
 Backend-Entwicklung
Python-Tutorial
Probleme im Zusammenhang mit der Lösung von Crawler-Problemen
Backend-Entwicklung
Python-Tutorial
Probleme im Zusammenhang mit der Lösung von Crawler-Problemen
Probleme im Zusammenhang mit der Lösung von Crawler-Problemen
继续上一篇文章的内容,上一篇文章中已经将url管理器和下载器写好了。接下来就是url解析器,总的来说这个模块是几个模块中比较难的。因为通过下载器下载完页面之后,我们虽然得到了页面,但是这并不是我们想要的结果。而且由于页面的代码很多,我们很难去里面找到自己想要的数据。所幸,我们下载的是html页面,它是一种由多个多层次的节点组成的树型结构的文本文件。所以,相较于txt文件,我们更加容易定位到我们要找的数据块。现在我们要做的就是去原页面去分析一下,我们想要的数据到底在哪。
打开百度百科pyton词条的页面,然后按F12调出开发者工具。通过使用工具,我们就能定位到页面的内容:
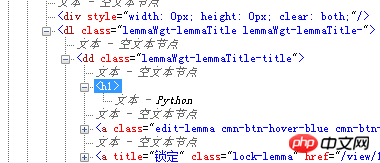

这样我们就找到了我们想要的信息处在哪个标签里了。
1 import bs4 2 import re 3 from urllib.parse import urljoin 4 class HtmlParser(object): 5 """docstring for HtmlParser""" 6 def _get_new_urls(self, url, soup): 7 new_urls = set() 8 links = soup.find_all('a', href = re.compile(r'/item/.')) 9 for link in links:10 new_url = re.sub(r'(/item/)(.*)', r'\1%s' % link.getText(), link['href'])11 new_full_url = urljoin(url, new_url)12 new_urls.add(new_full_url)13 return new_urls14 15 def _get_new_data(self, url, soup):16 res_data = {}17 #url18 res_data['url'] = url19 #<dd class="lemmaWgt-lemmaTitle-title">20 title_node = soup.find('dd', class_ = "lemmaWgt-lemmaTitle-title").find('h1')21 res_data['title'] = title_node.getText()22 #<div class="lemma-summary" label-module="lemmaSummary">23 summary_node = soup.find('div', class_ = "lemma-summary")24 res_data['summary'] = summary_node.getText()25 return res_data26 27 def parse(self, url, html_cont):28 if url is None or html_cont is None:29 return 30 soup = bs4.BeautifulSoup(html_cont, 'lxml')31 new_urls = self._get_new_urls(url, soup)32 new_data = self._get_new_data(url, soup)33 return new_urls, new_data解析器只有一个外部方法就是parse方法,
a.首先它会接受url, html_cont两个参数,然后进行判断页面内容是否为空
b.调用bs4模块的方法来解析网页内容,'lxml'为文档解析器,默认的为html.parser,bs官方推荐我们用lxml,那就听它的吧,谁让人家是官方呢。
c.接下来就是调用两个内部函数来获取新的url列表和数据
d.最后将url列表和数据返回
这里有一些注意点
1.bs的方法调用还有一个参数,from_encoding 这个和我在下载器那里的重复了,所以我就取消了,两个的功能是一样的。
2.获取url列表的内部方法,需要用到正则表达式,这里我也是摸着石头过河,不是很会,中间也调试过许多次。
3.数据是放在字典中的,这样可以通过key来增改删除数据。
最好,就直接数据输出了,这个比较简单,直接上代码。
1 class HtmlOutputer(object): 2 """docstring for HtmlOutputer""" 3 def __init__(self): 4 self.datas = [] 5 def collect_data(self, new_data): 6 if new_data is None: 7 return 8 self.datas.append(new_data) 9 def output_html(self):10 fout = open('output1.html', 'w', encoding = 'utf-8')11 fout.write('<html>')12 fout.write('<head><meta charset="utf-8"></head>')13 fout.write('<body>')14 fout.write('<table>')15 for data in self.datas:16 fout.write('<tr>')17 fout.write('<td>%s</td>' % data['url'])18 fout.write('<td>%s</td>' % data['title'])19 fout.write('<td>%s</td>' % data['summary'])20 fout.write('</tr>')21 fout.write('</table>')22 fout.write('</body>')23 fout.write('</html>')24 fout.close()这里也有两个注意点
1.fout = open('output1.html', 'w', encoding = 'utf-8'),这里的encoding参数一定要加,不然会报错,在windows平台,它默认是使用gbk编码来写文件的。
2.fout.write('
'),这里的meta标签也要加上,因为要告诉浏览器使用什么编码来渲染页面,这里我一开始没加弄了很久,我打开页面的内容,发现里面是中文的,结果浏览器展示的就是乱码。总的来说,因为整个页面采集过程结果好几个模块,所以编码问题要非常小心,不然少不留神就会出错。
最后总结,这段程序还有许多方面可以深入探讨:
1.页面的数据量过小,我尝试了10000个页面的爬取。一旦数据量剧增之后,就会带来一下问题,第一是待爬取url和已爬取url就不能放在set集合中了,要么放到radi缓存服务器里,要么放到mysql数据库中
2.第二,数据也是同样的,字典也满足不了了,需要专门的数据库来存放
3.第三量上去之后,对爬取效率就有要求了,那么多线程就要加进来
4.第四,一旦布置好任务,单台服务器的压力会过大,而且一旦宕机,风险很大,所以分布式的高可用架构也要跟上来
5.一方面是页面的内容过于简单,都是静态页面,不涉及登录,也不涉及ajax动态获取
6.这只是数据采集,后续还有建模,分析…………
综上所述,路还远的很呢,加油!
Das obige ist der detaillierte Inhalt vonProbleme im Zusammenhang mit der Lösung von Crawler-Problemen. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1375
1375
 52
52

 Was ist der Grund, warum PS immer wieder Laden zeigt?
Apr 06, 2025 pm 06:39 PM
Was ist der Grund, warum PS immer wieder Laden zeigt?
Apr 06, 2025 pm 06:39 PM
PS "Laden" Probleme werden durch Probleme mit Ressourcenzugriff oder Verarbeitungsproblemen verursacht: Die Lesegeschwindigkeit von Festplatten ist langsam oder schlecht: Verwenden Sie Crystaldiskinfo, um die Gesundheit der Festplatte zu überprüfen und die problematische Festplatte zu ersetzen. Unzureichender Speicher: Upgrade-Speicher, um die Anforderungen von PS nach hochauflösenden Bildern und komplexen Schichtverarbeitung zu erfüllen. Grafikkartentreiber sind veraltet oder beschädigt: Aktualisieren Sie die Treiber, um die Kommunikation zwischen PS und der Grafikkarte zu optimieren. Dateipfade sind zu lang oder Dateinamen haben Sonderzeichen: Verwenden Sie kurze Pfade und vermeiden Sie Sonderzeichen. Das eigene Problem von PS: Installieren oder reparieren Sie das PS -Installateur neu.
 Wie löst ich das Problem des Ladens beim Starten von PS?
Apr 06, 2025 pm 06:36 PM
Wie löst ich das Problem des Ladens beim Starten von PS?
Apr 06, 2025 pm 06:36 PM
Ein PS, der beim Booten auf "Laden" steckt, kann durch verschiedene Gründe verursacht werden: Deaktivieren Sie korrupte oder widersprüchliche Plugins. Eine beschädigte Konfigurationsdatei löschen oder umbenennen. Schließen Sie unnötige Programme oder aktualisieren Sie den Speicher, um einen unzureichenden Speicher zu vermeiden. Upgrade auf ein Solid-State-Laufwerk, um die Festplatte zu beschleunigen. PS neu installieren, um beschädigte Systemdateien oder ein Installationspaketprobleme zu reparieren. Fehlerinformationen während des Startprozesses der Fehlerprotokollanalyse anzeigen.
 Wie löste ich das Problem des Ladens, wenn die PS die Datei öffnet?
Apr 06, 2025 pm 06:33 PM
Wie löste ich das Problem des Ladens, wenn die PS die Datei öffnet?
Apr 06, 2025 pm 06:33 PM
Das Laden von Stottern tritt beim Öffnen einer Datei auf PS auf. Zu den Gründen gehören: zu große oder beschädigte Datei, unzureichender Speicher, langsame Festplattengeschwindigkeit, Probleme mit dem Grafikkarten-Treiber, PS-Version oder Plug-in-Konflikte. Die Lösungen sind: Überprüfen Sie die Dateigröße und -integrität, erhöhen Sie den Speicher, aktualisieren Sie die Festplatte, aktualisieren Sie den Grafikkartentreiber, deinstallieren oder deaktivieren Sie verdächtige Plug-Ins und installieren Sie PS. Dieses Problem kann effektiv gelöst werden, indem die PS -Leistungseinstellungen allmählich überprüft und genutzt wird und gute Dateimanagementgewohnheiten entwickelt werden.
 So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
So verwenden Sie MySQL nach der Installation
Apr 08, 2025 am 11:48 AM
Der Artikel führt den Betrieb der MySQL -Datenbank vor. Zunächst müssen Sie einen MySQL -Client wie MySQLworkBench oder Befehlszeilen -Client installieren. 1. Verwenden Sie den Befehl mySQL-uroot-P, um eine Verbindung zum Server herzustellen und sich mit dem Stammkonto-Passwort anzumelden. 2. Verwenden Sie die Erstellung von Createdatabase, um eine Datenbank zu erstellen, und verwenden Sie eine Datenbank aus. 3.. Verwenden Sie CreateTable, um eine Tabelle zu erstellen, Felder und Datentypen zu definieren. 4. Verwenden Sie InsertInto, um Daten einzulegen, Daten abzufragen, Daten nach Aktualisierung zu aktualisieren und Daten nach Löschen zu löschen. Nur indem Sie diese Schritte beherrschen, lernen, mit gemeinsamen Problemen umzugehen und die Datenbankleistung zu optimieren, können Sie MySQL effizient verwenden.
 Wie kontrolliert PS -Federn die Weichheit des Übergangs?
Apr 06, 2025 pm 07:33 PM
Wie kontrolliert PS -Federn die Weichheit des Übergangs?
Apr 06, 2025 pm 07:33 PM
Der Schlüssel zur Federkontrolle liegt darin, seine allmähliche Natur zu verstehen. PS selbst bietet nicht die Möglichkeit, die Gradientenkurve direkt zu steuern, aber Sie können den Radius und die Gradientenweichheit flexius durch mehrere Federn, Matching -Masken und feine Selektionen anpassen, um einen natürlichen Übergangseffekt zu erzielen.
 Was soll ich tun, wenn sich die PS -Karte in der Ladeschnittstelle befindet?
Apr 06, 2025 pm 06:54 PM
Was soll ich tun, wenn sich die PS -Karte in der Ladeschnittstelle befindet?
Apr 06, 2025 pm 06:54 PM
Die Ladeschnittstelle der PS-Karte kann durch die Software selbst (Dateibeschäftigung oder Plug-in-Konflikt), die Systemumgebung (ordnungsgemäße Treiber- oder Systemdateienbeschäftigung) oder Hardware (Hartscheibenbeschäftigung oder Speicherstickfehler) verursacht werden. Überprüfen Sie zunächst, ob die Computerressourcen ausreichend sind. Schließen Sie das Hintergrundprogramm und geben Sie den Speicher und die CPU -Ressourcen frei. Beheben Sie die PS-Installation oder prüfen Sie, ob Kompatibilitätsprobleme für Plug-Ins geführt werden. Aktualisieren oder Fallback die PS -Version. Überprüfen Sie den Grafikkartentreiber und aktualisieren Sie ihn und führen Sie die Systemdateiprüfung aus. Wenn Sie die oben genannten Probleme beheben, können Sie die Erkennung von Festplatten und Speichertests ausprobieren.
 Wie richte ich PS -Federn ein?
Apr 06, 2025 pm 07:36 PM
Wie richte ich PS -Federn ein?
Apr 06, 2025 pm 07:36 PM
PS Federn ist ein Bildkantenschwärcheneffekt, der durch den gewichteten Durchschnitt der Pixel im Randbereich erreicht wird. Das Einstellen des Federradius kann den Grad der Unschärfe steuern und je größer der Wert ist, desto unscharfer ist er. Eine flexible Einstellung des Radius kann den Effekt entsprechend den Bildern und Bedürfnissen optimieren. Verwenden Sie beispielsweise einen kleineren Radius, um Details bei der Verarbeitung von Charakterfotos zu erhalten und einen größeren Radius zu verwenden, um ein dunstiges Gefühl bei der Verarbeitung von Kunst zu erzeugen. Es ist jedoch zu beachten, dass zu groß der Radius leicht an Kantendetails verlieren kann, und zu klein ist der Effekt nicht offensichtlich. Der Federneffekt wird von der Bildauflösung beeinflusst und muss anhand des Bildverständnisses und des Griffs von Effekten angepasst werden.
 So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
So optimieren Sie die Datenbankleistung nach der MySQL -Installation
Apr 08, 2025 am 11:36 AM
Die MySQL -Leistungsoptimierung muss von drei Aspekten beginnen: Installationskonfiguration, Indexierung und Abfrageoptimierung, Überwachung und Abstimmung. 1. Nach der Installation müssen Sie die my.cnf -Datei entsprechend der Serverkonfiguration anpassen, z. 2. Erstellen Sie einen geeigneten Index, um übermäßige Indizes zu vermeiden und Abfrageanweisungen zu optimieren, z. B. den Befehl Erklärung zur Analyse des Ausführungsplans; 3. Verwenden Sie das eigene Überwachungstool von MySQL (ShowProcessList, Showstatus), um die Datenbankgesundheit zu überwachen und die Datenbank regelmäßig zu sichern und zu organisieren. Nur durch kontinuierliche Optimierung dieser Schritte kann die Leistung der MySQL -Datenbank verbessert werden.
