

Langsame Abfragevorgänge in MySQL

Datenbankoperationen sind heute zunehmend zum Leistungsengpass der gesamten Anwendung geworden, insbesondere bei Webanwendungen. In Bezug auf die Leistung der Datenbank müssen sich nicht nur Datenbankadministratoren darum kümmern, sondern auch unsere Programmierer müssen darauf achten.
Heutzutage sind Datenbankoperationen zunehmend zum Leistungsengpass der Datenbank geworden Dies gilt insbesondere für Webanwendungen. Was die Leistung der Datenbank betrifft, ist dies nicht nur etwas, worüber sich Datenbankadministratoren Sorgen machen müssen, sondern auch etwas, worauf wir Programmierer achten müssen. Wenn wir die Tabellenstruktur der Datenbank entwerfen, müssen wir alle auf die Leistung der Datenoperationen beim Betrieb der Datenbank achten (insbesondere der SQL-Anweisungen beim Nachschlagen von Tabellen). Hier werden wir nicht zu viel über die Optimierung von SQL-Anweisungen sprechen, sondern uns nur auf MySQL konzentrieren, die Datenbank mit den meisten Webanwendungen.
Die Leistungsoptimierung von MySQL kann nicht über Nacht erreicht werden. Sie müssen Schritt für Schritt vorgehen und in allen Aspekten optimieren, und die endgültige Leistung wird erheblich verbessert.
MySQL-Datenbank Optimierungstechnologie
MySQL-Optimierung ist eine umfassende Technologie, die hauptsächlich
•Rationalisierung des Tabellendesigns (im Einklang mit 3NF)
•Geeigneten Index (Index) hinzufügen [vier Typen: gewöhnlicher Index, Primärschlüsselindex, eindeutiger Index, vollständig Textindex]
•Tabellenaufteilungstechnologie (horizontale Aufteilung, vertikale Aufteilung)
•Lesen und Schreiben [Schreiben: Aktualisieren/Löschen/Hinzufügen] Trennung
•Speicherprozedur [Modulare Programmierung, kann die Geschwindigkeit verbessern]
• MySQL-Konfiguration optimieren [Konfigurieren Sie die maximale Anzahl von Parallelitätsmy.ini, passen Sie die Cache-Größe an ]
•MySQL-Server-Hardware-Upgrade
•Regelmäßig unnötige Daten löschen und regelmäßig defragmentieren (MyISAM)
Arbeiten zur Datenbankoptimierung
Bei einer datenzentrierten Anwendung wirkt sich die Qualität der Datenbank direkt auf die Leistung des Programms aus, daher ist die Datenbankleistung von entscheidender Bedeutung. Um die Effizienz der Datenbank sicherzustellen, müssen im Allgemeinen die folgenden vier Aspekte durchgeführt werden:
① Datenbankdesign
② SQL-Anweisungsoptimierung
③ Datenbankparameterkonfiguration
④ Geeignete Hardwareressourcen und Betriebssystem
Darüber hinaus kann die Verwendung geeigneter gespeicherter Prozeduren auch die Leistung verbessern.
Diese Reihenfolge zeigt auch die Auswirkungen dieser vier Aufgaben auf die Leistung
Datenbanktabellendesign
Ein gemeinsames Verständnis der drei Paradigmen ist für das Datenbankdesign von großem Nutzen. Um die drei Paradigmen beim Datenbankdesign besser anwenden zu können, ist es notwendig, die drei Paradigmen auf populäre Weise zu verstehen (das populäre Verständnis ist ein ausreichendes Verständnis, nicht das wissenschaftlichste und genaueste Verständnis):
Erste Normalform: 1NF ist eine atomare Einschränkung für Attribute, die erfordert, dass Attribute (Spalten) atomar sind und nicht zerlegt werden können (solange es sich um eine
handelt, erfüllt sie 1NF)
Zweite Normalform: 2NF ist die Eindeutigkeitsbeschränkung für Datensätze, die erfordert, dass Datensätze eindeutige Bezeichner haben, d. h. die Einzigartigkeit von Entitäten
Dritte Normalform: 3NF ist die Einschränkung der Eindeutigkeit von Datensätzen, die erfordern, dass Felder nicht redundant sind. Das kann kein redundantes Datenbankdesign leisten.
Eine Datenbank ohne Redundanz ist jedoch möglicherweise nicht die beste Datenbank. Um die Betriebseffizienz zu verbessern, ist es manchmal erforderlich, den Paradigmenstandard zu senken und redundante Daten angemessen aufzubewahren. Der spezifische Ansatz besteht darin, sich beim Entwurf des konzeptionellen Datenmodells an das dritte Paradigma zu halten und beim Entwurf des physischen Datenmodells die Arbeit zur Senkung des Paradigmenstandards zu berücksichtigen. Das Absenken der Normalform bedeutet das Hinzufügen von Feldern und das Zulassen von Redundanz.
Relationale Datenbank: mysql/oracle/db2/informix/sysbase/sql server
Nicht-relationale Datenbank: (Funktionen:
oder Sammlung)
NoSql-Datenbank: MongoDB (charakteristisch dokumentorientiert)
Geben Sie ein Beispiel dafür, was mäßige Redundanz oder begründete Redundanz ist!
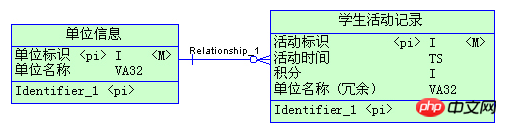
Das oben Genannte ist aus folgenden Gründen eine unangemessene Redundanz:
Um die Abrufeffizienz der Aktivitätsdatensätze der Schüler zu verbessern, wird hier der Name der Einheit redundant zur Tabelle der Aktivitätsdatensätze der Schüler hinzugefügt. Es gibt 500 Datensätze mit Einheiteninformationen, und die Aktivitätsdatensätze der Studierenden
umfassen etwa 2 Millionen Datenmengen pro Jahr. Wenn die Tabelle der Schüleraktivitätsdatensätze das Feld „Einheitsname“ nicht überflüssig macht, enthält sie nur drei Int-Felder und ein Zeitstempelfeld, belegt nur 16 Byte und ist eine sehr kleine Tabelle. Bei einem redundanten varchar(32)-Feld ist die Größe dreimal so groß wie die ursprüngliche Größe und der Abruf erfordert so viel mehr E/A. Darüber hinaus ist die Anzahl der Datensätze sehr unterschiedlich, 500 vs. 2.000.000, was dazu führt, dass bei der Aktualisierung eines Einheitennamens 4.000 redundante Datensätze aktualisiert werden müssen. Man erkennt, dass diese Redundanz schlichtweg kontraproduktiv ist.
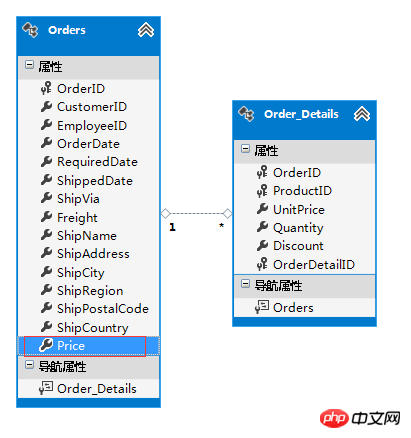
Der Preis in der Bestelltabelle ist ein redundantes Feld, da wir den Preis dieser Bestellung aus der Bestelldetailtabelle berechnen können. Diese Redundanz ist jedoch angemessen und kann auch die Abfrageleistung verbessern.
Aus den oben genannten beiden Beispielen lässt sich eine Schlussfolgerung ziehen:
1---n-Redundanz sollte auf der 1-Seite auftreten.
SQL-Anweisungsoptimierung
Allgemeine Schritte zur SQL-Optimierung
1. Bestehen Sie die Show Der Statusbefehl versteht die Ausführungshäufigkeit verschiedener SQLs.
2. Suchen Sie SQL-Anweisungen mit geringer Ausführungseffizienz – (Schwerpunkt auf Select)
3. Analysieren Sie ineffizientes SQL durch EXPLAIN
4 . Ermitteln Sie das Problem und ergreifen Sie entsprechende Optimierungsmaßnahmen Verbindung können Serverstatusinformationen mithilfe des Befehls show [session|global] status bereitgestellt werden. Die Sitzung stellt die statistischen Ergebnisse der aktuellen Verbindung dar, und global stellt die statistischen Ergebnisse seit dem letzten Start der Datenbank dar. Der Standardwert ist Sitzungsebene.
-- select语句分类 Select Dml数据操作语言(insert update delete) dtl 数据事物语言(commit rollback savepoint) Ddl数据定义语言(create alter drop..) Dcl(数据控制语言) grant revoke -- Show status 常用命令 --查询本次会话 Show session status like 'com_%'; //show session status like 'Com_select' --查询全局 Show global status like 'com_%'; -- 给某个用户授权 grant all privileges on *.* to 'abc'@'%'; --为什么这样授权 'abc'表示用户名 '@' 表示host, 查看一下mysql->user表就知道了 --回收权限 revoke all on *.* from 'abc'@'%'; --刷新权限[也可以不写] flush privileges;
Das folgende Beispiel: Status wie „Com_%“ anzeigen;
show status like 'Connections' show status like 'Uptime' show status like 'Slow_queries'
Show variables like 'long_query_time';
Die Frage ist: Wie kann man langsam ausgeführte Anweisungen in einem großen Projekt schnell finden? (Langsame Abfragen finden)
set long_query_time=2
Zunächst verstehen wir, wie man einen bestimmten Betriebsstatus einer MySQL-Datenbank abfragt (z. B. wenn Sie wissen möchten, wie lange MySQL aktuell läuft bzw. wie oft es ausgeführt wurde). wurde insgesamt ausgeführtAuswählen/Aktualisieren/Löschen.. / aktuelle Verbindung)
Um das Testen zu erleichtern, erstellen wir eine große Tabelle (4 Millionen) -> Verwendung einer gespeicherten Prozedur
Ändern Sie die langsame Abfrage von MySQL.
Erstellen Sie eine große Tabelle->Es gibt Anforderungen für Datensätze in großen Tabellen, und die Datensätze sind unterschiedlich. Dies ist nützlich, da sich der Testeffekt sonst stark vom tatsächlichen unterscheidet. Erstellen:
Damit die gespeicherte Prozedur normal ausgeführt werden kann, müssen wir das Trennzeichen $$ für das Ende der Befehlsausführung ändern
Eine Funktion erstellen, die zurückgibt eine zufällige Zeichenfolge der angegebenen Längeshow variables like 'long_query_time' ; //可以显示当前慢查询时间 set long_query_time=1 ;//可以修改慢查询时间
CREATE TABLE dept( /*部门表*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ dname VARCHAR(20) NOT NULL DEFAULT "", /*名称*/ loc VARCHAR(13) NOT NULL DEFAULT "" /*地点*/ ) ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE emp (empno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, /*编号*/ ename VARCHAR(20) NOT NULL DEFAULT "", /*名字*/ job VARCHAR(9) NOT NULL DEFAULT "",/*工作*/ mgr MEDIUMINT UNSIGNED NOT NULL DEFAULT 0,/*上级编号*/ hiredate DATE NOT NULL,/*入职时间*/ sal DECIMAL(7,2) NOT NULL,/*薪水*/ comm DECIMAL(7,2) NOT NULL,/*红利*/ deptno MEDIUMINT UNSIGNED NOT NULL DEFAULT 0 /*部门编号*/ )ENGINE=MyISAM DEFAULT CHARSET=utf8 ; CREATE TABLE salgrade ( grade MEDIUMINT UNSIGNED NOT NULL DEFAULT 0, losal DECIMAL(17,2) NOT NULL, hisal DECIMAL(17,2) NOT NULL )ENGINE=MyISAM DEFAULT CHARSET=utf8;
Zu diesem Zeitpunkt wird die Ausführung einer Anweisung gezählt
INSERT INTO salgrade VALUES (1,700,1200); INSERT INTO salgrade VALUES (2,1201,1400); INSERT INTO salgrade VALUES (3,1401,2000); INSERT INTO salgrade VALUES (4,2001,3000); INSERT INTO salgrade VALUES (5,3001,9999);
create function rand_string(n INT) returns varchar(255) #该函数会返回一个字符串 begin #chars_str定义一个变量 chars_str,类型是 varchar(100),默认值'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare chars_str varchar(100) default 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ'; declare return_str varchar(255) default ''; declare i int default 0; while i < n do set return_str =concat(return_str,substring(chars_str,floor(1+rand()*52),1)); set i = i + 1; end while; return return_str; end
create procedure insert_emp(in start int(10),in max_num int(10)) begin declare i int default 0; #set autocommit =0 把autocommit设置成0 set autocommit = 0; repeat set i = i + 1; insert into emp values ((start+i) ,rand_string(6),'SALESMAN',0001,curdate(),2000,400,rand()); until i = max_num end repeat; commit; end #调用刚刚写好的函数, 1800000条记录,从100001号开始 call insert_emp(100001,4000000);
binmysqld.exe –log-slow-queries=d:/abc.log [niedrigere Version von mysql5.0 kann in my.ini angegeben werden]
Das langsame Abfrageprotokoll wird im Datenverzeichnis [in mysql5 abgelegt .0-Version wird im MySQL-Installationsverzeichnis/data/ abgelegt. Unter mysql5.5.19 müssen Sie es anzeigen
My.ini's datadir="C:/Documents and Settings/ Alle Benutzer/Anwendungsdaten/MySQL/MySQL Server 5.5/Data/“ zur Bestimmung.
In mysql5.6 wird standardmäßig die langsame Abfrageprotokollierung gestartet. Das Verzeichnis, in dem sich my.ini befindet, ist : C:ProgramDataMySQLMySQL Server 5.6, das über ein Konfigurationselement
slow-query-log=1
Es gibt zwei Möglichkeiten, eine langsame Abfrage für mysql5.5 zu starten
binmysqld.exe - -safe-mode - -slow-query-log
kann auch in meiner Konfiguration in der .ini-Datei verwendet werden:
Finden Sie SQL-Anweisungen mit geringer Ausführungseffizienz anhand langsamer Abfrageprotokolle. Das langsame Abfrageprotokoll zeichnet alle SQL-Anweisungen auf, deren Ausführungszeit die Einstellung von long_query_time überschreitet.
Daten zur Dept-Tabelle hinzufügen
****Testanweisung***[Der Datensatz der Emp-Tabelle kann 3600000 sein, der Effekt ist offensichtlich langsam]
[mysqld] # The TCP/IP Port the MySQL Server will listen on port=3306 slow-query-log
show variables like 'long_query_time'; set long_query_time=2;
desc dept; ALTER table dept add id int PRIMARY key auto_increment; CREATE PRIMARY KEY on dept(id); create INDEX idx_dptno_dptname on dept(deptno,dname); INSERT into dept(deptno,dname,loc) values(1,'研发部','康和盛大厦5楼501'); INSERT into dept(deptno,dname,loc) values(2,'产品部','康和盛大厦5楼502'); INSERT into dept(deptno,dname,loc) values(3,'财务部','康和盛大厦5楼503');UPDATE emp set deptno=1 where empno=100002;
select * from emp where empno=(select empno from emp where ename='研发部')
SQL-Anweisungsoptimierung – Analyseprobleme erklären
select * from emp e,dept d where e.empno=100002 and e.deptno=d.deptno;
Tabelle: Die Tabelle, die die Ergebnismenge ausgibt
Typ: Stellt den Verbindungstyp der Tabelle darExplain select * from emp where ename=“wsrcla”
possible_keys:表示查询时,可能使用的索引
key:表示实际使用的索引
key_len:索引字段的长度
rows:扫描出的行数(估算的行数)
Extra:执行情况的描述和说明

explain select * from emp where ename='JKLOIP'
如果要测试Extra的filesort可以对上面的语句修改
explain select * from emp order by ename\G
EXPLAIN详解
id
SELECT识别符。这是SELECT的查询序列号
id 示例
SELECT * FROM emp WHERE empno = 1 and ename = (SELECT ename FROM emp WHERE empno = 100001) \G;
select_type
PRIMARY :子查询中最外层查询
SUBQUERY : 子查询内层第一个SELECT,结果不依赖于外部查询
DEPENDENT SUBQUERY:子查询内层第一个SELECT,依赖于外部查询
UNION :UNION语句中第二个SELECT开始后面所有SELECT,
SIMPLE
UNION RESULT UNION 中合并结果
Table
显示这一步所访问数据库中表名称
Type
对表访问方式
ALL:
SELECT * FROM emp \G
完整的表扫描 通常不好
SELECT * FROM (SELECT * FROM emp WHERE empno = 1) a ;
system:表仅有一行(=系统表)。这是const联接类型的一个特
const:表最多有一个匹配行
Possible_keys
该查询可以利用的索引,如果没有任何索引显示 null
Key
Mysql 从 Possible_keys 所选择使用索引
Rows
估算出结果集行数
Extra
查询细节信息
No tables :Query语句中使用FROM DUAL 或不含任何FROM子句
Using filesort :当Query中包含 ORDER BY 操作,而且无法利用索引完成排序,
Impossible WHERE noticed after reading const tables: MYSQL Query Optimizer
通过收集统计信息不可能存在结果
Using temporary:某些操作必须使用临时表,常见 GROUP BY ; ORDER BY
Using where:不用读取表中所有信息,仅通过索引就可以获取所需数据;
Das obige ist der detaillierte Inhalt vonLangsame Abfragevorgänge in MySQL. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

Video Face Swap
Tauschen Sie Gesichter in jedem Video mühelos mit unserem völlig kostenlosen KI-Gesichtstausch-Tool aus!

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1393
1393
 52
1205
24
52
1205
24

 Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Wie man phpmyadmin öffnet
Apr 10, 2025 pm 10:51 PM
Sie können PhpMyAdmin in den folgenden Schritten öffnen: 1. Melden Sie sich beim Website -Bedienfeld an; 2. Finden und klicken Sie auf das Symbol phpmyadmin. 3. Geben Sie MySQL -Anmeldeinformationen ein; 4. Klicken Sie auf "Login".
 MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL: Eine Einführung in die beliebteste Datenbank der Welt
Apr 12, 2025 am 12:18 AM
MySQL ist ein Open Source Relational Database Management -System, das hauptsächlich zum schnellen und zuverlässigen Speicher und Abrufen von Daten verwendet wird. Sein Arbeitsprinzip umfasst Kundenanfragen, Abfragebedingungen, Ausführung von Abfragen und Rückgabergebnissen. Beispiele für die Nutzung sind das Erstellen von Tabellen, das Einsetzen und Abfragen von Daten sowie erweiterte Funktionen wie Join -Operationen. Häufige Fehler umfassen SQL -Syntax, Datentypen und Berechtigungen sowie Optimierungsvorschläge umfassen die Verwendung von Indizes, optimierte Abfragen und die Partitionierung von Tabellen.
 So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
So verwenden Sie ein einzelnes Gewinde -Redis
Apr 10, 2025 pm 07:12 PM
Redis verwendet eine einzelne Gewindearchitektur, um hohe Leistung, Einfachheit und Konsistenz zu bieten. Es wird E/A-Multiplexing, Ereignisschleifen, nicht blockierende E/A und gemeinsame Speicher verwendet, um die Parallelität zu verbessern, jedoch mit Einschränkungen von Gleichzeitbeschränkungen, einem einzelnen Ausfallpunkt und ungeeigneter Schreib-intensiver Workloads.
 Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Mysqls Platz: Datenbanken und Programmierung
Apr 13, 2025 am 12:18 AM
Die Position von MySQL in Datenbanken und Programmierung ist sehr wichtig. Es handelt sich um ein Open -Source -Verwaltungssystem für relationale Datenbankverwaltung, das in verschiedenen Anwendungsszenarien häufig verwendet wird. 1) MySQL bietet effiziente Datenspeicher-, Organisations- und Abruffunktionen und unterstützt Systeme für Web-, Mobil- und Unternehmensebene. 2) Es verwendet eine Client-Server-Architektur, unterstützt mehrere Speichermotoren und Indexoptimierung. 3) Zu den grundlegenden Verwendungen gehören das Erstellen von Tabellen und das Einfügen von Daten, und erweiterte Verwendungen beinhalten Multi-Table-Verknüpfungen und komplexe Abfragen. 4) Häufig gestellte Fragen wie SQL -Syntaxfehler und Leistungsprobleme können durch den Befehl erklären und langsam abfragen. 5) Die Leistungsoptimierungsmethoden umfassen die rationale Verwendung von Indizes, eine optimierte Abfrage und die Verwendung von Caches. Zu den Best Practices gehört die Verwendung von Transaktionen und vorbereiteten Staten
 Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
Warum MySQL verwenden? Vorteile und Vorteile
Apr 12, 2025 am 12:17 AM
MySQL wird für seine Leistung, Zuverlässigkeit, Benutzerfreundlichkeit und Unterstützung der Gemeinschaft ausgewählt. 1.MYSQL bietet effiziente Datenspeicher- und Abruffunktionen, die mehrere Datentypen und erweiterte Abfragevorgänge unterstützen. 2. Übernehmen Sie die Architektur der Client-Server und mehrere Speichermotoren, um die Transaktion und die Abfrageoptimierung zu unterstützen. 3. Einfach zu bedienend unterstützt eine Vielzahl von Betriebssystemen und Programmiersprachen. V.
 So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
So stellen Sie eine Verbindung zur Datenbank von Apache her
Apr 13, 2025 pm 01:03 PM
Apache verbindet eine Verbindung zu einer Datenbank erfordert die folgenden Schritte: Installieren Sie den Datenbanktreiber. Konfigurieren Sie die Datei web.xml, um einen Verbindungspool zu erstellen. Erstellen Sie eine JDBC -Datenquelle und geben Sie die Verbindungseinstellungen an. Verwenden Sie die JDBC -API, um über den Java -Code auf die Datenbank zuzugreifen, einschließlich Verbindungen, Erstellen von Anweisungen, Bindungsparametern, Ausführung von Abfragen oder Aktualisierungen und Verarbeitungsergebnissen.
 So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
So starten Sie MySQL von Docker
Apr 15, 2025 pm 12:09 PM
Der Prozess des Startens von MySQL in Docker besteht aus den folgenden Schritten: Ziehen Sie das MySQL -Image zum Erstellen und Starten des Containers an, setzen
 CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
CentOS installieren MySQL
Apr 14, 2025 pm 08:09 PM
Die Installation von MySQL auf CentOS umfasst die folgenden Schritte: Hinzufügen der entsprechenden MySQL Yum -Quelle. Führen Sie den Befehl mySQL-server aus, um den MySQL-Server zu installieren. Verwenden Sie den Befehl mySQL_SECURE_INSTALLATION, um Sicherheitseinstellungen vorzunehmen, z. B. das Festlegen des Stammbenutzerkennworts. Passen Sie die MySQL -Konfigurationsdatei nach Bedarf an. Tune MySQL -Parameter und optimieren Sie Datenbanken für die Leistung.
