

Analysieren Sie den Buffer-Quellcode in Java

In diesem Artikel werden hauptsächlich relevante Informationen zur Analyse des Pufferquellcodes in Java vorgestellt. Freunde, die sie benötigen, können sich auf
Analyse des Pufferquellcodes in Java
Buffer
Das Klassendiagramm von Buffer lautet wie folgt: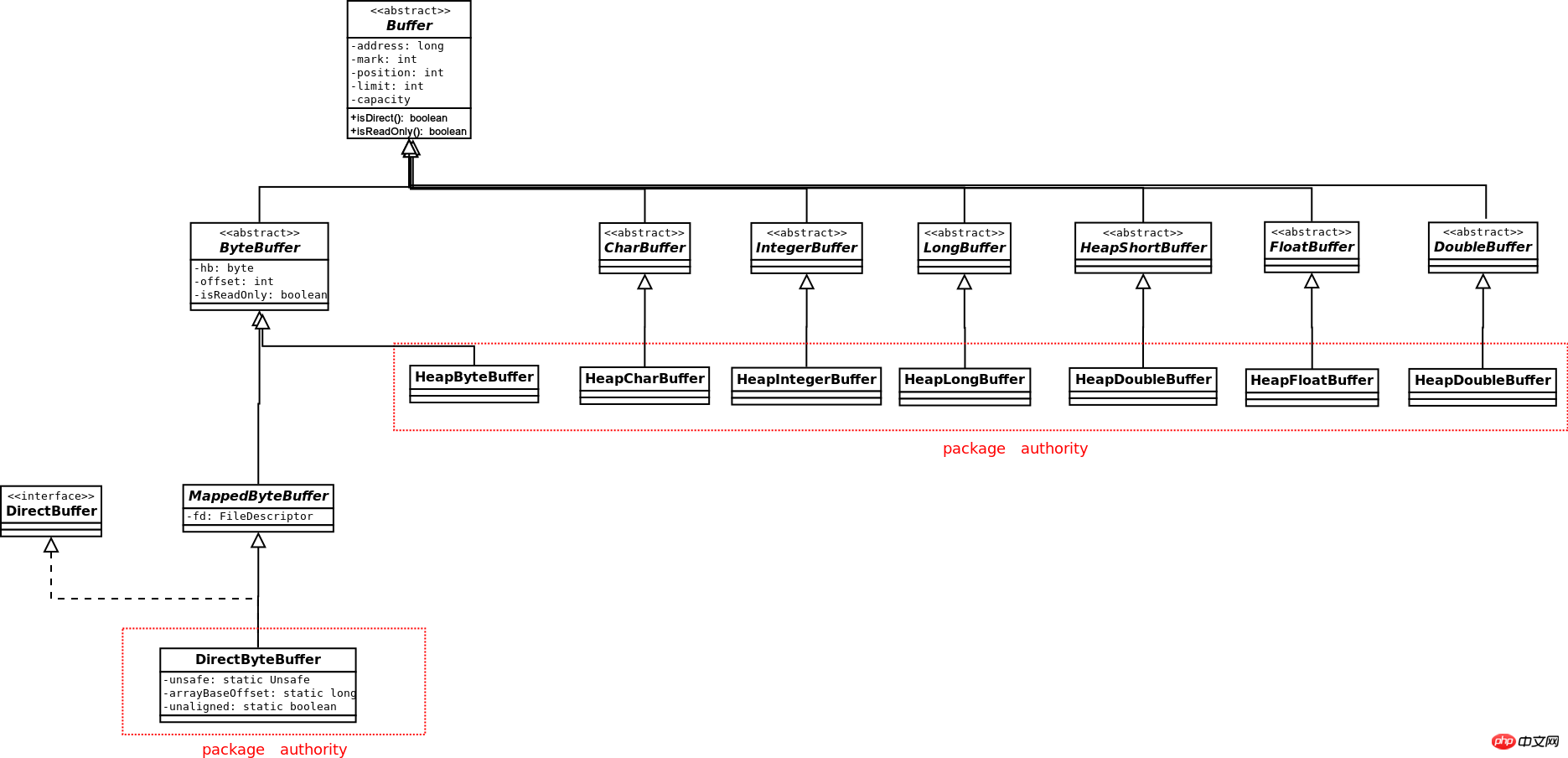
Das Wesen von Puffern vom Typ „Direkt“ und „Heap“
Die erste Wahl besteht darin, darüber zu sprechen, wie die JVM E/A-Vorgänge ausführt. JVM muss E/A-Vorgänge über Betriebssystemaufrufe abschließen. Beispielsweise kann das Lesen von Dateien über Lesesystemaufrufe abgeschlossen werden. Der Prototyp von read lautet:ssize_t read(int fd, void *buf, size_t nbytes), ähnlich wie bei anderen E/A-Systemaufrufen, erfordert im Allgemeinen einen Puffer als einen der Parameter, und der Puffer muss vorhanden sein kontinuierlich.
Puffer ist in zwei Kategorien unterteilt: Direkt und Heap. Diese beiden Arten von Puffern werden im Folgenden erläutert.Heap
Auf dem JVM-Heap ist ein Puffer vom Typ Heap vorhanden. Das Recycling und die Anordnung dieses Teils des Speichers sind die gleichen wie bei gewöhnlichen Objekten. Pufferobjekte vom Heap-Typ enthalten alle ein Array-Attribut, das einem Basisdatentyp entspricht (z. B. final **[] hb), und das Array ist der zugrunde liegende Puffer des Heap-Typs Buffer.- JVM kann den Puffer während der GC verschieben (kopieren und organisieren), und die Adresse des Puffers ist nicht festgelegt.
- Wenn das System aufgerufen wird, muss der Puffer kontinuierlich sein, aber das Array ist möglicherweise nicht kontinuierlich (die JVM-Implementierung erfordert keine kontinuierliche).
des temporären Direct verwenden
Puffer wird als Parameter für Betriebssystemaufrufe verwendet. Dies führt hauptsächlich aus zwei Gründen zu einer sehr geringen Effizienz:- Die Daten müssen vom Heap-Typ-Puffer in den vorübergehend erstellten Direktpuffer kopiert werden.
- kann eine große Anzahl von Pufferobjekten generieren, wodurch die Häufigkeit der GC erhöht wird. Daher kann während E/A-Vorgängen eine Optimierung durch Wiederverwendung des Puffers durchgeführt werden.
Direkt
Der Puffer vom Typ „Direkt“ existiert nicht auf dem Heap, sondern ist ein kontinuierliches Segment, das direkt von der JVM über malloc zugewiesen wird .Speicher, dieser Teil des Speichers wird zum Direktspeicher, und die JVM verwendet den Direktspeicher als Puffer, wenn sie E/A-Systemaufrufe durchführt.Beziehung zwischen MappedByteBuffer und DirectByteBuffer
Das ist ein bisschen rückwärts: Eigentlich sollte MappedByteBuffer eine Unterklasse von DirectByteBuffer sein, aber um die Spezifikation klar und einfach zu halten, und Aus Optimierungsgründen ist es einfacher, es umgekehrt zu machen, da DirectByteBuffer eine paketprivate Klasse ist (Dieser Absatz stammt aus dem Quellcode von MappedByteBuffer)MappedByteBuffer
MappedByteBuffer über FileChannel.map abrufen (MapMode-Modus, lange Position, lange Größe) Der Generierungsprozess von MappedByteBuffer wird unten anhand des Quellcodes erläutert.
Quellcode von FileChannel.map:
public MappedByteBuffer map(MapMode mode, long position, long size)
throws IOException
{
ensureOpen();
if (position < 0L)
throw new IllegalArgumentException("Negative position");
if (size < 0L)
throw new IllegalArgumentException("Negative size");
if (position + size < 0)
throw new IllegalArgumentException("Position + size overflow");
//最大2G
if (size > Integer.MAX_VALUE)
throw new IllegalArgumentException("Size exceeds Integer.MAX_VALUE");
int imode = -1;
if (mode == MapMode.READ_ONLY)
imode = MAP_RO;
else if (mode == MapMode.READ_WRITE)
imode = MAP_RW;
else if (mode == MapMode.PRIVATE)
imode = MAP_PV;
assert (imode >= 0);
if ((mode != MapMode.READ_ONLY) && !writable)
throw new NonWritableChannelException();
if (!readable)
throw new NonReadableChannelException();
long addr = -1;
int ti = -1;
try {
begin();
ti = threads.add();
if (!isOpen())
return null;
//size()返回实际的文件大小
//如果实际文件大小不符合,则增大文件的大小,文件的大小被改变,文件增大的部分默认设置为0。
if (size() < position + size) { // Extend file size
if (!writable) {
throw new IOException("Channel not open for writing " +
"- cannot extend file to required size");
}
int rv;
do {
//增大文件的大小
rv = nd.truncate(fd, position + size);
} while ((rv == IOStatus.INTERRUPTED) && isOpen());
}
//如果要求映射的文件大小为0,则不调用操作系统的mmap调用,只是生成一个空间容量为0的DirectByteBuffer
//并返回
if (size == 0) {
addr = 0;
// a valid file descriptor is not required
FileDescriptor dummy = new FileDescriptor();
if ((!writable) || (imode == MAP_RO))
return Util.newMappedByteBufferR(0, 0, dummy, null);
else
return Util.newMappedByteBuffer(0, 0, dummy, null);
}
//allocationGranularity的大小在我的系统上是4K
//页对齐,pagePosition为第多少页
int pagePosition = (int)(position % allocationGranularity);
//从页的最开始映射
long mapPosition = position - pagePosition;
//因为从页的最开始映射,增大映射空间
long mapSize = size + pagePosition;
try {
// If no exception was thrown from map0, the address is valid
//native方法,源代码在openjdk/jdk/src/solaris/native/sun/nio/ch/FileChannelImpl.c,
//参见下面的说明
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {
// An OutOfMemoryError may indicate that we've exhausted memory
// so force gc and re-attempt map
System.gc();
try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}
try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {
// After a second OOME, fail
throw new IOException("Map failed", y);
}
}
// On Windows, and potentially other platforms, we need an open
// file descriptor for some mapping operations.
FileDescriptor mfd;
try {
mfd = nd.duplicateForMapping(fd);
} catch (IOException ioe) {
unmap0(addr, mapSize);
throw ioe;
}
assert (IOStatus.checkAll(addr));
assert (addr % allocationGranularity == 0);
int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);
if ((!writable) || (imode == MAP_RO)) {
return Util.newMappedByteBufferR(isize,
addr + pagePosition,
mfd,
um);
} else {
return Util.newMappedByteBuffer(isize,
addr + pagePosition,
mfd,
um);
}
} finally {
threads.remove(ti);
end(IOStatus.checkAll(addr));
}
}Quellcode-Implementierung von map0:
JNIEXPORT jlong JNICALL
Java_sun_nio_ch_FileChannelImpl_map0(JNIEnv *env, jobject this,
jint prot, jlong off, jlong len)
{
void *mapAddress = 0;
jobject fdo = (*env)->GetObjectField(env, this, chan_fd);
//linux系统调用是通过整型的文件id引用文件的,这里得到文件id
jint fd = fdval(env, fdo);
int protections = 0;
int flags = 0;
if (prot == sun_nio_ch_FileChannelImpl_MAP_RO) {
protections = PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_RW) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_PV) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_PRIVATE;
}
//这里就是操作系统调用了,mmap64是宏定义,实际最后调用的是mmap
mapAddress = mmap64(
0, /* Let OS decide location */
len, /* Number of bytes to map */
protections, /* File permissions */
flags, /* Changes are shared */
fd, /* File descriptor of mapped file */
off); /* Offset into file */
if (mapAddress == MAP_FAILED) {
if (errno == ENOMEM) {
//如果没有映射成功,直接抛出OutOfMemoryError
JNU_ThrowOutOfMemoryError(env, "Map failed");
return IOS_THROWN;
}
return handle(env, -1, "Map failed");
}
return ((jlong) (unsigned long) mapAddress);
}Obwohl der Zise-Parameter von FileChannel.map() lang ist, beträgt die maximale Größe Integer.MAX_VALUE, was bedeutet, dass nur die maximale Größe des Speicherplatzes möglich ist auf 2G abgebildet werden. Tatsächlich kann der vom Betriebssystem bereitgestellte MMAP größeren Speicherplatz zuweisen, JAVA ist jedoch auf 2G beschränkt, und Puffer wie ByteBuffer können nur eine maximale Puffergröße von 2G zuweisen.
MappedByteBuffer ist ein durch mmap generierter Puffer. Dieser Teil des Puffers wird direkt vom Betriebssystem erstellt und verwaltet. Schließlich ermöglicht die JVM dem Betriebssystem, diesen Teil des Speichers direkt durch unmmap freizugeben .
Haep****Buffer
Im Folgenden wird ByteBuffer als Beispiel verwendet, um die Details des Puffers vom Heap-Typ zu veranschaulichen.
Diese Art von Puffer kann auf folgende Weise generiert werden:
ByteBuffer.allocate(int Capacity)
ByteBuffer.wrap(byte[] array) verwendet das eingehende Array als zugrunde liegenden Puffer. Eine Änderung des Arrays wirkt sich auf den Puffer aus, und eine Änderung des Puffers wirkt sich auch auf das Array aus.
ByteBuffer.wrap(byte[] array, int offset, int length)
Teil des übergebenen Arrays als zugrunde liegenden Puffer verwenden, Das Ändern des entsprechenden Teils des Arrays wirkt sich auf den Puffer aus, und das Ändern des Puffers wirkt sich auch auf das Array aus.
DirectByteBuffer
DirectByteBuffer kann nur von ByteBuffer.allocateDirect(int Capacity) generiert werden.
Der Quellcode von ByteBuffer.allocateDirect() lautet wie folgt:
public static ByteBuffer allocateDirect(int capacity) {
return new DirectByteBuffer(capacity);
}Der Quellcode von DirectByteBuffer() lautet wie folgt:
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
//直接内存是否要页对齐,我本机测试的不用
boolean pa = VM.isDirectMemoryPageAligned();
//页的大小,本机测试的是4K
int ps = Bits.pageSize();
//如果页对齐,则size的大小是ps+cap,ps是一页,cap也是从新的一页开始,也就是页对齐了
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//JVM维护所有直接内存的大小,如果已分配的直接内存加上本次要分配的大小超过允许分配的直接内存的最大值会
//引起GC,否则允许分配并把已分配的直接内存总量加上本次分配的大小。如果GC之后,还是超过所允许的最大值,
//则throw new OutOfMemoryError("Direct buffer memory");
Bits.reserveMemory(size, cap);
long base = 0;
try {
//是吧,unsafe可以直接操作底层内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {、
//没有分配成功,把刚刚加上的已分配的直接内存的大小减去。
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}Der Quellcode von unsafe.allocateMemory() befindet sich in openjdk/src/openjdk/hotspot/src/share/vm/prims/unsafe.cpp. Der spezifische Quellcode lautet wie folgt:
UNSAFE_ENTRY(jlong, Unsafe_AllocateMemory(JNIEnv *env, jobject unsafe, jlong size))
UnsafeWrapper("Unsafe_AllocateMemory");
size_t sz = (size_t)size;
if (sz != (julong)size || size < 0) {
THROW_0(vmSymbols::java_lang_IllegalArgumentException());
}
if (sz == 0) {
return 0;
}
sz = round_to(sz, HeapWordSize);
//最后调用的是 u_char* ptr = (u_char*)::malloc(size + space_before + space_after),也就是malloc。
void* x = os::malloc(sz, mtInternal);
if (x == NULL) {
THROW_0(vmSymbols::java_lang_OutOfMemoryError());
}
//Copy::fill_to_words((HeapWord*)x, sz / HeapWordSize);
return addr_to_java(x);
UNSAFE_ENDDie JVM weist über malloc einen kontinuierlichen Puffer zu. Dieser Teil des Puffers kann direkt als Pufferparameter für den Betrieb verwendet werden Systemaufrufe.
Das obige ist der detaillierte Inhalt vonAnalysieren Sie den Buffer-Quellcode in Java. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Perfekte Zahl in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur perfekten Zahl in Java. Hier besprechen wir die Definition, Wie prüft man die perfekte Zahl in Java?, Beispiele mit Code-Implementierung.
 Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Zufallszahlengenerator in Java
Aug 30, 2024 pm 04:27 PM
Leitfaden zum Zufallszahlengenerator in Java. Hier besprechen wir Funktionen in Java anhand von Beispielen und zwei verschiedene Generatoren anhand ihrer Beispiele.
 Weka in Java
Aug 30, 2024 pm 04:28 PM
Weka in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden für Weka in Java. Hier besprechen wir die Einführung, die Verwendung von Weka Java, die Art der Plattform und die Vorteile anhand von Beispielen.
 Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Smith-Nummer in Java
Aug 30, 2024 pm 04:28 PM
Leitfaden zur Smith-Zahl in Java. Hier besprechen wir die Definition: Wie überprüft man die Smith-Nummer in Java? Beispiel mit Code-Implementierung.
 Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
Fragen zum Java Spring-Interview
Aug 30, 2024 pm 04:29 PM
In diesem Artikel haben wir die am häufigsten gestellten Fragen zu Java Spring-Interviews mit ihren detaillierten Antworten zusammengestellt. Damit Sie das Interview knacken können.
 Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Brechen oder aus Java 8 Stream foreach zurückkehren?
Feb 07, 2025 pm 12:09 PM
Java 8 führt die Stream -API ein und bietet eine leistungsstarke und ausdrucksstarke Möglichkeit, Datensammlungen zu verarbeiten. Eine häufige Frage bei der Verwendung von Stream lautet jedoch: Wie kann man von einem Foreach -Betrieb brechen oder zurückkehren? Herkömmliche Schleifen ermöglichen eine frühzeitige Unterbrechung oder Rückkehr, aber die Stream's foreach -Methode unterstützt diese Methode nicht direkt. In diesem Artikel werden die Gründe erläutert und alternative Methoden zur Implementierung vorzeitiger Beendigung in Strahlverarbeitungssystemen erforscht. Weitere Lektüre: Java Stream API -Verbesserungen Stream foreach verstehen Die Foreach -Methode ist ein Terminalbetrieb, der einen Vorgang für jedes Element im Stream ausführt. Seine Designabsicht ist
 Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Zeitstempel für Datum in Java
Aug 30, 2024 pm 04:28 PM
Anleitung zum TimeStamp to Date in Java. Hier diskutieren wir auch die Einführung und wie man Zeitstempel in Java in ein Datum konvertiert, zusammen mit Beispielen.
 Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Gestalten Sie die Zukunft: Java-Programmierung für absolute Anfänger
Oct 13, 2024 pm 01:32 PM
Java ist eine beliebte Programmiersprache, die sowohl von Anfängern als auch von erfahrenen Entwicklern erlernt werden kann. Dieses Tutorial beginnt mit grundlegenden Konzepten und geht dann weiter zu fortgeschrittenen Themen. Nach der Installation des Java Development Kit können Sie das Programmieren üben, indem Sie ein einfaches „Hello, World!“-Programm erstellen. Nachdem Sie den Code verstanden haben, verwenden Sie die Eingabeaufforderung, um das Programm zu kompilieren und auszuführen. Auf der Konsole wird „Hello, World!“ ausgegeben. Mit dem Erlernen von Java beginnt Ihre Programmierreise, und wenn Sie Ihre Kenntnisse vertiefen, können Sie komplexere Anwendungen erstellen.
