
 Backend-Entwicklung
Python-Tutorial
Beispiel für den Prozess des Crawlens von qq-Musik mit Python
Backend-Entwicklung
Python-Tutorial
Beispiel für den Prozess des Crawlens von qq-Musik mit Python
Beispiel für den Prozess des Crawlens von qq-Musik mit Python

1. Vorwort
Manchmal möchte ich gute Musik herunterladen, aber Beim Herunterladen von einer Webseite gibt es jedes Mal einen lästigen Anmeldevorgang. Hier kommt also ein qqmusic-Crawler. Zumindest denke ich, dass das Wichtigste für einen For-Loop-Crawler darin besteht, die URL des zu crawlenden Elements zu finden. Beginnen Sie unten mit der Suche (lachen Sie mich nicht aus, wenn ich falsch liege)
<br>
2. Python crawlt QQ-Musik-Singles
Ein Video von MOOC, das ich mir zuvor angesehen habe, gab eine gute Erklärung der allgemeinen Schritte zum Schreiben eines Crawlers. Wir werden dies auch befolgen.
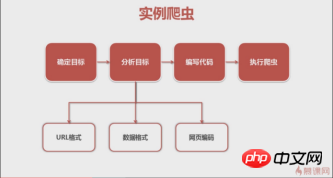
Crawler-Schritte
1. Bestimmen Sie das Ziel
Zuerst müssen wir unser Ziel klären. Diesmal haben wir die Singles von QQ Music-Sänger Andy Lau gecrawlt.
(Baidu-Enzyklopädie) -> Analyseziel (Strategie: URL-Format (Bereich), Datenformat, Webseitenkodierung) -> Crawler ausführen
2. Analyseziel
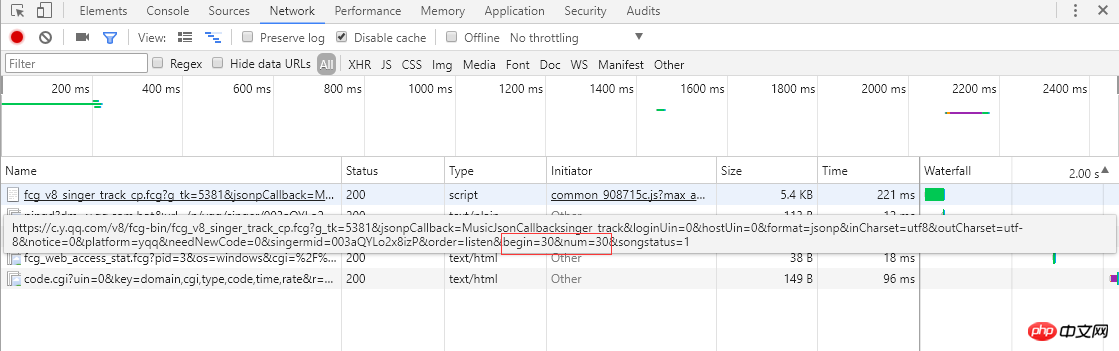
Song-Link:
Aus dem Screenshot links können Sie erkennen, dass Singles Paging verwenden, um Songinformationen anzuordnen 30 Artikel, insgesamt 30 Seiten. Wenn Sie auf die Seitenzahl oder das „>“ ganz rechts klicken, wird der Browser eine asynchrone Ajax-Anfrage an den Server senden. Über den Link können Sie die Parameter „Begin“ und „Num“ sehen Start-Song-Index (der Screenshot ist die 2. Seite, der Start-Index ist 30) und eine Seite gibt 30 Elemente zurück, und der Server antwortet, indem er Song-Informationen im JSON-Format zurückgibt (MusicJsonCallbacksinger_track({"code":0,"data": {"list":[{"Flisten_count1":. .....]})), wenn Sie nur Songinformationen erhalten möchten, können Sie die Linkanforderung direkt zusammenfügen und die zurückgegebenen JSON-Formatdaten analysieren. Hier verwenden wir nicht die Methode zum direkten Parsen des Datenformats. Nachdem jede Seite mit einzelnen Informationen abgerufen und analysiert wurde, klicken Sie auf „>“, um zur nächsten Seite zu springen und mit dem Parsen fortzufahren Einzelinformationen werden analysiert und aufgezeichnet. Fordern Sie abschließend den Link jedes einzelnen an, um detaillierte Einzelinformationen zu erhalten.
Der Screenshot rechts ist der Quellcode der Webseite. Alle Songinformationen befinden sich in der div-Floating-Ebene mit dem Klassennamen mod_songlist. Es gibt kein div mit dem Klassennamen songlist_list. Unter der Sequenzliste ul zeigt jedes Unterelement li eine Single an, und das a-Tag unter dem Klassennamen songlist__album enthält den Link, den Namen und die Dauer der Single.
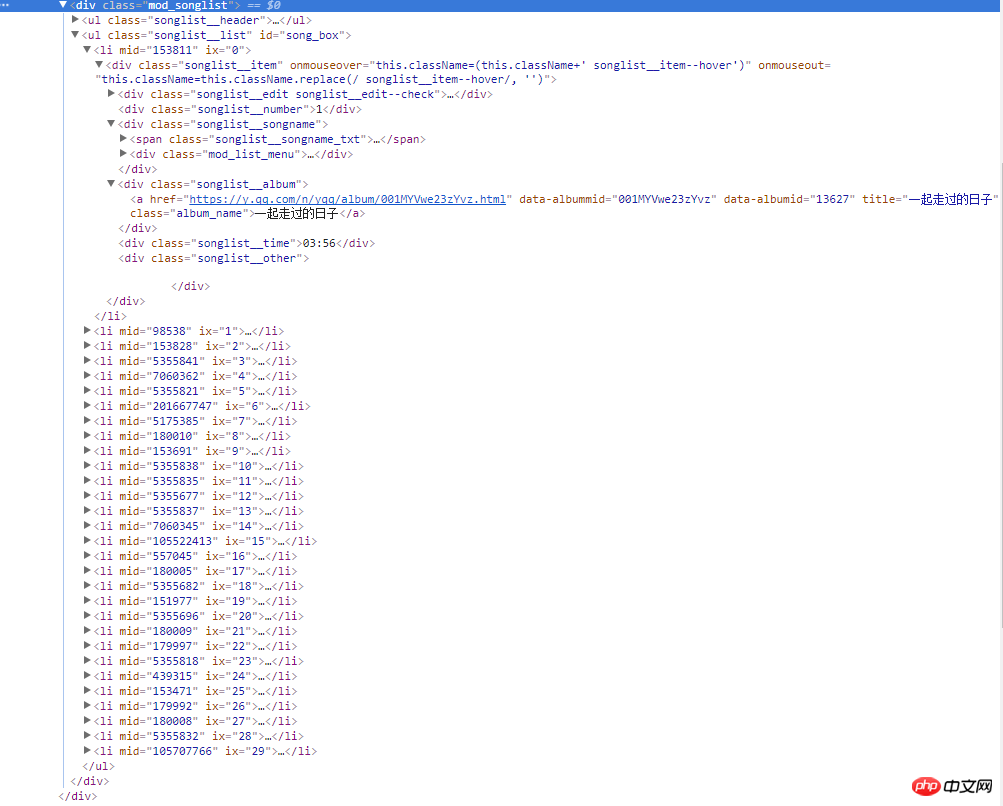
3. Code schreiben
1 ) Laden Sie den Inhalt der Webseite herunter. Hier verwenden wir die Urllib-Standardbibliothek und kapseln eine Download-Methode:
def download(url, user_agent='wswp', num_retries=2):
if url is None:
return None
print('Downloading:', url)
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}
request = urllib.request.Request(url, headers=headers) # 设置用户代理wswp(Web Scraping with Python)
try:
html = urllib.request.urlopen(request).read().decode('utf-8')
except urllib.error.URLError as e:
print('Downloading Error:', e.reason)
html = None
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
# retry when return code is 5xx HTTP erros
return download(url, num_retries-1) # 请求失败,默认重试2次,
return html<br>2) Hier verwenden wir den dritten Inhalt. Party-Plug-in BeautifulSoup ,Weitere Informationen finden Sie in der BeautifulSoup-API.
def music_scrapter(html, page_num=0):
try:
soup = BeautifulSoup(html, 'html.parser')
mod_songlist_div = soup.find_all('div', class_='mod_songlist')
songlist_ul = mod_songlist_div[1].find('ul', class_='songlist__list')
'''开始解析li歌曲信息'''
lis = songlist_ul.find_all('li')
for li in lis:
a = li.find('div', class_='songlist__album').find('a')
music_url = a['href'] # 单曲链接
urls.add_new_url(music_url) # 保存单曲链接
# print('music_url:{0} '.format(music_url))
print('total music link num:%s' % len(urls.new_urls))
next_page(page_num+1)
except TimeoutException as err:
print('解析网页出错:', err.args)
return next_page(page_num + 1)
return Nonedef get_music():
try:
while urls.has_new_url():
# print('urls count:%s' % len(urls.new_urls))
'''跳转到歌曲链接,获取歌曲详情'''
new_music_url = urls.get_new_url()
print('url leave count:%s' % str( len(urls.new_urls) - 1))
html_data_info = download(new_music_url)
# 下载网页失败,直接进入下一循环,避免程序中断
if html_data_info is None:
continue
soup_data_info = BeautifulSoup(html_data_info, 'html.parser')
if soup_data_info.find('div', class_='none_txt') is not None:
print(new_music_url, ' 对不起,由于版权原因,暂无法查看该专辑!')
continue
mod_songlist_div = soup_data_info.find('div', class_='mod_songlist')
songlist_ul = mod_songlist_div.find('ul', class_='songlist__list')
lis = songlist_ul.find_all('li')
del lis[0] # 删除第一个li
# print('len(lis):$s' % len(lis))
for li in lis:
a_songname_txt = li.find('div', class_='songlist__songname').find('span', class_='songlist__songname_txt').find('a')
if 'https' not in a_songname_txt['href']: #如果单曲链接不包含协议头,加上
song_url = 'https:' + a_songname_txt['href']
song_name = a_songname_txt['title']
singer_name = li.find('div', class_='songlist__artist').find('a').get_text()
song_time =li.find('div', class_='songlist__time').get_text()
music_info = {}
music_info['song_name'] = song_name
music_info['song_url'] = song_url
music_info['singer_name'] = singer_name
music_info['song_time'] = song_time
collect_data(music_info)
except Exception as err: # 如果解析异常,跳过
print('Downloading or parse music information error continue:', err.args)Führen Sie den Crawler aus
<span style="font-size: 16px;">爬虫跑起来了,一页一页地去爬取专辑的链接,并保存到集合中,最后通过get_music()方法获取单曲的名称,链接,歌手名称和时长并保存到Excel文件中。</span><br><span style="font-size: 14px;"><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/a1138f33f00f8d95b52fbfe06e562d24-4.png" class="lazy" alt="" style="max-width:90%" style="max-width:90%"><strong><img src="/static/imghw/default1.png" data-src="https://img.php.cn/upload/article/000/000/001/9282b5f7a1dc4a90cee186c16d036272-5.png" class="lazy" alt=""></strong></span>
<br>
3 Crawler Holen Sie sich die Zusammenfassung der QQ Music-Singles
1 Die Single verwendet Paging, um Daten im JSON-Format vom Server über eine asynchrone Ajax-Anfrage abzurufen Rendern Sie es auf Seiten und Browser-Adressleisten-Links bleiben unverändert und können nicht über gespleißte Links angefordert werden. Zuerst dachte ich darüber nach, Ajax-Anfragen über die Python-Urllib-Bibliothek zu simulieren, aber dann dachte ich darüber nach, Selenium zu verwenden. Selenium kann den tatsächlichen Betrieb des Browsers sehr gut simulieren, und die Positionierung von Seitenelementen ist ebenfalls sehr praktisch. Es simuliert das Klicken auf die nächste Seite, das ständige Wechseln der einzelnen Paginierung und das anschließende Parsen des Webseiten-Quellcodes über BeautifulSoup, um die einzelne Seite zu erhalten Information.
2.URL-Linkmanager verwendet eine Sammlungsdatenstruktur, um einzelne Links zu speichern. Da mehrere Singles aus demselben Album stammen können (die Album-URL ist dieselbe), kann dies die Anzahl der Anfragen reduzieren.
class UrlManager(object):<br> def __init__(self):<br> self.new_urls = set() # 使用集合数据结构,过滤重复元素<br> self.old_urls = set() # 使用集合数据结构,过滤重复元素
def add_new_url(self, url):<br> if url is None:<br> return<br> if url not in self.new_urls and url not in self.old_urls:<br> self.new_urls.add(url)<br><br> def add_new_urls(self, urls):<br> if urls is None or len(urls) == 0:<br> return<br> for url in urls:<br> self.add_new_url(url)<br><br> def has_new_url(self):<br> return len(self.new_urls) != 0<br><br> def get_new_url(self):<br> new_url = self.new_urls.pop()<br> self.old_urls.add(new_url)<br> return new_url<br><br>
3. Es ist sehr praktisch, Excel über das Python-Drittanbieter-Plug-in openpyxl und die einzelnen Informationen zu lesen und zu schreiben lassen sich gut durch Excel-Dateien speichern.
def write_to_excel(self, content):<br> try:<br> for row in content:<br> self.workSheet.append([row['song_name'], row['song_url'], row['singer_name'], row['song_time']])<br> self.workBook.save(self.excelName) # 保存单曲信息到Excel文件<br> except Exception as arr:<br> print('write to excel error', arr.args)<br><br>
4. Nachtrag
Endlich muss ich feiern, schließlich habe ich die einzelnen Informationen von QQ Music erfolgreich gecrawlt ENTFERNT. Dieses Mal konnten wir die Single erfolgreich crawlen. Dieses Mal haben wir nur einige einfache Funktionen von Selenium verwendet. Wir werden in Zukunft mehr über Selenium erfahren, nicht nur in Bezug auf Crawler, sondern auch in Bezug auf die UI-Automatisierung.
Punkte, die in Zukunft optimiert werden müssen:
1. Es gibt viele Download-Links und es wird langsam sein, einen nach dem anderen herunterzuladen Verwenden Sie später das gleichzeitige Herunterladen mit mehreren Threads.
2. Um zu vermeiden, dass der Server die IP deaktiviert und später zu häufig auf denselben Domainnamen zugreift, gibt es einen Wartemechanismus. und zwischen den einzelnen Anfragen gibt es eine Wartezeit.
3. Das Parsen von Webseiten ist ein wichtiger Prozess. Derzeit ist die BeautifulSoup-Bibliothek nicht so effizient als lxml. Als nächstes werde ich versuchen, lxml zu verwenden.
Das obige ist der detaillierte Inhalt vonBeispiel für den Prozess des Crawlens von qq-Musik mit Python. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen



 Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?
Apr 02, 2025 am 07:12 AM
Was soll ich tun, wenn das Modul '__builtin__' beim Laden der Gurkendatei in Python 3.6 nicht gefunden wird?
Apr 02, 2025 am 07:12 AM
Laden Sie Gurkendateien in Python 3.6 Umgebungsbericht Fehler: ModulenotFoundError: Nomodulennamen ...
 Ist Debian Strings kompatibel mit mehreren Browsern
Apr 02, 2025 am 08:30 AM
Ist Debian Strings kompatibel mit mehreren Browsern
Apr 02, 2025 am 08:30 AM
"DebianStrings" ist kein Standardbegriff und seine spezifische Bedeutung ist noch unklar. Dieser Artikel kann seine Browserkompatibilität nicht direkt kommentieren. Wenn sich jedoch "DebianStrings" auf eine Webanwendung bezieht, die auf einem Debian -System ausgeführt wird, hängt seine Browserkompatibilität von der technischen Architektur der Anwendung selbst ab. Die meisten modernen Webanwendungen sind für die Kompatibilität des Cross-Browsers verpflichtet. Dies beruht auf den folgenden Webstandards und der Verwendung gut kompatibler Front-End-Technologien (wie HTML, CSS, JavaScript) und Back-End-Technologien (wie PHP, Python, Node.js usw.). Um sicherzustellen, dass die Anwendung mit mehreren Browsern kompatibel ist, müssen Entwickler häufig Kreuzbrowser-Tests durchführen und die Reaktionsfähigkeit verwenden
 Benötigt die XML -Änderung eine Programmierung?
Apr 02, 2025 pm 06:51 PM
Benötigt die XML -Änderung eine Programmierung?
Apr 02, 2025 pm 06:51 PM
Das Ändern des XML -Inhalts erfordert die Programmierung, da die Zielknoten genau aufgefasst werden müssen, um hinzuzufügen, zu löschen, zu ändern und zu überprüfen. Die Programmiersprache verfügt über entsprechende Bibliotheken, um XML zu verarbeiten, und bietet APIs zur Durchführung sicherer, effizienter und steuerbarer Vorgänge wie Betriebsdatenbanken.
 Ist die Konversionsgeschwindigkeit beim Umwandeln von XML in PDF auf Mobiltelefon schnell?
Apr 02, 2025 pm 10:09 PM
Ist die Konversionsgeschwindigkeit beim Umwandeln von XML in PDF auf Mobiltelefon schnell?
Apr 02, 2025 pm 10:09 PM
Die Geschwindigkeit der mobilen XML zu PDF hängt von den folgenden Faktoren ab: der Komplexität der XML -Struktur. Konvertierungsmethode für mobile Hardware-Konfiguration (Bibliothek, Algorithmus) -Codierungsoptimierungsmethoden (effiziente Bibliotheken, Optimierung von Algorithmen, Cache-Daten und Nutzung von Multi-Threading). Insgesamt gibt es keine absolute Antwort und es muss gemäß der spezifischen Situation optimiert werden.
 So ändern Sie den Kommentarinhalt in XML
Apr 02, 2025 pm 06:15 PM
So ändern Sie den Kommentarinhalt in XML
Apr 02, 2025 pm 06:15 PM
Für kleine XML -Dateien können Sie den Annotationsinhalt direkt durch einen Texteditor ersetzen. Für große Dateien wird empfohlen, den XML -Parser zu verwenden, um ihn zu ändern, um Effizienz und Genauigkeit zu gewährleisten. Seien Sie vorsichtig, wenn Sie XML -Kommentare löschen. Beibehalten von Kommentaren hilft das Verständnis und die Wartung von Code normalerweise. Erweiterte Tipps bieten Python -Beispielcode, um Kommentare mit XML -Parser zu ändern. Die spezifische Implementierung muss jedoch gemäß der verwendeten XML -Bibliothek angepasst werden. Achten Sie bei der Änderung von XML -Dateien auf Codierungsprobleme. Es wird empfohlen, die UTF-8-Codierung zu verwenden und das Codierungsformat anzugeben.
 Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 08:54 PM
Gibt es eine mobile App, die XML in PDF umwandeln kann?
Apr 02, 2025 pm 08:54 PM
Eine Anwendung, die XML direkt in PDF konvertiert, kann nicht gefunden werden, da es sich um zwei grundlegend unterschiedliche Formate handelt. XML wird zum Speichern von Daten verwendet, während PDF zur Anzeige von Dokumenten verwendet wird. Um die Transformation abzuschließen, können Sie Programmiersprachen und Bibliotheken wie Python und ReportLab verwenden, um XML -Daten zu analysieren und PDF -Dokumente zu generieren.
 Wie definiere ich einen Enum -Typ in Protobuf- und Associate -String -Konstanten?
Apr 02, 2025 pm 03:36 PM
Wie definiere ich einen Enum -Typ in Protobuf- und Associate -String -Konstanten?
Apr 02, 2025 pm 03:36 PM
Probleme bei der Definition von String Constant -Aufzählung in Protobuf Bei der Verwendung von Protobuf stellen Sie häufig Situationen auf, in denen Sie den Enum -Typ mit String -Konstanten verknüpfen müssen ...
 Wie steuert ich die Größe von XML, die in Bilder konvertiert sind?
Apr 02, 2025 pm 07:24 PM
Wie steuert ich die Größe von XML, die in Bilder konvertiert sind?
Apr 02, 2025 pm 07:24 PM
Um Bilder über XML zu generieren, müssen Sie Grafikbibliotheken (z. B. Kissen und Jfreechart) als Brücken verwenden, um Bilder basierend auf Metadaten (Größe, Farbe) in XML zu generieren. Der Schlüssel zur Steuerung der Bildgröße besteht darin, die Werte der & lt; width & gt; und & lt; Höhe & gt; Tags in XML. In praktischen Anwendungen haben jedoch die Komplexität der XML -Struktur, die Feinheit der Graphenzeichnung, die Geschwindigkeit der Bilderzeugung und des Speicherverbrauchs und die Auswahl der Bildformate einen Einfluss auf die generierte Bildgröße. Daher ist es notwendig, ein tiefes Verständnis der XML -Struktur zu haben, die in der Grafikbibliothek kompetent ist, und Faktoren wie Optimierungsalgorithmen und Bildformatauswahl zu berücksichtigen.
