

Wie macht man einen guten Webcrawler?

Das Wesen von Webcrawlern besteht eigentlich darin, Daten aus dem Internet zu „stehlen“. Durch Webcrawler können wir die benötigten Ressourcen sammeln, aber auch eine unsachgemäße Verwendung kann zu ernsthaften Problemen führen.
Daher müssen wir beim Einsatz von Webcrawlern in der Lage sein, „auf die richtige Art und Weise zu stehlen“.
Webcrawler werden hauptsächlich in die folgenden drei Kategorien unterteilt:
1. Kleiner Maßstab, kleine Datenmenge und unempfindliche Crawling-Geschwindigkeit; Dafür können wir die Requests-Bibliothek verwenden, um Webcrawler zu implementieren, die hauptsächlich zum Crawlen von Webseiten verwendet werden.
2 Kann die Scrapy-Bibliothek verwenden, die hauptsächlich zum Crawlen von Websites oder einer Reihe von Websites verwendet wird das gesamte Netzwerk, normalerweise zum Aufbau des gesamten Netzwerks Suchmaschinen wie Baidu, Google-Suche usw.
Von diesen drei Typen ist der erste der häufigste, und die meisten von ihnen sind kleine Crawler, die Webseiten crawlen.
Es gibt auch viele Einwände gegen Webcrawler. Da Webcrawler ständig Anfragen an den Server senden, beeinträchtigt dies die Serverleistung, verursacht Belästigungen für den Server und erhöht die Arbeitsbelastung der Website-Betreuer.
Neben der Belästigung von Servern können Webcrawler auch rechtliche Risiken mit sich bringen.Da die Daten auf dem Server Eigentumsrechte haben, birgt die gewinnorientierte Nutzung der Daten rechtliche Risiken. Darüber hinaus können Webcrawler auch zu Datenschutzverletzungen bei den Benutzern führen.
Kurz gesagt, das Risiko von Webcrawlern ergibt sich hauptsächlich aus den folgenden drei Punkten:
- Leistung des Servers Belästigung
- Rechtliche Risiken auf inhaltlicher Ebene
- Verletzung der Privatsphäre
- Daher Web Crawler Die Nutzung erfordert bestimmte Regeln.
In der Praxis haben einige größere Websites den Webcrawlern entsprechende Einschränkungen auferlegt, und Webcrawler gelten auch im gesamten Internet als standardisierbare Funktion.
Für allgemeine Server können wir Webcrawler auf zwei Arten einschränken: 1. Wenn der Eigentümer der Website über bestimmte technische Fähigkeiten verfügt Begrenzen Sie Webcrawler durch Quellenüberprüfung.
Die Quellenüberprüfung führt im Allgemeinen zu Einschränkungen durch die Beurteilung von User-Agent. Dieser Artikel konzentriert sich auf den zweiten Typ.
2. Verwenden Sie das Robots-Protokoll, um Webcrawlern die Regeln mitzuteilen, die sie einhalten müssen, welche Regeln gecrawlt werden können und welche nicht, und um von allen Crawlern die Einhaltung dieses Protokolls zu verlangen.
Die zweite Methode besteht darin, in Form einer Bekanntmachung darüber zu informieren, dass die Robots-Vereinbarung zwar empfohlen, aber nicht bindend ist, es aber möglicherweise rechtliche Risiken gibt. Durch diese beiden Methoden werden im Internet wirksame moralische und technische Beschränkungen für Webcrawler gebildet.
Dann
wenn wir einen Webcrawler schreiben, müssen wir die Verwaltung der Website-Ressourcen durch die Website-Betreuer respektieren.Im Internet verfügen einige Websites nicht über das Robots-Protokoll und alle Daten können gecrawlt werden. Die überwiegende Mehrheit der Mainstream-Websites unterstützt jedoch das Robots-Protokoll und unterliegt den entsprechenden Einschränkungen Einführung in die grundlegende Syntax des Robots-Protokolls.
Robots-Protokoll (Robots Exclusion Standard, Web-Crawler-Ausschlussstandard): Funktion: Die Website teilt Webcrawlern mit, welche Seiten gecrawlt werden können und welche nein.
Formular: robots.txt-Datei im Stammverzeichnis der Website.
Grundlegende Syntax des Robots-Protokolls: * steht für alles, / steht für das Stammverzeichnis.
Zum Beispiel das Robots-Protokoll von PMCAFF:
Benutzeragent: *Disallow: /article/edit
Disallow: /discuss/write
Disallow: /discuss/edit
in Zeile 1 Benutzer -agent:* bedeutet, dass alle Webcrawler die folgenden Protokolle einhalten müssen;
Disallow: /article/edit in Zeile 2 bedeutet, dass alle Webcrawler nicht auf Artikel unter Artikel/Bearbeiten zugreifen dürfen das Gleiche gilt auch für andere.
Wenn Sie das Robots-Protokoll von JD.com beachten, können Sie sehen, dass es den Benutzeragenten EtaoSpider, Disallow: / gibt, wobei EtaoSpider ein böswilliger Crawler ist und keine Ressourcen von JD.com crawlen darf.
Benutzeragent: *Nicht zulassen: /?*
Nicht zulassen: /pop /*.html
Disallow: /pinpai/*.html?*
User-agent: EtaoSpider
Nicht zulassen: /
Benutzeragent: HuihuiSpider
Nicht zulassen: /
Benutzeragent: GwdangSpider
Nicht zulassen: /
Benutzeragent: WochachaSpider
Nicht zulassen: /
Mit dem Robots-Protokoll können Sie den Inhalt der Website regulieren und allen Webcrawlern mitteilen, welche gecrawlt werden dürfen und welche nicht.
Es ist wichtig zu beachten, dass das Robots-Protokoll im Stammverzeichnis vorhanden ist. Verschiedene Stammverzeichnisse können unterschiedliche Robots-Protokolle haben , daher müssen Sie beim Crawlen mehr Aufmerksamkeit schenken.
Das obige ist der detaillierte Inhalt vonWie macht man einen guten Webcrawler?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

![WLAN-Erweiterungsmodul ist gestoppt [Fix]](https://img.php.cn/upload/article/000/465/014/170832352052603.gif?x-oss-process=image/resize,m_fill,h_207,w_330) WLAN-Erweiterungsmodul ist gestoppt [Fix]
Feb 19, 2024 pm 02:18 PM
WLAN-Erweiterungsmodul ist gestoppt [Fix]
Feb 19, 2024 pm 02:18 PM
Wenn es ein Problem mit dem WLAN-Erweiterungsmodul Ihres Windows-Computers gibt, kann dies dazu führen, dass Sie nicht mehr mit dem Internet verbunden sind. Diese Situation ist oft frustrierend, aber glücklicherweise enthält dieser Artikel einige einfache Vorschläge, die Ihnen helfen können, dieses Problem zu lösen und Ihre drahtlose Verbindung wieder ordnungsgemäß funktionieren zu lassen. Behebung, dass das WLAN-Erweiterbarkeitsmodul nicht mehr funktioniert Wenn das WLAN-Erweiterbarkeitsmodul auf Ihrem Windows-Computer nicht mehr funktioniert, befolgen Sie diese Vorschläge, um das Problem zu beheben: Führen Sie die Netzwerk- und Internet-Fehlerbehebung aus, um drahtlose Netzwerkverbindungen zu deaktivieren und wieder zu aktivieren. Starten Sie den WLAN-Autokonfigurationsdienst neu. Ändern Sie die Energieoptionen. Ändern Erweiterte Energieeinstellungen Netzwerkadaptertreiber neu installieren Einige Netzwerkbefehle ausführen Schauen wir uns das nun im Detail an
 So beheben Sie einen Win11-DNS-Serverfehler
Jan 10, 2024 pm 09:02 PM
So beheben Sie einen Win11-DNS-Serverfehler
Jan 10, 2024 pm 09:02 PM
Um auf das Internet zuzugreifen, müssen wir beim Herstellen einer Verbindung zum Internet das richtige DNS verwenden. Wenn wir die falschen DNS-Einstellungen verwenden, wird auf die gleiche Weise ein DNS-Serverfehler angezeigt. Zu diesem Zeitpunkt können wir versuchen, das Problem zu lösen, indem wir in den Netzwerkeinstellungen auswählen, ob DNS automatisch abgerufen werden soll Lösungen. So beheben Sie den Win11-Netzwerk-DNS-Serverfehler. Methode 1: DNS zurücksetzen 1. Klicken Sie zunächst in der Taskleiste auf „Start“, suchen Sie die Symbolschaltfläche „Einstellungen“ und klicken Sie darauf. 2. Klicken Sie dann in der linken Spalte auf den Optionsbefehl „Netzwerk & Internet“. 3. Suchen Sie dann rechts die Option „Ethernet“ und klicken Sie zur Eingabe. 4. Klicken Sie anschließend in der DNS-Serverzuweisung auf „Bearbeiten“ und stellen Sie schließlich DNS auf „Automatisch (D.)“ ein
 Beheben Sie „fehlgeschlagene Netzwerkfehler'-Downloads auf Chrome, Google Drive und Fotos!
Oct 27, 2023 pm 11:13 PM
Beheben Sie „fehlgeschlagene Netzwerkfehler'-Downloads auf Chrome, Google Drive und Fotos!
Oct 27, 2023 pm 11:13 PM
Was ist das Problem „Download aufgrund eines Netzwerkfehlers fehlgeschlagen“? Bevor wir uns mit den Lösungen befassen, wollen wir zunächst verstehen, was das Problem „Netzwerkfehler-Download fehlgeschlagen“ bedeutet. Dieser Fehler tritt normalerweise auf, wenn die Netzwerkverbindung während des Downloads unterbrochen wird. Dies kann verschiedene Gründe haben, wie z. B. eine schwache Internetverbindung, Netzwerküberlastung oder Serverprobleme. Wenn dieser Fehler auftritt, wird der Download gestoppt und eine Fehlermeldung angezeigt. Wie kann ein fehlgeschlagener Download mit Netzwerkfehler behoben werden? Die Meldung „Netzwerkfehler beim Herunterladen fehlgeschlagen“ kann beim Zugriff auf oder beim Herunterladen erforderlicher Dateien zu einem Hindernis werden. Unabhängig davon, ob Sie Browser wie Chrome oder Plattformen wie Google Drive und Google Fotos verwenden, wird dieser Fehler auftreten und Unannehmlichkeiten verursachen. Nachfolgend finden Sie Punkte, die Ihnen bei der Navigation und Lösung dieses Problems helfen sollen
 Fix: WD My Cloud wird unter Windows 11 nicht im Netzwerk angezeigt
Oct 02, 2023 pm 11:21 PM
Fix: WD My Cloud wird unter Windows 11 nicht im Netzwerk angezeigt
Oct 02, 2023 pm 11:21 PM
Wenn WDMyCloud unter Windows 11 nicht im Netzwerk angezeigt wird, kann dies ein großes Problem sein, insbesondere wenn Sie Backups oder andere wichtige Dateien darin speichern. Dies kann ein großes Problem für Benutzer sein, die häufig auf Netzwerkspeicher zugreifen müssen. In der heutigen Anleitung zeigen wir Ihnen daher, wie Sie dieses Problem dauerhaft beheben können. Warum wird WDMyCloud nicht im Windows 11-Netzwerk angezeigt? Ihr MyCloud-Gerät, Ihr Netzwerkadapter oder Ihre Internetverbindung sind nicht richtig konfiguriert. Die SMB-Funktion ist nicht auf dem Computer installiert. Dieses Problem kann manchmal durch einen vorübergehenden Fehler in Winsock verursacht werden. Was soll ich tun, wenn meine Cloud nicht im Netzwerk angezeigt wird? Bevor wir mit der Behebung des Problems beginnen, können Sie einige Vorprüfungen durchführen:
 Was soll ich tun, wenn die Erde in der unteren rechten Ecke von Windows 10 angezeigt wird, wenn ich nicht auf das Internet zugreifen kann? Verschiedene Lösungen für das Problem, dass die Erde in Win10 nicht auf das Internet zugreifen kann
Feb 29, 2024 am 09:52 AM
Was soll ich tun, wenn die Erde in der unteren rechten Ecke von Windows 10 angezeigt wird, wenn ich nicht auf das Internet zugreifen kann? Verschiedene Lösungen für das Problem, dass die Erde in Win10 nicht auf das Internet zugreifen kann
Feb 29, 2024 am 09:52 AM
In diesem Artikel wird die Lösung für das Problem vorgestellt, dass das Globussymbol im Win10-Systemnetzwerk angezeigt wird, aber nicht auf das Internet zugreifen kann. Der Artikel enthält detaillierte Schritte, die den Lesern helfen sollen, das Problem des Win10-Netzwerks zu lösen, das zeigt, dass die Erde keinen Zugriff auf das Internet hat. Methode 1: Direkt neu starten. Überprüfen Sie zunächst, ob das Netzwerkkabel nicht richtig eingesteckt ist und ob das Breitband im Rückstand ist. In diesem Fall müssen Sie den Router oder das optische Modem neu starten. Wenn auf dem Computer keine wichtigen Dinge erledigt werden, können Sie den Computer direkt neu starten. Die meisten kleineren Probleme können durch einen Neustart des Computers schnell behoben werden. Wenn festgestellt wird, dass die Breitbandanbindung nicht im Rückstand ist und das Netzwerk normal ist, ist das eine andere Sache. Methode 2: 1. Drücken Sie die [Win]-Taste oder klicken Sie auf [Startmenü] in der unteren linken Ecke. Klicken Sie im sich öffnenden Menüelement auf das Zahnradsymbol über dem Netzschalter.
 Überprüfen Sie die Netzwerkverbindung: lol kann keine Verbindung zum Server herstellen
Feb 19, 2024 pm 12:10 PM
Überprüfen Sie die Netzwerkverbindung: lol kann keine Verbindung zum Server herstellen
Feb 19, 2024 pm 12:10 PM
LOL kann keine Verbindung zum Server herstellen. Bitte überprüfen Sie das Netzwerk. In den letzten Jahren sind Online-Spiele für viele Menschen zu einer täglichen Unterhaltungsaktivität geworden. Unter ihnen ist League of Legends (LOL) ein sehr beliebtes Multiplayer-Onlinespiel, das die Teilnahme und das Interesse von Hunderten Millionen Spielern auf sich zieht. Wenn wir jedoch LOL spielen, stoßen wir manchmal auf die Fehlermeldung „Verbindung zum Server nicht möglich, bitte überprüfen Sie das Netzwerk“, was den Spielern zweifellos einige Probleme bereitet. Als nächstes werden wir die Ursachen und Lösungen dieses Fehlers besprechen. Zunächst besteht möglicherweise das Problem, dass LOL keine Verbindung zum Server herstellen kann
 Was passiert, wenn das Netzwerk keine Verbindung zum WLAN herstellen kann?
Apr 03, 2024 pm 12:11 PM
Was passiert, wenn das Netzwerk keine Verbindung zum WLAN herstellen kann?
Apr 03, 2024 pm 12:11 PM
1. Überprüfen Sie das WLAN-Passwort: Stellen Sie sicher, dass das von Ihnen eingegebene WLAN-Passwort korrekt ist und achten Sie auf die Groß-/Kleinschreibung. 2. Überprüfen Sie, ob das WLAN ordnungsgemäß funktioniert: Überprüfen Sie, ob der WLAN-Router normal funktioniert. Sie können andere Geräte an denselben Router anschließen, um festzustellen, ob das Problem beim Gerät liegt. 3. Starten Sie das Gerät und den Router neu: Manchmal liegt eine Fehlfunktion oder ein Netzwerkproblem mit dem Gerät oder Router vor, und ein Neustart des Geräts und des Routers kann das Problem lösen. 4. Überprüfen Sie die Geräteeinstellungen: Stellen Sie sicher, dass die WLAN-Funktion des Geräts eingeschaltet und die WLAN-Funktion nicht deaktiviert ist.
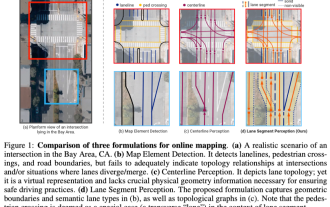 ICLR'24 neue Ideen ohne Bilder! LaneSegNet: Kartenlernen basierend auf dem Bewusstsein für die Spursegmentierung
Jan 19, 2024 am 11:12 AM
ICLR'24 neue Ideen ohne Bilder! LaneSegNet: Kartenlernen basierend auf dem Bewusstsein für die Spursegmentierung
Jan 19, 2024 am 11:12 AM
Oben geschrieben & Das persönliche Verständnis des Autors von Karten als Schlüsselinformationen für nachgelagerte Anwendungen autonomer Fahrsysteme wird normalerweise durch Fahrspuren oder Mittellinien dargestellt. Die vorhandene Literatur zum Kartenlernen konzentriert sich jedoch hauptsächlich auf die Erkennung geometriebasierter topologischer Beziehungen von Fahrspuren oder die Erfassung von Mittellinien. Beide Methoden ignorieren die inhärente Beziehung zwischen Fahrspurlinien und Mittellinien, das heißt, Fahrspurlinien binden Mittellinien. Obwohl die einfache Vorhersage zweier Fahrspurtypen in einem Modell sich im Lernziel gegenseitig ausschließt, schlägt dieser Artikel Fahrspursegment als eine neue Darstellung vor, die geometrische und topologische Informationen nahtlos kombiniert, und schlägt somit LaneSegNet vor. Dies ist das erste End-to-End-Kartierungsnetzwerk, das Fahrspursegmente generiert, um eine vollständige Darstellung der Straßenstruktur zu erhalten. LaneSegNet hat zwei Ebenen
