
Verzeichnis dieses Artikels:
9.1 Einfache Beschreibung des Prozesses
9.11 Der Unterschied zwischen Prozessen und Programmen
9.12 Multitasking und CPU-Zeitscheiben
9.13 Eltern-Kind-Prozesse und wie man Prozesse erstellt
9.14 Prozessstatus
9.15 Beispielanalyse von Prozessstatus-Übergangsprozess
9.16 Prozessstruktur und Unterschalen
9.2 Arbeitsaufgabe
9.3 Die Beziehung zwischen Terminal und Prozess
9.4 Signale
9.41 Signale, die Sie kennen sollten
9.42 SIGHUP
9.43 Zombie-Prozesse und SIGCHLD
9.44 Signal manuell senden (Kill-Befehl)
9,45 pkill und killall
9,5 Fixiereinheit und lsof
Prozess ist ein sehr komplexes Konzept und beinhaltet viele Inhalte. Der in diesem Abschnitt aufgeführte Inhalt wurde von mir extrem vereinfacht. Sie sollten ihn so weit wie möglich verstehen. Ich denke, dass diese Theorien wichtiger sind als die Verwendung von Befehlen, um den Status zu überprüfen Überprüfen Sie die Statusinformationen später. Grundsätzlich weiß ich nicht, was der entsprechende Status bedeutet.
Aber für Nicht-Programmierer besteht keine Notwendigkeit, sich mit weiteren Prozessdetails zu befassen: Je mehr, desto besser.
Ein Programm ist eine Binärdatei, die statisch auf der Festplatte gespeichert ist und keine laufenden Systemressourcen belegt (CPU/Speicher).
Ein Prozess ist das Ergebnis der Ausführung eines Programms durch einen Benutzer oder des Auslösens eines Programms. Man kann davon ausgehen, dass ein Prozess eine laufende Instanz des Programms ist. Der Prozess ist dynamisch, er beantragt und nutzt Systemressourcen und interagiert mit dem Betriebssystemkernel. Im folgenden Artikel zeigen die Ergebnisse vieler Statusstatistiktools den Status der Systemklasse. Tatsächlich ist das Synonym für Systemstatus der Kernelstatus.
Jetzt können alle Betriebssysteme mehrere Prozesse „gleichzeitig“ ausführen, also Multitasking bzw. Multitasking parallel ausgeführt werden. Tatsächlich ist dies jedoch eine menschliche Illusion. Eine physische CPU kann nur einen Prozess gleichzeitig ausführen. Nur mehrere physische CPUs können wirklich Multitasking durchführen.
Der Mensch wird die Illusion haben, dass das Betriebssystem mehrere Dinge parallel erledigen kann. Dies wird durch das Umschalten zwischen Prozessen in sehr kurzer Zeit erreicht. Da die Zeit sehr kurz ist, wird Prozess A im ersten Moment ausgeführt , und Prozess A wird im nächsten Moment ausgeführt. Wechseln Sie gleichzeitig zu Prozess B und wechseln Sie ständig zwischen mehreren Prozessen, sodass der Mensch denkt, er würde mehrere Dinge gleichzeitig verarbeiten.
Wie die CPU jedoch den nächsten auszuführenden Prozess auswählt, ist eine sehr komplizierte Angelegenheit. Unter Linux wird die Bestimmung des nächsten auszuführenden Prozesses durch die „Schedulerklasse“ (Scheduler) erreicht. Wann ein Programm ausgeführt wird, wird durch die Priorität des Prozesses bestimmt. Beachten Sie jedoch, dass je niedriger der Prioritätswert, desto höher die Priorität und desto früher wird es von der Planungsklasse ausgewählt. Unter Linux kann sich die Änderung des Nice-Werts eines Prozesses auf den Prioritätswert eines bestimmten Prozesstyps auswirken.
Einige Prozesse sind wichtiger und sollten so schnell wie möglich abgeschlossen werden, während einige Prozesse weniger wichtig sind und ihre frühere oder spätere Ausführung keine großen Auswirkungen hat. Daher muss das Betriebssystem wissen, welche Prozesse wichtiger sind und welche Prozesse weniger wichtig sind. Wichtigeren Prozessen sollte mehr CPU-Ausführungszeit zugewiesen werden, damit sie schnellstmöglich abgeschlossen werden können. Die folgende Abbildung zeigt das Konzept der CPU-Zeitscheibe.

Daraus können wir erkennen, dass alle Prozesse ausgeführt werden können, wichtige Prozesse jedoch immer mehr CPU-Zeit erhalten. Bei dieser Methode handelt es sich um eine „präventive Multiprozess“-Aufgabenverarbeitung ": Der Kernel kann erzwingen, dass die CPU-Nutzungsrechte zurückgenommen werden, wenn die Zeitscheibe erschöpft ist, und die CPU an den von der Planungsklasse ausgewählten Prozess übergeben. Darüber hinaus kann er in einigen Fällen auch direkt vorgreifen aktuell laufender Prozess. Mit der Zeit wird die dem Prozess zugewiesene Zeit nach und nach verbraucht. Wenn die zugewiesene Zeit verbraucht ist, übernimmt der Kernel wieder die Kontrolle über den Prozess und lässt den nächsten Prozess ausführen. Da der vorherige Prozess jedoch noch nicht abgeschlossen ist, wird die Scheduling-Klasse ihn dennoch zu einem späteren Zeitpunkt auswählen. Daher sollte der Kernel die Laufzeitumgebung (Inhalte in Registern und Seitentabellen) speichern, wenn jeder Prozess vorübergehend gestoppt wird (Speichern). Der Speicherort ist der vom Kernel belegte Speicher. Dies wird als Schutz-Site bezeichnet. Wenn der Prozess das nächste Mal wieder ausgeführt wird, wird die ursprüngliche Laufzeitumgebung auf die CPU geladen. Dies wird als Wiederherstellungs-Site bezeichnet, sodass die CPU weiterhin ausgeführt werden kann in der ursprünglichen Laufzeitumgebung.
Reading sagte, dass der Linux-Scheduler den nächsten auszuführenden Prozess nicht basierend auf der verstrichenen CPU-Zeitscheibe auswählt, sondern die Wartezeit des Prozesses berücksichtigt, d. h. wie lange er in der Bereitschaftsphase gewartet hat Warteschlange, und diejenigen, die an der Zeit interessiert sind, sollten Prozesse mit höchsten Anforderungen so früh wie möglich zur Ausführung einplanen. Darüber hinaus beanspruchen wichtige Prozesse natürlich mehr CPU-Laufzeit.
Nachdem die Planungsklasse den nächsten auszuführenden Prozess ausgewählt hat, muss sie einen zugrunde liegenden Aufgabenwechsel durchführen, dh einen Kontextwechsel. Dieser Prozess erfordert eine enge Interaktion mit dem CPU-Prozess. Prozesswechsel sollten weder zu häufig noch zu langsam erfolgen. Zu häufiges Umschalten führt dazu, dass die CPU in der Schutz- und Wiederherstellungsszene zu lange im Leerlauf bleibt, was für Menschen oder Prozesse nicht produktiv ist (da sie keine Programme ausführt). Ein zu langsamer Wechsel führt zu einer langsamen Prozessplanung Es ist sehr wahrscheinlich, dass der nächste Prozess lange warten muss, bevor er an der Reihe ist, wenn Sie einen ls-Befehl erteilen. Möglicherweise müssen Sie einen halben Tag warten, was natürlich nicht zulässig ist.
An diesem Punkt wissen Sie auch, dass die Maßeinheit der CPU die Zeit ist , genau wie die Maßeinheit des Speichers die Speicherplatzgröße ist. Die lange CPU-Zeit, die ein Prozess in Anspruch nimmt, bedeutet, dass die CPU viel Zeit damit verbringt, ihn auszuführen. Beachten Sie, dass der prozentuale Wert einer CPU nicht ihre Arbeitsintensität oder -frequenz ist, sondern „Prozessbelegte CPU-Zeit/Gesamt-CPU-Zeit“.
Jedem Prozess wird eine eindeutige eindeutige ID zugewiesen, die auf der UID des ausführenden Benutzers basiert das Programm und andere Kriterien.
Das Konzept des Eltern-Kind-Prozesses: Wenn ein Programm im Kontext eines bestimmten Prozesses (Elternprozess) ausgeführt oder aufgerufen wird, ist der von diesem Programm ausgelöste Prozess der untergeordnete Prozess und die PPID des Prozesses stellt das übergeordnete Element des Prozesses dar. Die PID des Prozesses. Daraus wissen wir auch, dass untergeordnete Prozesse immer durch übergeordnete Prozesse erstellt werden .
Unter Linux existieren Eltern-Kind-Prozesse in einer Baumstruktur, und mehrere von einem Elternprozess erstellte Kinderprozesse werden als Geschwisterprozesse bezeichnet. Unter CentOS 6 ist der Init-Prozess der übergeordnete Prozess aller Prozesse und unter CentOS 7 ist er systemd.
Es gibt drei Möglichkeiten, unter Linux untergeordnete Prozesse zu erstellen (ein äußerst wichtiges Konzept): Eine ist ein von Fork erstellter Prozess, eine ist ein von Exec erstellter Prozess und eine ist ein von Clone erstellter Prozess .
(1).fork ist ein Kopierprozess, der eine Kopie des aktuellen Prozesses kopiert (unabhängig vom Copy-on-Write-Modus) und diese Ressourcen an den untergeordneten Prozess übergibt eine angemessene Art und Weise. Daher sind die vom untergeordneten Prozess gesteuerten Ressourcen dieselben wie die des übergeordneten Prozesses, einschließlich des Speicherinhalts , sodass auch Umgebungsvariablen und Variablen enthalten sind. Die übergeordneten und untergeordneten Prozesse sind jedoch völlig unabhängig. Sie sind zwei Instanzen desselben Programms.
(2).exec dient dazu, eine andere Anwendung zu laden, um den aktuell ausgeführten Prozess zu ersetzen, was bedeutet, dass ein neues Programm geladen wird, ohne einen neuen Prozess zu erstellen. exec hat auch eine weitere Aktion: Nachdem der Prozess ausgeführt wurde, verlassen Sie die Shell, in der sich exec befindet. Um die Prozesssicherheit zu gewährleisten, müssen Sie daher, wenn Sie einen neuen und unabhängigen untergeordneten Prozess erstellen möchten, zunächst eine Kopie des aktuellen Prozesses erstellen und dann exec für den untergeordneten untergeordneten Prozess aufrufen, um ein neues Programm zu laden, das das untergeordnete Element ersetzt Verfahren. Wenn Sie beispielsweise den Befehl cp unter Bash ausführen, wird zuerst ein Bash gegabelt, und dann lädt exec das CP-Programm, um den Sub-Bash-Prozess zu überschreiben und zum CP-Prozess zu werden.
(3).clone wird zum Implementieren von Threads verwendet. Klonen funktioniert genauso wie Fork, aber der neue geklonte Prozess ist nicht unabhängig vom übergeordneten Prozess. Er teilt nur bestimmte Ressourcen mit dem übergeordneten Prozess. Beim Klonen des Prozesses können Sie angeben, welche Ressourcen gemeinsam genutzt werden sollen.
Im Allgemeinen sind Geschwisterprozesse unabhängig und füreinander unsichtbar, aber manchmal können sie durch besondere Mittel eine Kommunikation zwischen Prozessen erreichen. Beispielsweise koordiniert eine Pipe die Prozesse auf beiden Seiten. Die Prozesse auf beiden Seiten gehören zur gleichen Prozessgruppe und ihre PPIDs sind identisch. Die Pipe ermöglicht ihnen, Daten in einer „Pipeline“-Methode zu übertragen.
Ein Prozess hat einen Besitzer, das heißt seinen Initiator. Wenn ein Benutzer nicht der Initiator des Prozesses, der Initiator des übergeordneten Prozesses oder der Root-Benutzer ist, kann er den Prozess nicht beenden. Und das Beenden des übergeordneten Prozesses (nicht terminaler Prozess) führt dazu, dass der untergeordnete Prozess zu einem verwaisten Prozess wird. Der übergeordnete Prozess des verwaisten Prozesses ist immer init/systemd.
Der Prozess läuft nicht immer, zumindest läuft er nicht, wenn die CPU nicht darauf läuft. Ein Prozess hat mehrere Zustände und es kann ein Zustandswechsel zwischen verschiedenen Zuständen erreicht werden. Das Bild unten ist ein sehr klassisches Prozessstatusbeschreibungsdiagramm. Ich persönlich bin der Meinung, dass das Bild rechts leichter zu verstehen ist.
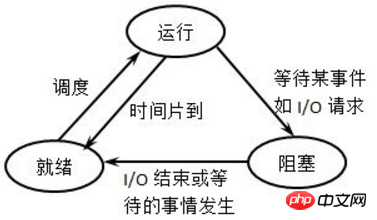
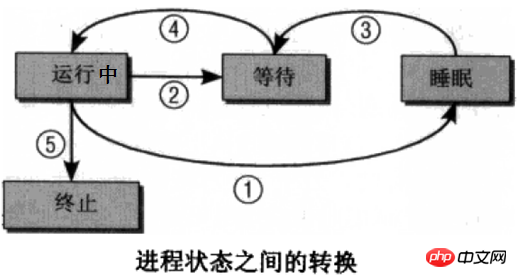
Laufstatus: Der Prozess läuft, das heißt, die CPU ist darauf.
Bereitschaftszustand (wartend): Der Prozess kann ausgeführt werden und befindet sich bereits in der Warteschlange, was bedeutet, dass die Planungsklasse ihn beim nächsten Mal auswählen kann.
Ruhezustand (blockiert): Der Prozess ist schläft und kann nicht zum Laufen verwendet werden.
Die Übergangsmethode zwischen den einzelnen Zuständen ist: (Es ist möglicherweise nicht leicht zu verstehen, Sie können es später mit dem Beispiel kombinieren)
(1) Neuer Zustand -> Bereitzustand: Wenn der Warteschlange ist zulässig. Wenn ein neuer Prozess zugelassen wird, verschiebt der Kernel den neuen Prozess in die Warteschlange.
(2) Bereitstatus -> Ausführungsstatus: Die Planungsklasse wählt einen Prozess in der Warteschlange aus und der Prozess wechselt in den Ausführungsstatus.
(3) Laufzustand -> Ruhezustand: Der laufende Prozess kann nicht ausgeführt werden, da er auf das Auftreten eines bestimmten Ereignisses (z. B. E/A-Warten, Signalwarten usw.) warten muss und in den Ruhezustand wechselt Zustand.
(4) Ruhezustand -> Bereitschaftszustand: Wenn das Ereignis eintritt, auf das der Prozess wartet, wird der Prozess aus dem Ruhezustand in die Warteschlange eingereiht und wartet darauf, beim nächsten Mal zur Ausführung ausgewählt zu werden.
(5) Ausführungsstatus -> Bereitschaftsstatus: Der ausgeführte Prozess wird angehalten, weil die Zeitscheibe abgelaufen ist oder im präemptiven Planungsmodus der Prozess mit hoher Priorität den ausgeführten Prozess mit niedriger Priorität zwangsweise vorwegnimmt Verfahren.
(6) Laufender Zustand -> Beendigungszustand: Wenn ein Prozess abgeschlossen ist oder ein besonderes Ereignis eintritt, wird der Prozess in den beendeten Zustand versetzt. Bei Befehlen werden im Allgemeinen Exit-Statuscodes zurückgegeben.
Beachten Sie, dass es im obigen Bild keinen Statuswechsel zwischen „Bereit –>Ruhezustand“ und „Ruhezustand –>Ausführen“ gibt. Es ist leicht zu verstehen. Für „Bereit -> Ruhezustand“ ist der Warteprozess bereits in die Warteschlange eingetreten, was darauf hinweist, dass er ausgeführt werden kann. Wenn er in den Ruhezustand wechselt, bedeutet dies, dass er vorübergehend nicht ausführbar ist, was für „Ruhezustand“ an sich schon einen Konflikt darstellt. >Ausführen“ Dies funktioniert auch nicht, da die Planungsklasse einfach den nächsten auszuführenden Prozess aus der Warteschlange auswählt.
Sprechen wir über den Laufzustand -> Schlafzustand. Vom laufenden Zustand bis zum Ruhezustand wird normalerweise auf das Eintreten eines Ereignisses gewartet, z. B. auf eine Signalbenachrichtigung oder auf den Abschluss von E/A. Die Signalbenachrichtigung ist leicht zu verstehen, aber beim Warten auf E/A muss die CPU die Anweisungen des Programms ausführen, damit das Programm ausgeführt werden kann, und gleichzeitig müssen Daten eingegeben werden, bei denen es sich um variable Daten, Tastatureingabedaten oder Daten handeln kann In Festplattendateien sind die beiden letztgenannten Datentypen im Vergleich zur CPU extrem langsam. Aber egal, wenn die CPU die Daten nicht abrufen kann, wenn sie sie benötigt, kann die CPU nur im Leerlauf bleiben. Dies ist definitiv nicht der Fall, da die CPU eine äußerst wertvolle Ressource ist, die der Kernel zulassen sollte Die CPU läuft und benötigt Daten. Der Prozess geht vorübergehend in den Ruhezustand und wartet, bis seine Daten bereit sind, bevor er in die Warteschlange zurückkehrt und darauf wartet, von der Planungsklasse ausgewählt zu werden. Hier wartet IO.
Tatsächlich fehlt im obigen Bild ein spezieller Zustand des Prozess-Zombie-Zustands. Der Zombie-Statusprozess bedeutet, dass der Prozess in den beendeten Zustand versetzt wurde. Er hat seine Mission abgeschlossen und ist verschwunden, aber der Kernel hatte keine Zeit, seinen Eintrag in der Prozessliste zu löschen , was bedeutet, dass der Der Kernel muss sich nicht um seine Folgen kümmern, wodurch die Illusion entsteht, dass ein Prozess sowohl tot als auch lebendig ist. Er wird als tot bezeichnet, weil er keine Ressourcen mehr verbraucht und es für die Planungsklasse unmöglich ist, ihn auszuwählen und zuzulassen Es wird als lebendig bezeichnet, da es auch einen entsprechenden Eintrag in der Prozessliste gibt, der erfasst werden kann. Der Zombie-Prozess belegt nicht viele Ressourcen, er belegt nur wenig Speicher in der Prozessliste. Die meisten Zombie-Prozesse werden angezeigt, weil der Prozess normal beendet wird (einschließlich kill -9), der übergeordnete Prozess jedoch nicht bestätigt, dass der Prozess beendet wurde, sodass er dem Kernel nicht mitgeteilt wird und der Kernel nicht weiß, dass der Prozess beendet wurde. Eine detailliertere Beschreibung des Zombie-Prozesses finden Sie unter und später .
Darüber hinaus ist der Schlafzustand ein sehr weit gefasster Begriff, der in unterbrechbaren Schlaf und ununterbrochenen Schlaf unterteilt ist. Unterbrechbarer Schlaf ist ein Schlaf, der durch den Empfang externer Signale und Kernel-Signale geweckt werden kann. Der überwiegende Teil des Schlafs ist unterbrechbarer Schlaf, der durch ps erfasst werden kann, oder unterbrechbarer Schlaf, der nur durch gesteuert werden kann Der Kernel kann ein Signal zum Aufwecken initiieren. Die Außenwelt kann nicht durch Signale aufgeweckt werden, insbesondere wenn sie mit der Hardware interagiert. Beim Catting einer Datei muss das Laden von Daten von der Festplatte in den Speicher beispielsweise während der kurzen Zeitspanne, in der sie mit der Hardware interagiert, unterbrechungsfrei erfolgen. Andernfalls wird sie beim Laden der Daten plötzlich manuell durch ein künstliches Signal geweckt. und wenn es aktiviert ist, wird es nicht unterbrochen. Der Hardware-Interaktionsprozess ist noch nicht abgeschlossen. Selbst wenn es aktiviert wird, kann die CPU nicht ausgeführt werden, sodass beim Catting nicht nur ein Teil des Inhalts angezeigt werden kann eine Datei. Wenn außerdem der ununterbrochene Schlaf künstlich geweckt werden kann, ist die schwerwiegendere Folge ein Hardware-Absturz. Es ist ersichtlich, dass der ununterbrochene Ruhezustand dazu dient, bestimmte wichtige Prozesse zu schützen und zu verhindern, dass die CPU verschwendet wird. Im Allgemeinen ist ununterbrochener Schlaf äußerst kurzlebig und äußerst schwer nicht programmgesteuert zu erfassen.
Solange festgestellt wird, dass der Prozess existiert, kein Zombie-Prozess ist und keine CPU-Ressourcen belegt, schläft er. Einschließlich des Pausenzustands und des Verfolgungszustands, die später im Artikel erscheinen, handelt es sich auch um Schlafzustände.
Die Zustandsübergangssituation zwischen Prozessen kann kompliziert sein. Hier ist ein Beispiel, um es zu beschreiben so detailliert wie möglich.
Nehmen Sie als Beispiel die Ausführung des cp-Befehls unter Bash. Wenn es sich in der aktuellen Bash-Umgebung in einem ausführbaren Zustand (d. h. im Bereitschaftszustand) befindet und der Befehl cp ausgeführt wird, wird zunächst ein Bash-Unterprozess gegabelt, und dann wird das cp-Programm von exec auf den Unterprozess geladen. bash. Der cp-Unterprozess wird in die Warteschlange gestellt. Der Befehl wird in der Befehlszeile eingegeben, sodass er eine höhere Priorität hat und von der Planungsklasse schnell ausgewählt wird. Während der Ausführung des untergeordneten Prozesses cp wechselt der übergeordnete Prozess bash in den Ruhezustand (nicht nur, weil jeweils nur ein Prozess ausgeführt werden kann, wenn nur eine CPU vorhanden ist, sondern auch, weil der Prozess wartet) und wartet darauf erwacht. In diesem Moment kann Bash nicht mit Menschen interagieren. Wenn der cp-Befehl ausgeführt wird, informiert er den übergeordneten Prozess über seinen Exit-Statuscode, ob die Kopie erfolgreich ist oder fehlgeschlagen ist. Dann verschwindet der cp-Prozess von selbst, und die Bash des übergeordneten Prozesses wird erneut aktiviert und tritt erneut in die Warteschlange ein Diesmal hat Bash den Exit-Statuscode erhalten. Anhand des „Signals“ des Statuscodes weiß die Bash des übergeordneten Prozesses, dass der untergeordnete Prozess beendet wurde, und benachrichtigt den Kernel. Nach Erhalt der Benachrichtigung löscht der Kernel den CP-Prozesseintrag in der Prozessliste. Zu diesem Zeitpunkt ist der gesamte CP-Prozess normal abgeschlossen.
Wenn der cp-Unterprozess eine große Datei kopiert und den Kopiervorgang nicht in einer CPU-Zeitscheibe abschließen kann, wird er in die Warteschlange gestellt, wenn eine CPU-Zeitscheibe erschöpft ist.
Wenn der cp-Unterprozess eine Datei kopiert und am Zielspeicherort bereits eine Datei mit demselben Namen vorhanden ist, fragt er standardmäßig, ob sie überschrieben werden soll. Bei der Frage wird auf ein Ja oder Nein gewartet Wenn Sie auf der Tastatur „Yes“ oder „No Signal“ an cp eingeben, empfängt cp das Signal und wechselt vom Ruhezustand in den Bereitschaftszustand und wartet darauf, dass die Planungsklasse es auswählt, um den Vorgang abzuschließen CP-Prozess.
Wenn cp kopiert, muss es mit der Festplatte interagieren. Während des kurzen Prozesses der Interaktion mit der Hardware befindet sich cp im ununterbrochenen Ruhezustand.
Wenn der CP-Prozess endet, aber während des Endprozesses etwas Unerwartetes passiert, sodass der übergeordnete Prozess von Bash nicht weiß, dass er beendet wurde (dies ist in diesem Beispiel unmöglich), wird Bash den Kernel ausführen Sie werden nicht aufgefordert, den cp-Eintrag in der Prozessliste wiederzuverwenden, und cp wird zu diesem Zeitpunkt zu einem Zombie-Prozess.
Vordergrundprozess: Allgemeine Befehle (z. B. cp-Befehl) verzweigen den untergeordneten Prozess zur Ausführung während der Ausführung des untergeordneten Prozesses , der übergeordnete Prozess Der Prozess wird in den Ruhezustand versetzt, was ein Vordergrundprozess ist. Wenn der Vordergrundprozess ausgeführt wird, schläft sein übergeordneter Prozess. Da es nur eine CPU gibt, kann aufgrund des Ausführungsablaufs (Prozesswartezeit) nur ein Prozess ausgeführt werden true Für Multitasking sollte prozessinternes Multithreading verwendet werden, um mehrere Ausführungsströme zu implementieren.
durch Hinzufügen von „&“ nach dem Befehl und anschließender Angabe eines anderen auszuführenden Befehls nach dem „&“ eine „pseudoparallele“ Ausführung erreicht werden, z. B. „cp /etc/fstab /tmp & cat /etc/fstab".
erbt die untergeordnete Shell aufgrund des Neuladens der Umgebungskonfigurationselemente keine gewöhnlichen Variablen. Genauer gesagt überschreibt sie die von ihr geerbten Variablen die übergeordnete Shell . Sie könnten genauso gut versuchen, eine Variable in der Datei /etc/bashrc zu definieren und dann eine Umgebungsvariable mit demselben Namen, aber einem anderen Wert in die übergeordnete Shell zu exportieren und dann zur Subshell zu gehen, um zu sehen, welchen Wert die Variable hat?
Die meisten Prozesse können sie in den Hintergrund stellen, daher ist dies häufig der Fall Als Job bezeichnet, verwaltet jede geöffnete Shell eine Jobtabelle, und jeder Job im Hintergrund entspricht einem Jobelement in der Jobtabelle.
Um einen Befehl oder ein Skript manuell im Hintergrund auszuführen, fügen Sie nach der Befehlszeile das Symbol „&“ hinzu. Beispiel:
[root@server2 ~]# cp /etc/fstab /tmp/ &[1] 8701
Nachdem der Prozess in den Hintergrund verschoben wurde, kehrt er sofort zu seinem übergeordneten Prozess zurück Hintergrund werden unter Bash ausgeführt, also kehren Sie sofort zur Bash-Umgebung zurück. Bei der Rückgabe des übergeordneten Prozesses werden auch dessen Job-ID und PID an den übergeordneten Prozess zurückgegeben. Wenn Sie jobid in Zukunft angeben möchten, sollten Sie vor jobid ein Prozentzeichen „%“ hinzufügen, wobei „%%“ für den aktuellen Job steht. „kill -9 %1“ bedeutet beispielsweise, dass der Hintergrundprozess mit jobid 1 beendet wird . Wenn Sie kein Hundert Semikolon hinzufügen, ist es vorbei, beenden Sie den Init-Prozess.
Sie können Hintergrundjobinformationen über den Befehl jobs anzeigen.
jobs [--l:jobs默认不会列出后台工作的PID,加上---s:显示后台工作处于stopped状态的jobs
Aufgaben, die über „&“ in den Hintergrund gestellt wurden, werden weiterhin im Hintergrund ausgeführt. Bei interaktiven Befehlen wie vim wird der Ausführungsstatus natürlich angehalten.
[root@server2 ~]# sleep 10 &[1] 8710[root@server2 ~]# jobs [1]+ Running sleep 10 &
Achten Sie darauf, dass Sie hier den R-Status sehen, der durch „Running“ und „Ps“ oder „Top“ angezeigt wird nicht Es bedeutet immer Laufen, und Prozesse in der Warteschlange gehören auch zum Laufen. Sie gehören alle zur Task_running-Kennung.
Eine andere Möglichkeit, den Hintergrund manuell zu verbinden, besteht darin, die Tasten STRG+Z zu drücken. Dadurch kann der laufende Prozess zum Hintergrund hinzugefügt werden, der zum Hintergrund hinzugefügte Prozess wird jedoch im Hintergrund angehalten.
[root@server2 ~]# sleep 10^Z [1]+ Stopped sleep 10[root@server2 ~]# jobs [1]+ Stopped sleep 10
Anhand der Jobinformationen können wir auch erkennen, dass nach jedem Jobid ein „+“-Zeichen und auch ein „-“ steht. , oder kein Zeichen.
[root@server2 ~]# sleep 30&vim /etc/my.cnf&sleep 50&[1] 8915[2] 8916[3] 8917
[root@server2 ~]# jobs [1] Running sleep 30 &[2]+ Stopped vim /etc/my.cnf [3]- Running sleep 50 &
Es wurde festgestellt, dass auf den VIM-Prozess ein Pluszeichen folgt und „+“ darauf hinweist Die ausgeführte Aufgabe, d. Es kann anhand des Status von Jobs analysiert werden. Das Ausführen ohne „+“ in der Hintergrundaufgabentabelle bedeutet, dass es sich in der Warteschlange befindet, das Ausführen mit „+“ bedeutet, dass es ausgeführt wird, und der Status „Gestoppt“ bedeutet, dass es sich in der Warteschlange befindet Schlafzustand . Wir können jedoch nicht davon ausgehen, dass sich die Aufgaben in der Jobliste immer in diesem Zustand befinden, da die jeder Aufgabe zugewiesene Zeitscheibe tatsächlich sehr kurz ist. Nach der Ausführung der Aufgabe dieser Zeitscheibenlänge in sehr kurzer Zeit wird dies sofort der Fall sein Wechseln Sie zur nächsten Aufgabe und führen Sie sie aus. Da jedoch im tatsächlichen Prozess die Umschaltgeschwindigkeit und die Zeitspanne jeder Aufgabe extrem kurz sind, ändert sich die angezeigte Reihenfolge möglicherweise nicht wesentlich, wenn die Aufgabenliste klein ist.
Was das obige Beispiel betrifft, ist die nächste auszuführende Aufgabe vim, aber sie wird gestoppt. Werden andere Prozesse nicht ausgeführt, weil der erste Prozess gestoppt ist? Das ist offensichtlich nicht der Fall. Tatsächlich werden Sie bald feststellen, dass die beiden anderen Schlafaufgaben abgeschlossen sind, vim sich jedoch immer noch im Stoppzustand befindet.
[root@server2 ~]# jobs [1] Done sleep 30[2]+ Stopped vim /etc/my.cnf [3]- Done sleep 50
Haben Sie durch dieses Jobbeispiel ein tieferes Verständnis dafür, wie der Kernel Prozesse plant?
Zurück zum Thema. Da Sie den Prozess manuell in den Hintergrund versetzen können, können Sie ihn auf jeden Fall wieder in den Vordergrund rücken, um den Ausführungsfortschritt zu überprüfen, und ihn in den Hintergrund holen möchten Verwenden Sie nicht STRG+Z, um es im Backstage-Modus hinzuzufügen.
Die Befehle fg und bg sind die Abkürzungen für „foreground“ bzw. „background“, d , auch wenn sich die ursprüngliche Aufgabe im gestoppten Zustand befindet.
Die Operationsmethode ist ebenfalls sehr einfach. Fügen Sie einfach jobid direkt nach dem Befehl hinzu (d. h. [fg|bg] [%jobid]). Wenn jobid nicht angegeben ist, wird die aktuelle Aufgabe ausgeführt. mit „+“ Aufgabenelementen.
[root@server2 ~]# sleep 20^Z # 按下CTRL+Z进入暂停并放入后台 [3]+ Stopped sleep 20
[root@server2 ~]# jobs [2]- Stopped vim /etc/my.cnf [3]+ Stopped sleep 20 # 此时为stopped状态
[root@server2 ~]# bg %3 # 使用bg或fg可以让暂停状态的进程变会运行态 [3]+ sleep 20 &
[root@server2 ~]# jobs [2]+ Stopped vim /etc/my.cnf [3]- Running sleep 20 & # 已经变成运行态
Verwenden Sie den Befehl „disown“, um einen Job direkt aus der Jobtabelle zu entfernen. Dabei wird nur die Jobtabelle entfernt, nicht die Aufgabe beendet. Und nach dem Entfernen der Jobtabelle bleibt die Aufgabe im init/systemd-Prozess hängen, wodurch sie vom Terminal unabhängig wird .
disown [-ar] [-h] [%jobid ...] 选项说明:-h:给定该选项,将不从job table中移除job,而是将其设置为不接受shell发送的sighup信号。具体说明见"信号"小节。-a:如果没有给定jobid,该选项表示针对Job table中的所有job进行操作。-r:如果没有给定jobid,该选项严格限定为只对running状态的job进行操作
如果不给定任何选项,该shell中所有的job都会被移除,移除是disown的默认操作,如果也没给定jobid,而且也没给定-a或-r,则表示只针对当前任务即带有"+"号的任务项。
使用pstree命令查看下当前的进程,不难发现在某个终端执行的进程其父进程或上几个级别的父进程总是会是终端的连接程序。
例如下面筛选出了两个终端下的父子进程关系,第一个行是tty终端(即直接在虚拟机中)中执行的进程情况,第二行和第三行是ssh连接到Linux上执行的进程。
[root@server2 ~]# pstree -c | grep bash|-login---bash---bash---vim|-sshd-+-sshd---bash| `-sshd---bash-+-grep
正常情况下杀死父进程会导致子进程变为孤儿进程,即其PPID改变,但是杀掉终端这种特殊的进程,会导致该终端上的所有进程都被杀掉。这在很多执行长时间任务的时候是很不方便的。比如要下班了,但是你连接的终端上还在执行数据库备份脚本,这可能会花掉很长时间,如果直接退出终端,备份就终止了。所以应该保证一种安全的退出方法。
一般的方法也是最简单的方法是使用nohup命令带上要执行的命令或脚本放入后台,这样任务就脱离了终端的关联。当终端退出时,该任务将自动挂到init(或systemd)进程下执行。如:
shell> nohup tar rf a.tar.gz /tmp/*.txt
另一种方法是使用screen这个工具,该工具可以模拟多个物理终端,虽然模拟后screen进程仍然挂在其所在的终端上的,但同nohup一样,当其所在终端退出后将自动挂到init/systemd进程下继续存在,只要screen进程仍存在,其所模拟的物理终端就会一直存在,这样就保证了模拟终端中的进程继续执行。它的实现方式其实和nohup差不多,只不过它花样更多,管理方式也更多。一般对于简单的后台持续运行进程,使用nohup足以。
另外,可能你已经发现了,很多进程是和终端无关的,也就是不依赖于终端,这类进程一般是内核类进程/线程以及daemon类进程,若它们也依赖于终端,则终端一被终止,这类进程也立即被终止,这是绝对不允许的。
信号在操作系统中控制着进程的绝大多数动作,信号可以让进程知道某个事件发生了,也指示着进程下一步要做出什么动作。信号的来源可以是硬件信号(如按下键盘或其他硬件故障),也可以是软件信号(如kill信号,还有内核发送的信号)。不过,很多可以感受到的信号都是从进程所在的控制终端发送出去的。
Linux中支持非常多种信号,它们都以SIG字符串开头,SIG字符串后的才是真正的信号名称,信号还有对应的数值,其实数值才是操作系统真正认识的信号。但由于不少信号在不同架构的计算机上数值不同(例如CTRL+Z发送的SIGSTP信号就有三种值18,20,24),所以在不确定信号数值是否唯一的时候,最好指定其字符名称。
以下是需要了解的信号。
中断进程,可被捕捉和忽略,几乎等同于sigterm,所以也会尽可能的释放执行clean-up,释放资源,保存状态等(CTRL+ 强制杀死进程,该信号不可被捕捉和忽略,进程收到该信号后不会执行任何clean- 杀死(终止)进程,可被捕捉和忽略,几乎等同于sigint信号,会尽可能的释放执行clean-- 该信号是可被忽略的进程停止信号(CTRL+ 发送此信号使得stopped进程进入running,该信号主要用于jobs,例如bg & 用户自定义信号2
只有SIGKILL和SIGSTOP这两个信号是不可被捕捉且不可被忽略的信号,其他所有信号都可以通过trap或其他编程手段捕捉到或忽略掉。
更多更详细的信号理解或说明,可以参考wiki的两篇文章:
jobs控制机制:(Unix)
信号说明:
(1).当控制终端退出时,会向该终端中的进程发送sighup信号,因此该终端上行的shell进程、其他普通进程以及任务都会收到sighup而导致进程终止。
两种方式可以改变因终端中断发送sighup而导致子进程也被结束的行为:一是使用nohup命令启动进程,它会忽略所有的sighup信号,使得该进程不会随着终端退出而结束;二是使用disown,将任务列表中的任务移除出job table或者直接使用disown -h的功能设置其不接收终端发送的sighup信号。但不管是何种实现方式,终端退出后未被终止的进程将只能挂靠在init/systemd下。
(2).对于daemon类的程序(即服务性进程),这类程序不依赖于终端(它们的父进程都是Init或systemd),它们收到sighup信号时会重读配置文件并重新打开日志文件,使得服务程序可以不用重启就可以加载配置文件。
一个编程完善的程序,在子进程终止、退出的时候,会发送SIGCHLD信号给父进程,父进程收到信号就会通知内核清理该子进程相关信息。
在子进程死亡的那一刹那,子进程的状态就是僵尸进程,但因为发出了SIGCHLD信号给父进程,父进程只要收到该信号,子进程就会被清理也就不再是僵尸进程。所以正常情况下,所有终止的进程都会有一小段时间处于僵尸态(发送SIGCHLD信号到父进程收到该信号之间),只不过这种僵尸进程存在时间极短(倒霉的僵尸),几乎是不可被ps或top这类的程序捕捉到的。
如果在特殊情况下,子进程终止了,但父进程没收到SIGCHLD信号,没收到这信号的原因可能是多种的,不管如何,此时子进程已经成了永存的僵尸,能轻易的被ps或top捕捉到。僵尸不倒霉,人类就要倒霉,但是僵尸爸爸并不知道它儿子已经变成了僵尸,因为有僵尸爸爸的掩护,僵尸道长即内核见不到小僵尸,所以也没法收尸。悲催的是,人类能力不足,直接发送信号(如kill)给僵尸进程是无效的,因为僵尸进程本就是终结了的进程,不占用任何运行资源,也收不到信号,只有内核从进程列表中将僵尸进程表项移除才能收尸。
要解决掉永存的僵尸有几种方法:
(1).杀死僵尸进程的父进程。没有了僵尸爸爸的掩护,小僵尸就暴露给了僵尸道长的直系弟子init/systemd,init/systemd会定期清理它下面的各种僵尸进程。所以这种方法有点不讲道理,僵尸爸爸是正常的啊,不过如果僵尸爸爸下面有很多僵尸儿子,这僵尸爸爸肯定是有问题的,比如编程不完善,杀掉是应该的。
(2).手动发送SIGCHLD信号给僵尸进程的父进程。僵尸道长找不到僵尸,但被僵尸祸害的人类能发现僵尸,所以人类主动通知僵尸爸爸,让僵尸爸爸知道自己的儿子死而不僵,然后通知内核来收尸。
当然,第二种手动发送SIGCHLD信号的方法要求父进程能收到信号,而SIGCHLD信号默认是被忽略的,所以应该显式地在程序中加上获取信号的代码。也就是人类主动通知僵尸爸爸的时候,默认僵尸爸爸是不搭理人类的,所以要强制让僵尸爸爸收到通知。不过一般daemon类的程序在编程上都是很完善的,发送SIGCHLD总是会收到,不用担心。
使用kill命令可以手动发送信号给指定的进程。
kill [-s signal] pid...kill [-signal] pid...kill -l
使用kill -l可以列出Linux中支持的信号,有64种之多,但绝大多数非编程人员都用不上。
使用-s或-signal都可以发送信号,不给定发送的信号时,默认为TREM信号,即kill -15。
shell> kill -9 pid1 pid2... shell> kill -TREM pid1 pid2... shell> kill -s TREM pid1 pid2...
这两个命令都可以直接指定进程名来发送信号,不指定信号时,默认信号都是TERM。
(1).pkill
pkill和pgrep命令是同族命令,都是先通过给定的匹配模式搜索到指定的进程,然后发送信号(pkill)或列出匹配的进程(pgrep),pgrep就不介绍了。
pkill能够指定模式匹配,所以可以使用进程名来删除,想要删除指定pid的进程,反而还要使用"-s"选项来指定。默认发送的信号是SIGTERM即数值为15的信号。
pkill [-signal] [-v] [-P ppid,...] [-s pid,...][-U uid,...] [-t term,...] [pattern] 选项说明:-P ppid,... :匹配PPID为指定值的进程-s pid,... :匹配PID为指定值的进程-U uid,... :匹配UID为指定值的进程,可以使用数值UID,也可以使用用户名称-t term,... :匹配给定终端,终端名称不能带上"/dev/"前缀,其实"w"命令获得终端名就满足此处条件了,所以pkill可以直接杀掉整个终端-v :反向匹配-signal :指定发送的信号,可以是数值也可以是字符代表的信号
在CentOS 7上,还有两个好用的新功能选项。
-F, --pidfile file:匹配进程时,读取进程的pid文件从中获取进程的pid值。这样就不用去写获取进程pid命令的匹配模式-L, --logpidfile :如果"-F"选项读取的pid文件未加锁,则pkill或pgrep将匹配失败。
例如踢出终端:
shell> pkill -t pts/0
(2).killall
killall主要用于杀死一批进程,例如杀死整个进程组。其强大之处还体现在可以通过指定文件来搜索哪个进程打开了该文件,然后对该进程发送信号,在这一点上,fuser和lsof命令也一样能实现。
killall [-r,--regexp] [-s,--signal signal] [-u,--user user] [-v,--verbose] [-w,--wait] [-I,--ignore-case] [--] name ... 选项说明:-I :匹配时不区分大小写-r :使用扩展正则表达式进行模式匹配-s, --signal :发送信号的方式可以是-HUP或-SIGHUP,或数值的"-1",或使用"-s"选项指定信号-u, --user :匹配该用户的进程-v, :给出详细信息-w, --wait :等待直到该杀的进程完全死透了才返回。默认killall每秒检查一次该杀的进程是否还存在,只有不存在了才会给出退出状态码。 如果一个进程忽略了发送的信号、信号未产生效果、或者是僵尸进程将永久等待下去
fuser可以查看文件或目录所属进程的pid,即由此知道该文件或目录被哪个进程使用。例如,umount的时候提示the device busy可以判断出来哪个进程在使用。而lsof则反过来,它是通过进程来查看进程打开了哪些文件,但要注意的是,一切皆文件,包括普通文件、目录、链接文件、块设备、字符设备、套接字文件、管道文件,所以lsof出来的结果可能会非常多。
fuser [-ki] [-signal] file/dir-k:找出文件或目录的pid,并试图kill掉该pid。发送的信号是SIGKILL-i:一般和-k一起使用,指的是在kill掉pid之前询问。-signal:发送信号,如-1 -15,如果不写,默认-9,即kill -9不加选项:直接显示出文件或目录的pid
在不加选项时,显示结果中文件或目录的pid后会带上一个修饰符:
c:在当前目录下
e:可被执行的
f:是一个被开启的文件或目录
F:被打开且正在写入的文件或目录
r:代表root directory
例如:
[root@xuexi ~]# fuser /usr/sbin/crond/usr/sbin/crond: 1425e
表示/usr/sbin/crond被1425这个进程打开了,后面的修饰符e表示该文件是一个可执行文件。
[root@xuexi ~]# ps aux | grep 142[5] root 1425 0.0 0.1 117332 1276 ? Ss Jun10 0:00 crond
例如:
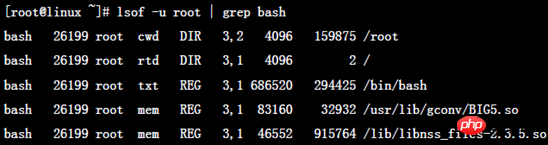
输出信息中各列意义:
COMMAND:进程的名称
PID:进程标识符
USER:进程所有者
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE:文件类型,如DIR、REG等
DEVICE:指定磁盘的名称
SIZE/OFF:文件的大小或文件的偏移量(单位kb)(size and offset)
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
lsof的各种用法:
lsof /path/to/somefile:显示打开指定文件的所有进程之列表;建议配合grep使用 lsof -c string:显示其COMMAND列中包含指定字符(string)的进程所有打开的文件;可多次使用该选项lsof -p PID:查看该进程打开了哪些文件lsof -U:列出套接字类型的文件。一般和其他条件一起使用。如lsof -u root -a -Ulsof -u uid/name:显示指定用户的进程打开的文件;可使用脱字符"^"取反,如"lsof -u ^root"将显示非root用户打开的所有文件lsof +d /DIR/:显示指定目录下被进程打开的文件 lsof +D /DIR/:基本功能同上,但lsof会对指定目录进行递归查找,注意这个参数要比grep版本慢 lsof -a:按"与"组合多个条件,如lsof -a -c apache -u apache lsof -N:列出所有NFS(网络文件系统)文件 lsof -n:不反解IP至HOSTNAME lsof -i:用以显示符合条件的进程情况lsof -i[46] [protocol][@host][:service|port]46:IPv4或IPv6 protocol:TCP or UDP host:host name或ip地址,表示搜索哪台主机上的进程信息 service:服务名称(可以不只一个) port:端口号 (可以不只一个)
大概"-i"是使用最多的了,而"-i"中使用最多的又是服务名或端口了。
[root@www ~]# lsof -i :22COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME sshd 1390 root 3u IPv4 13050 0t0 TCP *:ssh (LISTEN) sshd 1390 root 4u IPv6 13056 0t0 TCP *:ssh (LISTEN) sshd 36454 root 3r IPv4 94352 0t0 TCP xuexi:ssh->172.16.0.1:50018 (ESTABLISHED)
回到系列文章大纲:
Das obige ist der detaillierte Inhalt vonLinux-Prozesse und -Signale. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Der Unterschied zwischen Threads und Prozessen
Der Unterschied zwischen Threads und Prozessen
 So zeigen Sie Prozesse unter Linux an
So zeigen Sie Prozesse unter Linux an
 Linux-Ansichtsprozess
Linux-Ansichtsprozess
 503-Fehlerlösung
503-Fehlerlösung
 So beheben Sie das 504-Gateway-Timeout
So beheben Sie das 504-Gateway-Timeout
 Der Unterschied zwischen Ankern und Zielen
Der Unterschied zwischen Ankern und Zielen
 Anforderungen an die Computerkonfiguration für die Python-Programmierung
Anforderungen an die Computerkonfiguration für die Python-Programmierung
 Welche Datei ist ISO?
Welche Datei ist ISO?
 Eclipse-Tutorial
Eclipse-Tutorial








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



