

Eingehende Analyse des Java-Puffer-Quellcodes

Native Umgebung: Linux 4.4.0-21-generic #37-Ubuntu SMP Mon Apr 18 18:33:37 UTC 2016 x86_64 x86_64 x86_64 GNU/Linux
Buffer
Das Klassendiagramm von Buffer lautet wie folgt:
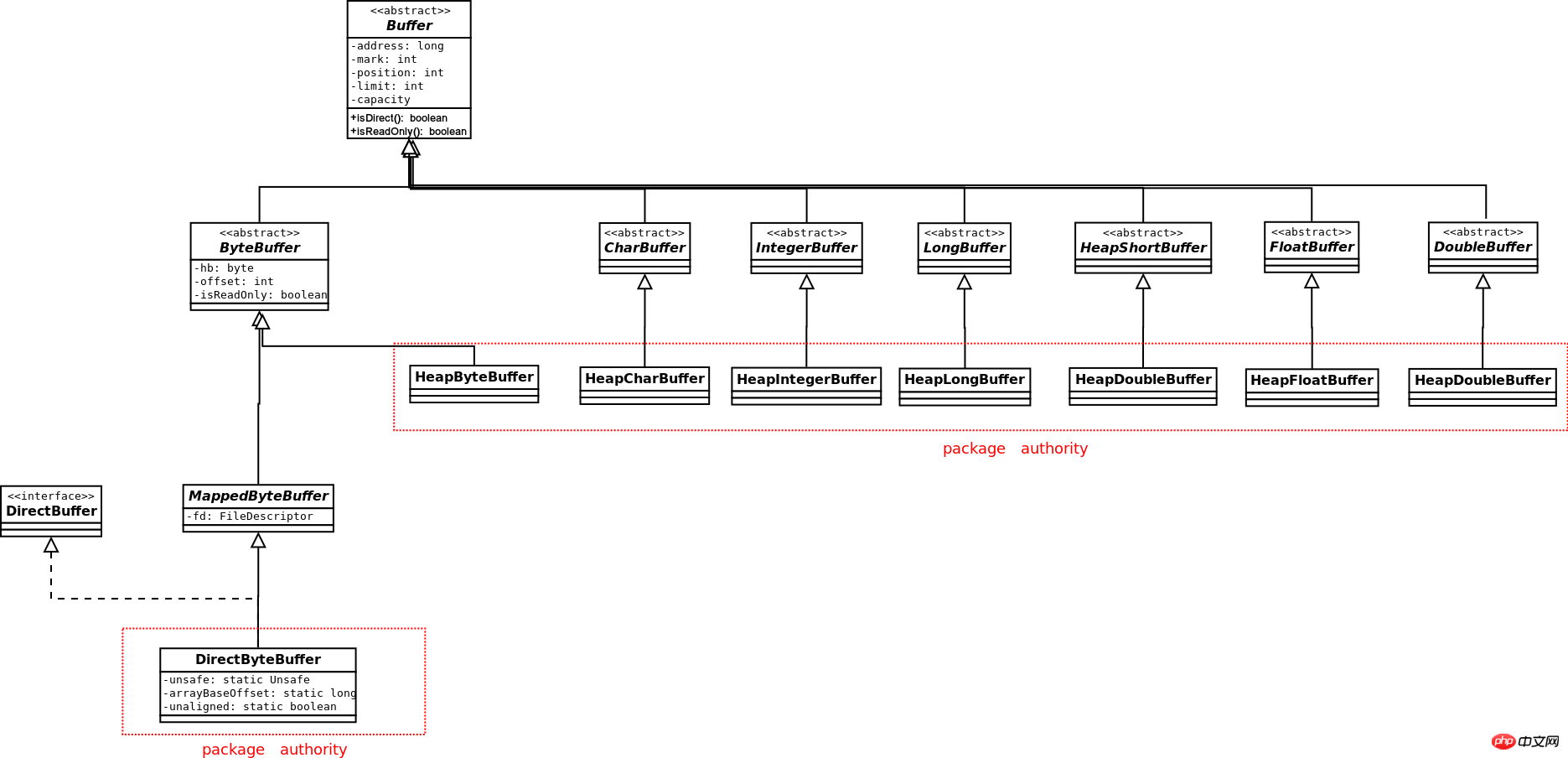
In Zusätzlich zu Boolean verfügen andere grundlegende Datentypen über entsprechende Puffer, aber nur ByteBuffer kann mit Channel interagieren. Nur ByteBuffer kann Direktpuffer generieren Puffer anderer Datentypen können nur Puffer vom Heap-Typ generieren. ByteBuffer kann Ansichtspuffer anderer Datentypen generieren. Wenn ByteBuffer selbst direkt ist, , dann ist jeder generierte Ansichtspuffer auch direkt .
Das Wesen von Puffern vom Typ „Direkt“ und „Heap“
Die erste Wahl besteht darin, darüber zu sprechen, wie die JVM E/A-Vorgänge ausführt.
JVM muss E/A-Vorgänge über Betriebssystemaufrufe abschließen. Beispielsweise kann das Lesen von Dateien über Lesesystemaufrufe abgeschlossen werden. Der Leseprototyp lautet: ssize_t read(int fd,void *buf,size_t nbytes), ähnlich wie bei anderen E/A-Systemaufrufen, erfordert im Allgemeinen einen Puffer als einen der Parameter, und der Puffer muss kontinuierlich sein.
Puffer ist in zwei Kategorien unterteilt: Direkt und Heap. Diese beiden Arten von Puffern werden im Folgenden erläutert.
Heap
Auf dem JVM-Heap ist ein Puffer vom Typ Heap vorhanden. Das Recycling und Sortieren dieses Teils des Speichers ist dasselbe wie bei gewöhnlichen Objekten. Pufferobjekte vom Heap-Typ enthalten alle ein Array-Attribut, das einem Basisdatentyp entspricht (z. B. final **[] hb), und das Array ist der zugrunde liegende Puffer des Heap-Typs Buffer.
Der Puffer vom Heap-Typ kann jedoch nicht als Pufferparameter für direkte Systemaufrufe verwendet werden, hauptsächlich aus den folgenden zwei Gründen.
JVM kann den Puffer während der GC verschieben (kopieren und organisieren), und die Adresse des Puffers ist nicht festgelegt.
Bei Systemaufrufen muss der Puffer kontinuierlich sein, aber das Array ist möglicherweise nicht kontinuierlich (die JVM-Implementierung erfordert keine kontinuierliche).
Wenn Sie also einen Heap-Puffer für E/A verwenden, muss die JVM einen temporären Direktpuffer generieren, dann die Daten kopieren und dann den temporären Direktpuffer als Parameter verwenden ein Betriebssystemaufruf. Dies führt hauptsächlich aus zwei Gründen zu einer sehr geringen Effizienz:
Die Daten müssen vom Heap-Typ-Puffer in den vorübergehend erstellten Direktpuffer kopiert werden.
kann eine große Anzahl von Pufferobjekten generieren, wodurch die Häufigkeit der GC erhöht wird. Sie können also während E/A-Vorgängen eine Optimierung durchführen, indem Sie den Puffer wiederverwenden.
Direkt
Der Puffer vom Typ „Direkt“ existiert nicht auf dem Heap, sondern ist ein kontinuierlicher Speicher, der direkt von der JVM über malloc zugewiesen wird Direkter Speicher: Die JVM verwendet den direkten Speicher als Puffer, wenn sie E/A-Systemaufrufe durchführt. -XX:MaxDirectMemorySize, über diese Konfiguration können Sie die maximale direkte Speichergröße festlegen, die zugewiesen werden darf (der von MappedByteBuffer zugewiesene Speicher ist von dieser Konfiguration nicht betroffen).
Das direkte Speicherrecycling unterscheidet sich vom Heap-Speicherrecycling. Wenn der direkte Speicher nicht ordnungsgemäß verwendet wird, kann es leicht zu OutOfMemoryError kommen. JAVA bietet keine explizite Methode zum aktiven Freigeben von Direktspeicher. Die Klasse sun.misc.Unsafe kann direkte zugrunde liegende Speicheroperationen ausführen, und Direktspeicher kann über diese Klasse aktiv freigegeben und verwaltet werden. In ähnlicher Weise sollte auch der direkte Speicher wiederverwendet werden, um die Effizienz zu verbessern.
Beziehung zwischen MappedByteBuffer und DirectByteBuffer
Das ist ein bisschen rückwärts: Eigentlich sollte MappedByteBuffer eine Unterklasse von DirectByteBuffer sein, aber um die Spezifikation klar zu halten und Einfacher, und aus Optimierungsgründen ist es einfacher, es umgekehrt zu machen. Dies funktioniert, weil DirectByteBuffer eine paketprivate Klasse ist.(Dieser Absatz stammt aus dem Quellcode von MappedByteBuffer)
Tatsächlich ist MappedByteBuffer ein zugeordneter Puffer (schauen Sie sich den virtuellen Speicher selbst an), aber DirectByteBuffer zeigt nur an, dass dieser Teil des Speichers ein kontinuierlicher Puffer ist, der von der JVM im direkten Speicherbereich zugewiesen wird und nicht unbedingt zugeordnet wird. Mit anderen Worten: MappedByteBuffer sollte eine Unterklasse von DirectByteBuffer sein, aber der Einfachheit halber und zur Optimierung wird MappedByteBuffer als übergeordnete Klasse von DirectByteBuffer verwendet. Obwohl MappedByteBuffer logischerweise eine Unterklasse von DirectByteBuffer sein sollte und der Speicher-GC von MappedByteBuffer dem GC des direkten Speichers ähnelt (anders als der Heap-GC), wird die Größe des zugewiesenen MappedByteBuffer durch -XX:MaxDirectMemorySize nicht beeinflusst Parameter.
MappedByteBuffer kapselt speicherzugeordnete Dateivorgänge, was bedeutet, dass nur Datei-E/A-Vorgänge ausgeführt werden können. MappedByteBuffer ist ein Mapping-Puffer, der auf der Grundlage von mmap generiert wird. Dieser Teil des Puffers wird der entsprechenden Dateiseite zugeordnet und gehört zum direkten Speicher im Benutzermodus. Der zugeordnete Puffer kann direkt über MappedByteBuffer bedient werden, und dieser Teil des Puffers wird zugeordnet Auf der Dateiseite vervollständigt das Betriebssystem das Schreiben und Schreiben von Dateien durch Aufrufen der entsprechenden Speicherseiten.
MappedByteBuffer
Get MappedByteBuffer über FileChannel.map(MapMode mode,long position, long size) Der Generierungsprozess von MappedByteBuffer wird unten anhand des Quellcodes erläutert.
FileChannel.map Quellcode:
public MappedByteBuffer map(MapMode mode, long position, long size)throws IOException
{ensureOpen();if (position < 0L)throw new IllegalArgumentException("Negative position");if (size < 0L)throw new IllegalArgumentException("Negative size");if (position + size < 0)throw new IllegalArgumentException("Position + size overflow");//最大2Gif (size > Integer.MAX_VALUE)throw new IllegalArgumentException("Size exceeds Integer.MAX_VALUE");int imode = -1;if (mode == MapMode.READ_ONLY)
imode = MAP_RO;else if (mode == MapMode.READ_WRITE)
imode = MAP_RW;else if (mode == MapMode.PRIVATE)
imode = MAP_PV;assert (imode >= 0);if ((mode != MapMode.READ_ONLY) && !writable)throw new NonWritableChannelException();if (!readable)throw new NonReadableChannelException();long addr = -1;int ti = -1;try {begin();
ti = threads.add();if (!isOpen())return null;//size()返回实际的文件大小//如果实际文件大小不符合,则增大文件的大小,文件的大小被改变,文件增大的部分默认设置为0。if (size() < position + size) { // Extend file sizeif (!writable) {throw new IOException("Channel not open for writing " +"- cannot extend file to required size");
}int rv;do { //增大文件的大小rv = nd.truncate(fd, position + size);
} while ((rv == IOStatus.INTERRUPTED) && isOpen());
}//如果要求映射的文件大小为0,则不调用操作系统的mmap调用,只是生成一个空间容量为0的DirectByteBuffer//并返回if (size == 0) {
addr = 0;// a valid file descriptor is not requiredFileDescriptor dummy = new FileDescriptor();if ((!writable) || (imode == MAP_RO))return Util.newMappedByteBufferR(0, 0, dummy, null);elsereturn Util.newMappedByteBuffer(0, 0, dummy, null);
}//allocationGranularity的大小在我的系统上是4K//页对齐,pagePosition为第多少页int pagePosition = (int)(position % allocationGranularity);//从页的最开始映射long mapPosition = position - pagePosition;//因为从页的最开始映射,增大映射空间long mapSize = size + pagePosition;try {// If no exception was thrown from map0, the address is valid//native方法,源代码在openjdk/jdk/src/solaris/native/sun/nio/ch/FileChannelImpl.c,//参见下面的说明addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError x) {// An OutOfMemoryError may indicate that we've exhausted memory// so force gc and re-attempt mapSystem.gc();try {
Thread.sleep(100);
} catch (InterruptedException y) {
Thread.currentThread().interrupt();
}try {
addr = map0(imode, mapPosition, mapSize);
} catch (OutOfMemoryError y) {// After a second OOME, failthrow new IOException("Map failed", y);
}
}// On Windows, and potentially other platforms, we need an open// file descriptor for some mapping operations.FileDescriptor mfd;try {
mfd = nd.duplicateForMapping(fd);
} catch (IOException ioe) {unmap0(addr, mapSize);throw ioe;
}assert (IOStatus.checkAll(addr));assert (addr % allocationGranularity == 0);int isize = (int)size;
Unmapper um = new Unmapper(addr, mapSize, isize, mfd);if ((!writable) || (imode == MAP_RO)) {return Util.newMappedByteBufferR(isize,
addr + pagePosition,
mfd,
um);
} else {return Util.newMappedByteBuffer(isize,
addr + pagePosition,
mfd,
um);
}
} finally {
threads.remove(ti);end(IOStatus.checkAll(addr));
}
}map0的源码实现:
JNIEXPORT jlong JNICALL
Java_sun_nio_ch_FileChannelImpl_map0(JNIEnv *env, jobject this,
jint prot, jlong off, jlong len)
{void *mapAddress = 0;
jobject fdo = (*env)->GetObjectField(env, this, chan_fd);//linux系统调用是通过整型的文件id引用文件的,这里得到文件idjint fd = fdval(env, fdo);int protections = 0;int flags = 0;if (prot == sun_nio_ch_FileChannelImpl_MAP_RO) {
protections = PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_RW) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_SHARED;
} else if (prot == sun_nio_ch_FileChannelImpl_MAP_PV) {
protections = PROT_WRITE | PROT_READ;
flags = MAP_PRIVATE;
}//这里就是操作系统调用了,mmap64是宏定义,实际最后调用的是mmapmapAddress = mmap64(0, /* Let OS decide location */len, /* Number of bytes to map */protections, /* File permissions */flags, /* Changes are shared */fd, /* File descriptor of mapped file */off); /* Offset into file */if (mapAddress == MAP_FAILED) {if (errno == ENOMEM) {//如果没有映射成功,直接抛出OutOfMemoryErrorJNU_ThrowOutOfMemoryError(env, "Map failed");return IOS_THROWN;
}return handle(env, -1, "Map failed");
}return ((jlong) (unsigned long) mapAddress);
}虽然FileChannel.map()的zise参数是long,但是size的大小最大为Integer.MAX_VALUE,也就是最大只能映射最大2G大小的空间。实际上操作系统提供的MMAP可以分配更大的空间,但是JAVA限制在2G,ByteBuffer等Buffer也最大只能分配2G大小的缓冲区。
MappedByteBuffer是通过mmap产生得到的缓冲区,这部分缓冲区是由操作系统直接创建和管理的,最后JVM通过unmmap让操作系统直接释放这部分内存。
Haep****Buffer
下面以ByteBuffer为例,说明Heap类型Buffer的细节。
该类型的Buffer可以通过下面方式产生:
ByteBuffer.allocate(int capacity)ByteBuffer.wrap(byte[] array)
使用传入的数组作为底层缓冲区,变更数组会影响缓冲区,变更缓冲区也会影响数组。ByteBuffer.wrap(byte[] array,int offset, int length)
使用传入的数组的一部分作为底层缓冲区,变更数组的对应部分会影响缓冲区,变更缓冲区也会影响数组。
DirectByteBuffer
DirectByteBuffer只能通过ByteBuffer.allocateDirect(int capacity) 产生。ByteBuffer.allocateDirect()源码如下:
public static ByteBuffer allocateDirect(int capacity) {return new DirectByteBuffer(capacity);
}DirectByteBuffer()源码如下:
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
//直接内存是否要页对齐,我本机测试的不用
boolean pa = VM.isDirectMemoryPageAligned();
//页的大小,本机测试的是4K
int ps = Bits.pageSize();
//如果页对齐,则size的大小是ps+cap,ps是一页,cap也是从新的一页开始,也就是页对齐了
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
//JVM维护所有直接内存的大小,如果已分配的直接内存加上本次要分配的大小超过允许分配的直接内存的最大值会
//引起GC,否则允许分配并把已分配的直接内存总量加上本次分配的大小。如果GC之后,还是超过所允许的最大值,
//则throw new OutOfMemoryError("Direct buffer memory");
Bits.reserveMemory(size, cap);
long base = 0;
try {
//是吧,unsafe可以直接操作底层内存
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {、
//没有分配成功,把刚刚加上的已分配的直接内存的大小减去。
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}unsafe.allocateMemory()的源码在openjdk/src/openjdk/hotspot/src/share/vm/prims/unsafe.cpp中。具体的源码如下:
UNSAFE_ENTRY(jlong, Unsafe_AllocateMemory(JNIEnv *env, jobject unsafe, jlong size))
UnsafeWrapper("Unsafe_AllocateMemory");
size_t sz = (size_t)size; if (sz != (julong)size || size < 0) {
THROW_0(vmSymbols::java_lang_IllegalArgumentException());
} if (sz == 0) {return 0;
}
sz = round_to(sz, HeapWordSize); //最后调用的是 u_char* ptr = (u_char*)::malloc(size + space_before + space_after),也就是malloc。
void* x = os::malloc(sz, mtInternal); if (x == NULL) {
THROW_0(vmSymbols::java_lang_OutOfMemoryError());
} //Copy::fill_to_words((HeapWord*)x, sz / HeapWordSize);
return addr_to_java(x);
UNSAFE_ENDJVM通过malloc分配得到连续的缓冲区,这部分缓冲区可以直接作为缓冲区参数进行操作系统调用。
Das obige ist der detaillierte Inhalt vonEingehende Analyse des Java-Puffer-Quellcodes. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Die Anwendungspraxis von Python beim Schutz von Software-Quellcode
Jun 29, 2023 am 11:20 AM
Die Anwendungspraxis von Python beim Schutz von Software-Quellcode
Jun 29, 2023 am 11:20 AM
Als Programmiersprache auf hohem Niveau ist Python leicht zu erlernen, leicht zu lesen und zu schreiben und wird häufig in der Softwareentwicklung eingesetzt. Aufgrund des Open-Source-Charakters von Python ist der Quellcode jedoch für andere leicht zugänglich, was einige Herausforderungen für den Schutz des Software-Quellcodes mit sich bringt. Daher müssen wir in praktischen Anwendungen häufig einige Methoden anwenden, um den Python-Quellcode zu schützen und seine Sicherheit zu gewährleisten. Beim Schutz des Software-Quellcodes stehen für Python verschiedene Anwendungspraktiken zur Auswahl. Nachfolgend sind einige häufige aufgeführt
 So zeigen Sie den Quellcode von Tomcat in der Idee an
Jan 25, 2024 pm 02:01 PM
So zeigen Sie den Quellcode von Tomcat in der Idee an
Jan 25, 2024 pm 02:01 PM
Schritte zum Anzeigen des Tomcat-Quellcodes in IDEA: 2. Tomcat-Quellcode in IDEA importieren; 4. Das Funktionsprinzip von Tomcat verstehen; Aktualisieren 7. Verwenden Sie Tools und Plug-Ins. 8. Nehmen Sie an der Community teil und leisten Sie einen Beitrag. Detaillierte Einführung: 1. Laden Sie den Tomcat-Quellcode herunter. Sie können das Quellcodepaket von der offiziellen Website von Apache Tomcat herunterladen. Normalerweise liegen diese Quellcodepakete im ZIP- oder TAR-Format vor.
 Eingehende Analyse: Was ist das wahre Leistungsniveau der Go-Sprache?
Jan 30, 2024 am 10:02 AM
Eingehende Analyse: Was ist das wahre Leistungsniveau der Go-Sprache?
Jan 30, 2024 am 10:02 AM
Eingehende Analyse: Wie ist die Leistung der Go-Sprache? Einleitung: In der heutigen Welt der Softwareentwicklung ist Leistung ein entscheidender Faktor. Für Entwickler kann die Wahl einer Programmiersprache mit hervorragender Leistung die Effizienz und Qualität von Softwareanwendungen verbessern. Als moderne Programmiersprache wird die Go-Sprache von vielen Entwicklern als eine Hochleistungssprache angesehen. In diesem Artikel werden die Leistungsmerkmale der Go-Sprache untersucht und anhand spezifischer Codebeispiele analysiert. 1. Parallelitätsfunktionen: Als Programmiersprache, die auf Parallelität basiert, verfügt die Go-Sprache über hervorragende Parallelitätsfunktionen.
 Wie kann der Quellcode von PHP-Code im Browser angezeigt werden, ohne dass er interpretiert und ausgeführt wird?
Mar 11, 2024 am 10:54 AM
Wie kann der Quellcode von PHP-Code im Browser angezeigt werden, ohne dass er interpretiert und ausgeführt wird?
Mar 11, 2024 am 10:54 AM
Wie kann der Quellcode von PHP-Code im Browser angezeigt werden, ohne dass er interpretiert und ausgeführt wird? PHP ist eine serverseitige Skriptsprache, die häufig zur Entwicklung dynamischer Webseiten verwendet wird. Wenn eine PHP-Datei auf dem Server angefordert wird, interpretiert und führt der Server den darin enthaltenen PHP-Code aus und sendet den endgültigen HTML-Inhalt zur Anzeige an den Browser. Manchmal möchten wir jedoch den Quellcode der PHP-Datei direkt im Browser anzeigen, anstatt ihn auszuführen. In diesem Artikel wird erläutert, wie der Quellcode von PHP-Code im Browser angezeigt wird, ohne dass er interpretiert und ausgeführt wird. In PHP können Sie verwenden
 Kann Vue Quellcode anzeigen?
Jan 05, 2023 pm 03:17 PM
Kann Vue Quellcode anzeigen?
Jan 05, 2023 pm 03:17 PM
Vue kann den Quellcode in Vue anzeigen: 1. Holen Sie sich Vue über „git clone https://github.com/vuejs/vue.git“ 2. Installieren Sie Abhängigkeiten über „npm i“; 3. Über „npm i -g rollup“ 4. Ändern Sie das Entwicklungsskript. 5. Debuggen Sie den Quellcode.
 Website zum Online-Ansehen des Quellcodes
Jan 10, 2024 pm 03:31 PM
Website zum Online-Ansehen des Quellcodes
Jan 10, 2024 pm 03:31 PM
Sie können die Entwicklertools des Browsers verwenden, um den Quellcode der Website anzuzeigen. Im Google Chrome-Browser: 1. Öffnen Sie den Chrome-Browser und besuchen Sie die Website, auf der Sie den Quellcode anzeigen möchten Seite und wählen Sie „Inspizieren“ oder drücken Sie die Tastenkombination Strg + Umschalt + I, um die Entwicklertools zu öffnen. 3. Wählen Sie in der oberen Menüleiste der Entwicklertools die Registerkarte „Elemente“ aus. 4. Sehen Sie sich einfach den HTML- und CSS-Code an der Website.
 Eine umfassende Anleitung zum Erlernen und Anwenden des Golang-Framework-Quellcodes
Jun 01, 2024 pm 10:31 PM
Eine umfassende Anleitung zum Erlernen und Anwenden des Golang-Framework-Quellcodes
Jun 01, 2024 pm 10:31 PM
Durch das Verständnis des Quellcodes des Golang-Frameworks können Entwickler die Essenz der Sprache beherrschen und die Funktionen des Frameworks erweitern. Besorgen Sie sich zunächst den Quellcode und machen Sie sich mit seiner Verzeichnisstruktur vertraut. Zweitens lesen Sie den Code, verfolgen Sie den Ausführungsfluss und verstehen Sie die Abhängigkeiten. Praxisbeispiele zeigen, wie Sie dieses Wissen anwenden: Erstellen Sie benutzerdefinierte Middleware und erweitern Sie das Routing-System. Zu den Best Practices gehören das schrittweise Lernen, das Vermeiden von sinnlosem Kopieren und Einfügen, die Verwendung von Tools und der Verweis auf Online-Ressourcen.
 PHP-Quellcode-Fehler: Lösung des Indexfehlerproblems
Mar 10, 2024 am 11:12 AM
PHP-Quellcode-Fehler: Lösung des Indexfehlerproblems
Mar 10, 2024 am 11:12 AM
PHP-Quellcodefehler: Um das Indexfehlerproblem zu lösen, sind spezifische Codebeispiele erforderlich. Aufgrund der rasanten Entwicklung des Internets stoßen Entwickler beim Schreiben von Websites und Anwendungen häufig auf verschiedene Probleme. Unter diesen ist PHP eine beliebte serverseitige Skriptsprache, und ihre Quellcodefehler sind eines der Probleme, auf die Entwickler häufig stoßen. Wenn wir versuchen, die Indexseite einer Website zu öffnen, werden manchmal verschiedene Fehlermeldungen angezeigt, z. B. „InternalServerError“, „Unde
