
 Backend-Entwicklung
Python-Tutorial
Ausführliche Erläuterung von Beispielen zum Bereinigen von Zeichenfolgen in Python
Backend-Entwicklung
Python-Tutorial
Ausführliche Erläuterung von Beispielen zum Bereinigen von Zeichenfolgen in Python
Ausführliche Erläuterung von Beispielen zum Bereinigen von Zeichenfolgen in Python

In diesem Artikel werden hauptsächlich relevante Informationen zur String-Verarbeitung der Python-Datenbereinigung vorgestellt.
Vorwort
Die Datenbereinigung ist ein Komplex und mühsame (kubi) Arbeit, es ist auch das wichtigste Glied im gesamten Datenanalyseprozess. Manche Leute sagen, dass 80 % der Zeit eines Analyseprojekts darin besteht, Daten zu bereinigen. Das klingt seltsam, trifft aber auf die tatsächliche Arbeit zu. Es gibt zwei Zwecke der Datenbereinigung. Der erste besteht darin, die Daten durch die Bereinigung verfügbar zu machen. Die zweite besteht darin, die Daten für die spätere Analyse besser geeignet zu machen. Mit anderen Worten: Es gibt „schmutzige“ Daten, die gelöscht werden müssen, und saubere Daten, die ebenfalls gelöscht werden müssen.
Bei der Datenanalyse, insbesondere bei der Textanalyse, erfordert die Zeichenverarbeitung viel Energie, daher ist das Verständnis der Zeichenverarbeitung auch eine sehr wichtige Fähigkeit für die Datenanalyse.
String-Verarbeitungsmethoden
Lassen Sie uns zunächst die grundlegenden Methoden verstehen.
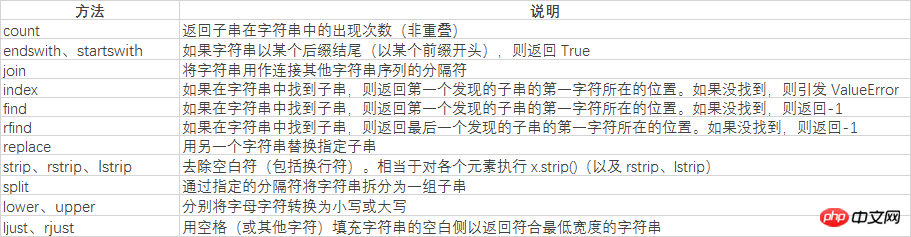
Zuerst Alle, lasst es uns verstehen. Die folgende String-Aufteilungsmethode
str='i like apple,i like bananer' print(str.split(','))
führt zur Aufteilung der Zeichenkette durch Kommas:
['i like apple', 'i like bananer']
print(str.split(' '))
Das Ergebnis der Aufteilung nach Leerzeichen:
['i', 'like', 'apple,i', 'like', 'bananer']
print(str.index(',')) print(str.find(','))
Beide Suchergebnisse sind:
12
Wenn nicht gefunden, gibt der Index einen Fehler zurück und die Suche gibt -1 zurück
print(str.count('i'))
Das Ergebnis ist:
4
connt wird verwendet, um die Häufigkeit der Zielzeichenfolge zu zählen
print(str.replace(',', ' ').split(' '))
Das Ergebnis ist:
['i', 'like', 'apple', 'i', 'like', 'bananer']
Hier ersetzt ersetzen Kommas durch Leerzeichen, Verwenden Sie Leerzeichen, um die Zeichenfolge aufzuteilen, gerade genug, um jedes Wort herauszunehmen.
Zusätzlich zu herkömmlichen Methoden ist das leistungsfähigere Zeichenverarbeitungstool Regulärer Ausdruck nichts anderes als.
Reguläre Ausdrücke
Bevor wir reguläre Ausdrücke verwenden, müssen wir die vielen Methoden in regulären Ausdrücken verstehen.

Lassen Sie mich die Verwendung der nächsten Methode betrachten. Verstehen Sie zunächst den Unterschied zwischen den Übereinstimmungs- und Suchmethoden
str = "Cats are smarter than dogs" pattern=re.compile(r'(.*) are (.*?) .*') result=re.match(pattern,str) for i in range(len(result.groups())+1): print(result.group(i))
Das Ergebnis ist:
Katzen sind schlauer als Hunde
Katzen
schlauer
Bei dieser Form der Pettern-Matching-Regel sind die Rückgabeergebnisse der Match- und Suchmethoden die gleich
Wenn Sie zu diesem Zeitpunkt das Muster in
pattern=re.compile(r'are (.*?) .*')
ändern, wird keine Übereinstimmung zurückgegeben und das Suchergebnis lautet:
sind schlauer als Hunde
klüger
Als nächstes lernen wir den Einsatz anderer Methoden kennen
str = "138-9592-5592 # number" pattern=re.compile(r'#.*$') number=re.sub(pattern,'',str) print(number)
Das Ergebnis ist:
138- 9592-5592
Das Obige dient dazu, die Nummer zu extrahieren, indem der Inhalt nach dem #-Zeichen durch nichts ersetzt wird.
Wir können den Querstrich der Zahl weiter ersetzen
print(re.sub(r'-*','',number))
Das Ergebnis ist:
13895925592
Wir können auch die Suchmethode verwenden, um die gefundene Zeichenfolge auszudrucken
str = "138-9592-5592 # number" pattern=re.compile(r'5') print(pattern.findall(str))
Das Ergebnis ist:
['5', '5', '5']
Der Gesamtinhalt regulärer Ausdrücke ist relativ umfangreich und wir müssen die Regeln für den Abgleich von Zeichenfolgen ausreichend verstehen. Im Folgenden sind die spezifischen Abgleichsregeln aufgeführt.

Vektorisierte ZeichenfolgeFunktion
Beim Bereinigen der verstreuten Daten, die analysiert werden sollen, ist dies häufig erforderlich Führen Sie einige Arbeiten zur String-Normalisierung durch.
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data)Das Ergebnis ist:

Sie können durch einige Integrationsmethoden eine vorläufige Beurteilung der Daten vornehmen, z Die Daten enthalten die Schlüsselwörter
print(data.str.contains('@'))
. Das Ergebnis lautet:

Sie können die Zeichenfolge auch teilen und die erforderliche Zeichenfolge extrahieren
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
pattern=re.compile(r'(\d*)@([a-z]+)\.([a-z]{2,4})')
result=data.str.match(pattern) #这里用fillall的方法也可以result=data.str.findall(pattern)
print(result)Das Ergebnis ist:
chen [(8622, xinlang, com)]
li [(120, qq, com)]
sun [(5243, gmail, com )]
wang [(5632, qq, com)]
zhao NaN
dtype: object
Um zu diesem Zeitpunkt beizutreten, müssen wir extrahieren die Vorderseite der E-Mail-Adresse. Der Name
print(result.str.get(0))
ergibt:

oder den Domainnamen, zu dem die E-Mail-Adresse gehört
print(result.str.get(1))
führt zu:

Natürlich können Sie es auch durch Slicing extrahieren, aber die Genauigkeit der extrahierten Daten ist nicht hoch
data = pd.Series({'li': '120@qq.com','wang':'5632@qq.com',
'chen': '8622@xinlang.com','zhao':np.nan,'sun':'5243@gmail.com'})
print(data.str[:6])Das Ergebnis ist:

Endlich verstehen wir die vektorisierte String-Methode

Zusammenfassung
[Verwandte Empfehlungen ]
1. Python kostenloses Video-Tutorial
2 Python objektorientiertes Video-Tutorial
3 Grundlegendes Einführungs-Tutorial zu Python
Das obige ist der detaillierte Inhalt vonAusführliche Erläuterung von Beispielen zum Bereinigen von Zeichenfolgen in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
Muss MySQL bezahlen?
Apr 08, 2025 pm 05:36 PM
MySQL hat eine kostenlose Community -Version und eine kostenpflichtige Enterprise -Version. Die Community -Version kann kostenlos verwendet und geändert werden, die Unterstützung ist jedoch begrenzt und für Anwendungen mit geringen Stabilitätsanforderungen und starken technischen Funktionen geeignet. Die Enterprise Edition bietet umfassende kommerzielle Unterstützung für Anwendungen, die eine stabile, zuverlässige Hochleistungsdatenbank erfordern und bereit sind, Unterstützung zu bezahlen. Zu den Faktoren, die bei der Auswahl einer Version berücksichtigt werden, gehören Kritikalität, Budgetierung und technische Fähigkeiten von Anwendungen. Es gibt keine perfekte Option, nur die am besten geeignete Option, und Sie müssen die spezifische Situation sorgfältig auswählen.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
MySQL kann nach dem Herunterladen nicht installiert werden
Apr 08, 2025 am 11:24 AM
Die Hauptgründe für den Fehler bei MySQL -Installationsfehlern sind: 1. Erlaubnisprobleme, Sie müssen als Administrator ausgeführt oder den Sudo -Befehl verwenden. 2. Die Abhängigkeiten fehlen, und Sie müssen relevante Entwicklungspakete installieren. 3. Portkonflikte müssen Sie das Programm schließen, das Port 3306 einnimmt, oder die Konfigurationsdatei ändern. 4. Das Installationspaket ist beschädigt. Sie müssen die Integrität herunterladen und überprüfen. 5. Die Umgebungsvariable ist falsch konfiguriert und die Umgebungsvariablen müssen korrekt entsprechend dem Betriebssystem konfiguriert werden. Lösen Sie diese Probleme und überprüfen Sie jeden Schritt sorgfältig, um MySQL erfolgreich zu installieren.
 Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt und kann nicht installiert werden. Reparaturlösung
Apr 08, 2025 am 11:21 AM
Die MySQL -Download -Datei ist beschädigt. Was soll ich tun? Wenn Sie MySQL herunterladen, können Sie die Korruption der Datei begegnen. Es ist heutzutage wirklich nicht einfach! In diesem Artikel wird darüber gesprochen, wie dieses Problem gelöst werden kann, damit jeder Umwege vermeiden kann. Nach dem Lesen können Sie nicht nur das beschädigte MySQL -Installationspaket reparieren, sondern auch ein tieferes Verständnis des Download- und Installationsprozesses haben, um zu vermeiden, dass Sie in Zukunft stecken bleiben. Lassen Sie uns zunächst darüber sprechen, warum das Herunterladen von Dateien beschädigt wird. Dafür gibt es viele Gründe. Netzwerkprobleme sind der Schuldige. Unterbrechung des Download -Prozesses und der Instabilität im Netzwerk kann zu einer Korruption von Dateien führen. Es gibt auch das Problem mit der Download -Quelle selbst. Die Serverdatei selbst ist gebrochen und natürlich auch unterbrochen, wenn Sie sie herunterladen. Darüber hinaus kann das übermäßige "leidenschaftliche" Scannen einer Antiviren -Software auch zu einer Beschädigung von Dateien führen. Diagnoseproblem: Stellen Sie fest, ob die Datei wirklich beschädigt ist
 Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
Braucht MySQL das Internet?
Apr 08, 2025 pm 02:18 PM
MySQL kann ohne Netzwerkverbindungen für die grundlegende Datenspeicherung und -verwaltung ausgeführt werden. Für die Interaktion mit anderen Systemen, Remotezugriff oder Verwendung erweiterte Funktionen wie Replikation und Clustering ist jedoch eine Netzwerkverbindung erforderlich. Darüber hinaus sind Sicherheitsmaßnahmen (wie Firewalls), Leistungsoptimierung (Wählen Sie die richtige Netzwerkverbindung) und die Datensicherung für die Verbindung zum Internet von entscheidender Bedeutung.
 Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Wie optimieren Sie die MySQL-Leistung für Hochlastanwendungen?
Apr 08, 2025 pm 06:03 PM
Die MySQL-Datenbankleistung Optimierungshandbuch In ressourcenintensiven Anwendungen spielt die MySQL-Datenbank eine entscheidende Rolle und ist für die Verwaltung massiver Transaktionen verantwortlich. Mit der Erweiterung der Anwendung werden jedoch die Datenbankleistung Engpässe häufig zu einer Einschränkung. In diesem Artikel werden eine Reihe effektiver Strategien zur Leistungsoptimierung von MySQL -Leistung untersucht, um sicherzustellen, dass Ihre Anwendung unter hohen Lasten effizient und reaktionsschnell bleibt. Wir werden tatsächliche Fälle kombinieren, um eingehende Schlüsseltechnologien wie Indexierung, Abfrageoptimierung, Datenbankdesign und Caching zu erklären. 1. Das Design der Datenbankarchitektur und die optimierte Datenbankarchitektur sind der Eckpfeiler der MySQL -Leistungsoptimierung. Hier sind einige Kernprinzipien: Die Auswahl des richtigen Datentyps und die Auswahl des kleinsten Datentyps, der den Anforderungen entspricht, kann nicht nur Speicherplatz speichern, sondern auch die Datenverarbeitungsgeschwindigkeit verbessern.
 Lösungen für den Dienst, der nach der MySQL -Installation nicht gestartet werden kann
Apr 08, 2025 am 11:18 AM
Lösungen für den Dienst, der nach der MySQL -Installation nicht gestartet werden kann
Apr 08, 2025 am 11:18 AM
MySQL hat sich geweigert, anzufangen? Nicht in Panik, lass es uns ausprobieren! Viele Freunde stellten fest, dass der Service nach der Installation von MySQL nicht begonnen werden konnte, und sie waren so ängstlich! Mach dir keine Sorgen, dieser Artikel wird dich dazu bringen, ruhig damit umzugehen und den Mastermind dahinter herauszufinden! Nachdem Sie es gelesen haben, können Sie dieses Problem nicht nur lösen, sondern auch Ihr Verständnis von MySQL -Diensten und Ihren Ideen zur Fehlerbehebungsproblemen verbessern und zu einem leistungsstärkeren Datenbankadministrator werden! Der MySQL -Dienst startete nicht und es gibt viele Gründe, von einfachen Konfigurationsfehlern bis hin zu komplexen Systemproblemen. Beginnen wir mit den häufigsten Aspekten. Grundkenntnisse: Eine kurze Beschreibung des Service -Startup -Prozesses MySQL Service Startup. Einfach ausgedrückt, lädt das Betriebssystem MySQL-bezogene Dateien und startet dann den MySQL-Daemon. Dies beinhaltet die Konfiguration
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
