取根节点下的子节点body132 Iterator iterss = rootElt.elementIterator("body");
133 // 遍历body节点134 while (iterss.hasNext()) {135 Element recordEless = (Element) iterss.next();136 // 拿到body节点下的子节点result值137 String result = recordEless.elementTextTrim("result");
138 System.out.println("result:" + result);139 // 获取子节点body下的子节点form140 Iterator itersElIterator = recordEless.elementIterator("form");
141 // 遍历Header节点下的Response节点142 while (itersElIterator.hasNext()) {143 Element itemEle = (Element) itersElIterator.next();144 // 拿到body下的子节点form下的字节点banlce的值145 String banlce = itemEle.elementTextTrim("banlce");
146 String subID = itemEle.elementTextTrim("subID");147 148 System.out.println("banlce:" + banlce);149 System.out.println("subID:" + subID);150 map.put("result", result);151 map.put("banlce", banlce);152 map.put("subID", subID);153 }154 }155 } catch (DocumentException e) {156 e.printStackTrace();157 } catch (Exception e) {158 e.printStackTrace();159 }160 return map;161 }162 163 public static void main(String[] args) {164 165 // 下面是需要解析的xml字符串例子166 String xmlString = "<html>" + "<head>" + "<title>dom4j解析一个例子</title>"167 + "<script>" + "<username>yangrong</username>"168 + "<password>123456</password>" + "</script>" + "</head>"169 + "<body>" + "<result>0</result>" + "<form>"170 + "<banlce>1000</banlce>" + "<subID>36242519880716</subID>"171 + "</form>" + "</body>" + "</html>";172 173 /*174 * Test2 test = new Test2(); test.readStringXml(xmlString);175 */176 Map map = readStringXmlOut(xmlString);177 Iterator iters = map.keySet().iterator();178 while (iters.hasNext()) {179 String key = iters.next().toString(); // 拿到键180 String val = map.get(key).toString(); // 拿到值181 System.out.println(key + "=" + val);182 }183 }184 185 }实例二: 1 /** 2 * 解析包含有DB连接信息的XML文件 3 * 格式必须符合如下规范: 4 * 1. 最多三级,每级的node名称自定义; 5 * 2. 二级节点支持节点属性,属性将被视作子节点; 6 * 3. CDATA必须包含在节点中,不能单独出现。 7 * 8 * 示例1——三级显示: 9 * <db-connections>10 * <connection>11 * <name>DBTest</name>12 * <jndi></jndi>13 * <url>14 * <![CDATA[jdbc:mysql://localhost:3306/db_test?useUnicode=true&characterEncoding=UTF8]]>15 * </url>16 * <driver>org.gjt.mm.mysql.Driver</driver>17 * <user>test</user>18 * <password>test2012</password>19 * <max-active>10</max-active>20 * <max-idle>10</max-idle>21 * <min-idle>2</min-idle>22 * <max-wait>10</max-wait>23 * <validation-query>SELECT 1+1</validation-query>24 * </connection>25 * </db-connections>26 *27 * 示例2——节点属性:28 * <bookstore>29 * <book category="cooking">30 * <title lang="en">Everyday Italian</title>31 * <author>Giada De Laurentiis</author>32 * <year>2005</year>33 * <price>30.00</price>34 * </book>35 *36 * <book category="children" title="Harry Potter" author="J K. Rowling" year="2005" price="$29.9"/>37 * </bookstore>38 *39 * @param configFile40 * @return41 * @throws Exception42 */43 public static List<Map<String, String>> parseDBXML(String configFile) throws Exception {44 List<Map<String, String>> dbConnections = new ArrayList<Map<String, String>>();45 InputStream is = Parser.class.getResourceAsStream(configFile);46 SAXReader saxReader = new SAXReader();47 Document document = saxReader.read(is);48 Element connections = document.getRootElement();49 50 Iterator<Element> rootIter = connections.elementIterator();51 while (rootIter.hasNext()) {52 Element connection = rootIter.next();53 Iterator<Element> childIter = connection.elementIterator();54 Map<String, String> connectionInfo = new HashMap<String, String>();55 List<Attribute> attributes = connection.attributes();56 for (int i = 0; i < attributes.size(); ++i) { // 添加节点属性57 connectionInfo.put(attributes.get(i).getName(), attributes.get(i).getValue());58 }59 while (childIter.hasNext()) { // 添加子节点60 Element attr = childIter.next();61 connectionInfo.put(attr.getName().trim(), attr.getText().trim());62 }63 dbConnections.add(connectionInfo);64 }65 66 return dbConnections;67 }
Das obige ist der detaillierte Inhalt vonTeilen Sie eine Methode zum Parsen einer XML-Zeichenfolge über dom4j. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 Detaillierte Erläuterung der Methode zum Konvertieren des Typs „int' in „string' in PHP
Mar 26, 2024 am 11:45 AM
Detaillierte Erläuterung der Methode zum Konvertieren des Typs „int' in „string' in PHP
Mar 26, 2024 am 11:45 AM
Ausführliche Erläuterung der Methode zum Konvertieren des Typs int in einen String in PHP. Bei der PHP-Entwicklung stoßen wir häufig auf die Notwendigkeit, den Typ int in einen String-Typ zu konvertieren. Diese Konvertierung kann auf verschiedene Weise erreicht werden. In diesem Artikel werden verschiedene gängige Methoden im Detail vorgestellt, mit spezifischen Codebeispielen, um den Lesern das Verständnis zu erleichtern. 1. Verwenden Sie die integrierte Funktion strval() von PHP. PHP bietet eine integrierte Funktion strval(), die Variablen verschiedener Typen in String-Typen konvertieren kann. Wenn wir den Typ int in den Typ string konvertieren müssen,
 So ermitteln Sie, ob eine Golang-Zeichenfolge mit einem bestimmten Zeichen endet
Mar 12, 2024 pm 04:48 PM
So ermitteln Sie, ob eine Golang-Zeichenfolge mit einem bestimmten Zeichen endet
Mar 12, 2024 pm 04:48 PM
Titel: So ermitteln Sie, ob eine Zeichenfolge in Golang mit einem bestimmten Zeichen endet. In der Go-Sprache müssen wir manchmal feststellen, ob eine Zeichenfolge mit einem bestimmten Zeichen endet. In diesem Artikel wird erläutert, wie Sie diese Funktion mithilfe der Go-Sprache implementieren, und es werden Codebeispiele als Referenz bereitgestellt. Schauen wir uns zunächst an, wie Sie in Golang feststellen können, ob eine Zeichenfolge mit einem bestimmten Zeichen endet. Die Zeichen in einer Zeichenfolge in Golang können durch Indizierung ermittelt werden, und die Länge der Zeichenfolge kann ermittelt werden
 So wiederholen Sie eine Zeichenfolge in Python_Tutorial zum Wiederholen von Zeichenfolgen in Python
Apr 02, 2024 pm 03:58 PM
So wiederholen Sie eine Zeichenfolge in Python_Tutorial zum Wiederholen von Zeichenfolgen in Python
Apr 02, 2024 pm 03:58 PM
1. Öffnen Sie zuerst Pycharm und rufen Sie die Pycharm-Homepage auf. 2. Erstellen Sie dann ein neues Python-Skript, klicken Sie mit der rechten Maustaste – klicken Sie auf „Neu“ – klicken Sie auf „Pythondatei“. 3. Geben Sie eine Zeichenfolge ein, Code: s="-". 4. Dann müssen Sie die Symbole in der Zeichenfolge 20 Mal wiederholen, Code: s1=s*20 5. Geben Sie den Druckausgabecode ein, Code: print(s1). 6. Führen Sie abschließend das Skript aus und Sie sehen unten unseren Rückgabewert: - 20 Mal wiederholt.
 Wie kann man in Golang überprüfen, ob eine Zeichenfolge mit einem bestimmten Zeichen beginnt?
Mar 12, 2024 pm 09:42 PM
Wie kann man in Golang überprüfen, ob eine Zeichenfolge mit einem bestimmten Zeichen beginnt?
Mar 12, 2024 pm 09:42 PM
Wie kann man in Golang überprüfen, ob eine Zeichenfolge mit einem bestimmten Zeichen beginnt? Beim Programmieren in Golang kommt es häufig vor, dass Sie prüfen müssen, ob eine Zeichenfolge mit einem bestimmten Zeichen beginnt. Um diese Anforderung zu erfüllen, können wir die vom Strings-Paket in Golang bereitgestellten Funktionen verwenden, um dies zu erreichen. Als Nächstes stellen wir anhand spezifischer Codebeispiele ausführlich vor, wie Sie mit Golang überprüfen können, ob eine Zeichenfolge mit einem bestimmten Zeichen beginnt. In Golang können wir HasPrefix aus dem Strings-Paket verwenden
 So fangen Sie eine Zeichenfolge in der Go-Sprache ab
Mar 13, 2024 am 08:33 AM
So fangen Sie eine Zeichenfolge in der Go-Sprache ab
Mar 13, 2024 am 08:33 AM
Die Go-Sprache ist eine leistungsstarke und flexible Programmiersprache, die umfangreiche Funktionen zur Zeichenfolgenverarbeitung bietet, einschließlich des Abfangens von Zeichenfolgen. In der Go-Sprache können wir Slices verwenden, um Zeichenfolgen abzufangen. Als Nächstes stellen wir anhand spezifischer Codebeispiele ausführlich vor, wie Zeichenfolgen in der Go-Sprache abgefangen werden. 1. Verwenden Sie Slicing, um eine Zeichenfolge abzufangen. In der Go-Sprache können Sie Slicing-Ausdrücke verwenden, um einen Teil einer Zeichenfolge abzufangen. Die Syntax des Slice-Ausdrucks lautet wie folgt: Slice:=str[Start:End]wo, s
 So lösen Sie das Problem verstümmelter chinesischer Zeichen bei der Konvertierung von Hexadezimalzahlen in Zeichenfolgen in PHP
Mar 04, 2024 am 09:36 AM
So lösen Sie das Problem verstümmelter chinesischer Zeichen bei der Konvertierung von Hexadezimalzahlen in Zeichenfolgen in PHP
Mar 04, 2024 am 09:36 AM
Methoden zur Lösung des Problems verstümmelter chinesischer Zeichen beim Konvertieren von Hexadezimalzeichenfolgen in PHP. Bei der PHP-Programmierung stoßen wir manchmal auf Situationen, in denen wir Hexadezimalzeichenfolgen in normale chinesische Zeichen konvertieren müssen. Bei dieser Konvertierung treten jedoch manchmal Probleme mit verstümmelten chinesischen Zeichen auf. In diesem Artikel finden Sie eine Methode zur Lösung des Problems verstümmelter chinesischer Zeichen bei der Konvertierung von Hexadezimalzahlen in Zeichenfolgen in PHP sowie spezifische Codebeispiele. Verwenden Sie die Funktion hex2bin() für die Hexadezimalkonvertierung. Die in PHP integrierte Funktion hex2bin() kann 1 konvertieren
 PHP-String-Manipulation: eine praktische Möglichkeit, Leerzeichen effektiv zu entfernen
Mar 24, 2024 am 11:45 AM
PHP-String-Manipulation: eine praktische Möglichkeit, Leerzeichen effektiv zu entfernen
Mar 24, 2024 am 11:45 AM
PHP-String-Operation: Eine praktische Methode zum effektiven Entfernen von Leerzeichen Bei der PHP-Entwicklung kommt es häufig vor, dass Sie Leerzeichen aus einem String entfernen müssen. Das Entfernen von Leerzeichen kann die Zeichenfolge sauberer machen und die nachfolgende Datenverarbeitung und -anzeige erleichtern. In diesem Artikel werden mehrere effektive und praktische Methoden zum Entfernen von Leerzeichen vorgestellt und spezifische Codebeispiele angehängt. Methode 1: Verwenden Sie die in PHP integrierte Funktion trim(). Die in PHP integrierte Funktion trim() kann Leerzeichen an beiden Enden der Zeichenfolge entfernen (einschließlich Leerzeichen, Tabulatoren, Zeilenumbrüche usw.), was sehr praktisch und einfach ist benutzen.
 Wie verwende ich PHP-Funktionen zur Verarbeitung von XML-Daten?
May 05, 2024 am 09:15 AM
Wie verwende ich PHP-Funktionen zur Verarbeitung von XML-Daten?
May 05, 2024 am 09:15 AM
Verwenden Sie PHPXML-Funktionen, um XML-Daten zu verarbeiten: XML-Daten analysieren: simplexml_load_file() und simplexml_load_string() laden XML-Dateien oder Strings. Auf XML-Daten zugreifen: Verwenden Sie die Eigenschaften und Methoden des SimpleXML-Objekts, um Elementnamen, Attributwerte und Unterelemente abzurufen. XML-Daten ändern: Fügen Sie neue Elemente und Attribute mit den Methoden addChild() und addAttribute() hinzu. Serialisierte XML-Daten: Die Methode asXML() konvertiert ein SimpleXML-Objekt in einen XML-String. Praxisbeispiel: Produkt-Feed-XML analysieren, Produktinformationen extrahieren, umwandeln und in einer Datenbank speichern.
