
Im vorherigen Abschnitt „Implementierung des Spring-Cloud-Sleuth + Zipkin-Tracking-Dienstes (1)“ haben wir Microservice-Zipkin-Server, Microservice-Zipkin-Client und Microservice verwendet Drei Zipkin-Client-Backend-Programme implementieren die Linkverfolgung von Serviceaufrufen mithilfe von http für die Kommunikation und Datenpersistenz im Speicher.
Hier nehmen wir zwei Änderungen vor: Die Daten werden nicht mehr im Speicher gespeichert, sondern in der Datenbank gespeichert. Zweitens wird die http-Kommunikation auf asynchrone mq-Kommunikation umgestellt.
Wir verwenden weiterhin die drei Programme im vorherigen Abschnitt, um Änderungen vorzunehmen, damit jeder die Unterschiede sehen kann. Hier wird jedem Projektnamen ein Stream hinzugefügt, um den Unterschied anzuzeigen.
Um die http-Methode auf Kommunikation über MQ umzustellen, müssen wir den ursprünglichen abhängigen io.zipkin.java:zipkin-server durch „Zu verwenden“ ersetzen MySQL-Persistenz Gleichzeitig mit Spring-Cloud-Sleuth-Zipkin-Stream und Spring-Cloud-Starter-Stream-Rabbit
müssen wir MySQL-bezogene Abhängigkeiten hinzufügen.
Alle Maven-Abhängigkeiten lauten wie folgt:
" <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <!--zipkin依赖--> <!--此依赖会自动引入spring-cloud-sleuth-stream并且引入zipkin的依赖包--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>io.zipkin.java</groupId> <artifactId>zipkin-autoconfigure-ui</artifactId> <scope>runtime</scope> </dependency> <!--保存到数据库需要如下依赖--> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-jdbc</artifactId> </dependency> "
Nachdem wir die oben genannten Maven-Abhängigkeiten hinzugefügt haben, ersetzen wir die Annotation @EnableZipkinServer in der Startup-Klasse ZipkinServer durch @EnableZipkinStreamServer.
Die Details lauten wie folgt :
package com.yangyang.cloud;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.sleuth.zipkin.stream.EnableZipkinStreamServer;
/**
* Created by chenshunyang on 2017/5/24.
*/
@EnableZipkinStreamServer// //使用Stream方式启动ZipkinServer
@SpringBootApplication
public class ZipkinStreamServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinStreamServerApplication.class,args);
}
}Klicken Sie auf den Quellcode der @EnableZipkinStreamServer-Annotation und wir können sehen, dass dadurch auch die @EnableZipkinServer-Annotation eingeführt und außerdem ein Rabbit-MQ-Nachrichtenwarteschlangen-Listener erstellt wird. 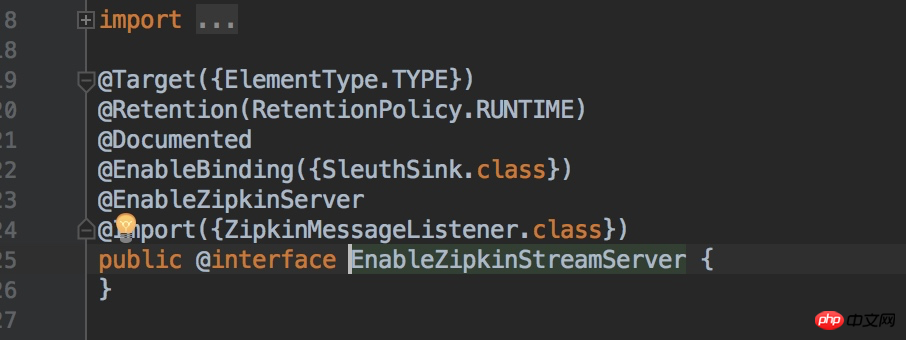
um den Empfang von MQ-Nachrichten zu erleichtern, die vom Nachrichten-Client gesendet werden.
Da die Nachrichten-Middleware Rabbit MQ und MySQL verwendet werden, müssen wir auch relevante Konfigurationen zur Konfigurationsdatei application.properties hinzufügen:
server.port=11020 spring.application.name=microservice-zipkin-stream-server #zipkin数据保存到数据库中需要进行如下配置 #表示当前程序不使用sleuth spring.sleuth.enabled=false #表示zipkin数据存储方式是mysql zipkin.storage.type=mysql #数据库脚本创建地址,当有多个是可使用[x]表示集合第几个元素 spring.datasource.schema[0]=classpath:/zipkin.sql #spring boot数据源配置 spring.datasource.url=jdbc:mysql://localhost:3306/zipkin?autoReconnect=true&useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull&useSSL=false spring.datasource.username=root spring.datasource.password=123456 spring.datasource.driver-class-name=com.mysql.jdbc.Driver spring.datasource.initialize=true spring.datasource.continue-on-error=true #rabbitmq配置 spring.rabbitmq.host=localhost spring.rabbitmq.port=5672 spring.rabbitmq.username=guest spring.rabbitmq.password=guest
Darunter kann zipkin.sql kopiert werden Direkt zur offiziellen Website, Sie können es auch von dieser Demo kopieren
Um Störungen durch die http-Kommunikation zu vermeiden, haben wir den ursprünglichen Abhörport von 11008 auf 11020 geändert, das Programm gestartet, es wurde kein Fehler gemeldet und die Rabbit-Verbindung hergestellt Das Protokoll zeigt an, dass das Programm erfolgreich gestartet wurde.
Wie die Konfiguration im vorherigen Abschnitt ist auch die Clientkonfiguration sehr einfach Nur Maven-Abhängigkeit Sie müssen das ursprüngliche Spring-Cloud-Starter-Zipkin durch die folgenden zwei Abhängigkeiten ersetzen
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-sleuth-zipkin-stream</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-stream-rabbit</artifactId> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-sleuth</artifactId> </dependency>
Fügen Sie außerdem die Konfiguration für die Verbindung mit MQ in der Konfigurationsdatei hinzu
server: port: 11021 spring: application: name: microservice-zipkin-stream-client #rabbitmq配置 rabbitmq: host: 127.0.0.1 port : 5672 username: guest password: guest
Um den Unterschied darzustellen, wurde natürlich auch der Port entsprechend angepasst
Wir haben die Adresse des Verbrauchers viele Male besucht und können im Protokoll sehen, dass die Anfrage nicht plötzlich lange dauern wird.
Um die Funktion ohne Datenverlust durch die MQ-Kommunikation zu nutzen, löschen wir die Daten in der Datenbank und aktualisieren dann die Zipkin-Serverschnittstelle. Sie können sehen, dass keine Daten mehr vorhanden sind
Dann werden wir das Zipkin-Serverprogramm schließen und dann mehrmals auf die Verbraucheradresse zugreifen. Nach erfolgreichem Start greifen wir auf die Benutzeroberfläche zu.
Dies zeigt, dass wir nach dem Neustart unseres Zipkins die von der generierten Informationsdaten erfolgreich erhalten haben Anbieter und Verbraucher während der Abschaltzeit von MQ. Auf diese Weise können wir die Restdienst-Anrufverfolgungsfunktion von Spring-Cloud-Sleuth-Stream + Zipkin verwenden.
Das obige ist der detaillierte Inhalt vonSpring-Cloud-Sleuth+Zipkin-Tracking-Service-Implementierung (2). Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Erstellen Sie einen Internetserver
Erstellen Sie einen Internetserver
 So beheben Sie Fehler, die bei der GeForce-Erfahrung aufgetreten sind
So beheben Sie Fehler, die bei der GeForce-Erfahrung aufgetreten sind
 Der Unterschied zwischen Tastendruck und Tastendruck
Der Unterschied zwischen Tastendruck und Tastendruck
 Wozu dient der Roaming-Ordner?
Wozu dient der Roaming-Ordner?
 So lösen Sie err_connection_reset
So lösen Sie err_connection_reset
 So verwenden Sie eine Python-for-Schleife
So verwenden Sie eine Python-for-Schleife
 SEO-Seitenbeschreibung
SEO-Seitenbeschreibung
 Win10-Tutorial zum Abrufen von Arbeitsplatzsymbolen
Win10-Tutorial zum Abrufen von Arbeitsplatzsymbolen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



