
HTTP-Protokoll:
HTTP (Hypertext Transfer Protocol): Hypertext Transfer Protocol. URL ist der Internetpfad für den Zugriff auf Ressourcen über das HTTP-Protokoll. Eine URL entspricht einer Datenressource.
Betrieb von Ressourcen durch HTTP-Protokoll:

Die Requests-Bibliothek stellt alle grundlegenden Anforderungsmethoden von HTTP bereit . Offizielle Einführung:
Die 6 Hauptmethoden der Requests-Bibliothek:

Ausnahmen in der Requests-Bibliothek:

Zwei wichtige Objekte in der Requests-Bibliothek: Request (Anfrage) und Response (Antwort). Das Request-Objekt unterstützt mehrere Request-Methoden; das Response-Objekt enthält alle vom Server zurückgegebenen Informationen sowie die angeforderten Request-Informationen.
Attribute des Antwortobjekts:

Unter anderem bedeutet r.encoding: wenn ja nicht im Header-Zeichensatz vorhanden ist, wird die Kodierung als ISO-8859-1 angesehen.
r.raise_for_status() kann direkt erkennen, ob r.status_code gleich 200 ist.
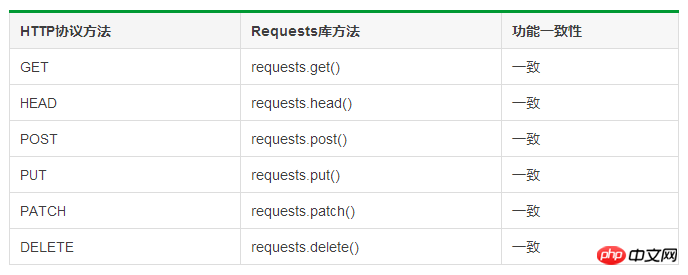
Vergleich von HTTP-Protokoll und Anforderungsbibliothek:
Crawling-Webseiten Allgemeines Code-Framework:
1 try:2 r = requests.get(url,timeout = 30)3 r.raise_for_status()4 # 如果状态不是200,引发HTTPError异常5 r.encoding = r.apparent_encoding6 return r.text7 except:8 return '产生异常'
Informationen finden Sie beispielsweise auf der PMCAFF-Homepage:
1 import requests 2 3 def getHtmlText(url): 4 try: 5 r = requests.get(url,timeout = 30) 6 r.raise_for_status() 7 r.encoding = r.apparent_encoding 8 return r.text 9 except:10 return '产生异常'11 12 if __name__ == '__main__':13 url = ''14 print(getHtmlText(url))
Allgemeines Code-Framework zum Crawlen von Webseiten: Betriebsumgebung: Mac, Python 3.6, PyCharm 2016.2
Referenz: MOOC-Kurs der Chinesischen Universität „Python Web Crawler and Information Extraction“
----- Ende -----
Autor: Du Wangdan, öffentliches WeChat-Konto: Du Wangdan, Internetprodukt Manager.

Das obige ist der detaillierte Inhalt vonPython-Crawler: HTTP-Protokoll, Requests-Bibliothek. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



