

Die meisten Python-Tutorials im Internet sind Version 2.X. Viele Bibliotheken werden anders verwendet. Schauen wir uns die Details an . Beispiel
0x01
Ich hatte während des Frühlingsfestes nichts zu tun (wie frei ich bin), also habe ich ein einfaches Programm geschrieben, um ein paar Witze zu machen und den Prozess des Programmschreibens aufzuzeichnen. Das erste Mal, dass ich mit Crawlern in Kontakt kam, war, als ich einen Beitrag wie diesen sah. Es war ein lustiger Beitrag über das Crawlen von Fotos von Mädchen auf Omelette. Also fing ich an, selbst Katzen und Tiger zu imitieren und machte einige Bilder.
Technologie inspiriert die Zukunft. Wie kann man als Programmierer über Witze lachen, die besser für die körperliche und geistige Gesundheit sind?

0x02
Bevor wir die Ärmel hochkrempeln und loslegen, lasst uns etwas theoretisches Wissen bekannt machen.
Um es einfach auszudrücken: Wir müssen den Inhalt an einer bestimmten Stelle auf der Webseite herunterziehen. Wie müssen wir zuerst die Webseite analysieren, um zu sehen, welchen Inhalt wir haben? brauchen. Was wir dieses Mal zum Beispiel gecrawlt haben, sind Witze von der urkomischen Website. Wenn wir die Witzeseite der urkomischen Website öffnen, können wir viele Witze sehen. Kommen Sie zurück und beruhigen Sie sich, nachdem Sie es gelesen haben. Wenn Sie so weiter lachen, können wir keinen Code schreiben. In chrome öffnen wir das Inspect Element und erweitern dann die HTML-Tags Ebene für Ebene oder klicken mit der kleinen Maus, um das benötigte Element zu finden.
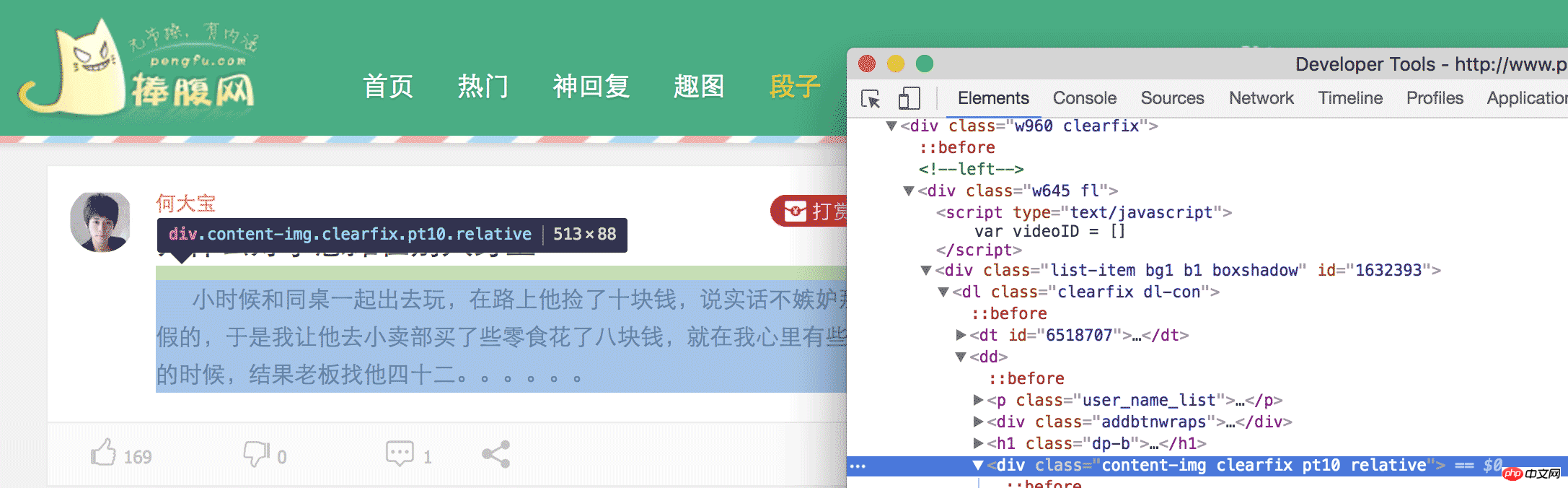
Schließlich können wir feststellen, dass der Inhalt in
der Witz ist, den wir brauchen . Wir können also alle
auf dieser Webseite finden und dann den darin enthaltenen Inhalt extrahieren, und schon sind wir fertig.
0x03
Okay, jetzt, da wir unser Ziel kennen, können wir die Ärmel hochkrempeln und loslegen. Ich verwende hier Python3. Bezüglich der Wahl von Python2 und Python3 kann jeder selbst entscheiden. Die Funktionen können realisiert werden, es gibt jedoch einige Unterschiede. Es wird jedoch weiterhin empfohlen, Python3 zu verwenden.
Wir möchten zuerst den Inhalt dieser Webseite abrufen gesamte Webseite.
Zuerst importieren wir urllib
Der Code lautet wie folgt:
import urllib.request as request
Dann können wir request verwenden, um die Webseite
abzurufen Der Code lautet wie folgt:
return request.urlopen(url).read()
Das Leben ist kurz, ich verwende Python, eine Codezeile, Download Die Webseite, sagen Sie, was sonst noch ein Grund ist, Python nicht zu verwenden.
Nach dem Herunterladen der Webseite müssen wir die Webseite analysieren, um die benötigten Elemente zu erhalten. Um Elemente zu analysieren, müssen wir ein anderes Tool namens Beautiful Soup verwenden. Damit können wir HTML und XML schnell analysieren und die Elemente erhalten, die wir benötigen.
Der Code lautet wie folgt:
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html"))Die Verwendung von BeautifulSoup zum Parsen einer Webseite ist nur ein Satz, aber wenn Sie den Code ausführen, wird eine solche Warnung mit einer Aufforderung angezeigt Sie müssen einen Parser-Server angeben, andernfalls kann es zu Fehlern auf anderen Plattformen oder Systemen kommen.
Der Code lautet wie folgt:
/Library/Frameworks/Python.framework/Versions/3.5/lib/python3.5/site-packages/bs4/init.py:181: UserWarning: No parser was explicitly specified, so I'm using the best available HTML parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 64 of the file joke.py. To get rid of this warning, change code that looks like this:
BeautifulSoup([your markup])
to this:
BeautifulSoup([your markup], "lxml")
markup_type=markup_type))Die Arten von Parsern und die Unterschiede zwischen verschiedenen Parsern werden in den offiziellen Dokumenten ausführlich erläutert. Derzeit ist die Verwendung von lxml zuverlässiger Parsing.
Nach der Änderung
lautet der Code wie folgt:
soup = BeautifulSoup(getHTML("http://www.pengfu.com/xiaohua_1.html", 'lxml'))Auf diese Weise wird es keine obige Warnung geben.
Der Code lautet wie folgt:
p_array = soup.find_all('p', {'class':"content-img clearfix pt10 relative"})Verwenden Sie die Funktion find_all , um alle p-Tags von class = content-img clearfix pt10 relative zu finden und diese dann zu durchlaufen array
Der Code lautet wie folgt:
for x in p_array: content = x.string
Auf diese Weise erhalten wir den Inhalt des Zwecks p. An diesem Punkt haben wir unser Ziel erreicht und sind zu unserem Witz aufgestiegen.
Aber beim Crawlen auf die gleiche Weise wird ein solcher Fehler gemeldet
Der Code lautet wie folgt:
raise RemoteDisconnected("Remote end closed connection without" http.client.RemoteDisconnected: Remote end closed connection without response说远端无响应,关闭了链接,看了下网络也没有问题,这是什么情况导致的呢?莫非是我姿势不对?
打开 charles 抓包,果然也没反应。唉,这就奇怪了,好好的一个网站,怎么浏览器可以访问,python 无法访问呢,是不是 UA 的问题呢?看了下 charles,发现,利用 urllib 发起的请求,UA 默认是 Python-urllib/3.5 而在 chrome 中访问 UA 则是 User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36,那会不会是因为服务器根据 UA 来判断拒绝了 python 爬虫。我们来伪装下试试看行不行
代码如下:
def getHTML(url):
head
ers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()这样就把 python 伪装成 chrome 去获取糗百的网页,可以顺利的得到数据。
至此,利用 python 爬取糗百和捧腹网的笑话已经结束,我们只需要分析相应的网页,找到我们感兴趣的元素,利用 python 强大的功能,就可以达到我们的目的,不管是 XXOO 的图,还是内涵段子,都可以一键搞定,不说了,我去找点妹子图看看。
# -*- coding: utf-8 -*-
import sys
import urllib.request as request
from bs4 import BeautifulSoup
def getHTML(url):
headers = {'User-Agent': 'User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'}
req = request.Request(url, headers=headers)
return request.urlopen(req).read()
def get_pengfu_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
return soup.find_all('p', {'class':"content-img clearfix pt10 relative"})
def get_pengfu_joke():
for x in range(1, 2):
url = 'http://www.pengfu.com/xiaohua_%d.html' % x
for x in get_pengfu_results(url):
content = x.string
try:
string = content.lstrip()
print(string + '\n\n')
except:
continue
return
def get_qiubai_results(url):
soup = BeautifulSoup(getHTML(url), 'lxml')
contents = soup.find_all('p', {'class':'content'})
restlus = []
for x in contents:
str = x.find('span').getText('\n','<br/>')
restlus.append(str)
return restlus
def get_qiubai_joke():
for x in range(1, 2):
url = 'http://www.qiushibaike.com/8hr/page/%d/?s=4952526' % x
for x in get_qiubai_results(url):
print(x + '\n\n')
return
if name == 'main':
get_pengfu_joke()
get_qiubai_joke()【相关推荐】
1. Python免费视频教程
3. Python基础入门手册
Das obige ist der detaillierte Inhalt vonPython-Implementierung des Netzwerk-Absatzseiten-Crawler-Falls. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



