

Teilen Sie häufig verwendete Sortierbeispiele in Python

Stabilität und Bedeutung des Sortieralgorithmus
Blasensortierung
Komplexität und Stabilitätseigenschaften
Auswahlsortierung
Einfügungssortierung
-
Hügelsortierung
Schnellsortierung
Vergleich der Effizienz gängiger Sortieralgorithmen
Stabilität und Bedeutung von Sortieralgorithmen
In der zu sortierenden Reihenfolge gibt es Datensätze mit denselben Schlüsselwörtern, und die relative Reihenfolge dieser Datensätze bleibt nach dem Sortieren unverändert, sodass der Sortieralgorithmus stabil ist.
Eine instabile Sortierung kann die Sortierung mehrerer Schlüsselwörter nicht abschließen. Bei der Ganzzahlsortierung gilt beispielsweise: Je höher die Anzahl der Ziffern, desto höher die Priorität, d. h. die Sortierung erfolgt von hohen Ziffern zu niedrigen Ziffern. Dann erfordert die Sortierung jedes Bits einen stabilen Algorithmus, da sonst nicht das richtige Ergebnis erzielt werden kann.
Das heißt, Wenn mehrere Schlüsselwörter mehrfach sortiert werden sollen, muss ein stabiler Algorithmus verwendet werden
Blasensortierung
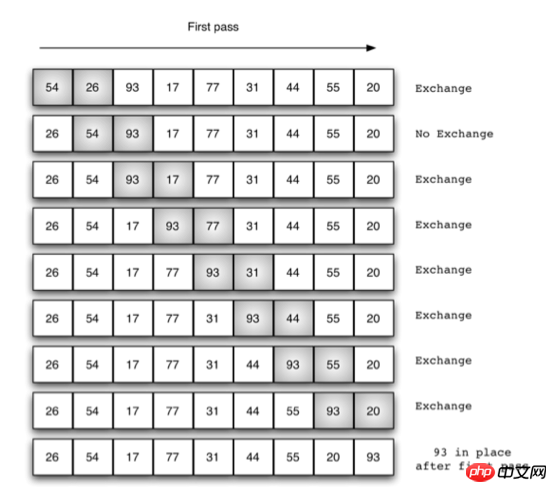 

def bubble_sort(alist):
"""
冒泡排序
"""
if len(alist) <= 1:
return alist
for j in range(len(alist)-1,0,-1):
for i in range(j):
if alist[i] > alist[i+1]:
alist[i], alist[i+1] = alist[i+1], alist[i]
return alistKomplexität und Stabilität
Optimale zeitliche Komplexität: (O(n)) Die Durchquerung findet keine Elemente, die ausgetauscht werden können, und die Sortierung endet
Schlechteste Zeitkomplexität: (O(n^2))
Stabilität: Stabil
Auswahlsortierung
Auswahlsortierung ist ein einfacher und intuitiver Sortieralgorithmus. So funktioniert es. Suchen Sie zunächst das kleinste (große) Element in der unsortierten Sequenz und speichern Sie es am Anfang der sortierten Sequenz. Suchen Sie dann weiterhin das kleinste (große) Element aus den verbleibenden unsortierten Elementen und fügen Sie es dann am Ende der sortierten Sequenz ein sortierte Reihenfolge. Und so weiter, bis alle Elemente sortiert sind.
Einfügesortierung
Einfügesortierung erstellt eine geordnete Sequenz. Scannen Sie bei unsortierten Daten die sortierte Sequenz von hinten nach vorne, um die entsprechende Position zu finden und einzufügen. Bei der Implementierung der Einfügungssortierung müssen die sortierten Elemente während des Scanvorgangs von hinten nach vorne wiederholt und schrittweise nach hinten verschoben werden, um Einfügungsraum für die neuesten Elemente zu schaffen.
 

def insert_sort(alist):
"""
插入排序
"""
n = len(alist)
if n <= 1:
return alist
# 从第二个位置,即下表为1的元素开始向前插入
for i in range(1, n):
j = i
# 向前向前比较,如果小于前一个元素,交换两个元素
while alist[j] < alist[j-1] and j > 0:
alist[j], alist[j-1] = alist[j-1], alist[j]
j-=1
return alistKomplexität und Stabilität
Optimale zeitliche Komplexität: O((n)) (aufsteigende Anordnung, die Reihenfolge ist bereits in aufsteigender Reihenfolge)
Schlechteste Zeitkomplexität: O((n^2))
Stabilität: Stabil
Shell Sort
Shell Sort ist eine Verbesserung der Einfügungssortierung und die Sortierung ist nicht stabil. Bei der Hill-Sortierung werden Datensätze nach einem bestimmten Inkrement des Indexes gruppiert und jede Gruppe mithilfe des Direkteinfügungssortieralgorithmus sortiert. Mit zunehmender Inkrementierung enthält jede Gruppe immer mehr Schlüsselwörter auf 1 reduziert, die gesamte Datei in eine Gruppe aufgeteilt und der Algorithmus beendet.
def shell_sort(alist): n = len(alist) gap = n//2 # gap 变化到0之前,插入算法之行的次数 while gap > 0: # 希尔排序, 与普通的插入算法的区别就是gap步长 for i in range(gap,n): j = i while alist[j] < alist[j-gap] and j > 0: alist[j], alist[j-gap] = alist[j-gap], alist[j] j-=gap gap = gap//2 return alist
Komplexität und Stabilität
Optimale zeitliche Komplexität: (O(n^{1.3})) (muss nicht bestellt werden)
Schlechteste Zeitkomplexität: (O(n^2))
Stabilität: instabil
Schnellsortierung
Quicksort (Quicksort) teilt die zu sortierenden Daten in einem Sortierdurchgang in zwei unabhängige Teile auf. Alle Daten in einem Teil sind kleiner als alle Daten im anderen Teil. Anschließend wird diese Methode zum schnellen Sortieren verwendet Die beiden Teile der Daten können jeweils rekursiv sortiert werden, sodass die gesamten Daten zu einer geordneten Sequenz werden.
Die Schritte sind:
Wählen Sie ein Element aus der Sequenz aus, das als „Pivot“ bezeichnet wird.
Re In a Sortierte Reihenfolge: Alle Elemente, die kleiner als der Basiswert sind, werden vor der Basis platziert, und alle Elemente, die größer als der Basiswert sind, werden hinter der Basis platziert (auf beiden Seiten kann die gleiche Zahl stehen). Nach dieser Partition befindet sich das Datum in der Mitte der Sequenz. Dies wird als Partitionsvorgang bezeichnet.
Sortieren Sie rekursiv das Subarray der Elemente, die kleiner als der Basiswert sind, und das Subarray der Elemente, die größer als der Basiswert sind.
Der unterste Fall der Rekursion liegt vor, wenn die Größe der Sequenz Null oder Eins ist, das heißt, sie wurde immer sortiert. Obwohl er weiterhin rekursiv ist, wird dieser Algorithmus immer enden, da er in jeder Iteration (Iteration) mindestens ein Element an seine endgültige Position bringt.
Vergleich der Effizienz gängiger Sortieralgorithmen
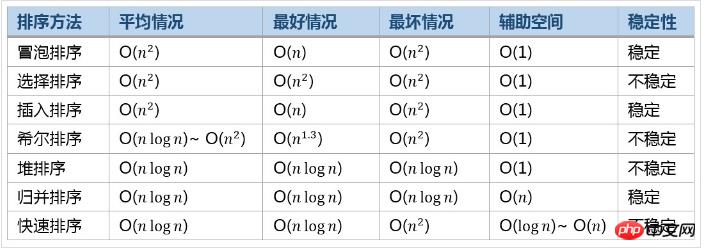 

Das obige ist der detaillierte Inhalt vonTeilen Sie häufig verwendete Sortierbeispiele in Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1378
1378
 52
52

 Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Der 2-stündige Python-Plan: ein realistischer Ansatz
Apr 11, 2025 am 12:04 AM
Sie können grundlegende Programmierkonzepte und Fähigkeiten von Python innerhalb von 2 Stunden lernen. 1. Lernen Sie Variablen und Datentypen, 2. Master Control Flow (bedingte Anweisungen und Schleifen), 3.. Verstehen Sie die Definition und Verwendung von Funktionen, 4. Beginnen Sie schnell mit der Python -Programmierung durch einfache Beispiele und Code -Snippets.
 Python: Erforschen der primären Anwendungen
Apr 10, 2025 am 09:41 AM
Python: Erforschen der primären Anwendungen
Apr 10, 2025 am 09:41 AM
Python wird in den Bereichen Webentwicklung, Datenwissenschaft, maschinelles Lernen, Automatisierung und Skripten häufig verwendet. 1) In der Webentwicklung vereinfachen Django und Flask Frameworks den Entwicklungsprozess. 2) In den Bereichen Datenwissenschaft und maschinelles Lernen bieten Numpy-, Pandas-, Scikit-Learn- und TensorFlow-Bibliotheken eine starke Unterstützung. 3) In Bezug auf Automatisierung und Skript ist Python für Aufgaben wie automatisiertes Test und Systemmanagement geeignet.
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Wie man AWS -Kleber mit Amazon Athena verwendet
Apr 09, 2025 pm 03:09 PM
Wie man AWS -Kleber mit Amazon Athena verwendet
Apr 09, 2025 pm 03:09 PM
Als Datenprofi müssen Sie große Datenmengen aus verschiedenen Quellen verarbeiten. Dies kann Herausforderungen für das Datenmanagement und die Analyse darstellen. Glücklicherweise können zwei AWS -Dienste helfen: AWS -Kleber und Amazon Athena.
 So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
So starten Sie den Server mit Redis
Apr 10, 2025 pm 08:12 PM
Zu den Schritten zum Starten eines Redis -Servers gehören: Installieren von Redis gemäß dem Betriebssystem. Starten Sie den Redis-Dienst über Redis-Server (Linux/macOS) oder redis-server.exe (Windows). Verwenden Sie den Befehl redis-cli ping (linux/macOS) oder redis-cli.exe ping (Windows), um den Dienststatus zu überprüfen. Verwenden Sie einen Redis-Client wie Redis-Cli, Python oder Node.js, um auf den Server zuzugreifen.
 So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
So lesen Sie Redis -Warteschlange
Apr 10, 2025 pm 10:12 PM
Um eine Warteschlange aus Redis zu lesen, müssen Sie den Warteschlangenname erhalten, die Elemente mit dem Befehl LPOP lesen und die leere Warteschlange verarbeiten. Die spezifischen Schritte sind wie folgt: Holen Sie sich den Warteschlangenname: Nennen Sie ihn mit dem Präfix von "Warteschlange:" wie "Warteschlangen: My-Queue". Verwenden Sie den Befehl LPOP: Wischen Sie das Element aus dem Kopf der Warteschlange aus und geben Sie seinen Wert zurück, z. B. die LPOP-Warteschlange: my-queue. Verarbeitung leerer Warteschlangen: Wenn die Warteschlange leer ist, gibt LPOP NIL zurück, und Sie können überprüfen, ob die Warteschlange existiert, bevor Sie das Element lesen.
 So sehen Sie die Serverversion von Redis
Apr 10, 2025 pm 01:27 PM
So sehen Sie die Serverversion von Redis
Apr 10, 2025 pm 01:27 PM
FRAGE: Wie kann man die Redis -Server -Version anzeigen? Verwenden Sie das Befehlszeilen-Tool-REDIS-CLI-Verssion, um die Version des angeschlossenen Servers anzuzeigen. Verwenden Sie den Befehl "Info Server", um die interne Version des Servers anzuzeigen, und muss Informationen analysieren und zurückgeben. Überprüfen Sie in einer Cluster -Umgebung die Versionskonsistenz jedes Knotens und können automatisch mit Skripten überprüft werden. Verwenden Sie Skripte, um die Anzeigeversionen zu automatisieren, z. B. eine Verbindung mit Python -Skripten und Druckversionsinformationen.
 Wie sicher ist Navicats Passwort?
Apr 08, 2025 pm 09:24 PM
Wie sicher ist Navicats Passwort?
Apr 08, 2025 pm 09:24 PM
Die Kennwortsicherheit von Navicat beruht auf der Kombination aus symmetrischer Verschlüsselung, Kennwortstärke und Sicherheitsmaßnahmen. Zu den spezifischen Maßnahmen gehören: Verwenden von SSL -Verbindungen (vorausgesetzt, dass der Datenbankserver das Zertifikat unterstützt und korrekt konfiguriert), die Navicat regelmäßig Aktualisierung unter Verwendung von sichereren Methoden (z. B. SSH -Tunneln), die Einschränkung von Zugriffsrechten und vor allem niemals Kennwörter aufzeichnen.
