

Beautiful Soup analysiert alles, was Sie ihm geben, und erledigt die Baumdurchquerung für Sie. Dabei geht es darum, jeden Knoten im Baum einmal und nur einmal entlang einer bestimmten Suchroute zu besuchen.
Wir nennen die BeautifulSoup-Bibliothek oft bs4. So importieren Sie die Bibliothek: aus bs4 importieren Sie BeautifulSoup. Unter diesen verwendet der Import von BeautifulSoup hauptsächlich die BeautifulSoup-Klasse in bs4.
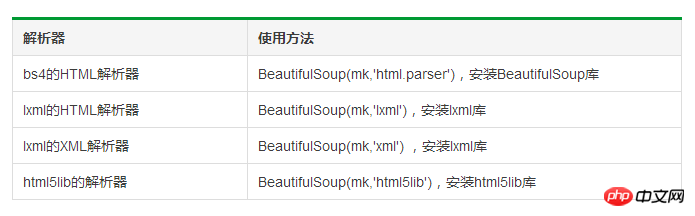
bs4-Bibliotheksparser
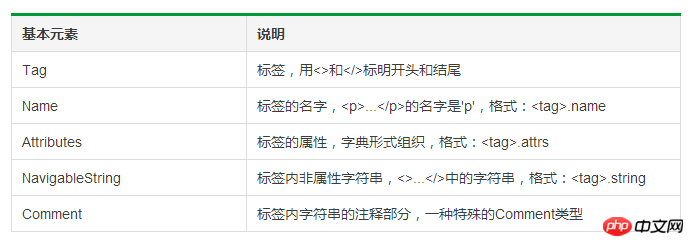
 Grundelemente der BeautifulSoup-Klasse
Grundelemente der BeautifulSoup-Klasse
1 import requests 2 from bs4 import BeautifulSoup 3 4 res = requests.get('') 5 soup = BeautifulSoup(res.text,'lxml') 6 print(soup.a) 7 # 任何存在于HTML语法中的标签都可以用soup.<tag>访问获得,当HTML文档中存在多个相同<tag>对应内容时,soup.<tag>返回第一个。 8 9 print(soup.a.name)10 # 每个<tag>都有自己的名字,可以通过<tag>.name获取,字符串类型11 12 print(soup.a.attrs)13 print(soup.a.attrs['class'])14 # 一个<tag>可能有一个或多个属性,是字典类型15 16 print(soup.a.string)17 # <tag>.string可以取到标签内非属性字符串18 19 soup1 = BeautifulSoup('<p><!--这里是注释--></p>','lxml')20 print(soup1.p.string)21 print(type(soup1.p.string))22 # comment是一种特殊类型,也可以通过<tag>.string取到a
{'href': '', 'class': [ 'no -login']} ['no-login']
Anmelden
Hier ist der Kommentar
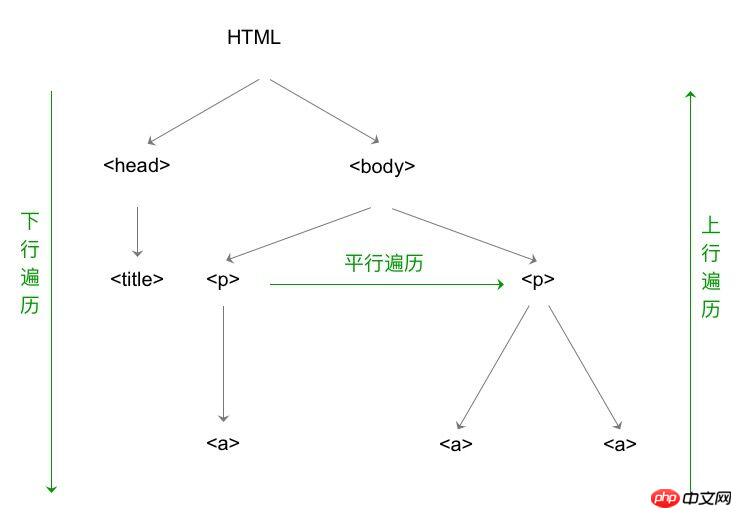
HTML-Inhaltsdurchlauf der bs4-Bibliothek
HTML The Grundstruktur von
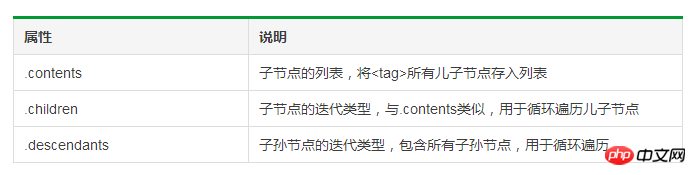
 Abwärtsdurchquerung des Tag-Baums
Abwärtsdurchquerung des Tag-Baums
Unter diesen ist der Typ BeautifulSoup der Wurzelknoten des Tag-Baums.
1 # 遍历儿子节点2 for child in soup.body.children:3 print(child.name)4 5 # 遍历子孙节点6 for child in soup.body.descendants:7 print(child.name)

1 # 遍历所有先辈节点时,包括soup本身,所以要if...else...判断2 for parent in soup.a.parents:3 if parent is None:4 print(parent)5 else:6 print(parent.name)
div
div
Körper
html
[Dokument]
Parallele Durchquerung des Tag-Baums
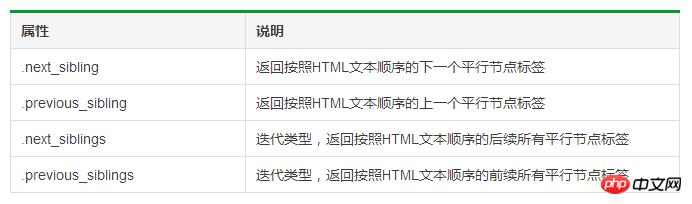
1 # 遍历后续节点2 for sibling in soup.a.next_sibling:3 print(sibling)4 5 # 遍历前续节点6 for sibling in soup.a.previous_sibling:7 print(sibling)
Die prettify()-Methode kann das Codeformat standardisierter machen, dargestellt durch Suppe.prettify(). Verwenden Sie in PyCharm print(soup.prettify()) zur Ausgabe.
Betriebsumgebung: Mac, Python 3.6, PyCharm 2016.2Referenz: MOOC-Kurs der Chinesischen Universität „Python Web Crawler and Information Extraction“
Das obige ist der detaillierte Inhalt vonPython – Einführung in die BeautifulSoup-Bibliothek. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



