

Wie implementiert mongoDB Paging?

Dieser Artikel stellt hauptsächlich die beiden Methoden von mongoDB zur Implementierung von Paging vor. Interessierte Freunde können sich darauf beziehen
MongoDBs Paging query verwendet die drei Funktionen array limit(), skip() und sort(), um eine Paging-Abfrage durchzuführen.
Das Folgende sind meine Testdaten
db.test.find().sort({"age":1});

Die erste Methode
Fragen Sie die Daten auf der ersten Seite ab: db.test.find().sort({"age":1}).limit(2); 🎜>


Die zweite Methode
Fragen Sie die Daten auf der ersten Seite ab: db.test.find().sort({"age":1}).limit( 2);
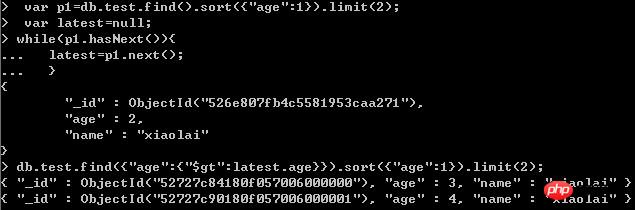
Überspringen überspringt zu viele Datensätze und die Effizienz ist etwas geringNach sorgfältiger Überlegung ist die zweite Methode Es ist in der Tat nicht zum Überspringen von Seiten geeignet und auch nicht sehr effizient.
Für große Datenmengen müssen wir eine spezielle Verarbeitung durchführen
Es gibt die folgenden zwei Methoden
Die erste Methode
 Begrenzen Sie die Anzahl der Paging-Seiten, ähnlich der Paging-Verarbeitung von Baidu, die nur zeigt die vorherigen siebenhundert Datensätze an, so dass es keinen Grund gibt, Leistungsprobleme zu berücksichtigen. Schließlich blättern die meisten Leute einfach auf den ersten zehn Seiten und finden, was sie brauchen.
Begrenzen Sie die Anzahl der Paging-Seiten, ähnlich der Paging-Verarbeitung von Baidu, die nur zeigt die vorherigen siebenhundert Datensätze an, so dass es keinen Grund gibt, Leistungsprobleme zu berücksichtigen. Schließlich blättern die meisten Leute einfach auf den ersten zehn Seiten und finden, was sie brauchen.
Die folgenden statistischen Ergebnisse sollten geschätzt werden über den Anteil dieser gefundenen Datensätze. Schätzen Sie die Gesamtzahl der Datensätze.
Die zweite MethodeVorausgesetzt, es ist sortiert Zur ID können wir der ID folgen. Die Seriennummer der Seite, auf der sich die ID befindet, wird in redis/MemberCached gespeichert,
so, vorausgesetzt, jede Seite hat 10 Datensätze
ID-Seite
1 1
2 1
. . .
10 1
11 2
12 2
. . . .
20 2
Auf diese Weise können wir beim Überprüfen der ersten Seite direkt zehn Datenelemente abrufen
Angenommen, es gibt 100 Millionen Datenelemente, einen Datensatz Die ID belegt 4 Bytes. Andere Informationen belegen ein Byte und ein Datensatz belegt 5 Bytes.
1 0000 0000 *5/(1024*1024)=476 MB
Dieser Ansatz verwendet im Allgemeinen Raum für Zeit Der größte Teil der Datenbankabfragezeit wird für die Verbindung zur Datenbank aufgewendet. Das Einfügen in den Cache kann die Abfrage erheblich beschleunigen
Das obige ist der detaillierte Inhalt vonWie implementiert mongoDB Paging?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1391
1391
 52
52

 So erkennen Sie echte und gefälschte Schuhkartons mit Nike-Schuhen (beherrschen Sie einen Trick, um sie leicht zu identifizieren)
Sep 02, 2024 pm 04:11 PM
So erkennen Sie echte und gefälschte Schuhkartons mit Nike-Schuhen (beherrschen Sie einen Trick, um sie leicht zu identifizieren)
Sep 02, 2024 pm 04:11 PM
Als weltbekannte Sportmarke haben die Schuhe von Nike viel Aufmerksamkeit erregt. Allerdings gibt es auch eine Vielzahl gefälschter Produkte auf dem Markt, darunter auch gefälschte Nike-Schuhkartons. Die Unterscheidung echter Schuhkartons von gefälschten ist für den Schutz der Rechte und Interessen der Verbraucher von entscheidender Bedeutung. In diesem Artikel erfahren Sie einige einfache und effektive Methoden, mit denen Sie zwischen echten und gefälschten Schuhkartons unterscheiden können. 1: Titel der Außenverpackung Wenn Sie sich die Außenverpackung von Nike-Schuhkartons ansehen, können Sie viele subtile Unterschiede feststellen. Originale Nike-Schuhkartons bestehen in der Regel aus hochwertigen Papiermaterialien, die sich glatt anfühlen und keinen offensichtlichen stechenden Geruch verströmen. Die Schriftarten und Logos auf authentischen Schuhkartons sind in der Regel klar und detailliert und es gibt keine Unschärfen oder Farbinkonsistenzen. 2: Der Logo-Heißprägetitel ist normalerweise auf dem Original-Schuhkarton abgebildet
 So konfigurieren Sie die automatische Expansion von MongoDB auf Debian
Apr 02, 2025 am 07:36 AM
So konfigurieren Sie die automatische Expansion von MongoDB auf Debian
Apr 02, 2025 am 07:36 AM
In diesem Artikel wird vorgestellt, wie MongoDB im Debian -System konfiguriert wird, um eine automatische Expansion zu erzielen. Die Hauptschritte umfassen das Einrichten der MongoDB -Replikat -Set und die Überwachung des Speicherplatzes. 1. MongoDB Installation Erstens stellen Sie sicher, dass MongoDB im Debian -System installiert ist. Installieren Sie den folgenden Befehl: sudoaptupdatesudoaptinstall-emongoDB-org 2. Konfigurieren von MongoDB Replika-Set MongoDB Replikate sorgt für eine hohe Verfügbarkeit und Datenreduktion, was die Grundlage für die Erreichung der automatischen Kapazitätserweiterung darstellt. Start MongoDB Service: SudosystemctlstartMongodsudosysys
 Wie Sie eine hohe Verfügbarkeit von MongoDB bei Debian gewährleisten
Apr 02, 2025 am 07:21 AM
Wie Sie eine hohe Verfügbarkeit von MongoDB bei Debian gewährleisten
Apr 02, 2025 am 07:21 AM
In diesem Artikel wird beschrieben, wie man eine hoch verfügbare MongoDB -Datenbank für ein Debian -System erstellt. Wir werden mehrere Möglichkeiten untersuchen, um sicherzustellen, dass die Datensicherheit und -Dienste weiter funktionieren. Schlüsselstrategie: ReplicaSet: Replicaset: Verwenden Sie Replikaten, um Datenreduktion und automatisches Failover zu erreichen. Wenn ein Master -Knoten fehlschlägt, wählt der Replikate -Set automatisch einen neuen Masterknoten, um die kontinuierliche Verfügbarkeit des Dienstes zu gewährleisten. Datensicherung und Wiederherstellung: Verwenden Sie den Befehl mongodump regelmäßig, um die Datenbank zu sichern und effektive Wiederherstellungsstrategien zu formulieren, um das Risiko eines Datenverlusts zu behandeln. Überwachung und Alarme: Überwachungsinstrumente (wie Prometheus, Grafana) bereitstellen, um den laufenden Status von MongoDB in Echtzeit zu überwachen, und
 So gehen Sie mit Video-Jitter um (praktische Tipps zur Beseitigung von Video-Jitter)
Sep 02, 2024 pm 03:53 PM
So gehen Sie mit Video-Jitter um (praktische Tipps zur Beseitigung von Video-Jitter)
Sep 02, 2024 pm 03:53 PM
Verwacklungen sind ein häufiges Problem beim Aufnehmen oder Ansehen von Videos, das das Seherlebnis beeinträchtigt und die Qualität des Videos verringert. In diesem Artikel werden einige praktische Tipps vorgestellt, die Ihnen helfen, mit Video-Jitter-Problemen umzugehen und Ihre Videos stabiler und flüssiger zu machen. 1. Verwenden Sie die Stabilisatortechnologie, um Videoverwacklungen zu beseitigen. Die Verwendung eines Stabilisatorgeräts ist eine der einfachsten und effektivsten Möglichkeiten, das Problem der Videoverwacklungen zu lösen. Stabilisatoren können durch Handzittern oder andere Faktoren verursachte Verwacklungen reduzieren, indem sie die Kamera ausbalancieren und stabilisieren. 2. Einführung in die Software-Videostabilisierungstechnologie Die Software-Videostabilisierungstechnologie eliminiert Jitter durch Anpassung des Videos in der Nachbearbeitung. Diese Technologie kann durch die Verfolgung von Schlüsselbildern, die Anwendung von Bildstabilisierungsalgorithmen und mehr für eine bessere Videostabilisierung sorgen. 3. Video-Jitter-Erkennung und automatische Reparatur
 So machen Sie Ihre Bankeinlagen kostengünstiger (Geldsparstrategie enthüllt)
Aug 21, 2024 pm 04:21 PM
So machen Sie Ihre Bankeinlagen kostengünstiger (Geldsparstrategie enthüllt)
Aug 21, 2024 pm 04:21 PM
In der modernen Gesellschaft sind wir alle untrennbar mit Bankkonten verbunden, und das Sparen von Geld ist die grundlegendste Interaktion zwischen uns und Banken. Allerdings haben viele Menschen gewisse Zweifel und Unklarheiten darüber, wie sie ihre Ersparnisse kosteneffizienter gestalten können. In diesem Artikel erhalten Sie einige praktische Ratschläge zum Geldsparen, die Ihnen dabei helfen, den Wert Ihrer Ersparnisse zu steigern. Absatz 1 Finanzplan: Ein Plan für zukünftiges Vermögenswachstum Die Entwicklung eines Finanzplans ist die Grundlage für die effektive Verwaltung und Steigerung Ihrer Ersparnisse. Identifizieren Sie Ihre kurz- und langfristigen finanziellen Ziele. Entwickeln Sie auf der Grundlage dieser Ziele einen spezifischen Sparplan und legen Sie für jedes Ziel den Zeitpunkt, den Betrag und die Einzahlungsmethode fest. Überprüfen Sie Ihren Plan regelmäßig und passen Sie ihn an veränderte wirtschaftliche Bedingungen und persönliche Bedürfnisse an. Absatz 2: Auswahl eines Sparkontos mit hohem Zinssatz: Erhöhen Sie die Rendite Ihrer Einlagen. Wählen Sie einen hohen Zinssatz
 Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Navicat -Methode zum Anzeigen von MongoDB -Datenbankkennwort
Apr 08, 2025 pm 09:39 PM
Es ist unmöglich, das MongoDB -Passwort direkt über Navicat anzuzeigen, da es als Hash -Werte gespeichert ist. So rufen Sie verlorene Passwörter ab: 1. Passwörter zurücksetzen; 2. Überprüfen Sie die Konfigurationsdateien (können Hash -Werte enthalten). 3. Überprüfen Sie Codes (May Hardcode -Passwörter).
 Großes Update von Pi Coin: Die PI Bank kommt!
Mar 03, 2025 pm 06:18 PM
Großes Update von Pi Coin: Die PI Bank kommt!
Mar 03, 2025 pm 06:18 PM
Pinetwork startet Pibank, eine revolutionäre Mobile -Banking -Plattform! PiNetwork today released a major update on Elmahrosa (Face) PIMISRBank, referred to as PiBank, which perfectly integrates traditional banking services with PiNetwork cryptocurrency functions to realize the atomic exchange of fiat currencies and cryptocurrencies (supports the swap between fiat currencies such as the US dollar, euro, and Indonesian rupiah with cryptocurrencies such as PiCoin, USDT, and USDC). Was ist der Charme von Pibank? Lass uns herausfinden! Die Hauptfunktionen von Pibank: One-Stop-Management von Bankkonten und Kryptowährungsvermögen. Unterstützen Sie Echtzeittransaktionen und übernehmen Sie Biospezies
 Was ist die CentOS MongoDB -Backup -Strategie?
Apr 14, 2025 pm 04:51 PM
Was ist die CentOS MongoDB -Backup -Strategie?
Apr 14, 2025 pm 04:51 PM
Detaillierte Erläuterung der effizienten Backup -Strategie von MongoDB im CentOS -System Dieser Artikel wird die verschiedenen Strategien zur Implementierung der MongoDB -Sicherung im CentOS -System ausführlich einführen, um die Datensicherheit und die Geschäftsübergang zu gewährleisten. Wir werden manuelle Backups, zeitgesteuerte Sicherungen, automatisierte Skriptsicherungen und Sicherungsmethoden in Docker -Containerumgebungen abdecken und Best Practices für die Verwaltung von Sicherungsdateien bereitstellen. Handbuch Sicherung: Verwenden Sie den Befehl mongodump, um eine manuelle vollständige Sicherung durchzuführen.
