

Beispiel für Python-Crawler-Audiodaten

1: Vorwort
Dieses Mal haben wir die Informationen zu jedem Kanal aller Radiosender unter der beliebten Spalte „Himalaya“ und verschiedene Informationen zu den einzelnen Audiodaten im Kanal gecrawlt und dann die gecrawlten Daten gespeichert mongodb zur späteren Verwendung. Diesmal beträgt die Datenmenge rund 700.000. Zu den Audiodaten gehören Audio-Download-Adresse, Kanalinformationen, Einleitung usw., davon gibt es viele.
Ich hatte gestern mein erstes Vorstellungsgespräch. Ich wollte in den Sommerferien meines zweiten Studienjahres ein Praktikum machen, also kam ich, um Himalaya zu analysieren . Die Audiodaten kriechen nach unten. Derzeit warte ich noch auf drei Interviews oder darauf, über die endgültigen Interviewnachrichten informiert zu werden. (Da ich eine gewisse Anerkennung bekommen kann, bin ich unabhängig von Erfolg oder Misserfolg sehr glücklich)
2: Laufumgebung
-
IDE: Pycharm 2017
Python3.6
Pymongo 3.4.0
Anfragen 2.14.2
-
lxml 3.7.2
BeautifulSoup 4.5.3
Drei: Beispielanalyse
1. Rufen Sie zunächst die Hauptseite dieses Crawls auf. Auf jeder Seite sind 12 Kanäle zu sehen. Unter jedem Kanal gibt es viele Seitenumbrüche. Crawling-Plan: Durchlaufen Sie 84 Seiten, analysieren Sie jede Seite, erfassen Sie den Namen, den Bildlink und den Kanallink jedes Kanals und speichern Sie sie in Mongodb.
2. Öffnen Sie den Entwicklermodus, analysieren Sie die Seite und ermitteln Sie schnell den Speicherort der gewünschten Daten. Mit dem folgenden Code werden die Informationen aller gängigen Kanäle erfasst und in mongodb gespeichert.
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
print(content)
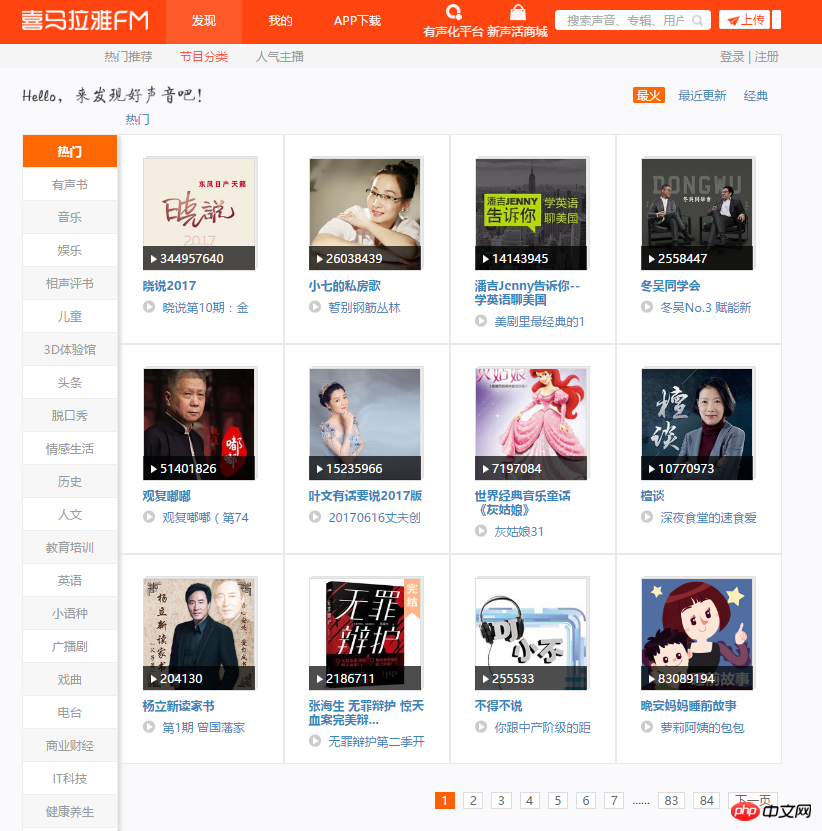
3 Im Folgenden wird damit begonnen, alle Audiodaten in jedem Kanal zu erhalten, die über erhalten wurden Die Analyseseite Hier ist der Link zum US-Kanal. Beispielsweise analysieren wir die Seitenstruktur nach Eingabe dieses Links. Es ist ersichtlich, dass jedes Audio eine bestimmte ID hat, die aus den Attributen in einem Div abgerufen werden kann. Verwenden Sie split() und int(), um in einzelne IDs zu konvertieren.
4. Klicken Sie dann auf einen Audiolink, wechseln Sie in den Entwicklermodus, aktualisieren Sie die Seite und klicken Sie auf XHR, dann klicken Sie auf a json Der Link, um dies anzuzeigen, enthält alle Details dieses Audios.
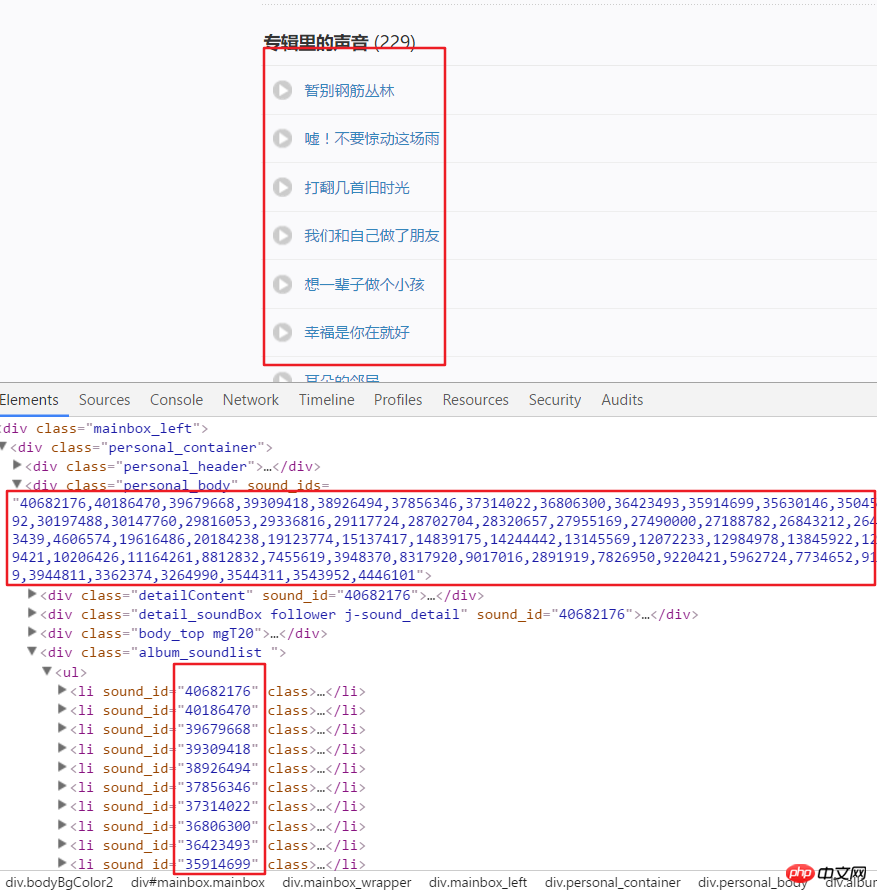
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
5. Das Obige analysiert nur alle Audioinformationen auf der Hauptseite eines Kanals. aber in Wirklichkeit hat der Audiolink auf dem oberen Kanal viele Seitenumbrüche.
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)# 之后就接解析音频页函数就行,后面有完整代码说明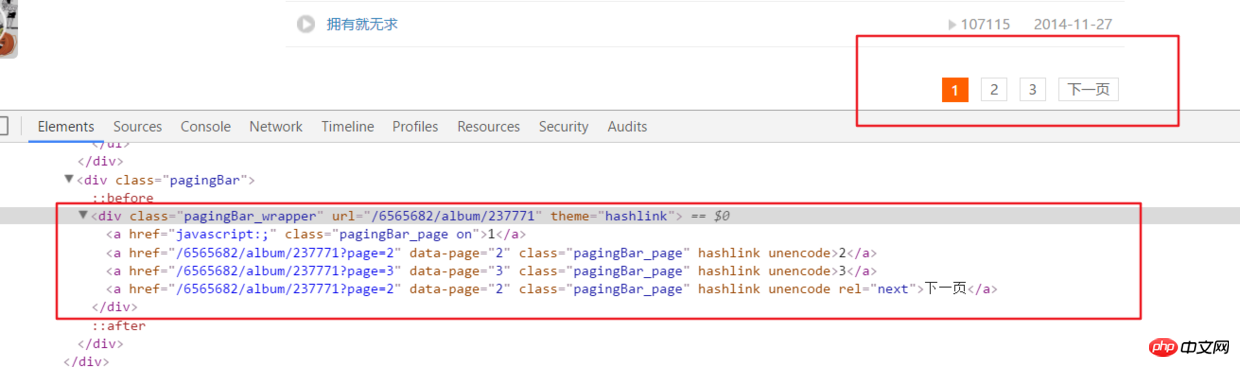
6. Alle Codes
Vollständige Codeadresse github.com/rieuse/learnPython
__author__ = '布咯咯_rieuse'import jsonimport randomimport timeimport pymongoimport requestsfrom bs4 import BeautifulSoupfrom lxml import etree
clients = pymongo.MongoClient('localhost')
db = clients["XiMaLaYa"]
col1 = db["album"]
col2 = db["detaile"]
UA_LIST = [] # 很多User-Agent用来随机使用可以防ban,显示不方便不贴出来了
headers1 = {} # 访问网页的headers,这里显示不方便我就不贴出来了
headers2 = {} # 访问网页的headers这里显示不方便我就不贴出来了def get_url():
start_urls = ['http://www.ximalaya.com/dq/all/{}'.format(num) for num in range(1, 85)]for start_url in start_urls:
html = requests.get(start_url, headers=headers1).text
soup = BeautifulSoup(html, 'lxml')for item in soup.find_all(class_="albumfaceOutter"):
content = {'href': item.a['href'],'title': item.img['alt'],'img_url': item.img['src']
}
col1.insert(content)
print('写入一个频道' + item.a['href'])
print(content)
another(item.a['href'])
time.sleep(1)def another(url):
html = requests.get(url, headers=headers2).text
ifanother = etree.HTML(html).xpath('//div[@class="pagingBar_wrapper"]/a[last()-1]/@data-page')if len(ifanother):
num = ifanother[0]
print('本频道资源存在' + num + '个页面')for n in range(1, int(num)):
print('开始解析{}个中的第{}个页面'.format(num, n))
url2 = url + '?page={}'.format(n)
get_m4a(url2)
get_m4a(url)def get_m4a(url):
time.sleep(1)
html = requests.get(url, headers=headers2).text
numlist = etree.HTML(html).xpath('//div[@class="personal_body"]/@sound_ids')[0].split(',')for i in numlist:
murl = 'http://www.ximalaya.com/tracks/{}.json'.format(i)
html = requests.get(murl, headers=headers1).text
dic = json.loads(html)
col2.insert(dic)
print(murl + '中的数据已被成功插入mongodb')if __name__ == '__main__':
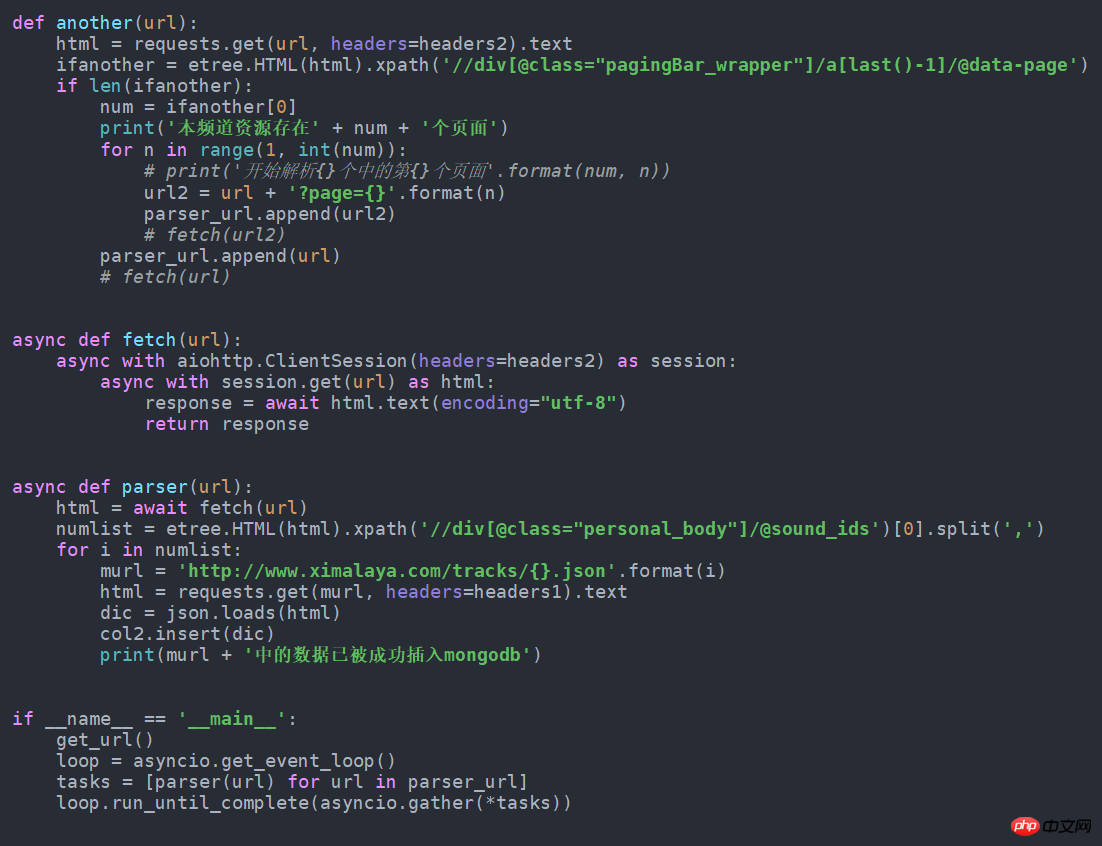
get_url()7. Wenn es in die asynchrone Form geändert wird, wird es schneller. Ändern Sie es einfach wie folgt. Ich habe versucht, fast 100 Daten mehr pro Minute als normal zu erhalten. Dieser Quellcode ist auch in Github.
Das obige ist der detaillierte Inhalt vonBeispiel für Python-Crawler-Audiodaten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1389
1389
 52
52

 Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
Kann gegen Code in Windows 8 ausgeführt werden
Apr 15, 2025 pm 07:24 PM
VS -Code kann unter Windows 8 ausgeführt werden, aber die Erfahrung ist möglicherweise nicht großartig. Stellen Sie zunächst sicher, dass das System auf den neuesten Patch aktualisiert wurde, und laden Sie dann das VS -Code -Installationspaket herunter, das der Systemarchitektur entspricht und sie wie aufgefordert installiert. Beachten Sie nach der Installation, dass einige Erweiterungen möglicherweise mit Windows 8 nicht kompatibel sind und nach alternativen Erweiterungen suchen oder neuere Windows -Systeme in einer virtuellen Maschine verwenden müssen. Installieren Sie die erforderlichen Erweiterungen, um zu überprüfen, ob sie ordnungsgemäß funktionieren. Obwohl VS -Code unter Windows 8 möglich ist, wird empfohlen, auf ein neueres Windows -System zu upgraden, um eine bessere Entwicklungserfahrung und Sicherheit zu erzielen.
 Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
Ist die VSCODE -Erweiterung bösartig?
Apr 15, 2025 pm 07:57 PM
VS -Code -Erweiterungen stellen böswillige Risiken dar, wie das Verstecken von böswilligem Code, das Ausbeutetieren von Schwachstellen und das Masturbieren als legitime Erweiterungen. Zu den Methoden zur Identifizierung böswilliger Erweiterungen gehören: Überprüfung von Verlegern, Lesen von Kommentaren, Überprüfung von Code und Installation mit Vorsicht. Zu den Sicherheitsmaßnahmen gehören auch: Sicherheitsbewusstsein, gute Gewohnheiten, regelmäßige Updates und Antivirensoftware.
 Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
Wählen Sie zwischen PHP und Python: Ein Leitfaden
Apr 18, 2025 am 12:24 AM
PHP eignet sich für Webentwicklung und schnelles Prototyping, und Python eignet sich für Datenwissenschaft und maschinelles Lernen. 1.PHP wird für die dynamische Webentwicklung verwendet, mit einfacher Syntax und für schnelle Entwicklung geeignet. 2. Python hat eine kurze Syntax, ist für mehrere Felder geeignet und ein starkes Bibliotheksökosystem.
 So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
So führen Sie Programme in der terminalen VSCODE aus
Apr 15, 2025 pm 06:42 PM
Im VS -Code können Sie das Programm im Terminal in den folgenden Schritten ausführen: Erstellen Sie den Code und öffnen Sie das integrierte Terminal, um sicherzustellen, dass das Codeverzeichnis mit dem Terminal Working -Verzeichnis übereinstimmt. Wählen Sie den Befehl aus, den Befehl ausführen, gemäß der Programmiersprache (z. B. Pythons Python your_file_name.py), um zu überprüfen, ob er erfolgreich ausgeführt wird, und Fehler auflösen. Verwenden Sie den Debugger, um die Debugging -Effizienz zu verbessern.
 PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP und Python: Verschiedene Paradigmen erklärt
Apr 18, 2025 am 12:26 AM
PHP ist hauptsächlich prozedurale Programmierung, unterstützt aber auch die objektorientierte Programmierung (OOP). Python unterstützt eine Vielzahl von Paradigmen, einschließlich OOP, funktionaler und prozeduraler Programmierung. PHP ist für die Webentwicklung geeignet, und Python eignet sich für eine Vielzahl von Anwendungen wie Datenanalyse und maschinelles Lernen.
 Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
Kann Visual Studio -Code in Python verwendet werden
Apr 15, 2025 pm 08:18 PM
VS -Code kann zum Schreiben von Python verwendet werden und bietet viele Funktionen, die es zu einem idealen Werkzeug für die Entwicklung von Python -Anwendungen machen. Sie ermöglichen es Benutzern: Installation von Python -Erweiterungen, um Funktionen wie Code -Abschluss, Syntax -Hervorhebung und Debugging zu erhalten. Verwenden Sie den Debugger, um Code Schritt für Schritt zu verfolgen, Fehler zu finden und zu beheben. Integrieren Sie Git für die Versionskontrolle. Verwenden Sie Tools für die Codeformatierung, um die Codekonsistenz aufrechtzuerhalten. Verwenden Sie das Lining -Tool, um potenzielle Probleme im Voraus zu erkennen.
 Kann VSCODE für MAC verwendet werden
Apr 15, 2025 pm 07:36 PM
Kann VSCODE für MAC verwendet werden
Apr 15, 2025 pm 07:36 PM
VS -Code ist auf Mac verfügbar. Es verfügt über leistungsstarke Erweiterungen, GIT -Integration, Terminal und Debugger und bietet auch eine Fülle von Setup -Optionen. Für besonders große Projekte oder hoch berufliche Entwicklung kann VS -Code jedoch Leistung oder funktionale Einschränkungen aufweisen.
 Kann vscode ipynb ausführen
Apr 15, 2025 pm 07:30 PM
Kann vscode ipynb ausführen
Apr 15, 2025 pm 07:30 PM
Der Schlüssel zum Ausführen von Jupyter -Notebook im VS -Code liegt darin, sicherzustellen, dass die Python -Umgebung ordnungsgemäß konfiguriert ist, verstehen, dass die Codeausführungsreihenfolge mit der Zellreihenfolge übereinstimmt, und sich der großen Dateien oder externen Bibliotheken bewusst zu sein, die die Leistung beeinflussen können. Die vom VS -Code bereitgestellten Codebetausch- und Debugging -Funktionen können die Codierungseffizienz erheblich verbessern und Fehler verringern.
