
 Java
javaLernprogramm
Einführung in den Aufgabenplanungstopologiegraphen des gerichteten Graphen
Java
javaLernprogramm
Einführung in den Aufgabenplanungstopologiegraphen des gerichteten Graphen
Einführung in den Aufgabenplanungstopologiegraphen des gerichteten Graphen

1. Datentyp eines gerichteten Graphen
Verwenden Sie Bag, um einen gerichteten Graphen darzustellen, wobei die Kante v->w als Scheitelpunkt dargestellt wird v Die entsprechende verknüpfte Adjazenzliste enthält einen w-Scheitelpunkt, hier erscheint jede Kante nur einmal. Der Datenstrukturtyp des gerichteten Diagramms ist wie folgt:
public class Digraph {private final int V;private int E;private Bag<Integer>[] adj;public Digraph(int V) {this.V=V;this.E=0;
adj=(Bag<Integer>[])new Bag[V];for(int v=0;v<V;v++) {
adj[v]=new Bag<Integer>();
}
}public int V() {return V;
}public int E() {return E;
}//添加一条边v->w,由于是有向图只要添加一条边就可以了public void addEdge(int v,int w) {
adj[v].add(w);
E++;
}public Iterable<Integer> adj(int v) {return adj[v];
}//返回当前图的一个反向的图public Digraph reverse() {
Digraph R=new Digraph(V);for(int v=0;v<V;v++) {for(int w:adj(v)) {
R.addEdge(w, v);
}
}return R;
}
}
2. Erreichbarkeit im gerichteten Graphen
Konnektivität des ungerichteten Graphen Ähnlich wie , Tiefen- Die erste Suche kann verwendet werden, um das
Einzelpunkt-Erreichbarkeitsproblem in einem gerichteten Graphen zu lösen: das heißt: gegeben ein gerichteter Graph Graph und ein Startpunkt s, Beantworten Sie die Frage, ob es einen gerichteten Pfad von s zu einem gegebenen Scheitelpunkt v gibt.
Mehrpunkt-Erreichbarkeitsproblem: gegeben Gegeben ein gerichteter Graph und eine Menge Beantworten Sie die Frage, ob es einen gerichteten Pfad von jedem Eckpunkt in der Menge zu einem gegebenen Eckpunkt v gibt?
public class DirectedDFS {private boolean[] marked;//从G中找出所有s可达的点public DirectedDFS(Digraph G,int s) {
marked=new boolean[G.V()];
dfs(G,s);
}//G中找出一系列点可达的点public DirectedDFS(Digraph G,Iterable<Integer> sources) {
marked=new boolean[G.V()];for(int s:sources) {if(!marked[s]) dfs(G,s);
}
}//深度优先搜素判断.private void dfs(Digraph G, int v) {
marked[v]=true;for(int w:G.adj(v)) {if(!marked[w]) dfs(G,w);
}
}//v是可达的吗public boolean marked(int v) {return marked[v];
}
}Eine wichtige Anwendung des Mehrpunkt-Erreichbarkeitsproblems findet sich in typischen Speicherverwaltungssystemen, einschließlich vieler Java-Implementierungen. In einem gerichteten Graphen stellt ein Scheitelpunkt ein Objekt dar und eine Kante stellt eine Referenz von einem Objekt zu einem anderen dar.
Dieses Modell stellt die Speichernutzung laufender Java-Programme gut dar. Es gibt bestimmte Objekte, auf die jederzeit während der Programmausführung direkt zugegriffen werden kann, und alle Objekte, auf die über diese Objekte nicht zugegriffen werden kann, sollten recycelt werden, um
Speicher freizugeben. Es führt regelmäßig einen gerichteten Graph-Erreichbarkeitsalgorithmus ähnlich wie DirectedDFS aus, um alle zugänglichen Objekte zu markieren.
3. Die Pfadfindung in gerichteten Graphen
ähnelt häufigen Problemen in gerichteten Graphen:
Einzelpunkt-gerichteter Pfad. Antworten Sie bei einem gegebenen gerichteten Graphen und einem Startpunkt: „Gibt es einen gerichteten Pfad von s zum angegebenen Zielscheitelpunkt v? Wenn ja, finden Sie diesen Pfad“
Einzelpunktkürzester gerichteter Weg. Angesichts eines gerichteten Graphen und eines Startpunkts antworten Sie: „Gibt es einen gerichteten Pfad von s zum angegebenen Zielscheitelpunkt v? Wenn ja, finden Sie den kürzesten (der die geringste Anzahl von Kanten enthält)“
4. Planungsproblem – topologische Sortierung
4.1 Finden gerichteter Ringe
Wenn es in einem Problem mit Prioritätseinschränkungen einen gerichteten Zyklus gibt, dann muss das Problem unlösbar sein. Daher ist eine gezielte Ringerkennung erforderlich.
Der folgende Code kann verwendet werden, um zu erkennen, ob ein bestimmter gerichteter Graph einen gerichteten Zyklus enthält. Wenn ja, werden alle Scheitelpunkte auf dem Zyklus entsprechend der Richtung des Pfads zurückgegeben.
Beim Ausführen von dfs wird nach dem gerichteten Pfad vom Startpunkt nach v gesucht. Das onStack-Array markiert alle Scheitelpunkte auf dem Stapel des rekursiven Aufrufs und das EdgeTo-Array wird ebenfalls hinzugefügt . Nachdem Sie alle Eckpunkte im Ring gefunden haben, wenn Sie sich auf den Ring zubewegen, sortieren Sie bei einem gegebenen gerichteten Diagramm alle Eckpunkte so, dass alle gerichteten Kanten von den Elementen nach vorne zeigen Wenn die Elemente im Hintergrund vorhanden sind, kann die topologische Sortierung nicht abgeschlossen werden Hier gibt es drei Anordnungen von Scheitelpunkten. Reihenfolge:
/**
* 有向图G是否含有有向环
* 获取有向环中的所有顶点
* @author Administrator
* */public class DirectedCycle {private boolean[] marked; private int[] edgeTo;private Stack<Integer> cycle; //有向环中的所有顶点private boolean[] onStack; //递归调用的栈上的所有顶点public DirectedCycle(Digraph G) {
edgeTo=new int[G.V()];
onStack=new boolean[G.V()];
marked=new boolean[G.V()];for(int v=0;v<G.V();v++) {if(!marked[v]) dfs(G,v);
}
}/**
* 该算法的关键步骤在于onStack数组的运用.
* onStack数组标记的是当前遍历的点.如果对于一个点指向的所有点中的某个点
* onstack[v]=true.代表该点正在被遍历也就是说
* 该点存在一条路径,指向这个点.而这个点现在又可以指向该点,
* 即存在环的结构~
* @param G
* @param v */ private void dfs(Digraph G, int v) {
onStack[v]=true;
marked[v]=true;for(int w:G.adj(v)) {if(this.hasCycle()) return;else if(!marked[w]) {
edgeTo[w]=v;
dfs(G,w);
}else if(onStack[w]) {
cycle=new Stack<Integer>();for(int x=v;x!=w;x=edgeTo[x])
cycle.push(x);
cycle.push(w);
cycle.push(v);
}
}//dfs方法结束,对于该点的递归调用结束.该点指向的所有点已经遍历完毕onStack[v]=false;
}private boolean hasCycle() {return cycle!=null;
}public Iterable<Integer> cycle() {return cycle;
}
}2. Nachbestellung: Fügen Sie die Vertices nach dem rekursiven Aufruf hinzu. Zur Warteschlange hinzufügen 3. Umgekehrte Reihenfolge: Schieben Sie die Vertices nach dem rekursiven Aufruf auf den Stapel
Spezifische Vorgänge finden Sie im folgenden Code:
遍历的顺序取决于这个数据结构的性质以及是在递归调用之前还是之后进行保存。
前序:在递归调用之前将顶点加入队列。
后序:在递归调用之后将顶点加入队列。
逆后序:在递归调用之后将顶点压入栈。
前序就时dfs()的调用顺序;后序就是顶点遍历完成的顺序;逆后序就是顶点遍历完成顺序的逆。
拓补排序的实现依赖于上面的API,实际上拓补排序即为所有顶点的逆后序排列
拓补排序的代码如下:
public class Topological {private Iterable<Integer> order; //顶点的拓补排序public Topological(Digraph G) {
DirectedCycle cyclefinder=new DirectedCycle(G);if(!cyclefinder.hasCycle()) {//只有无环才能进行拓补排序DepthFirstOrder dfs=new DepthFirstOrder(G);
order=dfs.reversePost();
}
}public Iterable<Integer> order() {return order;
}public boolean isDAG() {return order!=null;
}
}
5.有向图的强连通性
定义:如果两个顶点v和w是互相可达的,则称它们为强连通的.也就是说既存在一条从v到w的有向路径也存在一条从w到v的有向路径.
如果一幅有向图中的任意两个顶点都是强连通的,则称这副有向图也是强连通的.任意顶点和自己都是强连通的.
下面的代码采用如下步骤来计算强连通分量以及两个点是否是强连通的:
1.在给定的有向图中,使用DepthFirsetOrder来计算它的反向图GR的逆后序排列
2.按照第一步计算得到的顺序采用深度优先搜索来访问所有未被标记的点
3.在构造函数中,所有在同一个递归dfs()调用中被访问到的顶点都是在同一个强连通分量中.
下面的代码实现遵循了上面的思路:
/**
* 该算法实现的关键:
* 使用深度优先搜索查找给定有向图的反向图GR.根据由此得到的所有顶点的逆后序
* 再次用深度优先搜索处理有向图G.其构造函数的每一次递归调用所标记的顶点都在
* 同一个强连通分量中.
* 解决问题:
* 判断两个点是否是强连通的
* 判断总共有多少个连通分量
* @author Administrator
* */public class KosarajuSCC {private boolean[] marked;//已经访问过的顶点private int[] id; //强连通分量的标识符private int count; //强联通分量的数量public KosarajuSCC(Digraph G) {
marked=new boolean[G.V()];
id=new int[G.V()];
DepthFirstOrder order=new DepthFirstOrder(G.reverse());for(int s:order.reversePost()) {if(!marked[s]) {
dfs(G,s);
count++;
}
}
}private void dfs(Digraph G, int v) {
marked[v]=true;
id[v]=count;for(int w:G.adj(v)) {if(!marked[w]) {
dfs(G,w);
}
}
}public boolean stronglyConnected(int v,int w) {return id[v]==id[w];
}public int id(int v) {return id[v];
}public int count() {return count;
}
}
Das obige ist der detaillierte Inhalt vonEinführung in den Aufgabenplanungstopologiegraphen des gerichteten Graphen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1386
1386
 52
52

 So schließen Sie die Horrorkorridor-Mission in Goat Simulator 3 ab
Feb 25, 2024 pm 03:40 PM
So schließen Sie die Horrorkorridor-Mission in Goat Simulator 3 ab
Feb 25, 2024 pm 03:40 PM
Der Terrorkorridor ist eine Mission in Goat Simulator 3. Wie können Sie die detaillierten Räumungsmethoden und entsprechenden Prozesse meistern und die entsprechenden Herausforderungen dieser Mission meistern? Leitfaden zum Erlernen verwandter Informationen. Goat Simulator 3 Terror Corridor Guide 1. Zuerst müssen die Spieler zum Silent Hill in der oberen linken Ecke der Karte gehen. 2. Hier sehen Sie ein Haus mit der Aufschrift „RESTSTOP“ auf dem Dach. Um dieses Haus zu betreten, müssen die Spieler die Ziege bedienen. 3. Nachdem wir den Raum betreten haben, gehen wir zunächst geradeaus und biegen dann rechts ab. Hier befindet sich am Ende eine Tür, von hier aus gehen wir direkt hinein. 4. Nach dem Betreten müssen wir auch zuerst vorwärts gehen und dann rechts abbiegen. Wenn wir hier die Tür erreichen, müssen wir umkehren und sie finden.
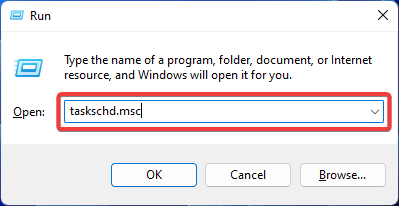 Fix: Fehler „Operator verweigert Anforderung' im Windows-Taskplaner
Aug 01, 2023 pm 08:43 PM
Fix: Fehler „Operator verweigert Anforderung' im Windows-Taskplaner
Aug 01, 2023 pm 08:43 PM
Um Aufgaben zu automatisieren und mehrere Systeme zu verwalten, ist Missionsplanungssoftware ein wertvolles Werkzeug in Ihrem Arsenal, insbesondere als Systemadministrator. Der Windows-Taskplaner erledigt seine Aufgabe perfekt, aber in letzter Zeit berichten viele Leute über Fehler, bei denen der Operator eine Anforderung abgelehnt hat. Dieses Problem besteht in allen Iterationen des Betriebssystems, und obwohl ausführlich darüber berichtet und behandelt wurde, gibt es keine wirksame Lösung. Lesen Sie weiter, um herauszufinden, was für andere Menschen tatsächlich funktionieren könnte! Welche Anfrage im Taskplaner 0x800710e0 wurde vom Bediener oder Administrator abgelehnt? Der Taskplaner ermöglicht die Automatisierung verschiedener Aufgaben und Anwendungen ohne Benutzereingaben. Sie können damit bestimmte Anwendungen planen und organisieren, automatische Benachrichtigungen konfigurieren, bei der Zustellung von Nachrichten helfen und vieles mehr. Es
 So bestehen Sie die Imperial Tomb-Mission im Goat Simulator 3
Mar 11, 2024 pm 01:10 PM
So bestehen Sie die Imperial Tomb-Mission im Goat Simulator 3
Mar 11, 2024 pm 01:10 PM
Goat Simulator 3 ist ein Spiel mit klassischem Simulationsspiel, das es den Spielern ermöglicht, den Spaß einer Gelegenheits-Action-Simulation in vollen Zügen zu genießen. Das Spiel hat auch viele spannende Spezialaufgaben. Unter anderem erfordert die Goat Simulator 3 Imperial Tomb-Aufgabe, dass die Spieler den Glockenturm finden. Einige Spieler sind sich nicht sicher, wie sie die drei Uhren gleichzeitig bedienen sollen. Hier ist die Anleitung zur Tomb of the Tomb-Mission in Goat Simulator 3. Die Anleitung zur Tomb of the Tomb-Mission in Goat Simulator 3 besteht darin, die Glocken zu läuten in Ordnung. Detaillierte Schritterweiterung 1. Zuerst müssen die Spieler die Karte öffnen und zum Wuqiu-Friedhof gehen. 2. Gehen Sie dann hinauf zum Glockenturm. Dort befinden sich drei Glocken. 3. Folgen Sie dann 222312312 in der Reihenfolge vom größten zum kleinsten, um sich mit dem wütenden Klopfen vertraut zu machen. 4. Nachdem Sie das Klopfen abgeschlossen haben, können Sie die Mission abschließen und die Tür öffnen, um das Lichtschwert zu erhalten.
 So führen Sie die Steve-Rettungsmission im Goat Simulator 3 durch
Feb 25, 2024 pm 03:34 PM
So führen Sie die Steve-Rettungsmission im Goat Simulator 3 durch
Feb 25, 2024 pm 03:34 PM
Steve zu retten ist eine einzigartige Aufgabe in Goat Simulator 3. Was genau muss getan werden, um sie abzuschließen? Diese Aufgabe ist relativ einfach, aber wir müssen aufpassen, dass wir die Bedeutung von Steve nicht falsch verstehen Simulator 3-Aufgabenstrategien können Ihnen dabei helfen, verwandte Aufgaben besser zu erledigen. Goat Simulator 3 Rescue Steve Mission Strategie 1. Kommen Sie zuerst zur heißen Quelle in der unteren rechten Ecke der Karte. 2. Nachdem Sie an der heißen Quelle angekommen sind, können Sie die Aufgabe auslösen, Steve zu retten. 3. Beachten Sie, dass es in der heißen Quelle einen Mann gibt, der zwar Steve heißt, aber nicht das Ziel dieser Mission ist. 4. Finden Sie in dieser heißen Quelle einen Fisch namens Steve und bringen Sie ihn an Land, um diese Aufgabe abzuschließen.
 Wo finde ich Douyin-Fangruppenaufgaben? Wird der Douyin-Fanclub an Niveau verlieren?
Mar 07, 2024 pm 05:25 PM
Wo finde ich Douyin-Fangruppenaufgaben? Wird der Douyin-Fanclub an Niveau verlieren?
Mar 07, 2024 pm 05:25 PM
Als eine der derzeit beliebtesten Social-Media-Plattformen hat TikTok eine große Anzahl von Nutzern zur Teilnahme angezogen. Auf Douyin gibt es viele Fangruppenaufgaben, die Benutzer erledigen können, um bestimmte Belohnungen und Vorteile zu erhalten. Wo finde ich die Aufgaben des Douyin-Fanclubs? 1. Wo kann ich die Aufgaben des Douyin-Fanclubs einsehen? Um die Aufgaben einer Douyin-Fangruppe zu finden, müssen Sie die persönliche Homepage von Douyin besuchen. Auf der Startseite sehen Sie eine Option namens „Fanclub“. Klicken Sie auf diese Option und Sie können die Fangruppen, denen Sie beigetreten sind, und die damit verbundenen Aufgaben durchsuchen. In der Spalte „Fanclub-Aufgaben“ sehen Sie verschiedene Arten von Aufgaben, wie z. B. Likes, Kommentare, Teilen, Weiterleiten usw. Für jede Aufgabe gibt es entsprechende Belohnungen und Anforderungen. Im Allgemeinen erhalten Sie nach Abschluss der Aufgabe eine bestimmte Menge an Goldmünzen oder Erfahrungspunkten.
 Timing-Analyse Pentagon-Krieger! Die Tsinghua-Universität schlägt TimesNet vor: führend in der Vorhersage, Füllung, Klassifizierung und Erkennung
Apr 11, 2023 pm 07:34 PM
Timing-Analyse Pentagon-Krieger! Die Tsinghua-Universität schlägt TimesNet vor: führend in der Vorhersage, Füllung, Klassifizierung und Erkennung
Apr 11, 2023 pm 07:34 PM
Das Erreichen von Aufgabenvielfalt ist ein zentrales Thema bei der Erforschung von Deep-Learning-Grundmodellen und stellt auch einen der Schwerpunkte in der jüngsten Ausrichtung auf große Modelle dar. Im Bereich der Zeitreihen sind die verschiedenen Arten von Analyseaufgaben jedoch sehr unterschiedlich, einschließlich Vorhersageaufgaben, die eine feinkörnige Modellierung erfordern, und Klassifizierungsaufgaben, die das Extrahieren semantischer Informationen auf hoher Ebene erfordern. Es ist noch nicht geklärt, wie ein einheitliches, tiefes Grundmodell zur effizienten Durchführung verschiedener Timing-Analyseaufgaben erstellt werden kann. Zu diesem Zweck führte ein Team der School of Software der Tsinghua-Universität Untersuchungen zum grundlegenden Problem der Timing-Änderungsmodellierung durch und schlug TimesNet vor, ein aufgabenübergreifendes Timing-Grundmodell. Das Papier wurde vom ICLR 2023 angenommen. Autorenliste: Wu Haixu*, Hu Tengge*, Liu Yong*, Zhou Hang, Wang Jianmin, Long Mingsheng Link: https://ope
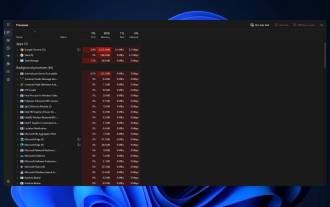 So stoppen Sie Prozessaktualisierungen im Task-Manager und beenden Aufgaben einfacher in Windows 11
Aug 20, 2023 am 11:05 AM
So stoppen Sie Prozessaktualisierungen im Task-Manager und beenden Aufgaben einfacher in Windows 11
Aug 20, 2023 am 11:05 AM
So unterbrechen Sie Task-Manager-Prozessaktualisierungen in Windows 11 und Windows 10. Drücken Sie STRG+Fenstertaste+Entf, um den Task-Manager zu öffnen. Standardmäßig öffnet der Task-Manager das Fenster „Prozesse“. Wie Sie hier sehen können, sind alle Apps endlos in Bewegung und es kann schwierig sein, auf sie zu zeigen, wenn Sie sie auswählen möchten. Drücken Sie also die STRG-Taste und halten Sie sie gedrückt. Dadurch wird der Task-Manager angehalten. Sie können weiterhin Apps auswählen und sogar nach unten scrollen, müssen jedoch jederzeit die STRG-Taste gedrückt halten.
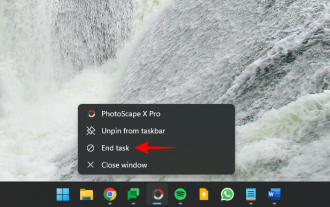 Alles, was Sie über die Option „Aufgabe beenden' in der Windows 11-Taskleiste wissen müssen
Aug 25, 2023 pm 12:29 PM
Alles, was Sie über die Option „Aufgabe beenden' in der Windows 11-Taskleiste wissen müssen
Aug 25, 2023 pm 12:29 PM
Eingefrorene oder nicht reagierende Programme können über den Task-Manager leicht beendet werden. Aber Microsoft bietet Benutzern seit Kurzem die Möglichkeit, diese Aufgaben direkt über die Taskleiste zu beenden. Obwohl die Option nicht für jeden verfügbar ist, ist sie leicht verfügbar, wenn Sie über den Windows Insider-Build verfügen. Hier finden Sie alles, was Sie zum Aktivieren der Schaltfläche „Aufgabe beenden“ und zum Schließen von Aufgaben über die Taskleiste benötigen. So erhalten Sie die Schaltfläche „Aufgabe beenden“ aus der Taskleiste, um Apps zu beenden. Derzeit ist die Option zum Aktivieren der Schaltfläche „Aufgabe beenden“ für Taskleisten-Apps nur als Entwickleroption für Benutzer mit Windows Insider-Builds verfügbar. Dies kann sich jedoch in einem bevorstehenden Funktionsupdate ändern, da es mit der stabilen Version für Benutzer weltweit bereitgestellt wird. Wenn Sie immer noch
