
 Backend-Entwicklung
Python-Tutorial
Wie verwende ich Python zum Lesen und Verarbeiten von Dateisuffixen?
Backend-Entwicklung
Python-Tutorial
Wie verwende ich Python zum Lesen und Verarbeiten von Dateisuffixen?
Wie verwende ich Python zum Lesen und Verarbeiten von Dateisuffixen?

Als ich kürzlich ein Projekt analysierte, sah ich eine Datendatei mit dem Suffix „.sqlite“. Da ich vorher noch nicht viel damit in Berührung gekommen war, überlegte ich, wie ich sie mit Python öffnen könnte und Datenanalyse und -verarbeitung durchführen, also habe ich ein wenig recherchiert.
SQLite ist eine sehr beliebte relationale Datenbank, die von einer großen Anzahl von Anwendungen verwendet wird, da sie sehr leichtgewichtig ist.
Wie CSV-Dateien kann SQLite Daten in einer einzigen Datendatei speichern, um sie einfach mit anderen Personen zu teilen. Viele Programmiersprachen unterstützen die Verarbeitung von SQLite-Daten, und die Python-Sprache bildet da keine Ausnahme.
sqlite3 ist eine Standardbibliothek von Python, die zur Verarbeitung von SQLite-Datenbanken verwendet werden kann.
Verwenden Sie sqlite3 zum Erstellen und Betreiben von Datenbankdateien
Für die SQL-Anweisungen der Datenbank werden in diesem Artikel die grundlegendsten SQL-Anweisungen verwendet, die sich nicht auf das Lesen auswirken sollten. Wenn Sie mehr wissen möchten, können Sie auf die folgende Website verweisen:
Als Nächstes wenden wir das salite3-Modul an, um SQLite-Datendateien zu erstellen und Datenlese- und -schreibvorgänge durchzuführen. Die Hauptschritte sind wie folgt:
Stellen Sie eine Verbindung mit der Datenbank her und erstellen Sie eine Datenbankdatei (.sqlite-Datei)
-
Erstellen Sie einen Cursor
Erstellen Sie eine Datentabelle (Tabelle)
Fügen Sie Daten in die Datentabelle ein
-
Abfrage Daten
Der Democode lautet wie folgt:
import sqlite3with sqlite3.connect('test_database.sqlite') as con:
c = con.cursor()
c.execute('''CREATE TABLE test_table
(date text, city text, value real)''')for table in c.execute("SELECT name FROM sqlite_master WHERE type='table'"):
print("Table", table[0])
c.execute('''INSERT INTO test_table VALUES
('2017-6-25', 'bj', 100)''')
c.execute('''INSERT INTO test_table VALUES
('2017-6-25', 'pydataroad', 150)''')
c.execute("SELECT * FROM test_table")
print(c.fetchall())Table test_table
[('2017-6-25', 'bj', 100.0), ('2017-6-25', 'pydataroad', 150.0)]Für die visuelle Vorschau von Daten in der SQLite-Datenbank gibt es viele Tools, die verwendet werden können Das, was ich hier verwende, ist SQLite Studio. Es ist ein kostenloses Tool, das keine Installation erfordert. Interessierte Schüler können es nach dem Herunterladen verwenden.
https://sqlitestudio.pl/index.rvt?act=download
Der Effekt der Datenvorschau ist wie folgt:

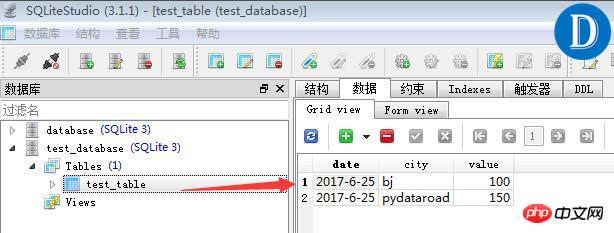
Verwenden Sie Pandas, um SQLite-Datendateien zu lesen
Wie aus den laufenden Ergebnissen des obigen Codes ersichtlich ist, ist das Ergebnis der Datenabfrage eine Liste aus Tupeln. Die Listendaten von Python sind möglicherweise für die weitere Datenverarbeitung und -analyse unpraktisch. Sie können sich vorstellen, dass die Effizienz des Durchlaufens der Liste zum Abrufen der Daten relativ gering ist, wenn die Datenbanktabelle 1 Million oder mehr Datenzeilen enthält.
Zu diesem Zeitpunkt können wir erwägen, die von Pandas bereitgestellten Funktionen zu verwenden, um relevante Dateninformationen aus der SQLite-Datenbankdatei zu lesen und sie in einem DataFrame zu speichern, um die weitere Verarbeitung zu erleichtern.
Pandas bietet zwei Funktionen, die beide Informationen aus Datendateien mit dem Suffix „.sqlite“ lesen können.
read_sql()
read_sql_query()
import pandas as pdwith sqlite3.connect('test_database.sqlite') as con:# read_sql_query和read_sql都能通过SQL语句从数据库文件中获取数据信息df = pd.read_sql_query("SELECT * FROM test_table", con=con)# df = pd.read_sql("SELECT * FROM test_table", con=con)print(df.shape)
print(df.dtypes)
print(df.head())<code style="font-size: 14px; font-family: Roboto, 'Courier New', Consolas, Inconsolata, Courier, monospace; margin: auto 5px; white-space: pre; border-radius: 3px; display: block !important; overflow: auto; padding: 1px;">(2, 3) date object city object value float64 dtype: object date city value 0 2017-6-25 bj 100.0 1 2017-6-25 pydataroad 150.0<br></code>
Das obige ist der detaillierte Inhalt vonWie verwende ich Python zum Lesen und Verarbeiten von Dateisuffixen?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1382
1382
 52
52

 PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python: Code Beispiele und Vergleich
Apr 15, 2025 am 12:07 AM
PHP und Python haben ihre eigenen Vor- und Nachteile, und die Wahl hängt von den Projektbedürfnissen und persönlichen Vorlieben ab. 1.PHP eignet sich für eine schnelle Entwicklung und Wartung großer Webanwendungen. 2. Python dominiert das Gebiet der Datenwissenschaft und des maschinellen Lernens.
 Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Wie ist die GPU -Unterstützung für Pytorch bei CentOS?
Apr 14, 2025 pm 06:48 PM
Aktivieren Sie die Pytorch -GPU -Beschleunigung am CentOS -System erfordert die Installation von CUDA-, CUDNN- und GPU -Versionen von Pytorch. Die folgenden Schritte führen Sie durch den Prozess: Cuda und Cudnn Installation Bestimmen Sie die CUDA-Version Kompatibilität: Verwenden Sie den Befehl nvidia-smi, um die von Ihrer NVIDIA-Grafikkarte unterstützte CUDA-Version anzuzeigen. Beispielsweise kann Ihre MX450 -Grafikkarte CUDA11.1 oder höher unterstützen. Download und installieren Sie Cudatoolkit: Besuchen Sie die offizielle Website von Nvidiacudatoolkit und laden Sie die entsprechende Version gemäß der höchsten CUDA -Version herunter und installieren Sie sie, die von Ihrer Grafikkarte unterstützt wird. Installieren Sie die Cudnn -Bibliothek:
 Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python gegen JavaScript: Community, Bibliotheken und Ressourcen
Apr 15, 2025 am 12:16 AM
Python und JavaScript haben ihre eigenen Vor- und Nachteile in Bezug auf Gemeinschaft, Bibliotheken und Ressourcen. 1) Die Python-Community ist freundlich und für Anfänger geeignet, aber die Front-End-Entwicklungsressourcen sind nicht so reich wie JavaScript. 2) Python ist leistungsstark in Bibliotheken für Datenwissenschaft und maschinelles Lernen, während JavaScript in Bibliotheken und Front-End-Entwicklungsbibliotheken und Frameworks besser ist. 3) Beide haben reichhaltige Lernressourcen, aber Python eignet sich zum Beginn der offiziellen Dokumente, während JavaScript mit Mdnwebdocs besser ist. Die Wahl sollte auf Projektbedürfnissen und persönlichen Interessen beruhen.
 Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Detaillierte Erklärung des Docker -Prinzips
Apr 14, 2025 pm 11:57 PM
Docker verwendet Linux -Kernel -Funktionen, um eine effiziente und isolierte Anwendungsumgebung zu bieten. Sein Arbeitsprinzip lautet wie folgt: 1. Der Spiegel wird als schreibgeschützte Vorlage verwendet, die alles enthält, was Sie für die Ausführung der Anwendung benötigen. 2. Das Union File System (UnionFS) stapelt mehrere Dateisysteme, speichert nur die Unterschiede, speichert Platz und beschleunigt. 3. Der Daemon verwaltet die Spiegel und Container, und der Kunde verwendet sie für die Interaktion. 4. Namespaces und CGroups implementieren Container -Isolation und Ressourcenbeschränkungen; 5. Mehrere Netzwerkmodi unterstützen die Containerverbindung. Nur wenn Sie diese Kernkonzepte verstehen, können Sie Docker besser nutzen.
 Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Miniopen CentOS -Kompatibilität
Apr 14, 2025 pm 05:45 PM
Minio-Objektspeicherung: Hochleistungs-Bereitstellung im Rahmen von CentOS System Minio ist ein hochleistungsfähiges, verteiltes Objektspeichersystem, das auf der GO-Sprache entwickelt wurde und mit Amazons3 kompatibel ist. Es unterstützt eine Vielzahl von Kundensprachen, darunter Java, Python, JavaScript und Go. In diesem Artikel wird kurz die Installation und Kompatibilität von Minio zu CentOS -Systemen vorgestellt. CentOS -Versionskompatibilitätsminio wurde in mehreren CentOS -Versionen verifiziert, einschließlich, aber nicht beschränkt auf: CentOS7.9: Bietet einen vollständigen Installationshandbuch für die Clusterkonfiguration, die Umgebungsvorbereitung, die Einstellungen von Konfigurationsdateien, eine Festplattenpartitionierung und Mini
 Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Wie man eine verteilte Schulung von Pytorch auf CentOS betreibt
Apr 14, 2025 pm 06:36 PM
Pytorch Distributed Training on CentOS -System erfordert die folgenden Schritte: Pytorch -Installation: Die Prämisse ist, dass Python und PIP im CentOS -System installiert sind. Nehmen Sie abhängig von Ihrer CUDA -Version den entsprechenden Installationsbefehl von der offiziellen Pytorch -Website ab. Für CPU-Schulungen können Sie den folgenden Befehl verwenden: PipinstallTorChTorChVisionTorChaudio Wenn Sie GPU-Unterstützung benötigen, stellen Sie sicher, dass die entsprechende Version von CUDA und CUDNN installiert ist und die entsprechende Pytorch-Version für die Installation verwenden. Konfiguration der verteilten Umgebung: Verteiltes Training erfordert in der Regel mehrere Maschinen oder mehrere Maschinen-Mehrfach-GPUs. Ort
 So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
So wählen Sie die Pytorch -Version auf CentOS aus
Apr 14, 2025 pm 06:51 PM
Bei der Installation von PyTorch am CentOS -System müssen Sie die entsprechende Version sorgfältig auswählen und die folgenden Schlüsselfaktoren berücksichtigen: 1. Kompatibilität der Systemumgebung: Betriebssystem: Es wird empfohlen, CentOS7 oder höher zu verwenden. CUDA und CUDNN: Pytorch -Version und CUDA -Version sind eng miteinander verbunden. Beispielsweise erfordert Pytorch1.9.0 CUDA11.1, während Pytorch2.0.1 CUDA11.3 erfordert. Die Cudnn -Version muss auch mit der CUDA -Version übereinstimmen. Bestimmen Sie vor der Auswahl der Pytorch -Version unbedingt, dass kompatible CUDA- und CUDNN -Versionen installiert wurden. Python -Version: Pytorch Official Branch
 So aktualisieren Sie Pytorch auf die neueste Version von CentOS
Apr 14, 2025 pm 06:15 PM
So aktualisieren Sie Pytorch auf die neueste Version von CentOS
Apr 14, 2025 pm 06:15 PM
Das Aktualisieren von PyTorch auf der neuesten Version von CentOS kann die folgenden Schritte ausführen: Methode 1: Aktualisieren von PIP mit PIP: Stellen Sie zunächst sicher, dass Ihr PIP die neueste Version ist, da ältere Versionen von PIP möglicherweise nicht in der Lage sind, die neueste Version von PyTorch ordnungsgemäß zu installieren. Pipinstall-upgradePip Die alte Version von Pytorch (falls installiert): PipuninstallTorChTorChVisionTorChaudio-Installation Neueste
