

Bei der ersten Verwendung des Scrapy-Frameworks bin ich beharrlich auf der Suche und Änderung gestoßen Der Code kann diese Frage lösen. Dieses Mal haben wir die neuesten Emoticon-Bilder einer DouTu-Website gecrawlt. Wir haben die Verwendung des Scrapy-Frameworks geübt und einen zufälligen Benutzeragenten verwendet, um ein Verbot zu verhindern Insgesamt werden etwa 50.000 Ausdrücke auf der Festplatte gespeichert. Um Zeit zu sparen, habe ich mehr als 10.000 Bilder aufgenommen.
Scrapy ist ein Anwendungsframework, das zum Crawlen von Website-Daten und zum Extrahieren von Strukturdaten geschrieben wurde. Es kann in einer Reihe von Programmen verwendet werden, darunter Data Mining, Informationsverarbeitung oder Speicherung historischer Daten.
Erstellen Sie ein Scrapy-Projekt mit dem Prozess
Definieren Sie das extrahierte Element
Schreiben Sie einen Spider, um die Website zu crawlen und Artikel zu extrahieren
Schreiben Sie eine Item-Pipeline, um den extrahierten Artikel (d. h. Daten) zu speichern
Das folgende Diagramm zeigt die Architektur von Scrapy, einschließlich einer Übersicht über die Komponenten und Datenflüsse, die im System auftreten (dargestellt durch den grünen Pfeil). Nachfolgend finden Sie eine kurze Einführung zu jeder Komponente mit Links zu detaillierten Inhalten. Der Datenfluss wird unten beschrieben
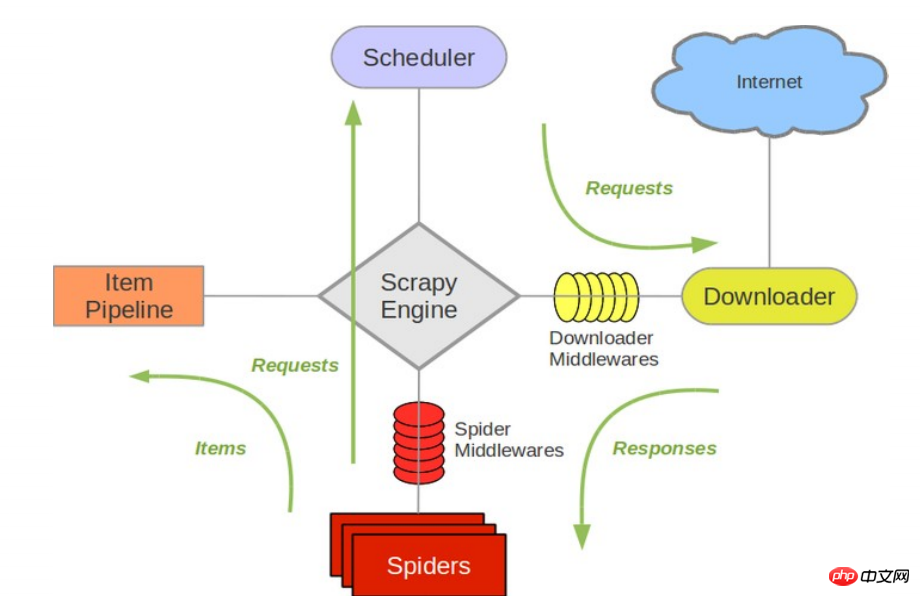
Komponenten
Scrapy Engine
Die Engine ist dafür verantwortlich, den Datenfluss durch alle Komponenten im System zu steuern und Ereignisse auszulösen, wenn entsprechende Aktionen stattfinden. Weitere Informationen finden Sie im Abschnitt „Datenfluss“ weiter unten.
Scheduler
Der Scheduler akzeptiert Anfragen von der Engine und stellt sie in die Warteschlange, damit sie der Engine bereitgestellt werden können, wenn die Engine sie später anfordert.
Downloader
Der Downloader ist dafür verantwortlich, Seitendaten abzurufen und sie der Engine und dann dem Spider bereitzustellen.
Spiders
Spider ist eine von Scrapy-Benutzern geschriebene Klasse, um die Antwort zu analysieren und das Element (d. h. das erhaltene Element) oder eine zusätzliche Folge-URL zu extrahieren. Jeder Spider ist für die Verarbeitung einer bestimmten (oder einiger weniger) Websites verantwortlich. Weitere Informationen finden Sie unter Spinnen.
Item Pipeline
Item Pipeline ist für die Verarbeitung der von der Spinne extrahierten Elemente verantwortlich. Typische Prozesse umfassen Bereinigung, Validierung und Persistenz (z. B. Zugriff auf eine Datenbank). Weitere Informationen finden Sie unter Artikelpipeline.
Downloader-Middleware
Downloader-Middleware ist ein spezifischer Hook zwischen der Engine und dem Downloader, der die vom Downloader an die Engine übergebene Antwort verarbeitet. Es bietet einen einfachen Mechanismus zum Erweitern der Scrapy-Funktionalität durch Einfügen von benutzerdefiniertem Code. Weitere Informationen finden Sie unter Downloader-Middleware.
Spider-Middlewares
Spider-Middleware ist eine spezifische Schnittstelle zwischen der Engine und Spider, die die Eingabe (Antwort) und Ausgabe (Elemente und Anfragen) verarbeitet. Es bietet einen einfachen Mechanismus zum Erweitern der Scrapy-Funktionalität durch Einfügen von benutzerdefiniertem Code. Weitere Informationen finden Sie unter Spider-Middleware (Middleware).
1. Nach Eingabe des neuesten Dou Tu-Emoticons auf der Homepage lautet die URL Seite, Sie werden sehen, dass die URL wird, dann kennen wir die Zusammensetzung der URL. Die letzte Seite ist die Anzahl der verschiedenen Seiten. Dann wird der Starteintrag start_urls in Spider wie folgt definiert und 1 bis 20 Seiten mit Bildausdrücken gecrawlt. Wenn Sie weitere Emoticon-Seiten herunterladen möchten, können Sie weitere hinzufügen.
start_urls = ['https://www.doutula.com/photo/list/?page={}'.format(i) for i in range(1, 20)]2. Wechseln Sie in den Entwicklermodus, um die Struktur der Webseite zu analysieren. Klicken Sie mit der rechten Maustaste und kopieren Sie die XPath-Adresse, um den Tag-Inhalt zu erhalten, in dem sich alle Ausdrücke befinden. a[1] stellt das erste a dar, und das Entfernen von [1] ist alles a.
//*[@id="pic-detail"]/div/div[1]/div[2]/a
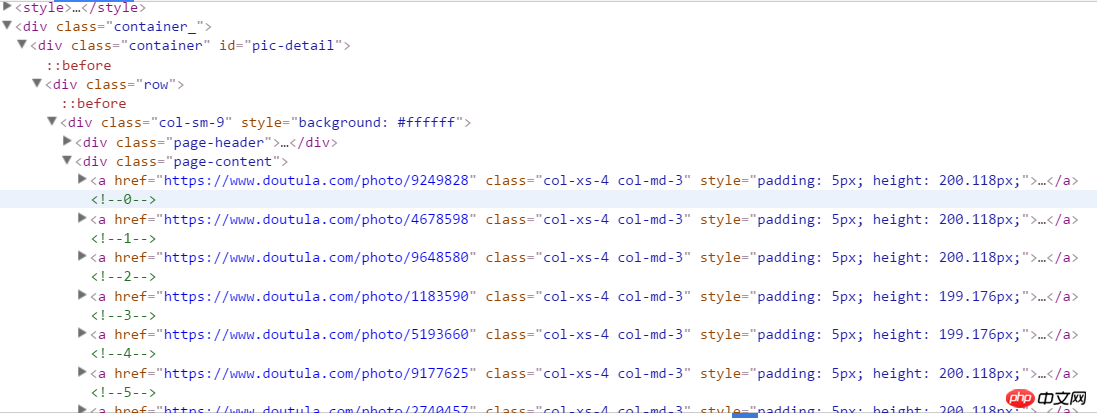
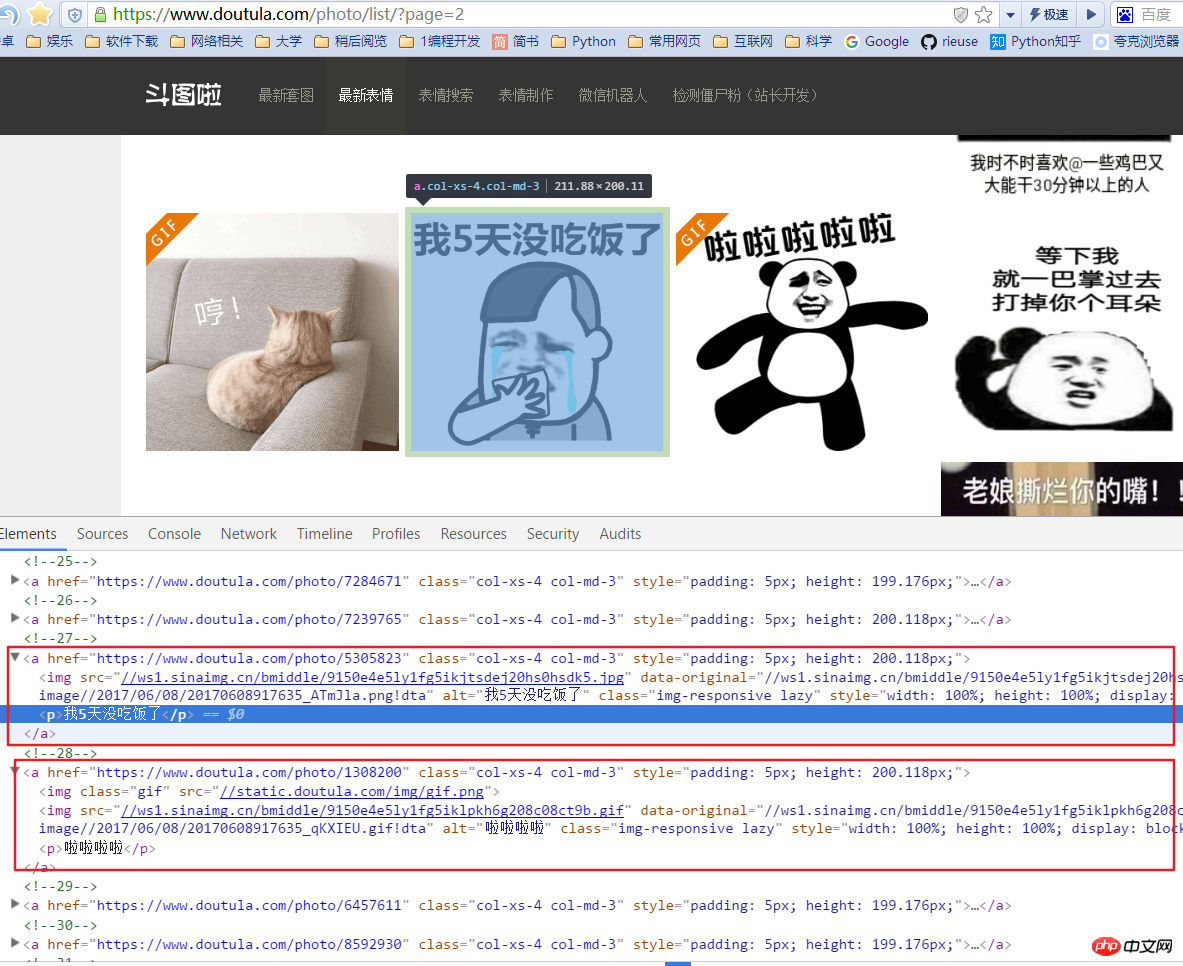
Es ist erwähnenswert, dass es hier zwei Arten von Ausdrücken gibt: einen jpg und einen GIF-Bild. Wenn Sie beim Abrufen der Bildadresse nur den Quellcode des ersten Bilds unter dem Tag a abrufen, tritt ein Fehler auf. Daher müssen wir den ursprünglichen Datenwert im Bild abrufen. Hier befindet sich unter dem a-Tag ein p-Tag, das die Bildeinführung darstellt, und wir verwenden es auch als Namen der Bilddatei.
图片的连接是 'http:' + content.xpath('//img/@data-original') 图片的名称是 content.xpath('//p/text()')
完整代码地址 github.com/rieuse/learnPython
1.首先使用命令行工具输入代码创建一个新的Scrapy项目,之后创建一个爬虫。
scrapy startproject ScrapyDoutu cd ScrapyDoutu\ScrapyDoutu\spidersscrapy genspider doutula doutula.com
2.打开Doutu文件夹中的items.py,改为以下代码,定义我们爬取的项目。
import scrapyclass DoutuItem(scrapy.Item):
img_url = scrapy.Field()
name = scrapy.Field()3.打开spiders文件夹中的doutula.py,改为以下代码,这个是爬虫主程序。
# -*- coding: utf-8 -*-
import os
import scrapy
import requestsfrom ScrapyDoutu.items import DoutuItems
class Doutu(scrapy.Spider):
name = "doutu"
allowed_domains = ["doutula.com", "sinaimg.cn"]
start_urls = ['https://www.doutula.com/photo/list/?page={}'.format(i) for i in range(1, 40)] # 我们暂且爬取40页图片
def parse(self, response):
i = 0for content in response.xpath('//*[@id="pic-detail"]/div/div[1]/div[2]/a'):
i += 1item = DoutuItems()item['img_url'] = 'http:' + content.xpath('//img/@data-original').extract()[i]item['name'] = content.xpath('//p/text()').extract()[i]try:if not os.path.exists('doutu'):
os.makedirs('doutu')
r = requests.get(item['img_url'])
filename = 'doutu\\{}'.format(item['name']) + item['img_url'][-4:]with open(filename, 'wb') as fo:
fo.write(r.content)
except:
print('Error')
yield item3.这里面有很多值得注意的部分:
因为图片的地址是放在sinaimg.cn中,所以要加入allowed_domains的列表中
content.xpath('//img/@data-original').extract()[i]中extract()用来返回一个list(就是系统自带的那个) 里面是一些你提取的内容,[i]是结合前面的i的循环每次获取下一个标签内容,如果不这样设置,就会把全部的标签内容放入一个字典的值中。
filename = 'doutu\{}'.format(item['name']) + item['img_url'][-4:] 是用来获取图片的名称,最后item['img_url'][-4:]是获取图片地址的最后四位这样就可以保证不同的文件格式使用各自的后缀。
最后一点就是如果xpath没有正确匹配,则会出现
4.配置settings.py,如果想抓取快一点CONCURRENT_REQUESTS设置大一些,DOWNLOAD_DELAY设置小一些,或者为0.
# -*- coding: utf-8 -*-BOT_NAME = 'ScrapyDoutu'SPIDER_MODULES = ['ScrapyDoutu.spiders']NEWSPIDER_MODULE = 'ScrapyDoutu.spiders'DOWNLOADER_MIDDLEWARES = {
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None,
'ScrapyDoutu.middlewares.RotateUserAgentMiddleware': 400,
}ROBOTSTXT_OBEY = False # 不遵循网站的robots.txt策略CONCURRENT_REQUESTS = 16 #Scrapy downloader 并发请求(concurrent requests)的最大值DOWNLOAD_DELAY = 0.2 # 下载同一个网站页面前等待的时间,可以用来限制爬取速度减轻服务器压力。COOKIES_ENABLED = False # 关闭cookies5.配置middleware.py配合settings中的UA设置可以在下载中随机选择UA有一定的反ban效果,在原有代码基础上加入下面代码。这里的user_agent_list可以加入更多。
import randomfrom scrapy.downloadermiddlewares.useragent import UserAgentMiddlewareclass RotateUserAgentMiddleware(UserAgentMiddleware):
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
ua = random.choice(self.user_agent_list)
if ua:
print(ua)
request.headers.setdefault('User-Agent', ua)
user_agent_list = [
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3",
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3",
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]6.到现在为止,代码都已经完成了。那么开始执行吧!scrapy crawl doutu
之后可以看到一边下载,一边修改User Agent。
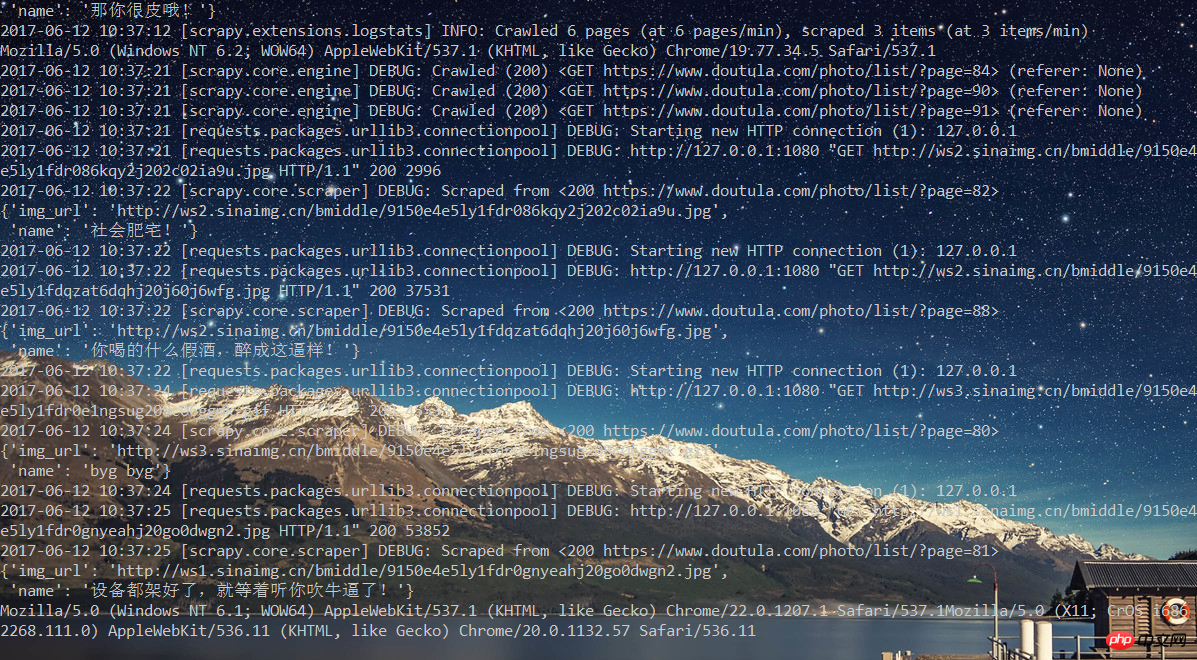
学习使用Scrapy遇到很多坑,但是强大的搜索系统不会让我感觉孤单。所以感觉Scrapy还是很强大的也很意思,后面继续学习Scrapy的其他方面内容。
Das obige ist der detaillierte Inhalt vonWie erhalte ich die neuesten Emoticons von DouTu.com?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 wie man eine Website erstellt
wie man eine Website erstellt
 Quellcode der Website
Quellcode der Website
 So blockieren Sie eine Website
So blockieren Sie eine Website
 Nodejs implementiert Crawler
Nodejs implementiert Crawler
 Was sind die kostenlosen Crawler-Tools?
Was sind die kostenlosen Crawler-Tools?
 Gängige Methoden zur Erkennung von Website-Schwachstellen
Gängige Methoden zur Erkennung von Website-Schwachstellen
 Empfohlene Datenanalyse-Websites
Empfohlene Datenanalyse-Websites
 Gründe, warum der Windows-Drucker nicht druckt
Gründe, warum der Windows-Drucker nicht druckt
 So bereinigen Sie das Laufwerk C Ihres Computers, wenn es voll ist
So bereinigen Sie das Laufwerk C Ihres Computers, wenn es voll ist








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



