

Seit kurzem muss ich Texterkennung durchführen und darf die Schnittstellen anderer Leute nicht direkt verwenden, daher kann ich nur versuchen, Open-Source-Bibliotheken zu verwenden. tesseract-ocr ist ein Open-Source-Texterkennungsprojekt von HP. Es kann schnell ein Bild- und Texterkennungssystem aufbauen und uns bei der Entwicklung eines OCR-Systems helfen, das Bilder erkennen kann. Da ich in einer Windows-Umgebung entwickle, muss ich das System in einer Windows-Umgebung installieren.
Schritt 1: Laden Sie das Installationspaket herunter
Demnach habe ich das inoffizielle Installationspaket gefunden. Es scheint, dass ich nur das 64-Bit-Installationspaket http://digi.bib gesehen habe. uni-mannheim .de/tesseract/tesseract-ocr-setup-4.00.00dev.exe, Sie können es direkt nach dem Download installieren, aber merken Sie sich Ihr Installationsverzeichnis, wir werden die Umgebungsvariablen später konfigurieren.
Wenn Sie keine englische Bild- und Texterkennung durchführen, müssen Sie auch Erkennungspakete in anderen Sprachen herunterladen.
Vereinfachtes Erkennungspaket für chinesische Schriftzeichen:
Traditionelles Erkennungspaket für chinesische Schriftzeichen:
Schritt 2: Installieren
Führen Sie das heruntergeladene Paket direkt aus tesseract -ocr-setup-4.00.00dev.exe, nächster Schritt, nächster Schritt zur Installation.
Schritt 3: Umgebungsvariablen konfigurieren
Hinweis: Mein System ist Win7, andere Systeme sollten ähnlich sein, genau wie beim Konfigurieren von Java-Variablen
Kopieren Sie Ihre Installationsadresse, ich bin installiert In C:Programme (x86)Tesseract-OCR lautet die Schnittstelle wie folgt:
Kopieren Sie den Installationspfad „C:Programme (x86)Tesseract-OCR“ und Geben Sie „Systemsteuerung und Sicherheitssystem“ ein und klicken Sie auf
„Systemschutz“

, um die folgende Schnittstelle aufzurufen:
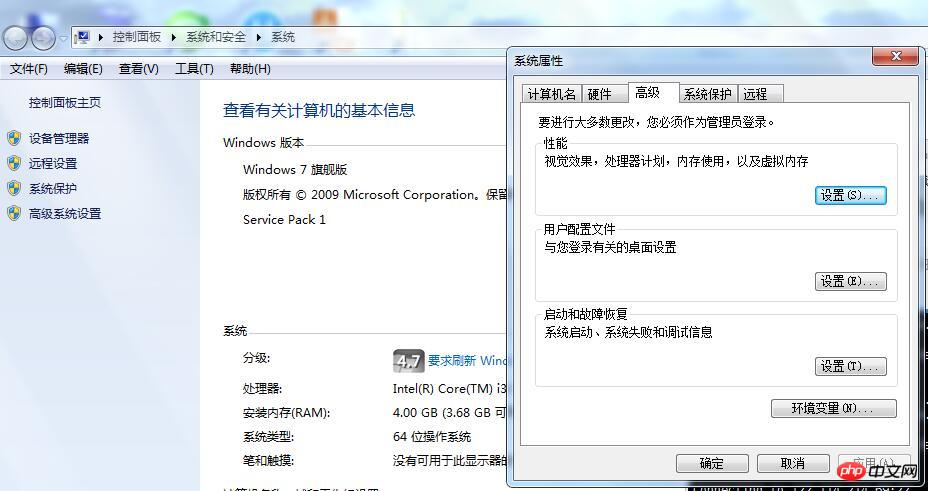
Klicken Sie auf die Umgebungsvariablen, um die folgende Konfigurationsoberfläche aufzurufen:
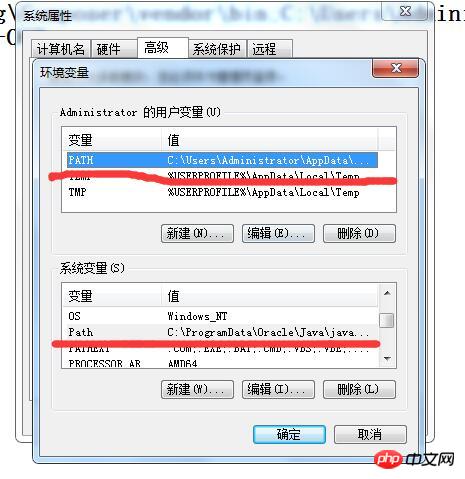
Fügen Sie den Installationspfad „C:Programme (x86)Tesseract-OCR“ hinzu. Bitte beachten Sie, dass Sie beim Hinzufügen der roten Linie PATH und Path am Anfang „;“ verwenden, um sie von den vorherigen Variablen zu trennen, und am Ende mit „;“ enden. Das Folgende ist ein Beispiel meiner Konfigurationsinformationen:
C:UsersAdministratorAppDataRoamingComposevendorbin;C:UsersAdministratorAppDataRoamingnpm;C:Program Files (x86)Tesseract-OCR;
Nach der Konfiguration Klicken Sie auf Speichern.
Öffnen Sie das Befehlsterminal und geben Sie Folgendes ein: tesseract -v. Sie können die Versionsinformationen sehen.

Wenn ein Fehler auftritt, wird dieser angezeigt ist wahrscheinlich eine Umgebungsvariable. Nicht richtig konfiguriert.
Auch wenn wir die Installation abgeschlossen haben, kann unser System immer noch kein Chinesisch erkennen. Wir müssen die Sprachpakete für vereinfachtes Chinesisch und traditionelles Chinesisch herunterladen (die Adressen sind oben angegeben). Gehen Sie zum Verzeichnis tessconfigs des Installationsverzeichnisses.
Zusätzlich: Da keine globalen Variablen konfiguriert sind, kann die Datenkonvertierung nicht über Festplatten hinweg durchgeführt werden. Hier fügen wir der Umgebungsvariablen eine Konfigurationsinformation hinzu
Systemvariablen—->Neu:

Fügen Sie einen TESSDATA_PREFIX-Variablennamen hinzu. Der Variablenwert ist immer noch mein Installationspfad C:Programme (x86)Tesseract-OCR;
Das obige ist der detaillierte Inhalt vonWie installiere und konfiguriere ich tesseract-ocr 4.00 unter Windows?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Windows prüft den Portbelegungsstatus
Windows prüft den Portbelegungsstatus
 Überprüfen Sie die Portbelegungsfenster
Überprüfen Sie die Portbelegungsfenster
 Windows-Fotos können nicht angezeigt werden
Windows-Fotos können nicht angezeigt werden
 Überprüfen Sie den Status der belegten Ports in Windows
Überprüfen Sie den Status der belegten Ports in Windows
 Windows kann nicht auf den freigegebenen Computer zugreifen
Windows kann nicht auf den freigegebenen Computer zugreifen
 Automatisches Windows-Update
Automatisches Windows-Update
 Windows Boot Manager
Windows Boot Manager
 Tastenkombinationen für den Windows-Sperrbildschirm
Tastenkombinationen für den Windows-Sperrbildschirm








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



