

Dokument, Dokumentenklasse. Die Grundeinheit der Indexierung in Pylucene ist „Dokument“. Ein Dokument kann eine Webseite, ein Artikel oder eine E-Mail sein. Das Dokument ist die Einheit, die zum Erstellen des Index verwendet wird, und ist auch die Ergebniseinheit bei der Suche. Durch die richtige Gestaltung können personalisierte Suchdienste bereitgestellt werden.
Abgelegt, Domänenklasse. Ein Dokument kann mehrere Felder (Feld) enthalten. Abgelegt ist eine Komponente des Dokuments, genau wie ein Artikel aus mehreren Dateien bestehen kann, z. B. Artikeltitel, Artikeltext, Autor, Veröffentlichungsdatum usw.
Behandeln Sie eine Seite als Dokument, das drei Felder enthält: die URL-Adresse der Seite (URL), den Titel der Seite (Titel) und den Haupttextinhalt der Seite Seite (Inhalt). Wählen Sie als Speichermethode des Index die Verwendung der SimpleFSDirectory-Klasse und speichern Sie den Index in einer Datei. Der Analysator wählt CJKAnalyzer, der mit Pylucene geliefert wird. Dieser Analysator bietet gute Unterstützung für Chinesisch und ist für die Textverarbeitung chinesischer Inhalte geeignet.
Was ist eine Suchmaschine?
Suchmaschine ist „ein System, das Netzwerkinformationsressourcen sammelt und organisiert und Informationsabfragedienste bereitstellt, die drei Teile umfassen: Informationssammlung, Informationssortierung und Benutzerabfrage“. Abbildung 1 ist die allgemeine Struktur einer Suchmaschine. Das Informationssammelmodul sammelt Informationen aus dem Internet in der Netzwerkinformationsdatenbank (im Allgemeinen mithilfe von Crawlern). Anschließend führt das Informationssortiermodul Wortsegmentierung, Stoppwortentfernung, Gewichtung und andere Vorgänge durch Erstellen Sie eine Indextabelle (normalerweise einen invertierten Index), um schließlich eine Indexdatenbank zu bilden. Das Benutzerabfragemodul kann schließlich die Abrufanforderungen des Benutzers ermitteln und Abrufdienste bereitstellen.
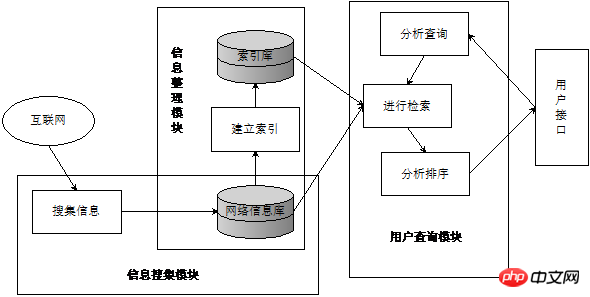
Abbildung 1 Allgemeine Struktur der Suchmaschine
2. Verwenden Sie Python, um eine einfache Suchmaschine zu implementieren
2.1 Problemanalyse
Aus Abbildung 1 geht hervor, dass eine vollständige Suchmaschinenarchitektur mit dem Sammeln von Informationen aus dem Internet beginnt. Sie können Python verwenden, um einen Crawler zu schreiben, was die Stärke von Python ist.
Als nächstes das Informationsverarbeitungsmodul. Partizip? Stoppwörter? Umgedrehter Tisch? Was? Was ist das für ein Durcheinander? Machen Sie sich darüber keine Sorgen, wir haben das Rad, das von unseren Vorgängern geschaffen wurde – Pylucene (eine Python-Paketversion von Lucene. Lucene kann Entwicklern dabei helfen, Suchfunktionen zu Software und Systemen hinzuzufügen. Lucene ist eine Reihe von Open-Source-Bibliotheken für vollständige Textabruf und -suche). Die Verwendung von Pylucene kann uns einfach dabei helfen, die gesammelten Informationen zu verarbeiten, einschließlich der Indexerstellung und Suche.
Um schließlich unsere Suchmaschine auf der Webseite nutzen zu können, verwenden wir Flask, ein leichtes Webanwendungs-Framework, um eine kleine Webseite zu erstellen, um Suchanweisungen und Feedback-Suchergebnisse zu erhalten.
2.2 Crawler-Design
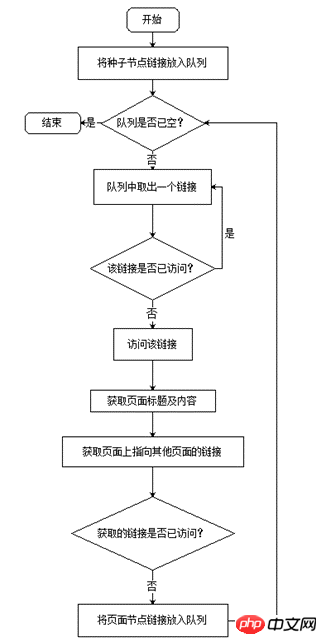
Sammelt hauptsächlich den folgenden Inhalt: den Titel der Zielwebseite, den Haupttextinhalt der Zielwebseite und die URL-Adressen anderer Seiten der Zielwebseite Seite verweist auf. Der Arbeitsablauf des Webcrawlers ist in Abbildung 2 dargestellt. Die Hauptdatenstruktur des Crawlers ist die Warteschlange. Zuerst tritt der anfängliche Startknoten in die Warteschlange ein, nimmt dann einen Knoten aus der Warteschlange, um darauf zuzugreifen, greift auf die Zielinformationen auf der Knotenseite zu, fügt dann den URL-Link der Knotenseite, der auf andere Seiten verweist, in die Warteschlange ein und nimmt ihn dann auf Auf den neuen Knoten aus der Warteschlange wird solange zugegriffen, bis die Warteschlange leer ist. Durch die „First In, First Out“-Funktion der Warteschlange wird ein Breiten-First-Traversal-Algorithmus implementiert, um nacheinander auf jede Seite der Website zuzugreifen.
dexWriter, Dokument, Abgelegt.
Directory ist eine Klasse in Pylucene für Dateioperationen. Es gibt 11 Unterklassen wie SimpleFSDirectory, CompoundFileDirectory und FileSwitchDirectory. Die vier aufgeführten Unterklassen speichern den erstellten Index im Dateisystem eine zusammengesetzte Indexspeichermethode; und FileSwitchDirectory ermöglicht das vorübergehende Umschalten der Indexspeichermethode, um die Vorteile verschiedener Indexspeichermethoden zu nutzen.
Analysator, Analysator. Es handelt sich um eine Klasse, die den vom Crawler erhaltenen Text verarbeitet, um ihn zu indizieren. Einschließlich Vorgänge wie Wortsegmentierung von Text, Entfernung von Stoppwörtern und Groß-/Kleinschreibungsumwandlung. Pylucene wird mit mehreren Analysegeräten geliefert, und Sie können beim Erstellen von Indizes auch Analysegeräte von Drittanbietern oder selbst geschriebene Analysegeräte verwenden. Die Qualität des Analysators hängt von der Qualität der Indexerstellung sowie der Genauigkeit und Geschwindigkeit ab, die der Suchdienst bieten kann.
IndexWriter, Index-Schreibkurs. In dem von Directory geöffneten Speicherplatz kann IndexWriter Vorgänge wie das Schreiben, Ändern, Hinzufügen und Löschen von Indizes ausführen, den Index jedoch nicht lesen oder durchsuchen.
Dokument, Dokumentenklasse. Die Grundeinheit der Indexierung in Pylucene ist „Dokument“. Ein Dokument kann eine Webseite, ein Artikel oder eine E-Mail sein. Das Dokument ist die Einheit, die zum Erstellen des Index verwendet wird, und ist auch die Ergebniseinheit bei der Suche. Durch die richtige Gestaltung können personalisierte Suchdienste bereitgestellt werden.
Abgelegt, Domänenklasse. Ein Dokument kann mehrere Felder (Feld) enthalten. Abgelegt ist eine Komponente des Dokuments, genau wie ein Artikel aus mehreren Dateien bestehen kann, z. B. Artikeltitel, Artikeltext, Autor, Veröffentlichungsdatum usw.
Behandeln Sie eine Seite als Dokument, das drei Felder enthält: die URL-Adresse der Seite (URL), den Titel der Seite (Titel) und den Haupttextinhalt der Seite (Inhalt). Wählen Sie als Speichermethode des Index die Verwendung der SimpleFSDirectory-Klasse aus, um den Index in einer Datei zu speichern. Der Analysator wählt CJKAnalyzer, der mit Pylucene geliefert wird. Dieser Analysator bietet gute Unterstützung für Chinesisch und ist für die Textverarbeitung chinesischer Inhalte geeignet.
Die spezifischen Schritte zum Erstellen eines Index mit Pylucene sind wie folgt:
lucene.initVM()
INDEXIDR = self.__index_dir
indexdir = SimpleFSDirectory(File(INDEXIDR))①
analyzer = CJKAnalyzer(Version.LUCENE_30)②
index_writer = IndexWriter(indexdir, analyzer, True, IndexWriter.MaxFieldLength(512))③
document = Document()④
document.add(Field("content", str(page_info["content"]), Field.Store.NOT, Field.Index.ANALYZED))⑤
document.add(Field("url", visiting, Field.Store.YES, Field.Index.NOT_ANALYZED))⑥
document.add(Field("title", str(page_info["title"]), Field.Store.YES, Field.Index.ANALYZED))⑦
index_writer.addDocument(document)⑧
index_writer.optimize()⑨
index_writer.close()⑩
Es gibt 10 Hauptschritte zum Erstellen eines Index:
① Instanziieren Sie ein SimpleFSDirectory-Objekt und speichern Sie den Index in einer lokalen Datei. Der gespeicherte Pfad ist der benutzerdefinierte Pfad „INDEXIDR“.
② Instanziieren Sie einen CJKAnalyzer-Analysator. Der Parameter Version.LUCENE_30 während der Instanziierung ist die Versionsnummer von Pylucene.
③ Instanziieren Sie ein IndexWriter-Objekt. Die vier mitgeführten Parameter sind das zuvor instanziierte SimpleFSDirectory-Objekt und der CJKAnalyzer-Analysator. Die boolesche Variable „true“ gibt die maximale Anzahl von Feldern (Filed) an ein Index.
④ Instanziieren Sie ein Document-Objekt und nennen Sie es „Dokument“.
⑤Fügen Sie dem Dokument eine Domäne mit dem Namen „content“ hinzu. Der Inhalt dieses Feldes ist der vom Crawler erhaltene Haupttextinhalt einer Webseite. Der Parameter dieser Operation ist das Field-Objekt, das sofort instanziiert und verwendet wird. Die vier Parameter des Field-Objekts sind:
(1) „content“, der Name der Domäne.
(2) page_info["content"], der vom Crawler gesammelte Haupttextinhalt der Webseite.
(3) Field.Store ist eine Variable, die angibt, ob der Wert dieses Felds auf die ursprünglichen Zeichen wiederhergestellt werden kann. Field.Store.YES gibt an, dass der in diesem Feld gespeicherte Inhalt wiederhergestellt werden kann Das Feld „Store.NOT“ bedeutet, dass es nicht wiederherstellbar ist.
(4) Die Variable Field.Index gibt an, ob der Inhalt des Feldes vom Analysator verarbeitet werden soll. NOT_ANALYZED gibt an, dass der Analysator nicht für das Feld verwendet wird. Der Parser verarbeitet Zeichen.
⑥Fügen Sie eine Domain mit dem Namen „url“ hinzu, um die Seitenadresse zu speichern.
⑦ Fügen Sie ein Feld mit dem Namen „Titel“ hinzu, um den Titel der Seite zu speichern.
⑧Instanziieren Sie das IndexWriter-Objekt, um das Dokumentdokument in die Indexdatei zu schreiben.
⑨ Optimieren Sie die Indexbibliotheksdateien und führen Sie kleine Dateien in der Indexbibliothek zu großen Dateien zusammen.
⑩Schließen Sie das IndexWriter-Objekt, nachdem der Indexerstellungsvorgang in einem einzigen Zyklus abgeschlossen ist.
Zu den Hauptklassen von Pylucene für die Indexsuche gehören IndexSearcher, Query und QueryParser[16].
IndexSearcher, Indexsuchklasse. Wird zum Durchführen von Suchvorgängen in der von IndexWriter erstellten Indexbibliothek verwendet.
Query, eine Klasse, die Abfrageanfragen beschreibt. Es sendet die Abfrageanforderung an IndexSearcher, um den Suchvorgang abzuschließen. Query verfügt über viele Unterklassen, um verschiedene Abfrageanforderungen zu erfüllen. TermQuery sucht beispielsweise nach Begriffen, dem grundlegendsten und einfachsten Abfragetyp und wird verwendet, um Dokumente mit bestimmten Elementen in einer bestimmten Domäne abzugleichen. RangeQuery sucht innerhalb eines bestimmten Bereichs und wird verwendet, um Dokumente innerhalb eines bestimmten Bereichs in einem abzugleichen angegebene Domäne; FuzzyQuery, eine Fuzzy-Abfrage, kann einfach Synonymübereinstimmungen identifizieren, die dem Abfrageschlüsselwort semantisch ähnlich sind.
QueryParser, Abfrageparser. Wenn Sie unterschiedliche Abfrageanforderungen implementieren müssen, müssen Sie unterschiedliche von Query bereitgestellte Unterklassen verwenden, was bei der Verwendung von Query leicht zu Verwirrung führen kann. Daher stellt Pylucene auch den Abfrageparser QueryParser bereit. QueryParser kann die übermittelte Abfrageanweisung analysieren und die entsprechende Abfrageunterklasse gemäß der Abfragesyntax auswählen, um die entsprechende Abfrage abzuschließen. Entwickler müssen sich nicht darum kümmern, welche Abfrageimplementierungsklasse unten verwendet wird. Beispielsweise analysiert QueryParser die Abfrageanweisung „Schlüsselwort 1 und Schlüsselwort 2“, um Dokumente abzufragen, die sowohl mit Schlüsselwort 1 als auch Schlüsselwort 2 übereinstimmen. Die Abfrageanweisung „id[123 bis 456]“ analysiert QueryParser, um die Domäne abzufragen, deren Name „id“ ist. Dokumente, deren Wert im angegebenen Bereich „123“ bis „456“ liegt; Abfrageanweisung „Schlüsselwort site:www.web.com“ QueryParser analysiert eine Abfrage, die auch den Wert von „www.web“ in der Domäne namens „site“ erfüllt „.com“ und Dokumente, die den beiden Abfragebedingungen von „keyword“ entsprechen.
Die Indexsuche ist einer der Bereiche, auf die sich Pylucene konzentriert. Zur Implementierung der Indexsuche wird eine Klasse mit dem Namen „Query“ geschrieben, die die folgenden Hauptschritte zur Implementierung der Indexsuche umfasst:
lucene.initVM()
if query_str.find(":") ==-1 and query_str.find(":") ==-1:
query_str="title:"+query_str+" OR content:"+query_str①
indir= SimpleFSDirectory(File(self.__indexDir))②
lucene_analyzer= CJKAnalyzer(Version.LUCENE_CURRENT)③
lucene_searcher= IndexSearcher(indir)④
my_query = QueryParser(Version.LUCENE_CURRENT,"title",lucene_analyzer).parse(query_str)⑤
total_hits = lucene_searcher.search(my_query, MAX)⑥
for hit in total_hits.scoreDocs:⑦
print"Hit Score: ", hit.score
doc = lucene_searcher.doc(hit.doc)
result_urls.append(doc.get("url").encode("utf-8"))
result_titles.append(doc.get("title").encode("utf-8"))
print doc.get("title").encode("utf-8")
result = {"Hits": total_hits.totalHits, "url":tuple(result_urls), "title":tuple(result_titles)}
return result
Es gibt 7 Hauptschritte bei der Indexsuche:
① Beurteilen Sie zunächst die Suchanweisung. Wenn es sich bei der Anweisung nicht um eine einzelne Domänenabfrage für den Titel oder Artikelinhalt handelt, enthält sie keine Schlüsselwörter. Wenn „title:“ oder „content:“ verwendet wird, werden standardmäßig die Titel- und Inhaltsfelder durchsucht.
②Instanziieren Sie ein SimpleFSDirectory-Objekt und geben Sie seinen Arbeitspfad als den Pfad an, in dem der Index zuvor erstellt wurde.
③实例化一个CJKAnalyzer分析器,搜索时使用的分析器应与索引构建时使用的分析器在类型版本上均一致。
④实例化一个IndexSearcher对象lucene_searcher,它的参数为第○2步的SimpleFSDirectory对象。
⑤实例化一个QueryParser对象my_query,它描述查询请求,解析Query查询语句。参数Version.LUCENE_CURRENT为pylucene的版本号,“title”指默认的搜索域,lucene_analyzer指定了使用的分析器,query_str是Query查询语句。在实例化QueryParser前会对用户搜索请求作简单处理,若用户指定了搜索某个域就搜索该域,若用户未指定则同时搜索“title”和“content”两个域。
⑥lucene_searcher进行搜索操作,返回结果集total_hits。total_hits中包含结果总数totalHits,搜索结果的文档集scoreDocs,scoreDocs中包括搜索出的文档以及每篇文档与搜索语句相关度的得分。
⑦lucene_searcher搜索出的结果集不能直接被Python处理,因而在搜索操作返回结果之前应将结果由Pylucene转为普通的Python数据结构。使用For循环依次处理每个结果,将结果文档按相关度得分高低依次将它们的地址域“url”的值放入Python列表result_urls,将标题域“title”的值放入列表result_titles。最后将包含地址、标题的列表和结果总数组合成一个Python“字典”,将最后处理的结果作为整个搜索操作的返回值。
用户在浏览器搜索框输入搜索词并点击搜索,浏览器发起一个GET请求,Flask的路由route设置了由result函数响应该请求。result函数先实例化一个搜索类query的对象infoso,将搜索词传递给该对象,infoso完成搜索将结果返回给函数result。函数result将搜索出来的页面和结果总数等传递给模板result.html,模板result.html用于呈现结果
如下是Python使用flask模块处理搜索请求的代码:
app = Flask(__name__)#创建Flask实例
@app.route('/')#设置搜索默认主页
def index():
html="<h1>title这是标题</h1>"
return render_template('index.html')
@app.route("/result",methods=['GET', 'POST'])#注册路由,并指定HTTP方法为GET、POST
def result(): #resul函数
if request.method=="GET":#响应GET请求
key_word=request.args.get('word')#获取搜索语句
if len(key_word)!=0:
infoso = query("./glxy") #创建查询类query的实例
re = infoso.search(key_word)#进行搜索,返回结果集
so_result=[]
n=0
for item in re["url"]:
temp_result={"url":item,"title":re["title"][n]}#将结果集传递给模板
so_result.append(temp_result)
n=n+1
return render_template('result.html', key_word=key_word, result_sum=re["Hits"],result=so_result)
else:
key_word=""
return render_template('result.html')
if __name__ == '__main__':
app.debug = True
app.run()#运行web服务Das obige ist der detaillierte Inhalt vonBeispiel-Tutorial zur Python-Implementierung einer Suchmaschine (Pylucene).. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
















![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



