

In diesem Artikel wird hauptsächlich der Python-Crawler vorgestellt: die Methode zum Crawlen von Baidu-Bildern anhand von Schlüsselwörtern. Es hat einen sehr guten Referenzwert, werfen wir einen Blick mit dem Editor unten
Verwendete Tools: Python2.7, klicken Sie hier zum Herunterladen
ScrapyFramework
erhabener Text3
Eins. Erstellen Sie Python (Windows-Version)
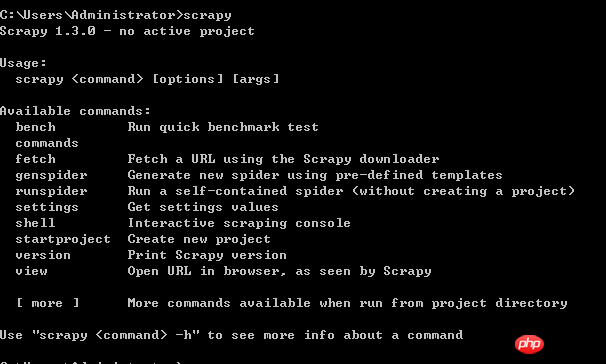
1.Installieren Sie python2.7 --- Geben Sie dann Python in cmd ein, die Schnittstelle ist wie folgt und die Installation ist erfolgreich

2. Scrapy-Framework integrieren----Geben Sie die Befehlszeile ein: pip install Scrapy

Die Schnittstelle für eine erfolgreiche Installation lautet wie folgt:
Es gibt viele Fehlersituationen, hier ist ein Beispiel :
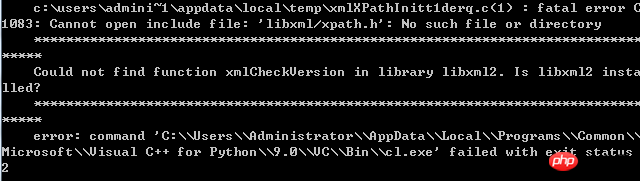
Lösung:
Der Rest der Fehler kann auf Baidu gesucht werden .
Zwei. Beginnen SieProgrammierung.
1. Crawlen Sie statische Websites ohne Anti-Crawler-Maßnahmen. Zum Beispiel Baidu Tieba und Douban Reading.
Zum Beispiel – ein Beitrag in „Desktop Bar“ tieba.baidu.com/p/2460150866?red_tag=3569129009
Der Python-Code lautet wie folgt:
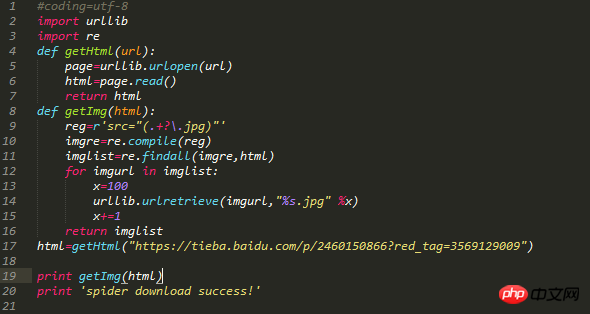
CodeKommentare: Zwei Module urllib, re werden eingeführt. Definieren Sie zwei -Funktionen . Die erste Funktion besteht darin, die gesamten Daten der Zielwebseite abzurufen, und die zweite Funktion besteht darin, das Zielbild auf der Zielwebseite abzurufen, die Webseite zu durchqueren und die erfassten Bilder zu sortieren ab 0.
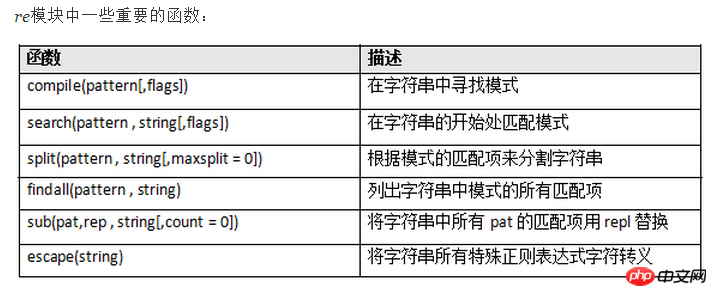
Hinweis: Wissenspunkte zum Modul:
Crawling-Bild-Renderings:
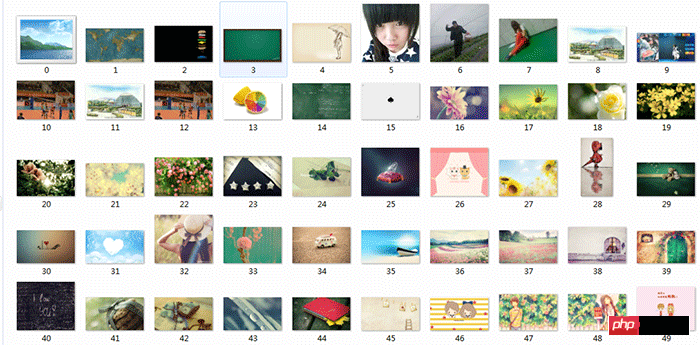
Bild Standardmäßig , der Speicherpfad befindet sich im selben Verzeichnis wie die erstellte .py-Datei.
2. Crawlen Sie Baidu-Bilder mit Anti-Crawler-Maßnahmen. Wie Baidu-Bilder usw.
Zum Beispiel die Stichwortsuche „Emoticon-Paket“ https://image.baidu.com/search/index?tn=baiduimage&ct=201326592&lm=-1&cl=2&ie=gbk&word=% B1% ED%C7%E9%B0%FC&fr=ala&ori_query=%E8%A1%A8%E6%83%85%E5%8C%85&ala=0&alatpl=sp&pos=0&hs=2&xthttps=111111
Das Bild scrollt. Zum Laden crawlen Sie zuerst die oberen 30 Bilder.
Der Code lautet wie folgt:
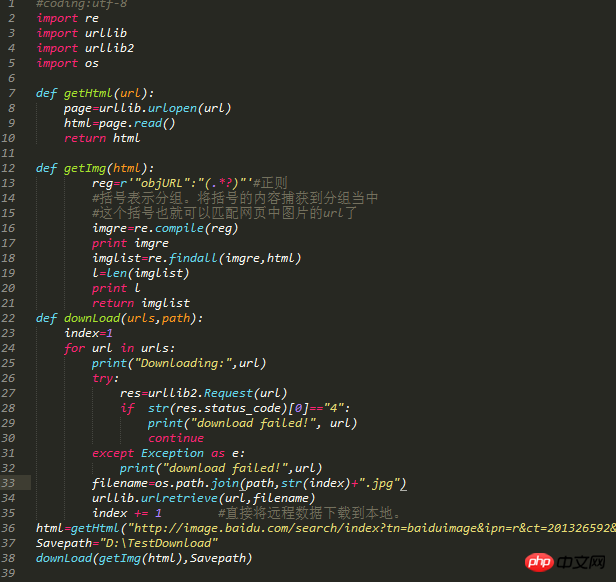
Codekommentare: Importieren Sie 4 Module, und das OS-Modul wird verwendet, um die Speicherung anzugeben Weg. Die ersten beiden Funktionen sind die gleichen wie oben. Die dritte Funktion verwendet die if-Anweisung und die tryException-Ausnahme.
Der Crawling-Prozess ist wie folgt:
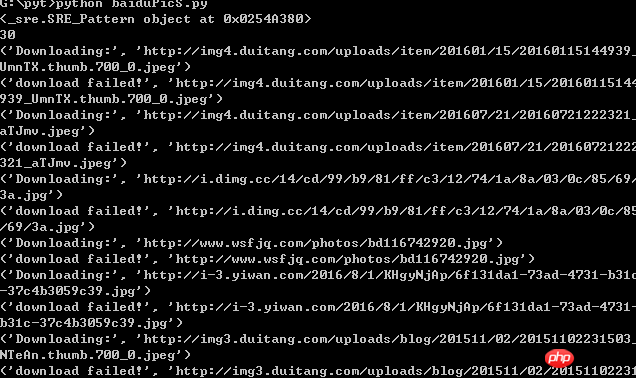
Crawling-Ergebnisse:

Hinweis: Schreiben Sie Python Code Achten Sie auf die Ausrichtung und mischen Sie keine Tabulatoren und Leerzeichen, da sonst leicht Fehler gemeldet werden können.
[Verwandte Empfehlungen]
1. Python kostenloses Video-Tutorial
3. Python objektorientiertes Video-Tutorial
Das obige ist der detaillierte Inhalt vonErfahren Sie, wie Sie Webbilder anhand von Schlüsselwörtern crawlen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



