

Während des Crawling-Vorgangs ist das Crawlen einiger Seiten vor der Anmeldung verboten. Zu diesem Zeitpunkt müssen Sie die Anmeldung simulieren. Im folgenden Artikel wird hauptsächlich erläutert, wie Sie den Python-Crawler verwenden, um die Zhihu-Anmeldung zu simulieren Das Methoden-Tutorial ist im Artikel sehr detailliert. Freunde, die es benötigen, können es sich gemeinsam ansehen.
Vorwort
Wie jeder weiß, der häufig Crawler schreibt, ist das Crawlen einiger Seiten vor dem Einloggen verboten, wie z. B. die Themenseite von Zhihu Benutzer müssen sich anmelden, um darauf zuzugreifen, und „Anmelden“ ist untrennbar mit der Cookie-Technologie in HTTP verbunden.
Login-Prinzip
Das Prinzip von Cookies ist sehr einfach, da HTTP ein zustandsloses Protokoll ist, also um das zustandslose HTTP-Protokoll zu verwenden Der Sitzungsstatus wird oben beibehalten, sodass der Server weiß, mit welchem Client er gerade zu tun hat. Die Cookie-Technologie entspricht einer vom Server dem Client zugewiesenen Kennung.
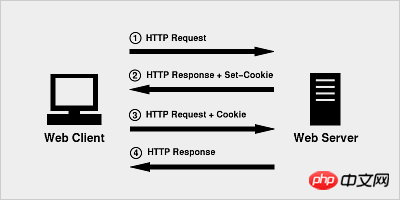
Wenn der Browser zum ersten Mal eine HTTP-Anfrage initiiert, enthält er keine Cookie-Informationen
Der Server verarbeitet die HTTP-Antwort zusammen mit einer Cookie-Information, die zusammen an den Browser zurückgegeben wird
Der Browser sendet die vom Server zurückgegebene Cookie-Information zusammen mit der zweiten Anfrage an den Server
Der Server empfängt die HTTP-Anfrage und stellt fest, dass sich im Anforderungsheader ein Cookie-Feld befindet, sodass er weiß, dass er sich bereits zuvor mit diesem Benutzer befasst hat.
Praktische Anwendung
Jeder, der Zhihu verwendet hat, weiß das, solange Sie Ihren Benutzernamen und angeben Passwort und Verifizierung Nach Eingabe des Codes können Sie sich anmelden. Das ist natürlich genau das, was wir sehen. Welche technischen Details sich dahinter verbergen, gilt es mithilfe eines Browsers zu entdecken. Lassen Sie uns nun Chrome verwenden, um zu sehen, was passiert, nachdem wir das Formular ausgefüllt haben.
(Wenn Sie bereits angemeldet sind, melden Sie sich zuerst ab) Rufen Sie zunächst die Zhihu-Anmeldeseite www.zhihu.com/#signin auf und öffnen Sie die Chrome-Entwicklersymbolleiste (drücken Sie F12). ) Versuchen Sie zunächst, einen falschen Bestätigungscode einzugeben und beobachten Sie, wie der Browser die Anfrage sendet.
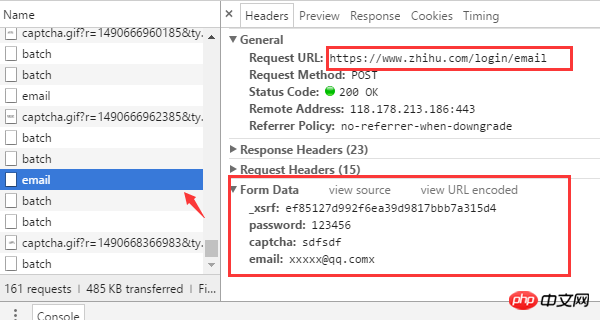
Mehrere wichtige Informationen können der Browseranfrage entnommen werden
Die Login-URL-Adresse lautet https://www.zhihu. com/login/email
Für die Anmeldung sind 4 Formulardaten erforderlich: Benutzername (E-Mail), Passwort (Passwort), Bestätigungscode (Captcha), _xsrf.
Die URL-Adresse zum Erhalten des Bestätigungscodes lautet https://www.zhihu.com/captcha.gif?r=1490690391695&type=login
Was ist _xsrf? Wenn Sie mit CSRF-Angriffen (Cross-Site Request Forgery) bestens vertraut sind, müssen Sie wissen, dass xsrf eine Folge von Pseudozufallszahlen ist, die zur Verhinderung von Cross-Site Request Forgery verwendet wird. Es ist normalerweise im Formular-Tag der Webseite vorhanden, indem Sie auf der Seite nach „xsrf“ suchen. Tatsächlich befindet sich _xsrf in einem versteckten Eingabe-Tag
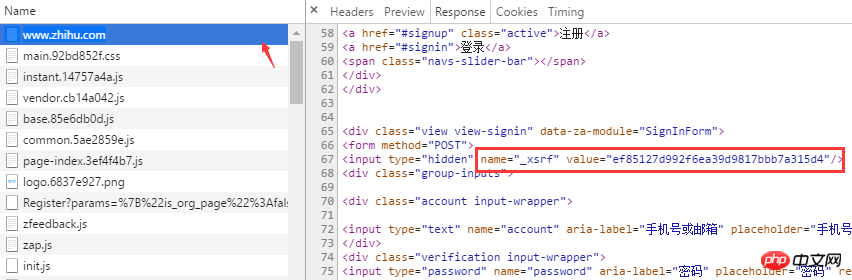
Nachdem Sie geklärt haben, wie Sie die für die Browser-Anmeldung erforderlichen Daten erhalten, können Sie nun mit dem Schreiben von Code beginnen, um die Browser-Anmeldung mit Python zu simulieren. Die beiden Bibliotheken von Drittanbietern, auf die beim Anmelden zurückgegriffen wird, sind Anfragen und das Modul „BeautifulSoup“ kann zur automatischen Verarbeitung von HTTP-Cookies verwendet werden die Kapselung von Cookies, die das Speichern von Cookies in Dateien und das Laden aus Dateien unterstützt. Das Sitzungsobjekt bietet Cookie-Persistenz- und Verbindungspooling-Funktionen. Anforderungen können über das Sitzungsobjekt gesendet werden.
pip install beautifulsoup4==4.5.3 pip install requests==2.13.0
Xsrf abrufen
from http import cookiejar
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
session.cookies.load(ignore_discard=True)
except LoadError:
print("load cookies failed")Der Tag, an dem sich xsrf befindet, wurde zuvor gefunden. Sie können die Suchmethode von BeatifulSoup verwenden, um ihn abzurufen das xsrf sehr praktisch. Wert
Bestätigungscode abrufen
def get_xsrf():
response = session.get("https://www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrfDer Bestätigungscode wird zurückgegeben über die /captcha.gif-Schnittstelle Ja, hier laden wir das Bestätigungscode-Bild herunter und speichern es zur manuellen Identifizierung im aktuellen Verzeichnis. Natürlich können Sie eine Support-Bibliothek eines Drittanbieters verwenden, um es automatisch zu identifizieren, z. B. Pytesser.
Anmelden
def get_captcha():
"""
把验证码图片保存到当前目录,手动识别验证码
:return:
"""
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
captcha = input("验证码:")
return captcha一切参数准备就绪之后,就可以请求登录接口了。
def login(email, password):
login_url = 'www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
for i in session.cookies:
print(i)
session.cookies.save()请求成功后,session 会自动把 服务端的返回的cookie 信息填充到 session.cookies 对象中,下次请求时,客户端就可以自动携带这些cookie去访问那些需要登录的页面了。
auto_login.py 示例代码
# encoding: utf-8
# !/usr/bin/env python
"""
作者:liuzhijun
"""
import time
from http import cookiejar
import requests
from bs4 import BeautifulSoup
headers = {
"Host": "www.zhihu.com",
"Referer": "www.zhihu.com/",
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87'
}
# 使用登录cookie信息
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
print(session.cookies)
session.cookies.load(ignore_discard=True)
except:
print("还没有cookie信息")
def get_xsrf():
response = session.get("www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrf
def get_captcha():
"""
把验证码图片保存到当前目录,手动识别验证码
:return:
"""
t = str(int(time.time() * 1000))
captcha_url = 'www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
captcha = input("验证码:")
return captcha
def login(email, password):
login_url = 'www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
for i in session.cookies:
print(i)
session.cookies.save()
if name == 'main':
email = "xxxx"
password = "xxxxx"
login(email, password)【相关推荐】
1. python爬虫入门(4)--详解HTML文本的解析库BeautifulSoup
2. python爬虫入门(3)--利用requests构建知乎API
3. python爬虫入门(2)--HTTP库requests
Das obige ist der detaillierte Inhalt vonTeilen Sie ein Beispiel für die Verwendung eines Python-Crawlers zur Simulation der Zhihu-Anmeldung. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



