

Dies ist das erste Mal, dass ich den Node.js-Crawler lerne. Der Vorteil von Node.js besteht darin, dass er gleichzeitig ausgeführt werden kann.
Dies Der Crawler dient hauptsächlich dazu, Kursinformationen auf MOOC.com abzurufen und die erhaltenen Informationen in einer Datei zu speichern. Dabei wird die Cheerio-Bibliothek verwendet, die es uns ermöglicht, HTML bequem zu bedienen, genau wie bei der Verwendung von jQ
Bevor Sie beginnen, denken Sie daran:
npm install cheerio
Um gleichzeitig zu kriechen, muss das Promise-Objekt
//接受一个url爬取整个网页,返回一个Promise对象function getPageAsync(url){return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = '';
res.on('data',function(data){
html += data;
});
res.on('end',function(){
resolve(html);
});
res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
}In MOOC.com hat jeder Kurs eine ID im Voraus. Wir müssen die ID des Kurses, den wir aufnehmen möchten, und die Adresse eingeben Bei jedem Kurs handelt es sich um dieselbe Adresse plus ID, daher müssen wir nur die Adresse und die ID verketten, um die Adresse des Kurses zu erhalten
const baseUrl = 'http://www.imooc.com/learn/'; const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';//获取课程的IDconst videosId = [773,371];
Um den Inhalt jedes Kurses gleichzeitig zu erhalten, verwenden Sie die All-Methode in Promise
Promise//当所有网页的内容爬取完毕 .all(courseArray)
.then((pages)=>{//所有页面需要的内容let courseData = [];//遍历每个网页提取出所需要的内容pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
});//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}//对所需要的内容进行排序courseData.sort((a,b)=>{return a.number > b.number;
});//在重新将爬取内容写入文件中前,清空文件fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{if(err){
console.log(err)
}
});
printfData(courseData);
});Im Dann ist die Methode „pages“ die HTML-Seite jedes Kurses. Wir müssen auch die folgende Funktion extrahieren:
//接受一个爬取下来的网页内容,查找网页中需要的信息function filterChapter(html){
const $ = cheerio.load(html);//所有章const chapters = $('.chapter');//课程的标题和学习人数let title = $('.hd>h2').text();
let number = 0;//最后返回的数据//每个网页需要的内容的结构let courseData = {'title':title,'number':number,'videos':[]
};
chapters.each(function(item){
let chapter = $(this);//文章标题let chapterTitle = Trim(chapter.find('strong').text(),'g');//每个章节的结构let chapterdata = {'chapterTitle':chapterTitle,'video':[]
};//一个网页中的所有视频let videos = chapter.find('.video').children('li');
videos.each(function(item){//视频标题let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');//视频IDlet id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({'title':videoTitle,'id':id
})
});
courseData.videos.push(chapterdata);
});return courseData;
}Hinweis: Die Anzahl der Studenten, die den Kurs studieren, ist oben auf 0 gesetzt, da die Anzahl der Studenten, die den Kurs studieren, dynamisch mithilfe von Ajax ermittelt wird. Daher habe ich später eine Methode geschrieben, um speziell die Anzahl der Studenten zu ermitteln, die den Kurs studieren Die verwendete Trim()-Methode lautet: Entfernen Sie die Leerzeichen im Text
Ermitteln Sie die Anzahl der Personen, die den Kurs lernen:
//获取上课人数function getNumber(url){
let datas = '';
http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
});
res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
}Auf diese Weise möchten Sie den Kurs erhalten. Die Anzahl der studierenden Studenten wird zum Array „courseMembers“ hinzugefügt und schließlich wird die Anzahl der Studenten, die den Kurs studieren, dem entsprechenden Kurs zugewiesen
//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}Nachdem wir die Daten erhalten haben, müssen wir sie in einer Datei in einem bestimmten Format speichern
//写入文件function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{if(err){
console.log(err);
}
})
}//打印信息function printfData(coursesData){
coursesData.forEach((courseData)=>{ // console.log(`${courseData.number}人学习过${courseData.title}\n`); writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`);
courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;// console.log(chapterTitle + '\n'); writeFile(outputFile,`\n ${chapterTitle}\n`);
item.video.forEach(function(item){// console.log(' 【' + item.id + '】' + item.title + '\n'); writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
});
});
}Die zuletzt erhaltenen Daten:
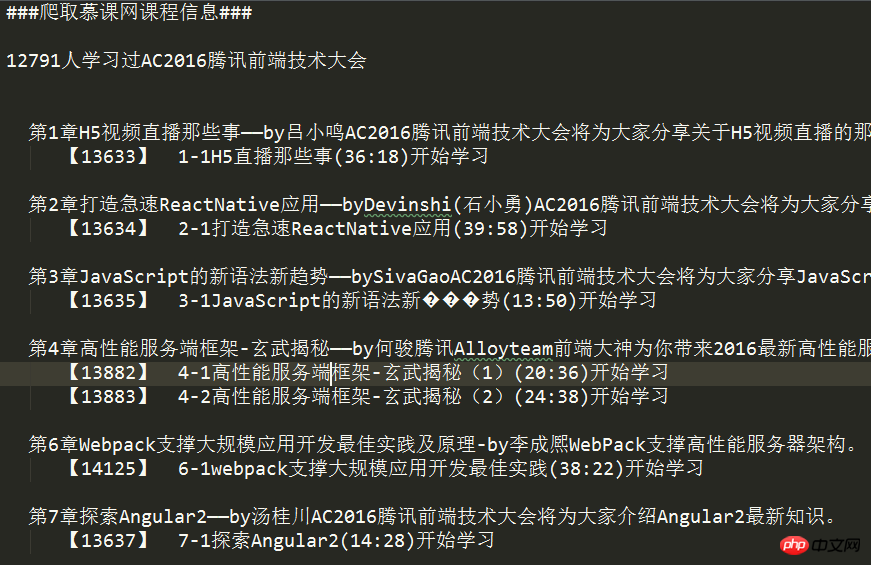
Quellcode:
/**
* Created by hp-pc on 2017/6/7 0007. */const http = require('http');
const fs = require('fs');
const cheerio = require('cheerio');
const baseUrl = 'http://www.imooc.com/learn/';
const baseNuUrl = 'http://www.imooc.com/course/AjaxCourseMembers?ids=';//获取课程的IDconst videosId = [773,371];//输出的文件const outputFile = 'test.txt';//记录学习课程的人数let courseMembers = [];//去除字符串中的空格function Trim(str,is_global)
{
let result;
result = str.replace(/(^\s+)|(\s+$)/g,"");if(is_global.toLowerCase()=="g")
{
result = result.replace(/\s/g,"");
}return result;
}//接受一个url爬取整个网页,返回一个Promise对象function getPageAsync(url){return new Promise((resolve,reject)=>{
console.log(`正在爬取${url}的内容`);
http.get(url,function(res){
let html = '';
res.on('data',function(data){
html += data;
});
res.on('end',function(){
resolve(html);
});
res.on('error',function(err){
reject(err);
console.log('错误信息:' + err);
})
});
})
}//接受一个爬取下来的网页内容,查找网页中需要的信息function filterChapter(html){
const $ = cheerio.load(html);//所有章const chapters = $('.chapter');//课程的标题和学习人数let title = $('.hd>h2').text();
let number = 0;//最后返回的数据//每个网页需要的内容的结构let courseData = {'title':title,'number':number,'videos':[]
};
chapters.each(function(item){
let chapter = $(this);//文章标题let chapterTitle = Trim(chapter.find('strong').text(),'g');//每个章节的结构let chapterdata = {'chapterTitle':chapterTitle,'video':[]
};//一个网页中的所有视频let videos = chapter.find('.video').children('li');
videos.each(function(item){//视频标题let videoTitle = Trim($(this).find('a.J-media-item').text(),'g');//视频IDlet id = $(this).find('a').attr('href').split('video/')[1];
chapterdata.video.push({'title':videoTitle,'id':id
})
});
courseData.videos.push(chapterdata);
});return courseData;
}//获取上课人数function getNumber(url){
let datas = '';
http.get(url,(res)=>{
res.on('data',(chunk)=>{
datas += chunk;
});
res.on('end',()=>{
datas = JSON.parse(datas);
courseMembers.push({'id':datas.data[0].id,'numbers':parseInt(datas.data[0].numbers,10)});
});
});
}//写入文件function writeFile(file,string) {
fs.appendFileSync(file,string,(err)=>{if(err){
console.log(err);
}
})
}//打印信息function printfData(coursesData){
coursesData.forEach((courseData)=>{ // console.log(`${courseData.number}人学习过${courseData.title}\n`); writeFile(outputFile,`\n\n${courseData.number}人学习过${courseData.title}\n\n`);
courseData.videos.forEach(function(item){
let chapterTitle = item.chapterTitle;// console.log(chapterTitle + '\n'); writeFile(outputFile,`\n ${chapterTitle}\n`);
item.video.forEach(function(item){// console.log(' 【' + item.id + '】' + item.title + '\n'); writeFile(outputFile,` 【${item.id}】 ${item.title}\n`);
})
});
});
}//所有页面爬取完后返回的Promise数组let courseArray = [];//循环所有的videosId,和baseUrl进行字符串拼接,爬取网页内容videosId.forEach((id)=>{//将爬取网页完毕后返回的Promise对象加入数组courseArray.push(getPageAsync(baseUrl + id));//获取学习的人数getNumber(baseNuUrl + id);
});
Promise//当所有网页的内容爬取完毕 .all(courseArray)
.then((pages)=>{//所有页面需要的内容let courseData = [];//遍历每个网页提取出所需要的内容pages.forEach((html)=>{
let courses = filterChapter(html);
courseData.push(courses);
});//给每个courseMenners.number赋值for(let i=0;i<videosId.length;i++){for(let j=0;j<videosId.length;j++){if(courseMembers[i].id +'' == videosId[j]){
courseData[j].number = courseMembers[i].numbers;
}
}
}//对所需要的内容进行排序courseData.sort((a,b)=>{return a.number > b.number;
});//在重新将爬取内容写入文件中前,清空文件fs.writeFileSync(outputFile,'###爬取慕课网课程信息###',(err)=>{if(err){
console.log(err)
}
});
printfData(courseData);
});Das obige ist der detaillierte Inhalt vonBeispiel-Tutorial zum Crawlen von MOOC-Kursinformationen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



