

Die Hauptaufgabe einer Laufzeitinstanz einer virtuellen Java-Maschine ist: Sie ist für die Ausführung eines Java-Programms verantwortlich. Wenn ein Java-Programm gestartet wird, wird eine Instanz einer virtuellen Maschine geboren. Wenn das Programm geschlossen und beendet wird, stirbt auch die Instanz der virtuellen Maschine. Wenn drei Java-Programme gleichzeitig auf demselben Computer ausgeführt werden, werden drei Java Virtual Machine-Instanzen erhalten. Jedes Java-Programm wird in einer eigenen Java Virtual Machine-Instanz ausgeführt.
Eine Java Virtual Machine-Instanz führt ein Java-Programm aus, indem sie die main()-Methode einer Anfangsklasse aufruft. Die main()-Methode muss öffentlich und statisch sein, void zurückgeben und ein String-Array als Parameter akzeptieren. Jede Klasse mit einer solchen main()-Methode kann als Ausgangspunkt für die Ausführung eines Java-Programms verwendet werden.
public class Test {public static void main(String[] args) {// TODO Auto-generated method stub
System.out.println("Hello World");
}
}Im obigen Beispiel ist die main()-Methode in der Anfangsklasse des Java-Programms der Startpunkt des Anfangsthreads des Programms, und alle anderen Threads werden von diesem Anfangsthread gestartet .
Es gibt zwei Arten von Threads innerhalb der Java Virtual Machine: Daemon-Threads und Nicht-Daemon-Threads. Daemon-Threads werden normalerweise von der virtuellen Maschine selbst verwendet, z. B. Threads, die Garbage-Collection-Aufgaben ausführen. Ein Java-Programm kann jedoch auch jeden von ihm erstellten Thread als Daemon-Thread markieren. Der anfängliche Thread im Java-Programm – derjenige, der in main() beginnt – ist ein Nicht-Daemon-Thread.
Solange Nicht-Daemon-Threads ausgeführt werden, wird das Java-Programm weiterhin ausgeführt. Wenn alle Nicht-Daemon-Threads im Programm beendet werden, wird die Instanz der virtuellen Maschine automatisch beendet. Wenn der Sicherheitsmanager dies zulässt, kann das Programm selbst auch beendet werden, indem die Methode „exit()“ der Klasse „Runtime“ oder „System“ aufgerufen wird.
Die folgende Abbildung ist das Strukturdiagramm der virtuellen JAVA-Maschine. Jede virtuelle Java-Maschine verfügt über ein Klassenladesubsystem, das auf dem angegebenen vollständig qualifizierten Namen Load basiert Typ (Klasse oder Schnittstelle). Ebenso verfügt jede virtuelle Java-Maschine über eine Ausführungs-Engine, die für die Ausführung von Anweisungen verantwortlich ist, die in den Methoden der geladenen Klasse enthalten sind.
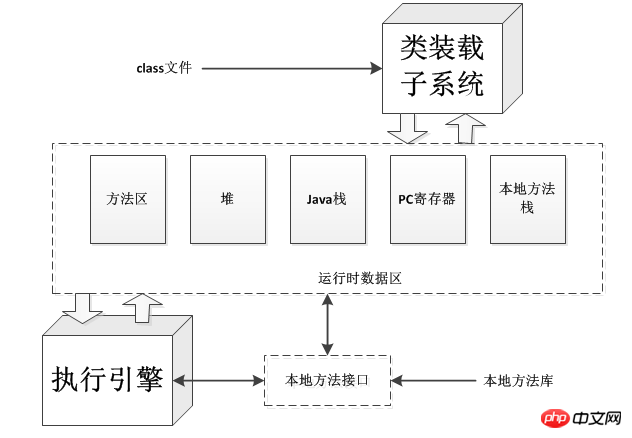
Wenn die virtuelle JAVA-Maschine ein Programm ausführt, benötigt sie Speicher, um viele Dinge zu speichern, wie zum Beispiel: Bytecode, andere aus geladenen Klassendateien erhaltene Informationen, vom Programm erstellte Objekte , an Methoden übergebene Parameter, Rückgabewerte, lokale Variablen usw. Die Java Virtual Machine organisiert diese Dinge zur einfachen Verwaltung in mehrere „Laufzeitdatenbereiche“.
Einige Laufzeitdatenbereiche werden von allen Threads im Programm gemeinsam genutzt, während andere nur einem Thread gehören können. Jede Java Virtual Machine-Instanz verfügt über einen Methodenbereich und einen Heap, die von allen Threads in der Virtual Machine-Instanz gemeinsam genutzt werden. Wenn eine virtuelle Maschine eine Klassendatei lädt, analysiert sie die Typinformationen aus den in der Klassendatei enthaltenen Binärdaten. Fügen Sie diese Typinformationen dann in den Methodenbereich ein. Wenn das Programm ausgeführt wird, legt die virtuelle Maschine alle vom Programm während der Ausführung erstellten Objekte auf dem Heap ab.

Wenn jeder neue Thread erstellt wird, erhält er ein eigenes PC-Register (Programmzähler) und einen Java-Stack. Wenn der Thread eine Java-Methode ausführt (nicht nativ). Methode), dann zeigt der Wert des PC-Registers immer auf die nächste auszuführende Anweisung und sein Java-Stack speichert immer den Status des Java-Methodenaufrufs im Thread – einschließlich seiner lokalen Variablen, die die übergebenen Parameter sind beim Aufruf der Rückgabewert und die Zwischenergebnisse der Operation usw. Der Status lokaler Methodenaufrufe wird im lokalen Methodenstapel in einer Methode gespeichert, die von der spezifischen Implementierung abhängt, oder er kann sich in einem Register oder einem anderen Speicherbereich befinden, der sich auf eine bestimmte Implementierung bezieht.
Der Java-Stack besteht aus vielen Stack-Frames. Ein Stack-Frame enthält den Status eines Java-Methodenaufrufs. Wenn ein Thread eine Java-Methode aufruft, schiebt die virtuelle Maschine einen neuen Stapelrahmen in den Java-Stack des Threads. Wenn die Methode zurückkehrt, wird der Stapelrahmen aus dem Java-Stack entfernt und verworfen.
Die Java Virtual Machine hat keine Register und ihr Befehlssatz verwendet den Java-Stack zum Speichern von Zwischendaten. Der Grund für dieses Design besteht darin, den Befehlssatz der Java Virtual Machine so kompakt wie möglich zu halten und die Implementierung der Java Virtual Machine auf Plattformen mit wenigen Allzweckregistern zu erleichtern. Darüber hinaus unterstützt die stapelbasierte Architektur der Java Virtual Machine auch die Codeoptimierung dynamischer Compiler und Just-in-Time-Compiler, die von einigen virtuellen Maschinen zur Laufzeit implementiert werden.
Die folgende Abbildung zeigt den von der Java Virtual Machine für jeden Thread erstellten Speicherbereich. Diese Speicherbereiche sind privat und kein Thread kann auf das PC-Register oder den Java-Stack eines anderen Threads zugreifen.

Die obige Abbildung zeigt einen Schnappschuss einer virtuellen Maschineninstanz mit drei ausgeführten Threads. Sowohl Thread 1 als auch Thread 2 führen Java-Methoden aus, während Thread 3 eine native Methode ausführt.
Java栈都是向下生长的,而栈顶都显示在图的底部。当前正在执行的方法的栈帧则以浅色表示,对于一个正在运行Java方法的线程而言,它的PC寄存器总是指向下一条将被执行的指令。比如线程1和线程2都是以浅色显示的,由于线程3当前正在执行一个本地方法,因此,它的PC寄存器——以深色显示的那个,其值是不确定的。
Java虚拟机是通过某些数据类型来执行计算的,数据类型可以分为两种:基本类型和引用类型,基本类型的变量持有原始值,而引用类型的变量持有引用值。

Java语言中的所有基本类型同样也都是Java虚拟机中的基本类型。但是boolean有点特别,虽然Java虚拟机也把boolean看做基本类型,但是指令集对boolean只有很有限的支持,当编译器把Java源代码编译为字节码时,它会用int或者byte来表示boolean。在Java虚拟机中,false是由整数零来表示的,所有非零整数都表示true,涉及boolean值的操作则会使用int。另外,boolean数组是当做byte数组来访问的,但是在“堆”区,它也可以被表示为位域。
Java虚拟机还有一个只在内部使用的基本类型:returnAddress,Java程序员不能使用这个类型,这个基本类型被用来实现Java程序中的finally子句。该类型是jsr, ret以及jsr_w指令需要使用到的,它的值是JVM指令的操作码的指针。returnAddress类型不是简单意义上的数值,不属于任何一种基本类型,并且它的值是不能被运行中的程序所修改的。
Java虚拟机的引用类型被统称为“引用(reference)”,有三种引用类型:类类型、接口类型、以及数组类型,它们的值都是对动态创建对象的引用。类类型的值是对类实例的引用;数组类型的值是对数组对象的引用,在Java虚拟机中,数组是个真正的对象;而接口类型的值,则是对实现了该接口的某个类实例的引用。还有一种特殊的引用值是null,它表示该引用变量没有引用任何对象。
java中参数的传递有两种,分别是按值传递和按引用传递。按值传递不必多说,下面就说一下按引用传递。
“当一个对象被当作参数传递到一个方法”,这就是所谓的按引用传递。
public class User { private String name;public String getName() {return name;
}public void setName(String name) {this.name = name;
}
}public class Test { public void set(User user){
user.setName("hello world");
} public static void main(String[] args) {
Test test = new Test();
User user = new User();
test.set(user);
System.out.println(user.getName());
}
}上面代码的输出结果是“hello world”,这不必多说,那如果将set方法改为如下,结果会是多少呢?
public void set(User user){
user.setName("hello world");
user = new User();
user.setName("change");
}答案依然是“hello world”,下面就让我们来分析一下如上代码。
首先
User user = new User();
是在堆中创建了一个对象,并在栈中创建了一个引用,此引用指向该对象,如下图:

test.set(user);
是将引用user作为参数传递到set方法,注意:这里传递的并不是引用本身,而是一个引用的拷贝。也就是说这时有两个引用(引用和引用的拷贝)同时指向堆中的对象,如下图:

user.setName("hello world");在set()方法中,“user引用的拷贝”操作堆中的User对象,给name属性设置字符串"hello world"。如下图:

user = new User();
在set()方法中,又创建了一个User对象,并将“user引用的拷贝”指向这个在堆中新创建的对象,如下图:

user.setName("change");在set()方法中,“user引用的拷贝”操作的是堆中新创建的User对象。

set()方法执行完毕,目光再回到mian()方法
System.out.println(user.getName());
因为之前,"user引用的拷贝"已经将堆中的User对象的name属性设置为了"hello world",所以当main()方法中的user调用getName()时,打印的结果就是"hello world"。如下图:

In der virtuellen JAVA-Maschine wird der Teil, der für das Suchen und Laden von Typen verantwortlich ist, als Klassenlade-Subsystem bezeichnet.
Die virtuelle JAVA-Maschine verfügt über zwei Klassenlader: den Startklassenlader und den benutzerdefinierten Klassenlader. Ersteres ist Teil der JAVA-Virtual-Machine-Implementierung und Letzteres ist Teil des Java-Programms. Von verschiedenen Klassenladern geladene Klassen werden in unterschiedlichen Namespaces innerhalb der virtuellen Maschine platziert.
Das Klassenlader-Subsystem umfasst mehrere andere Komponenten der Java Virtual Machine sowie mehrere Klassen aus der java.lang-Bibliothek. Ein benutzerdefinierter Klassenlader ist beispielsweise ein gewöhnliches Java-Objekt und seine Klasse muss von der Klasse java.lang.ClassLoader abgeleitet sein. Die in ClassLoader definierten Methoden stellen eine Schnittstelle für Programme bereit, um auf den Klassenlademechanismus zuzugreifen. Darüber hinaus erstellt die virtuelle JAVA-Maschine für jeden geladenen Typ eine Instanz der Klasse java.lang.Class, um den Typ darzustellen. Wie alle anderen Objekte werden benutzerdefinierte Klassenlader und Instanzen der Class-Klasse im Heap-Bereich im Speicher abgelegt, und die geladenen Typinformationen befinden sich im Methodenbereich.
Zusätzlich zum Auffinden und Importieren binärer Klassendateien muss das Klassenlade-Subsystem auch dafür verantwortlich sein, die Richtigkeit der importierten Klasse zu überprüfen, Speicher für Klassenvariablen zuzuweisen und zu initialisieren und bei der Auflösung von Symbolverweisen zu helfen. Diese Aktionen müssen unbedingt in der folgenden Reihenfolge ausgeführt werden:
● Überprüfung Stellen Sie sicher, dass der importierte Typ korrekt ist.
● Vorbereitung Reservieren Sie Speicher für Klassenvariablen und initialisieren Sie sie auf Standardwerte.
● ParsingKonvertieren Sie die Symbolreferenz im Typ in eine direkte Referenz.
Jede JAVA-Virtual-Machine-Implementierung muss über einen Startklassenlader verfügen, der weiß, wie vertrauenswürdige Klassen geladen werden.
Jeder Klassenlader verfügt über einen eigenen Namensraum, der die von ihm geladenen Typen verwaltet. Ein Java-Programm kann also mehrere Typen mit demselben vollqualifizierten Namen mehrmals laden. Der vollständig qualifizierte Name eines solchen Typs reicht nicht aus, um die Eindeutigkeit innerhalb einer Java Virtual Machine zu bestimmen. Wenn daher mehrere Klassenlader einen Typ mit demselben Namen laden, muss zur eindeutigen Identifizierung des Typs der Klassenlader-ID, die den Typ lädt (die den Namespace angibt, in dem er sich befindet), der Typname vorangestellt werden.
In der Java Virtual Machine werden Informationen über den geladenen Typ in einem Speicher gespeichert, der logisch als Methodenbereich bezeichnet wird. Wenn die virtuelle Maschine einen bestimmten Typ lädt, verwendet sie den Klassenlader, um die entsprechende Klassendatei zu finden, liest dann die Klassendatei – einen linearen binären Datenstrom – und überträgt ihn dann an die virtuelle Maschine. Anschließend extrahiert die virtuelle Maschine den Typ Informationen und speichern Sie diese Informationen im Methodenbereich. Klassenvariablen (statische Variablen) dieses Typs werden ebenfalls im Methodenbereich gespeichert.
Wie die virtuelle JAVA-Maschine Typinformationen intern speichert, wird vom Designer der jeweiligen Implementierung bestimmt.
Wenn die virtuelle Maschine ein Java-Programm ausführt, sucht sie nach den im Methodenbereich gespeicherten Typinformationen und verwendet diese. Da sich alle Threads den Methodenbereich teilen, muss ihr Zugriff auf Methodenbereichsdaten threadsicher gestaltet sein. Angenommen, zwei Threads versuchen gleichzeitig, auf eine Klasse namens Lava zuzugreifen, und diese Klasse wurde nicht in die virtuelle Maschine geladen. Dann sollte sie zu diesem Zeitpunkt nur von einem Thread geladen werden, während der andere Thread nur warten kann . .
Für jeden geladenen Typ speichert die virtuelle Maschine die folgenden Typinformationen im Methodenbereich:
● Der vollständig qualifizierte Name dieses Typs
● Der vollständig qualifizierte Name der direkten Superklasse dieses Typs (es sei denn, der Typ ist java.lang.Object, der keine Superklasse hat)
● Ist dieser Typ eine Klasse? Typ oder Schnittstellentyp
● Der Zugriffsmodifikator dieses Typs (eine Teilmenge von public, abstract oder final)
● Der vollständige Satz einer beliebigen direkten Superschnittstelle Eine geordnete Liste qualifizierter Namen
Zusätzlich zu den oben aufgeführten grundlegenden Typinformationen muss die virtuelle Maschine auch die folgenden Informationen für jeden geladenen Typ speichern:
● Der konstante Pool dieses Typs
●Feldinformationen
●Methodeninformationen
●Zusätzlich zu Konstanten Alle Klassenvariablen (statisch) außer 🎜>
Konstantenpool Die virtuelle Maschine muss für jeden geladenen Typ einen Konstantenpool verwalten. Ein Konstantenpool ist eine geordnete Sammlung von Konstanten, die vom Typ verwendet werden, einschließlich direkter Konstanten und symbolischer Verweise auf andere Typen, Felder und Methoden. Auf Datenelemente in einem Pool wird wie auf ein Array über einen Index zugegriffen. Da der Konstantenpool symbolische Verweise auf alle vom entsprechenden Typ verwendeten Typen, Felder und Methoden speichert, spielt er eine zentrale Rolle bei der dynamischen Verknüpfung von Java-Programmen.
对于类型中声明的每一个字段。方法区中必须保存下面的信息。除此之外,这些字段在类或者接口中的声明顺序也必须保存。
○ 字段名
○ 字段的类型
○ 字段的修饰符(public、private、protected、static、final、volatile、transient的某个子集)
对于类型中声明的每一个方法,方法区中必须保存下面的信息。和字段一样,这些方法在类或者接口中的声明顺序也必须保存。
○ 方法名
○ 方法的返回类型(或void)
○ 方法参数的数量和类型(按声明顺序)
○ 方法的修饰符(public、private、protected、static、final、synchronized、native、abstract的某个子集)
除了上面清单中列出的条目之外,如果某个方法不是抽象的和本地的,它还必须保存下列信息:
○ 方法的字节码(bytecodes)
○ 操作数栈和该方法的栈帧中的局部变量区的大小
○ 异常表
类变量是由所有类实例共享的,但是即使没有任何类实例,它也可以被访问。这些变量只与类有关——而非类的实例,因此它们总是作为类型信息的一部分而存储在方法区。除了在类中声明的编译时常量外,虚拟机在使用某个类之前,必须在方法区中为这些类变量分配空间。
而编译时常量(就是那些用final声明以及用编译时已知的值初始化的类变量)则和一般的类变量处理方式不同,每个使用编译时常量的类型都会复制它的所有常量到自己的常量池中,或嵌入到它的字节码流中。作为常量池或字节码流的一部分,编译时常量保存在方法区中——就和一般的类变量一样。但是当一般的类变量作为声明它们的类型的一部分数据面保存的时候,编译时常量作为使用它们的类型的一部分而保存。
每个类型被装载的时候,虚拟机必须跟踪它是由启动类装载器还是由用户自定义类装载器装载的。如果是用户自定义类装载器装载的,那么虚拟机必须在类型信息中存储对该装载器的引用。这是作为方法表中的类型数据的一部分保存的。
虚拟机会在动态连接期间使用这个信息。当某个类型引用另一个类型的时候,虚拟机会请求装载发起引用类型的类装载器来装载被引用的类型。这个动态连接的过程,对于虚拟机分离命名空间的方式也是至关重要的。为了能够正确地执行动态连接以及维护多个命名空间,虚拟机需要在方法表中得知每个类都是由哪个类装载器装载的。
对于每一个被装载的类型(不管是类还是接口),虚拟机都会相应地为它创建一个java.lang.Class类的实例,而且虚拟机还必须以某种方式把这个实例和存储在方法区中的类型数据关联起来。
在Java程序中,你可以得到并使用指向Class对象的引用。Class类中的一个静态方法可以让用户得到任何已装载的类的Class实例的引用。
public static Class<?> forName(String className)
比如,如果调用forName("java.lang.Object"),那么将得到一个代表java.lang.Object的Class对象的引用。可以使用forName()来得到代表任何包中任何类型的Class对象的引用,只要这个类型可以被(或者已经被)装载到当前命名空间中。如果虚拟机无法把请求的类型装载到当前命名空间,那么会抛出ClassNotFoundException异常。
另一个得到Class对象引用的方法是,可以调用任何对象引用的getClass()方法。这个方法被来自Object类本身的所有对象继承:
public final native Class<?> getClass();
比如,如果你有一个到java.lang.Integer类的对象的引用,那么你只需简单地调用Integer对象引用的getClass()方法,就可以得到表示java.lang.Integer类的Class对象。
为了展示虚拟机如何使用方法区中的信息,下面来举例说明:
class Lava {private int speed = 5;void flow(){
}
}public class Volcano { public static void main(String[] args){
Lava lava = new Lava();
lava.flow();
}
}不同的虚拟机实现可能会用完全不同的方法来操作,下面描述的只是其中一种可能——但并不是仅有的一种。
Um ein Volcano-Programm auszuführen, müssen Sie der virtuellen Maschine zunächst auf eine „implementierungsabhängige“ Weise den Namen „Volcano“ mitteilen. Danach findet und liest die virtuelle Maschine die entsprechende Klassendatei „Volcano.class“, extrahiert dann die Typinformationen aus den Binärdaten in der importierten Klassendatei und legt sie im Methodenbereich ab. Durch Ausführen des im Methodenbereich gespeicherten Bytecodes beginnt die virtuelle Maschine mit der Ausführung der main()-Methode. Während der Ausführung speichert sie immer den Konstantenpool (eine Datenstruktur im Methodenbereich), der auf die aktuelle Klasse (Volcano-Klasse) verweist. Zeiger.
Hinweis: Wenn die virtuelle Maschine mit der Ausführung des Bytecodes der main()-Methode in der Volcano-Klasse beginnt, wird dies nicht der Fall sein, obwohl die Lava-Klasse noch nicht geladen wurde, wie bei den meisten (vielleicht allen) Implementierungen virtueller Maschinen Warten Sie, bis alle im Programm verwendeten Klassen geladen sind, bevor Sie es ausführen. Im Gegenteil, die entsprechende Klasse wird nur bei Bedarf geladen.
Die erste Anweisung von main() weist die virtuelle Maschine an, genügend Speicher für die im ersten Element des Konstantenpools aufgeführte Klasse zuzuweisen. Die virtuelle Maschine verwendet also den Zeiger auf den Volcano-Konstantenpool, um das erste Element zu finden, stellt fest, dass es sich um einen symbolischen Verweis auf die Lava-Klasse handelt, und überprüft dann den Methodenbereich, um festzustellen, ob die Lava-Klasse geladen wurde.
Diese symbolische Referenz ist einfach eine Zeichenfolge, die den vollständig qualifizierten Namen „Lava“ der Klasse Lava angibt. Damit die virtuelle Maschine so schnell wie möglich eine Klasse anhand eines Namens finden kann, sollte der Designer der virtuellen Maschine die besten Datenstrukturen und Algorithmen auswählen.
Wenn die virtuelle Maschine feststellt, dass die Klasse „Lava“ nicht geladen wurde, beginnt sie mit der Suche und dem Laden der Datei „Lava.class“ und fügt die aus den gelesenen Binärdaten extrahierten Typinformationen in ein den Methodenbereich.
Unmittelbar danach ersetzt die virtuelle Maschine das erste Element des Konstantenpools (d. h. die Zeichenfolge „Lava“) durch einen Zeiger, der direkt auf die Lava-Klassendaten im Methodenbereich zeigt. Dieser Zeiger kann verwendet werden um in Zukunft schnell auf Lava zugreifen zu können. Dieser Ersetzungsprozess wird als Auflösung des Konstantenpools bezeichnet und ersetzt Symbolreferenzen im Konstantenpool durch direkte Referenzen.
Schließlich ist die virtuelle Maschine bereit, Speicher für ein neues Lava-Objekt zuzuweisen. An dieser Stelle benötigt es erneut die Informationen im Methodenbereich. Erinnern Sie sich an den Zeiger, den Sie gerade in das erste Element des Konstantenpools der Volcano-Klasse gesetzt haben? Jetzt greift die virtuelle Maschine damit auf Lava-Typinformationen zu und ermittelt die darin aufgezeichneten Informationen: wie viel Heap-Speicherplatz ein Lava-Objekt zuweisen muss.
Die virtuelle JAVA-Maschine kann anhand der Typinformationen der Speicher- und Methodenbereiche immer bestimmen, wie viel Speicher ein Objekt benötigt. Wenn die virtuelle JAVA-Maschine die Größe eines Lava-Objekts bestimmt, weist sie einen so großen Speicherplatz zu den Heap und initialisieren Sie die variable Geschwindigkeit dieser Objektinstanz auf den Standardanfangswert 0.
Wenn die Referenz des neu generierten Lava-Objekts auf den Stapel verschoben wird, ist auch die erste Anweisung der main()-Methode abgeschlossen. Die folgenden Anweisungen rufen über diese Referenz den Java-Code auf (der die Geschwindigkeitsvariable auf den korrekten Anfangswert 5 initialisiert). Eine andere Anweisung verwendet diese Referenz, um die flow()-Methode der Lava-Objektreferenz aufzurufen.
Alle von einem Java-Programm zur Laufzeit erstellten Klasseninstanzen oder Arrays werden im selben Heap abgelegt. In einer JAVA-VM-Instanz gibt es nur einen Heap-Speicherplatz, sodass alle Threads diesen Heap gemeinsam nutzen. Und da ein Java-Programm eine JAVA-Virtual-Machine-Instanz belegt, verfügt jedes Java-Programm über seinen eigenen Heap-Speicherplatz – sie stören sich nicht gegenseitig. Allerdings teilen sich mehrere Threads desselben Java-Programms denselben Heap-Speicherplatz. In diesem Fall muss das Synchronisierungsproblem des Multithread-Zugriffs auf Objekte (Heap-Daten) berücksichtigt werden.
Die virtuelle JAVA-Maschine verfügt über eine Anweisung zum Zuweisen neuer Objekte im Heap, es gibt jedoch keine Anweisung zum Freigeben von Speicher, genauso wie Sie ein Objekt nicht explizit über den Java-Codebereich freigeben können. Die virtuelle Maschine selbst ist dafür verantwortlich, zu entscheiden, wie und wann Speicher freigegeben wird, der von Objekten belegt wird, auf die von laufenden Programmen nicht mehr verwiesen wird. Normalerweise überlässt die virtuelle Maschine diese Aufgabe dem Garbage Collector.
In Java sind Arrays reale Objekte. Arrays werden wie andere Objekte immer im Heap gespeichert. Ebenso verfügen Arrays über eine Klasseninstanz, die ihrer Klasse zugeordnet ist, und alle Arrays mit denselben Abmessungen und demselben Typ sind Instanzen derselben Klasse, unabhängig von der Länge des Arrays (der Länge jeder Dimension eines mehrdimensionalen Arrays). Beispielsweise haben ein Array mit 3 Ganzzahlen und ein Array mit 300 Ganzzahlen dieselbe Klasse. Die Länge des Arrays ist nur für die Instanzdaten relevant.
Der Name der Array-Klasse besteht aus zwei Teilen: Jede Dimension wird durch eine eckige Klammer „[“ dargestellt und ein Zeichen oder eine Zeichenfolge wird zur Darstellung des Elementtyps verwendet. Beispielsweise lautet der Klassenname eines eindimensionalen Arrays, dessen Elementtyp eine Ganzzahl ist, „[I“, der Klassenname eines dreidimensionalen Arrays, dessen Elementtyp ein Byte ist, „[[[B““ und der Klassenname von Ein zweidimensionales Array, dessen Elementtyp Object ist, ist „[[Ljava/lang/Object“.
Mehrdimensionale Arrays werden als Arrays von Arrays dargestellt. Beispielsweise wird ein zweidimensionales Array vom Typ int als eindimensionales Array dargestellt, wobei jedes Element eine Referenz auf ein eindimensionales int-Array ist, wie unten gezeigt:
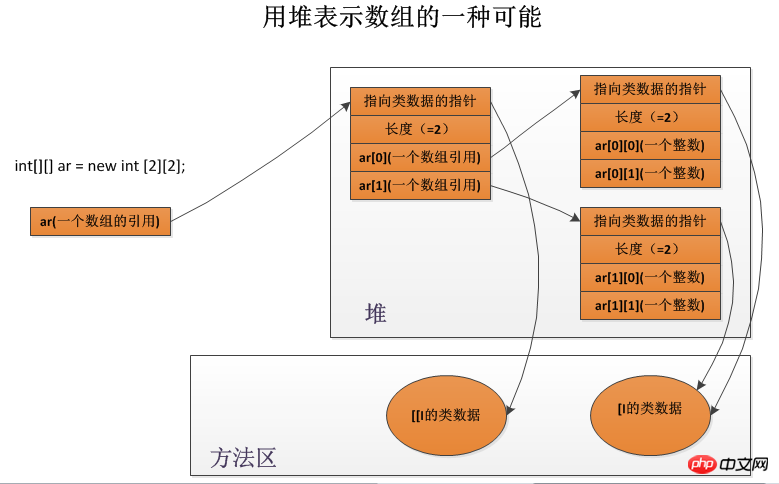
Jedes Array-Objekt im Heap muss außerdem die Länge des Arrays, die Array-Daten und einen Verweis auf die arrayähnlichen Daten speichern. Die virtuelle Maschine muss in der Lage sein, die Länge des Arrays durch einen Verweis auf ein Array-Objekt zu ermitteln, über Indizes auf seine Elemente zuzugreifen (wobei die Array-Grenzen überprüft werden müssen, um festzustellen, ob sie außerhalb der Grenzen liegen), und von ihr deklarierte Methoden aufzurufen direktes Oberklassenobjekt aller Arrays usw.
Für ein laufendes Java-Programm verfügt jeder Thread darin über ein eigenes PC-Register (Programmzähler), das beim Starten des Threads erstellt wird. Die Größe des PC-Registers beträgt eins Wort, sodass es entweder einen lokalen Zeiger oder eine returnAddress enthalten kann. Wenn ein Thread eine Java-Methode ausführt, ist der Inhalt des PC-Registers immer die „Adresse“ der nächsten auszuführenden Anweisung. Die „Adresse“ kann hier ein lokaler Zeiger oder relativ zur Methode in der Methode sein Bytecode. Der Offset der Startanweisung. Wenn der Thread eine native Methode ausführt, ist der Wert des PC-Registers zu diesem Zeitpunkt „undefiniert“.
Immer wenn ein neuer Thread gestartet wird, weist die Java Virtual Machine ihm einen Java-Stack zu. Der Java-Stack speichert den Ausführungsstatus des Threads in Frames. Die virtuelle Maschine führt nur zwei Vorgänge direkt auf dem Java-Stack aus: Pushen und Einfügen von Frames.
Die von einem Thread ausgeführte Methode wird als aktuelle Methode des Threads bezeichnet. Der von der aktuellen Methode verwendete Stapelrahmen wird als aktueller Rahmen bezeichnet. Die Klasse, zu der die aktuelle Methode gehört, wird als aktuelle Klasse bezeichnet. Der Konstantenpool der aktuellen Klasse heißt Der aktuelle Konstantenpool. Wenn ein Thread eine Methode ausführt, verfolgt er die aktuelle Klasse und den aktuellen Konstantenpool. Wenn die virtuelle Maschine außerdem auf eine In-Stack-Operationsanweisung trifft, führt sie die Operation für die Daten im aktuellen Frame aus.
Immer wenn ein Thread eine Java-Methode aufruft, schiebt die virtuelle Maschine einen neuen Frame in den Java-Stack des Threads. Und dieser neue Rahmen wird natürlich zum aktuellen Rahmen. Bei der Ausführung dieser Methode wird dieser Rahmen zum Speichern von Parametern, lokalen Variablen, Zwischenergebnissen von Operationen und anderen Daten verwendet.
Java-Methoden können auf zwei Arten ausgeführt werden. Einer wird durch Return zurückgegeben, was als normale Rückgabe bezeichnet wird; der andere wird durch das Auslösen einer Ausnahme abnormal beendet. Unabhängig davon, welche Methode zurückgegeben wird, holt die virtuelle Maschine den aktuellen Frame aus dem Java-Stack und gibt ihn frei, sodass der Frame der vorherigen Methode zum aktuellen Frame wird.
Alle Daten im Java-Frame sind für diesen Thread privat. Kein Thread kann auf die Stapeldaten eines anderen Threads zugreifen, daher müssen wir die Synchronisierung des Stapeldatenzugriffs in Situationen mit mehreren Threads nicht berücksichtigen. Wenn ein Thread eine Methode aufruft, werden die lokalen Variablen der Methode im Java-Stack-Frame des aufrufenden Threads gespeichert. Auf diese lokalen Variablen kann immer nur ein Thread zugreifen, nämlich der Thread, der die Methode aufruft.
Alle zuvor erwähnten Laufzeitdatenbereiche sind in der Java Virtual Machine-Spezifikation klar definiert. Darüber hinaus kann es für ein laufendes Java-Programm auch einige damit verbundene Datenbereiche verwenden native Methoden. Wenn ein Thread eine native Methode aufruft, betritt er eine neue Welt, die nicht mehr durch die virtuelle Maschine eingeschränkt wird. Eine native Methode kann über die native Methodenschnittstelle auf den Laufzeitdatenbereich der virtuellen Maschine zugreifen, aber darüber hinaus kann sie tun, was sie will.
Native Methoden sind im Wesentlichen von der Implementierung abhängig, und Designer von Implementierungen virtueller Maschinen können frei entscheiden, welchen Mechanismus sie verwenden, um Java-Programmen den Aufruf nativer Methoden zu ermöglichen.
Jede native Methodenschnittstelle verwendet eine Art nativen Methodenstapel. Wenn ein Thread eine Java-Methode aufruft, erstellt die virtuelle Maschine einen neuen Stapelrahmen und schiebt ihn auf den Java-Stack. Wenn sie jedoch eine lokale Methode aufruft, behält die virtuelle Maschine den Java-Stack unverändert und schiebt keinen neuen Frame mehr in den Java-Stack des Threads. Die virtuelle Maschine stellt einfach eine dynamische Verbindung her und ruft die angegebene lokale Methode direkt auf.
Wenn die von einer virtuellen Maschine implementierte lokale Methodenschnittstelle das C-Verbindungsmodell verwendet, ist ihr lokaler Methodenstapel der C-Stack. Wenn ein C-Programm eine C-Funktion aufruft, werden seine Stapeloperationen bestimmt. Die an die Funktion übergebenen Parameter werden in einer bestimmten Reihenfolge auf den Stapel gelegt und ihr Rückgabewert wird ebenfalls auf eine bestimmte Weise an den Aufrufer zurückgegeben. Dies ist wiederum das Verhalten nativer Methodenstapel in Implementierungen virtueller Maschinen.
Es ist sehr wahrscheinlich, dass die native Methodenschnittstelle eine Java-Methode in der Java Virtual Machine zurückrufen muss. In diesem Fall speichert der Thread den Status des lokalen Methodenstapels und gibt einen anderen Java-Stack ein.
Die folgende Abbildung zeigt ein Szenario, in dem, wenn ein Thread eine lokale Methode aufruft, die lokale Methode eine andere Java-Methode in der virtuellen Maschine zurückruft. Dieses Bild zeigt eine Panoramaansicht des Threads, der in der virtuellen JAVA-Maschine ausgeführt wird. Ein Thread kann während seines gesamten Lebenszyklus Java-Methoden ausführen und seinen Java-Stack betreiben oder ohne Hindernisse zwischen dem Java-Stack und dem nativen Methoden-Stack wechseln. 
Der Thread rief zuerst zwei Java-Methoden auf und die zweite Java-Methode rief eine native Methode auf, was dazu führte, dass die virtuelle Maschine einen nativen Methodenstapel verwendete. Angenommen, es handelt sich um einen C-Sprachstapel mit zwei C-Funktionen dazwischen. Die erste C-Funktion wird von der zweiten Java-Methode als native Methode aufgerufen, und diese C-Funktion ruft die zweite C-Funktion auf. Dann ruft die zweite C-Funktion über die lokale Methodenschnittstelle eine Java-Methode (die dritte Java-Methode) zurück, und schließlich ruft diese Java-Methode eine Java-Methode auf (sie wird zur aktuellen Methode im Diagramm).
Achtung Studierende, die Java lernen! ! !
Wenn Sie während des Lernprozesses auf Probleme stoßen oder Lernressourcen erhalten möchten, können Sie gerne der Java-Lernaustauschgruppe beitreten: 299541275 Lassen Sie uns gemeinsam Java lernen !
Das obige ist der detaillierte Inhalt vonDetaillierte Einführung in die Java Virtual Machine-Architektur. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



