
Das Architekturbüro in der E-Commerce-Plattform aus verschiedenen Blickwinkeln zusammengefasst, habe ich einen ersten Entwurf fertiggestellt, der wird ergänzt und verbessert. Herzlich willkommen, mitzumachen.
Bitte geben Sie die Quelle für den Nachdruck an:
Autor: Yang Butao
Schwerpunkt auf verteilter Architektur, Big Data, Suche, Open-Source-Technologie
QQ: 306591368
TechnologieBlog:
Client-Seiten-Cache (http-Header enthält Expires/Cache of Control, letzte Änderung(304, Der Server gibt den Body nicht zurück, der Client kann weiterhin den Cache verwenden, um den Datenverkehr zu reduzieren ), ETag)
Reverse-Proxy-Cache
App-seitiger Cache(Memcache)
Speicherdatenbank
Puffer, Cache-Mechanismus (Datenbank, Middleware usw.)
Hash, B-Baum, Inversion, Bitmap
Der Hash-Index eignet sich für umfassende Array-Adressierung und Funktionen zum Einfügen verknüpfter Listen und kann einen schnellen Zugriff auf Daten ermöglichen.
Der B-Tree-Index eignet sich für abfrageorientierte Szenarien, vermeidet mehrere IOs und verbessert die Abfrageeffizienz.
Invertierter Index ist die beste Möglichkeit, die Wort-zu-Dokument-Zuordnungsbeziehung und die effektivste Indexstruktur zu implementieren, und wird häufig im Suchfeld verwendet.
Bitmap ist eine sehr einfache und schnelle Datenstruktur, die gleichzeitig Speicherplatz und Geschwindigkeit optimieren kann (ohne Platz gegen Zeit eintauschen zu müssen) und eignet sich für Rechenszenarien mit riesige Datenmengen.
In großen Datenmengen weisen die Daten bestimmte lokale Merkmale auf, wobei das Prinzip verwendet wird Die Lokalität spaltet und überwindet das Problem der Massendatenberechnung.
Das MR-Modell ist eine Shared-Nothing-Architektur und der Datensatz wird auf verschiedene Knoten verteilt. Während der Verarbeitung liest jeder Knoten die lokal gespeicherten Daten zur Verarbeitung(Karte), führt die verarbeiteten Daten zusammen(kombinieren), sortiert(mischen und sortieren) und verteilt sie dann (an Knoten reduzieren), wodurch die Übertragung großer Datenmengen vermieden und die Verarbeitungseffizienz verbessert wird.
Parallel Computing (Parallel Computing) bezieht sich auf den Prozess der Verwendung mehrerer Computerressourcen zur Lösung Rechenprobleme gleichzeitig zu lösen, ist ein wirksames Mittel, um die Rechengeschwindigkeit und Verarbeitungsleistung von Computersystemen zu verbessern. Seine Grundidee besteht darin, mehrere Prozessoren /Prozesse /Threads zu verwenden, um dasselbe Problem gemeinsam zu lösen, dh das zu lösende Problem in mehrere Teile zu zerlegen und jeden Teil von einem unabhängigen Prozessor parallel zu berechnen.
Der Unterschied zwischenund MR besteht darin, dass es auf der Problemzerlegung und nicht auf der Datenzerlegung basiert.
Da die Parallelität der Plattform zunimmt, ist es notwendig, die Knotenkapazität für das Clustering zu erweitern und Lastausgleichsgeräte zu verwenden, um Anforderungen zu verteilen Bietet gleichzeitig auch eine Fehlererkennungsfunktion. Um die Verfügbarkeit zu verbessern, ist ein Disaster-Recovery-Backup erforderlich, um durch Knotenfehler verursachte Nichtverfügbarkeitsprobleme zu verhindern an unterschiedliche Ausfallanforderungen.
Die Lese- und Schreibtrennung erfolgt für die Datenbank mit Parallelität Die Erhöhung des Datenzugriffs ist ein wichtiges Mittel zur Verbesserung des Datenzugriffs. Natürlich müssen wir beim Trennen von Lese- und Schreibdaten auf die Konsistenz der Daten achten. in verteilten Systemen Bei der CAP-Quantifizierung wird mehr Wert auf die Benutzerfreundlichkeit gelegt.
Die Beziehung zwischen den verschiedenen Modulen in der Plattform sollte möglichst niedrig sein. Möglichst gekoppelt, können Sie über relevante Nachrichtenkomponenten interagieren, möglichst asynchron, und den Hauptprozess und den Sekundärprozess des Datenflusses klar unterscheiden. Die Protokollierung kann beispielsweise asynchron erfolgen, was die Verfügbarkeit erhöht des Gesamtsystems.
Natürlich ist bei der asynchronen Verarbeitung häufig ein Bestätigungsmechanismus (bestätigen, ack) erforderlich, um sicherzustellen, dass Daten empfangen oder verarbeitet werden.
In einigen Szenarien wird die Bestätigungsnachricht jedoch aus anderen Gründen nicht zurückgegeben, obwohl die Anfrage verarbeitet wurde (z. B. instabiles Netzwerk ), dann muss in diesem Fall die Anfrage erneut übertragen werden, und das Design der Anforderungsverarbeitung muss die Idempotenz aufgrund von Neuübertragungsfaktoren berücksichtigen.
Überwachung ist auch ein wichtiges Mittel zur Verbesserung der Verfügbarkeit von Die gesamte Plattform überwacht mehrere Dimensionen. Das Modul ist während der Laufzeit transparent, um während der Laufzeit Whiteboxing zu erreichen.
Aufteilung umfasst die Aufteilung des Geschäfts und der Datenbank.
Systemressourcen sind immer begrenzt. Wenn ein relativ langes Geschäft auf einmal ausgeführt wird, kann diese Blockierungsmethode bei einer großen Anzahl gleichzeitiger Vorgänge nicht wirksam sein auszuführenden Prozesse, sodass der Systemdurchsatz nicht hoch ist.
Es ist notwendig, das Geschäft logisch zu segmentieren und eine asynchrone, nicht blockierende Methode zu verwenden, um den Durchsatz des Systems zu verbessern.
Mit zunehmender Datenmenge und zunehmender Parallelität kann die Trennung von Lesen und Schreiben die Anforderungen an die Parallelitätsleistung des Systems nicht erfüllen. Daten müssen segmentiert werden, einschließlich der Aufteilung der Daten in Datenbanken und Tabellen . Diese Methode zum Aufteilen von Datenbanken und Tabellen erfordert das Hinzufügen von Routing-Logikunterstützung für Daten.
Für die Skalierbarkeit des Systems ist es am besten, wenn das Modul zustandslos ist. Durch das Hinzufügen von Knoten kann der Gesamtdurchsatz verbessert werden.
Die Kapazität des Systems ist begrenzt, und auch die Menge an Parallelität, die es aushalten kann, ist begrenzt. Beim Entwurf der Architektur muss die Verkehrskontrolle berücksichtigt werden, um zu verhindern, dass das System aufgrund unerwarteter Angriffe oder der Auswirkungen sofortiger Parallelität abstürzt. Wenn Sie das Hinzufügen von Flusskontrollmaßnahmen planen, können Sie erwägen, Anfragen in die Warteschlange zu stellen. Wenn die Anfrage den erwarteten Bereich überschreitet, können Sie einen Alarm ausgeben oder sie verwerfen.
Für den Zugriff auf gemeinsam genutzte Ressourcen, um Konflikte und Parallelität zu verhindern ist erforderlich Gleichzeitig müssen einige Transaktionen transaktional sein, um die Transaktionskonsistenz sicherzustellen. Daher müssen beim Entwurf des Transaktionssystems atomare Operationen und Parallelitätskontrolle berücksichtigt werden.
Einige häufig verwendete Hochleistungsmethoden zur Gewährleistung der Parallelitätskontrolle umfassen optimistisches Sperren, Latch, Mutex, Copy-on-Write, CAS usw. ; Mehrversions-Parallelitätskontrolle MVCC ist normalerweise ein wichtiges Mittel zur Gewährleistung der Konsistenz, das häufig beim Datenbankdesign verwendet wird.
Es gibt verschiedene Arten von Geschäftslogiken in der Plattform, darunter solche mit komplexen Berechnungen und solche, die IO verbrauchen. Gleichzeitig verbrauchen unterschiedliche Geschäftslogiken unterschiedliche Mengen an Ressourcen für verschiedene Logiken übernommen werden.
Für den IO-Typ kann eine ereignisgesteuerte asynchrone, nicht blockierende Methode übernommen werden. Die Single-Threaded-Methode kann den durch Threadwechsel verursachten Overhead reduzieren Bei mehreren Threads wird Spin Spin verwendet, um den Thread-Wechsel zu reduzieren (z. B. Oracle-Latch-Design ); nutzen Sie für Berechnungen vollständig Multi-Threads für Operationen.
Bei derselben Art von Aufrufmethode führen verschiedene Unternehmen eine entsprechende Ressourcenzuweisung durch und legen unterschiedliche Anzahlen von Rechenknoten oder Threads fest Menge, das Geschäft wird umgeleitet und Geschäfte mit hoher Priorität werden zuerst ausgeführt.
Wenn in einigen Geschäftsmodulen des Systems ein Fehler auftritt, der Reihe nach Um die Parallelität zu verringern, ist es im normalen System manchmal erforderlich, die Verarbeitung dieser abnormalen Anforderungen über separate Kanäle in Betracht zu ziehen oder diese abnormalen Geschäftsmodule vorübergehend automatisch zu verbieten.
Das Scheitern einiger Anfragen kann ein zufälliger vorübergehender Fehler sein (z. B. Netzwerkinstabilität ), und ein erneuter Versuch der Anfrage muss in Betracht gezogen werden.
Die Ressourcen des Systems sind begrenzt Ressourcen Bei der Anforderung müssen Ressourcen am Ende freigegeben werden, unabhängig davon, ob die Anforderung einen normalen oder einen abnormalen Pfad einnimmt, damit Ressourcen rechtzeitig für andere Anforderungen wiederhergestellt werden können.
Beim Entwurf der Kommunikationsarchitektur ist es oft notwendig, die Timeout-Kontrolle zu berücksichtigen.
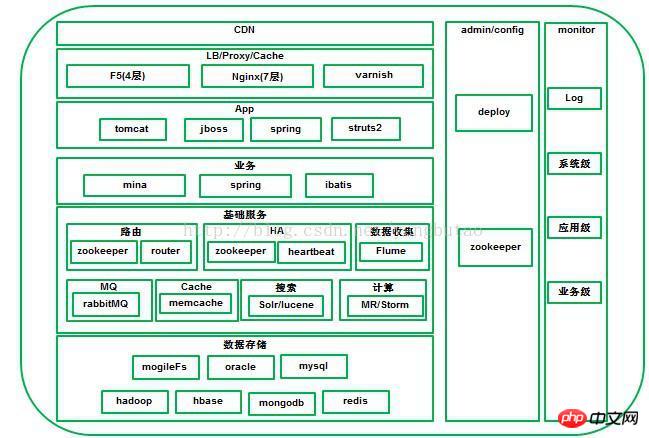
Die gesamte Architektur ist eine geschichtete und verteilte Architektur, auch vertikalCDN, Lastausgleich/Reverse-Proxy, Webanwendung, Business-Schicht, Basisdienstschicht, Datenspeicherschicht. Die horizontale Richtung umfasst Konfigurationsmanagement, Bereitstellung und Überwachung der gesamten Plattform.
CDNDas System kann den Netzwerkverkehr und die Verbindung jedes Knotens, den Laststatus und die Entfernung zum Benutzer in Echtzeit analysieren und Antwortzeit usw. Die umfassenden Informationen leiten die Anfrage des Benutzers an den Dienstknoten weiter, der dem Benutzer am nächsten liegt. Sein Zweck besteht darin, es Benutzern zu ermöglichen, die Inhalte, die sie benötigen, in der Nähe abzurufen, Überlastungen des Internetnetzwerks zu beseitigen und die Reaktionsgeschwindigkeit von Benutzern beim Zugriff auf Websites zu verbessern.
Für große E-Commerce-Plattformen ist es im Allgemeinen notwendig, ein CDN für die Netzwerkbeschleunigung aufzubauen. Große Plattformen wie Taobao und JD.com verwenden alle Selbst entwickeltes CDN Kleine und mittlere Unternehmen können mit Drittherstellern von CDN wie Lanxun, Wangsu, Kuaiwang usw. zusammenarbeiten.
Natürlich müssen Sie bei der Auswahl eines CDN-Anbieters die Geschäftsdauer berücksichtigen und prüfen, ob dies der Fall ist skalierbare Bandbreitenressourcen, flexible Verkehrs- und Bandbreitenauswahl, stabile Knoten und Kosteneffizienz.
Eine große Plattform umfasst viele Geschäftsdomänen und verschiedene Geschäftsdomänen haben unterschiedliche Cluster, Sie können DNS Führt die Verteilung oder Abfrage von Domänennamen durch. Die DNS-Methode ist einfach zu implementieren, aufgrund des Vorhandenseins von Cache mangelt es jedoch im Allgemeinen auf kommerzieller Hardware.F5, NetScaler Oder die Open-Source-Softload lvs wird auf der Ebene 4 verteilt. Natürlich wird Redundanz ( wie lvs+keepalived) und die aktive berücksichtigt und Backup-Methoden werden übernommen.
4Schichten Nach der Verteilung an den Geschäftscluster wird es zum Laden über Web-Server wie nginx oder HAProxy auf der 7-Ebene verteilt Balancing oder Reverse-Proxy-Verteilung an die Anwendungsknoten im Cluster.
Welche Last ausgewählt werden soll, erfordert eine umfassende Berücksichtigung verschiedener Faktoren (ob sie eine hohe Parallelität erfüllt und hohe Leistung, wie man die Sitzungsaufbewahrung löst, was der Lastausgleichsalgorithmus ist, Komprimierungsunterstützung, Cache-Speicherverbrauch); das Folgende ist eine Einführung, die auf mehreren häufig verwendeten Lastausgleichssoftware basiert. LVS, das auf der 4-Schicht arbeitet, ist ein leistungsstarker, hochparalleler, skalierbarer und zuverlässiger Load Balancer, der von Linux implementiert wird und a unterstützt Verschiedene Weiterleitungsmodi (NAT, DR, IP-Tunneling), wobei der DR-Modus den Lastausgleich über das WAN unterstützt. Unterstützt Dual-Machine-Hot-Standby (Keepalived oder Heartbeat) . Die Abhängigkeit von der Netzwerkumgebung ist relativ hoch.
Nginx arbeitet auf der 7-Schicht, einer ereignisgesteuerten, asynchronen und nicht blockierenden Architektur und unterstützt Multiprozess-Load-Balancer-/ Reverse-Proxy-Software mit hoher Parallelität. Sie können für http eine gewisse Umleitung vornehmen, die auf Domänennamen, Verzeichnisstrukturen und regulären Regeln basiert. Erkennen Sie interne Serverfehler wie Statuscodes, Zeitüberschreitungen usw., die vom Server zurückgegeben werden, der Webseiten verarbeitet, und senden Sie Anforderungen, die Fehler zurückgeben, erneut an einen anderen Knoten. Der Nachteil besteht jedoch darin, dass dies bei url nicht der Fall ist zum Testen unterstützt. Für Session Sticky kann es basierend auf dem Algorithmus von IP-Hash implementiert werden, und Session Sticky wird durch die Cookie-basierte Erweiterung nginx-sticky-module unterstützt .
HAProxy unterstützt 4 Schichten und 7 Schichten für den Lastausgleich, unterstützt Sitzung Sitzungserhaltung und Cookie-Anleitung; der Backend-URL-Methode; Lastausgleichsalgorithmen sind relativ umfangreich, einschließlich RR, Gewichtung usw.
Für Bilder benötigen Sie Ein separater Domänenname, ein unabhängiger oder verteilter Bildserver oder mogileFS können verwendet werden, um Varnish zum Bildserver für das Bild-Caching hinzuzufügen.
Die Anwendungsschicht läuft auf jboss oder Der TomcatContainer repräsentiert unabhängige Systeme wie Front-End-Shopping, benutzerunabhängige Dienste, Back-End-Systeme usw.
Protokollschnittstelle, HTTP, JSON
können servlet3.0, asynchrones Servlet, verwenden, um das zu verbessern Durchsatz des gesamten Systems
http-Anfrage läuft über Nginx und wird einem Knoten von App Durch den Lastausgleichsalgorithmus ist es relativ einfach, die Kapazität Schicht für Schicht zu erweitern.
Zusätzlich zur Verwendung vonCookie zum Speichern einer kleinen Menge an Benutzerinformationen(Cookie ist im Allgemeinen nicht möglich). 4K-Größe überschreiten), für die App-Zugriffsschicht werden benutzerbezogene Sitzungsdaten gespeichert, einige Reverse-Proxys oder Lastausgleich unterstützen dies jedoch nicht Sitzung bleibt hängenDer Support ist nicht sehr gut oder die Anforderungen an die Zugriffsverfügbarkeit sind relativ hoch(AppDer Zugriffsknoten ist ausgefallen und Sitzunggeht verloren) Dies erfordert die Berücksichtigung der zentralen Speicherung von Sitzungen, um die App-Zugriffsschicht zustandslos zu machen. Gleichzeitig können mehr Anwendungsknoten vorhanden sein, wenn die Anzahl der Systembenutzer zunimmt hinzugefügt.
Zentrale Speicherung von Sitzungenmuss die folgenden Anforderungen erfüllen:
a, effizientes Kommunikationsprotokoll
b, verteilter Cache von Sitzung, unterstützt Knotenskalierung, datenredundante Sicherung und Datenmigration
c, SitzungAblaufmanagement
stellen Dienstleistungen dar, die von Unternehmen in einem bestimmten Bereich bereitgestellt werden. Zu den Feldern gehören Benutzer, Waren, Bestellungen, rote Umschläge, Zahlungsdienste usw. Verschiedene Felder bieten unterschiedliche Dienstleistungen an 🎜>Diese verschiedenen Bereiche bilden Module. Generell sind die Prinzipien hoher Kohäsion und Schnittstellenkonvergenz wichtig. Natürlich können Module entsprechend der Größe der Anwendung gemeinsam bereitgestellt werden. Bei großen Anwendungen werden sie im Allgemeinen unabhängig voneinander bereitgestellt.
Hohe Parallelität:
Das externe Protokoll der Geschäftsschicht wird im
RPC-Modus von
NIOverfügbar gemacht, und zwar im ausgereifteren NIO kann in Kommunikationsframeworks wie netty, mina verwendet werden Verfügbarkeit:Um die Verfügbarkeit von Moduldiensten zu verbessern, wird ein Modul aus Redundanzgründen auf mehreren Knoten bereitgestellt und führt automatisch Lastweiterleitung und Failover durch
;kann zunächst verwendet werdenVIP+Heartbeat-Methode, das aktuelle System verfügt über eine separate Komponente
HA,verwendetZookeeper zur Implementierung( Vorteile gegenüber der Originallösung) Konsistenz, Transaktionen: Konsistenz für verteilte Systeme gewährleistet die Benutzerfreundlichkeit, und Konsistenz kann durch Korrekturlesen erreicht werden, um einen endgültigen konsistenten Zustand zu erreichen.
5. Grundlegende Service-Middleware
1) Kommunikationskomponente
Der Client und der Server unterhalten lange Verbindungen, wodurch die Kosten für den Verbindungsaufbau für jede Anfrage gesenkt werden können. Der Client definiert einen Verbindungspool für jeden Server und kann gleichzeitig eine Verbindung zum Server herstellen
rpcBetrieb, lange Verbindungen im Verbindungspool erfordern eine Heartbeat-Wartung und legen das Anforderungszeitlimit fest.
Der Aufrechterhaltungsprozess langer Verbindungen kann in zwei Phasen unterteilt werden: Die eine ist der Prozess des Sendens der Anfrage und der andere der Prozess des Empfangens der Antwort. Wenn beim Senden der Anfrage eine IOException auftritt, wird die Verbindung als ungültig markiert. Beim Empfang einer Antwort gibt der Server eine SocketTimeoutException zurück. Wenn eine Zeitüberschreitung festgelegt ist, gibt er direkt eine Ausnahme zurück und löscht diese abgelaufenen Anforderungen in der aktuellen Verbindung. Andernfalls senden Sie weiterhin Heartbeat-Pakete
(Da es zu Paketverlusten kommen kann, senden Sie einen PingVorgang, wenn das Intervall pingInterval überschreitet), wenn Wenn Ping fehlschlägt ( sendet IOException) , bedeutet dies, dass ein Problem mit der aktuellen Verbindung vorliegt, dann markieren Sie die aktuelle Verbindung als ungültig; ping ist erfolgreich, was anzeigt, dass die aktuelle Verbindung zuverlässig ist und der Lesevorgang fortgesetzt wird. Ungültige Verbindungen werden aus dem Verbindungspool gelöscht. Jede Verbindung läuft in einem separaten Thread zum Empfangen von Antworten. Der Client kann dies synchron (warten, benachrichtigen) oder asynchron rpc
aufrufen,Die Serialisierung übernimmt die effizientere Hesion-Serialisierungsmethode.
Der Server verwendet das ereignisgesteuerte MINA-Framework von NIO, um Anforderungen mit hoher Parallelität und hohem Durchsatz zu unterstützen.

in Bei den meisten Datenbank-Sharding-Lösungen werden zur Verbesserung des Datenbankdurchsatzes zunächst verschiedene Tabellen vertikal in verschiedene Datenbanken segmentiert.
Wenn eine Tabelle in der Datenbank dann eine bestimmte Größe überschreitet, muss die Tabelle aufgeteilt werden horizontal, und hier gilt das Gleiche als Beispiel:
Für Clients, die auf die Datenbank zugreifen, ist es notwendig, den Speicherort zu lokalisieren, auf den der Benutzer zugreifen muss ID-Daten;
Datensegmentierungsalgorithmus,
führt einen Hash-Vorgang basierend auf der ID des Benutzers durch Hash, diese Methode hat das Problem, ungültige Daten zu migrieren, und der Dienst ist während des Migrationszeitraums nicht verfügbar
Pflegen Sie die Routing-Tabelle. Die Zuordnungsbeziehung zwischen Benutzern und Sharding wird in der Routing-Tabelle unterteilt in Leader und Replica, die für das Schreiben bzw. Lesen verantwortlich sind
Auf diese Weise jedes Geschäft Der Client muss den gesamten Sharding Verbindungspool beibehalten. Dies hat den Nachteil, dass es zu dem Problem einer vollständigen Verbindung kommt
Eine Lösung besteht darin, die Sharding-Methode Sharding zu verwenden. Gehen Sie zur Geschäftsdienstschicht. Jeder Geschäftsknoten unterhält nur eine Shard-Verbindung.
Siehe Bild (Router)

Die Implementierung der Routing-Komponente ist wie folgt (Verfügbarkeit, hohe Leistung, hohe Parallelität)
Basierend auf Leistungsüberlegungen wird die Benutzer-IDMongoDB Die Beziehung zwischen 🎜> und Shard besteht darin, einen Replicatset-Cluster aufzubauen, um die Verfügbarkeit sicherzustellen. biz
sSharding und Datenbanks shardingEs handelt sich um eine Eins-zu-Eins-Korrespondenz und greift nur auf eine Datenbank zuSharding.Geschäft
Geschäft Registrierungsknoten nachzookeepernach oben/bizs/shard/nach unten. Router
ÜberwachungZookeeperKnotenstatus auf /bizs/, Cache onlinebiz befindet sich im Router. Wenn Client Router auffordert, biz zu erhalten, ruft Router zunächst den entsprechenden Shard des Benutzers von mongodb ab ,router erhält den biz-Knoten über den RR-Algorithmus basierend auf dem zwischengespeicherten Inhalt. Um die Verfügbarkeits- und gleichzeitigen Durchsatzprobleme des Routers zu lösen, stellen Sie Redundanz auf dem Router her und gleichzeitig überwacht der Client Zookeepers /routers-Knoten und speichert die Liste der Online-Router-Knoten im Cache. Die traditionelle Art und Weise, HA zu implementieren, ist im Allgemeinen die Verwendung eines virtuellen IP-Drifts in Kombination mit Heartbeat, keepalived usw.HA, KeepalivedVerwenden Sie denvrrp-Modus, um Datenpakete weiterzuleiten und so einen Lastausgleich von 4 Schichten zu ermöglichen. Die Umschaltung erfolgt durch Erkennung von vrrp-Datenpaketen, wodurch redundanter Hot-Standby besser für geeignet ist LVS Übereinstimmung. linux Heartbeat ist ein Hochverfügbarkeitsdienst basierend auf Netzwerk oder Host HAProxy oder Nginx kann Datenpakete basierend auf der 7-Schicht weiterleiten . Daher ist Heatbeat besser für HAProxy und Nginx geeignet, einschließlich Business-Hochverfügbarkeit. In einem verteilten Cluster können Sie Zookeeper für die verteilte Koordination verwenden und den Cluster für die Listenpflege realisieren und Fehlerbenachrichtigung kann der Client den Hash-Algorithmus oder roudrobin wählen, um einen Lastausgleich für den Master-Master-Modus, Master-Slave zu erreichen Modus, der durch den verteilten Sperrmechanismus zookeeper unterstützt werden kann. Die asynchrone Interaktion zwischen verschiedenen Systemen der Plattform erfolgt über die MQ-Komponente. Beim Entwurf von Nachrichtendienstkomponenten müssen Nachrichtenkonsistenz, Persistenz, Verfügbarkeit und ein vollständiges Überwachungssystem berücksichtigt werden. Es gibt zwei Haupt-Open-Source-Nachrichten-Middlewares in der Branche: RabbitMQ und kafka, RabbitMQ folgt dem AMQP-Protokoll und wird von der inhärent hochparallelen erlanng-Sprache entwickelt; kafka ist Linkedin in 2010 JahrDezemberEin Open-Source-Nachrichtenveröffentlichungs- und Abonnementsystem,Es wird hauptsächlich zur Verarbeitung aktiver Streaming-Daten verwendet,Datenverarbeitung großer Mengen von Daten. In Situationen, in denen die Anforderungen an die Nachrichtenkonsistenz relativ hoch sind, ist ein Antwortbestätigungsmechanismus erforderlich, einschließlich des Prozesses der Nachrichtenerstellung und des Nachrichtenkonsums. Das Fehlen von Antworten aufgrund von Netzwerk- und anderen Prinzipien kann jedoch zu Duplikaten von Nachrichten führen. Dies kann auf Geschäftsebene erfolgen. Die Beurteilungsfilterung erfolgt auf Basis der Idempotenz; RabbitMQ übernimmt diesen Ansatz. Es gibt auch einen Mechanismus, bei dem der Verbraucher die LSN-Nummer mitbringt, wenn er die Nachricht vom Broker abruft, und sie von einem bestimmten LSN im Broker Pull-Nachrichten, daher ist kein Antwortmechanismus erforderlich. kafka verteilte Nachrichten-Middleware ist auf diese Weise. Broker kann entsprechend den Zuverlässigkeitsanforderungen der Nachricht und der umfassenden Leistungsmessung im Speicher erfolgen oder im Speicher bestehen bleiben. Für Verfügbarkeit und hohe Durchsatzanforderungen können in tatsächlichen Szenarien sowohl der Cluster- als auch der Aktiv-Standby-Modus angewendet werden. Die -Lösung umfasst gewöhnliche Cluster- und höherverfügbare Mirror-Queue-Methoden. kafka verwendet zookeeper, um den Broker und Verbraucher im Cluster zu verwalten. Sie können Thema bei zookeeperUp; durch den Koordinationsmechanismus von Zookeeper speichert Produzent die Makler-Informationen zum Thema, die an Broker und Produzent können Shards basierend auf der Semantik angeben, und Nachrichten werden an einen bestimmten Shard von Broker gesendet. Im Allgemeinen wird RabbitMQ verwendet in Echtzeit-Messaging, das eine relativ hohe Zuverlässigkeit erfordert. kafka wird hauptsächlich zur Verarbeitung aktiver Streaming-Daten zur Datenverarbeitung großer Datenmengen verwendet. 5) Cache&Puffer In einigen Szenarien mit hoher Parallelität und hoher Leistung kann die Verwendung von Cache die Belastung des Back-End-Systems verringern und den größten Teil des Lesedrucks tragen, was den Durchsatz des Systems erheblich verbessern kann. Beispielsweise wird in einer Datenbank normalerweise vor dem Speichern ein -Cache hinzugefügt. Allerdings wird die Einführung der Cache-Architektur unweigerlich einige Probleme mit sich bringen, wie z. B. CacheTrefferratenprobleme, durch Cachefehler verursachten Jitter, Cache und Speicherkonsistenz. Die Daten im Cache sind im Vergleich zum Speicher begrenzt, daher ist die Situation ideal Hier können einige gängige Algorithmen LRU usw. verwendet werden, um alte Daten zu entfernen, da ein einzelner Knoten Cache die Anforderungen nicht erfüllen kann Anforderungen. Es ist notwendig, einen verteilten Cache aufzubauen. Um den durch den Ausfall eines einzelnen Knotens verursachten Jitter zu beheben, übernimmt der verteilte Cache im Allgemeinen die Lösung der Konsistenz Hash, wodurch das Risiko eines Ausfalls eines einzelnen Knotens erheblich verringert wird. Bei Szenarien mit relativ hohen Verfügbarkeitsanforderungen muss jeder Knoten gesichert werden. Die Daten verfügen sowohl im Cache als auch im Speicher über die gleiche Sicherung. Wenn die Konsistenz relativ stark ist, aktualisieren Sie gleichzeitig den Datenbank-Cache. Für Benutzer mit geringen Konsistenzanforderungen können Sie eine Cache-Ablaufzeitrichtlinie festlegen. Memcached ist ein verteilter Hochgeschwindigkeits-Cache-Server mit einem relativ einfachen Protokoll und basiert auf dem Ereignisverarbeitungsmechanismus von libevent. Das Cache-System wird im Client des Router-Systems in der Plattform verwendet. Die Hotspot-Daten werden auf dem Client zwischengespeichert. Wenn der Zugriff auf die Daten fehlschlägt, greifen Sie auf das Router-System zu. Natürlich werden derzeit mehr In-Memory-Datenbanken für Cache verwendet, wie zum Beispiel Redis , mongodb; redis verfügt über umfangreichere Datenoperationen als memcacheAPI; redis und mongodb alle Daten bleiben erhalten, aber memcache verfügt nicht über diese Funktion, sodass memcache besser zum Zwischenspeichern von Daten in relationalen Datenbanken geeignet ist. PufferSystem wird bei Hochgeschwindigkeits-Schreibvorgängen verwendet Auf der Plattform müssen einige Daten in die Datenbank geschrieben werden, und die Daten werden in Datenbanken und Tabellen unterteilt, aber die Zuverlässigkeit der Daten ist nicht so hoch. Um den Schreibdruck auf die Datenbank zu verringern, können Stapelschreibvorgänge durchgeführt werden angenommen. Öffnen Sie einen Speicherbereich, wenn die Daten einen bestimmten Schwellenwert des Bereichs erreichen, z. B. 80 %, und führen Sie die Sortierung der Unterbibliothek im Speicher durch (die Speichergeschwindigkeit ist immer noch relativ hoch) und leeren Sie dann den Bereich Teilbibliothek stapelweise. Die Suche ist eine sehr wichtige Funktion in E-Commerce-Plattformen. Sie umfasst hauptsächlich die Navigation nach Suchbegriffen, automatische Eingabeaufforderungen und Suchsortierfunktionen. Zu den Open-Source-Suchmaschinen auf Unternehmensebene gehören hauptsächlich Lucene und Sphinx. Ich werde hier jedoch nicht darauf eingehen, welche Grundfunktionen bei der Auswahl unterstützt werden müssen Suchmaschine, nicht-funktionale Aspekte müssen berücksichtigt werden: A. Unterstützt die Suchmaschine die verteilte Indizierung und Suche, um mit riesigen Datenmengen umzugehen, unterstützt sie die Lese-/Schreibtrennung? Verfügbarkeit verbessern? B. Echtzeit-Indizierung Sex c, Leistung Solr ist ein leistungsstarker Volltextsuchserver, der auf lucene basiert. Er bietet eine umfangreichere Abfragesprache als lucene. Er ist konfigurierbar und skalierbar und bietet externe Funktionen Dienste basierend auf der XML/JSON-Formatschnittstelle des lucene 🎜>http-Protokolls. SolrCloudSolr4 verfügbar Version. 🎜> Methode zur Unterstützung der verteilten Indizierung, automatische Durchführung der Sharding-Datensegmentierung durch jedes Shardings Master-Slave (Leader, Replikat) Der -Modus verbessert die Suchleistung; verwenden Sie Zookeeper, um den Cluster zu verwalten, einschließlich der Leader-Auswahl usw., um die Verfügbarkeit des Clusters sicherzustellen. Lucene indizierter Reader basiert auf indiziertem Snapshot, daher muss nach der Indizierung Commit 🎜>Snapshot ein neuer erneut geöffnet werden kann zur Suche nach neu hinzugefügten Inhalten verwendet werden; die Indizierung Commit ist sehr leistungsintensiv, daher ist die Effizienz der Echtzeit-Indexsuche relativ gering. Solr4 Die bisherige Lösung von bestand darin, den vollständigen Dateiindex und die Zusammenführung des inkrementellen Speicherindex zu kombinieren, siehe Abbildung unten. bietet eine Lösung für NRT-Softcommit, SoftcommitSie können nach den neuesten Änderungen am Index suchen, ohne den Indexvorgang zu übernehmen. Die Änderungen am Index werden jedoch nicht synchronisiert auf den Festplattenspeicher übertragen. Dies wird nicht der Fall sein.Commit gehen verloren, daher muss der Commit-Vorgang regelmäßig durchgeführt werden. Die Indizierungs- und Speichervorgänge von Daten in der Plattform sind asynchron, was die Verfügbarkeit und den Durchsatz erheblich verbessern kann; nur Indexoperationen für bestimmte Attributfelder durchführen, den Datenidentifikations- speichern und die Größe des Indexes im verteilten Speicher Hbase reduzieren , hbase unterstützt die Sekundärindexsuche nicht gut, kann aber mit der Solr-Suchfunktion kombiniert werden, um mehrdimensionale Abrufstatistiken durchzuführen. Die Konsistenz von Indexdaten und Datenspeicherung, also wie Um sicherzustellen, dass die in HBase gespeicherten Daten indiziert wurden, können Sie den Bestätigungsmechanismus Bestätigen verwenden, um vor der Indizierung eine Datenwarteschlange zu erstellen Die zu indizierende Datenwarteschlange wird aus der zu indizierenden Datenwarteschlange abgerufen. 7) Protokollerfassung Das Protokollsystem muss drei Grundkomponenten haben, nämlich Agent (kapselt die Datenquelle und sendet die Daten in der Datenquelle an Collector), Collector (Daten von mehreren Agenten empfangen, zusammenfassen und in den Store des Backends importieren), Store (zentrales Speichersystem, sollte skalierbar und zuverlässig sein. Es sollte unterstützen das derzeit sehr beliebte HDFS). Open Source Die in der Branche am häufigsten verwendeten Protokollerfassungssysteme sind Clouderas Flume und Facebooks Scribe, darunter Flume Die aktuelle Version FlumeNG hat wesentliche architektonische Änderungen an Flume vorgenommen. im Design Oder bei der technischen Auswahl eines Protokollerfassungssystems muss es normalerweise die folgenden Eigenschaften aufweisen: a. Eine Brücke zwischen dem Anwendungssystem und dem Analysesystem, die die Beziehung zwischen ihnen entkoppelt b, verteilt und skalierbar, mit hoher Skalierbarkeit. Wenn die Datenmenge zunimmt, kann sie durch Hinzufügen von Knoten horizontal erweitert werden. Das Protokollerfassungssystem ist skalierbar und kann auf allen Ebenen des Systems skaliert werden Es ist kein Status erforderlich, und die Skalierbarkeit ist relativ einfach zu implementieren. c. Nahezu in Echtzeit In einigen Szenarien mit hohen Aktualitätsanforderungen ist es notwendig, Protokolle rechtzeitig für die Datenanalyse zu sammeln Allgemeine Protokolldateien werden Rolling wird regelmäßig oder quantitativ durchgeführt, sodass die Generierung von Protokolldateien in Echtzeit erkannt wird, ähnliche Tail-Vorgänge an den Protokolldateien zeitnah ausgeführt werden und Batch-Versand zur Verbesserung unterstützt wird Übertragungseffizienz; Der Zeitpunkt des Stapelversands muss den Anforderungen an Nachrichtenmenge und Zeitintervall entsprechen. d. Fehlertoleranz ScribeDie Fehlertoleranz wird berücksichtigt, wenn das Back-End-Speichersystem abstürzt, scribe schreibt die Daten auf die lokale Festplatte. Wenn das Speichersystem wieder normal ist, lädt scribe das Protokoll neu in das Speichersystem. FlumeNG erreicht Lastausgleich und Failover durch Sink Processor. Mehrere Senken können eine Senkengruppe bilden. Ein Sink-Prozessor ist für die Aktivierung eines Sink aus einer angegebenen Sink-Gruppe verantwortlich. Der Sink-Prozessor kann einen Lastausgleich über alle Senke in der Gruppe erreichen; er kann auch auf eine andere Senke übertragen werden, wenn er ausfällt. e. Transaktionsunterstützung Scribe berücksichtigt keine Transaktionsunterstützung. Flume realisiert die Transaktionsunterstützung durch den Antwortbestätigungsmechanismus, siehe Abbildung unten, Normalerweise werden Nachrichten extrahiert und gesendet Bei Stapelvorgängen handelt es sich bei der Nachrichtenbestätigung um die Bestätigung eines Datenstapels, wodurch die Effizienz des Datenversands erheblich verbessert werden kann. f. Wiederherstellbarkeit FlumeNGs Kanal kann auf Speicher- und Dateipersistenzmechanismen basierend auf unterschiedlichen Zuverlässigkeitsanforderungen basieren. Das Verkaufsvolumen der speicherbasierten Datenübertragung ist relativ hoch, aber nachdem der Knoten ausgefallen ist , die verlorenen und nicht wiederherstellbaren Daten; Ausfallzeit der Dateipersistenz kann wiederhergestellt werden. g. Regelmäßige und quantitative Archivierung von Daten Nachdem die Daten vom Protokollerfassungssystem erfasst wurden, werden sie im Allgemeinen in einem verteilten Dateisystem gespeichert, z Als Hadoop ist es zur Erleichterung der anschließenden Verarbeitung und Analyse von Daten erforderlich, (TimeTrigger) oder quantitative (SizeTriggers zu planen rollierendeDatei des verteilten Systems Tail Dateien, um Dateiänderungen in Echtzeit zu verfolgen und , in Batches oder Multi-Threads zur Datenbank. Die Architektur ähnelt dem Protokollsammlungs-Framework. Diese Methode erfordert einen Bestätigungsmechanismus, der zwei Aspekte umfasst. dem Agenten bestätigen muss, dass er Datensätze stapelweise empfangen und gesendet hat LSN-Nummer an Agent, sodass er, wenn Agent ausfällt und wiederhergestellt wird, Ende an diesem LSN-Punkt starten kann; Natürlich ist eine geringfügige Vervielfältigung zulässig. Aufgezeichnetes Problem ( trat auf, als Kanal dem Agent bestätigt wurde, Agent ausfiel und nicht empfangen wurde die Bestätigungsnachricht), müssen im Geschäftsszenario beurteilt werden. Kanal zu zu synchronisieren zu bestätigen, dass das Schreiben erfolgt ist stapelweise abgeschlossen Vorgang in der Datenbank, sodass Kanal diesen Teil der Nachricht löschen kann, der bestätigt wurde. Kanal Dateipersistenz verwenden. Es ist notwendig, die Quelldaten wie MySQL zu segmentieren, die Quelldaten gleichzeitig mit mehreren Threads zu lesen und gleichzeitig stapelweise in eine verteilte Datenbank wie HBase zu schreiben, mit KanalAls Puffer zwischen Lesen und Schreiben, um eine bessere Entkopplung zu erreichen, kann Kanal auf Dateispeicher oder Speicher basieren. Siehe das Bild unten: Für die Segmentierung von Quelldaten , Wenn es sich um eine Datei handelt, können Sie die Blockgröße entsprechend dem Dateinamen festlegen, um sie aufzuteilen. Für relationale Datenbanken besteht die allgemeine Anforderung darin, Daten nur für einen bestimmten Zeitraum offline zu synchronisieren (Synchronisieren Sie beispielsweise die Bestelldaten des Tages frühzeitig mit HBase Morgen), also ist es notwendig, wenn Daten aufgeteilt werden ( wird entsprechend der Anzahl der Zeilen aufgeteilt ) , Multithreads scannen die gesamte Tabelle ( Indizes rechtzeitig erstellen und die Tabelle zurückgeben ) , bei Tabellen mit großen Datenmengen ist IO sehr hoch und die Effizienz hier sehr gering; Die Datenbank entsprechend dem Zeitfeld (nach Zeit)Partitionen erstellen und jedes Mal entsprechend den Partitionen exportieren. Vom traditionellen Parallelverarbeitungscluster basierend auf relationalen Datenbanken, der für In-Memory-Computing nahezu in Echtzeit verwendet wird, bis zum aktuellen Cluster basierend auf hadoop Analyse großer Datenmengen. Die Datenanalyse wird häufig auf großen E-Commerce-Websites verwendet, einschließlich Verkehrsstatistiken, Empfehlungs-Engines, Trendanalysen, Benutzerverhaltensanalysen, Data-Mining-Klassifizierern, verteilten Indizes usw. Der Parallelverarbeitungscluster verfügt über kommerzielles , und die Architektur von Greenplum übernimmt MPP( Groß angelegte Parallelverarbeitung), eine verteilte Datenbank basierend auf postgresql für die Speicherung großer Datenmengen. In Sachen In-Memory-Computing gibt es HANA, die Open-Source-nosql In-Memory-Datenbank mongodb unterstützt auch mapreduce für die Datenanalyse. Die Offline-Analyse großer Datenmengen wird derzeit häufig von Internetunternehmen eingesetzt , Hadoop bietet unersetzliche Vorteile in Bezug auf Skalierbarkeit, Robustheit, Rechenleistung und Kosten. Tatsächlich ist es zur Mainstream-Big-Data-Analyseplattform für aktuelle Internetunternehmen gewordenHadoop MapReuce verwendet, und seine Skalierbarkeit ist ebenfalls sehr gut; das größte Manko von MapReduce Es handelt sich um ein Szenario, das Echtzeitanforderungen nicht erfüllen kann und hauptsächlich für Offline-Analysen verwendet wird. Basierend auf der MapRduce-Modellprogrammierung für die Datenanalyse ist die Entwicklungseffizienz nicht hoch. Das Aufkommen von Hive auf Hadoop ermöglicht die Datenanalyse Ähnlich wie beim Schreiben wird sql einer Syntaxanalyse unterzogen und Ausführungspläne generiert, um schließlich MapReduce-Aufgaben für die Ausführung zu generieren erreicht das Ziel einer Ad-hoc-Methode (Berechnung der Analyse, die auf durchgeführt wird), wenn eine Abfrage auftritt. Die Analyse verteilter Daten basierend auf dem -Modell ist eine reine Offline-Analyse, und die Ausführung erfolgt ausschließlich durch Brute-Force-Scannen und kann keinen indexähnlichen Mechanismus verwenden QuelleCloudera Impala basiert auf dem parallelen Programmiermodell von MPP. Die zugrunde liegende Schicht ist eine leistungsstarke Echtzeit-Analyseplattform, die in Hadoop gespeichert ist Reduzieren Sie die Verzögerung der Datenanalyse erheblich. Die aktuelle Version von ist Hadoop1.0 Einerseits weist das ursprüngliche MapReduce-Framework ein Einzelpunktproblem von JobTracker auf. Andererseits übernimmt JobTracker die Ressourcenverwaltung und Aufgabenplanung Gleichzeitig gibt es mit der Zunahme der Datenmenge und der Zunahme der Job-Aufgaben offensichtliche Engpässe bei der Skalierbarkeit, dem Speicherverbrauch, dem Thread-Modell, der Zuverlässigkeit und der Leistung; Das gesamte Framework wurde neu strukturiert, Ressourcenmanagement und Aufgabenplanung wurden getrennt und dieses Problem wurde vom Architekturentwurf an gelöst. Referenzgarn Architektur 10) Echtzeit-Computing CEP Esper usw. sind die Open-Source-Produkte von Storm am weitesten verbreitet. Für eine Echtzeit-Computing-Plattform müssen die folgenden Faktoren im Hinblick auf das architektonische Design berücksichtigt werden: 1, Skalierbarkeit Twitters Storm schneidet in den oben genannten Aspekten besser ab. Lassen Sie uns kurz die Architektur von Storm vorstellen. Der gesamte Cluster wird über Zookeeper verwaltet. Der Client übermittelt die Topologie an nimbus. Nimbus Erstellen Sie ein lokales Verzeichnis für diese Topologie. Berechnen Sie die Aufgabe basierend auf der Konfiguration der Topologie , und ordnen Sie Aufgabe zu, richten Sie Zuweisungen KnotenspeicherAufgabe auf Zookeeper und Woker in der Maschinenknoten >Korrespondenz ein . taskbeats-Knoten auf zookeeper, um den Heartbeat von task zu überwachen; starten Sie Topologie. Gehe zu Tierpfleger zu Holen Sie sich zugewiesene Aufgaben, starten Sie mehrere Woker, um fortzufahren. Jeder Woker generiert eine Aufgabe, einen Aufgaben-Thread ; Initialisieren Sie die Verbindung zwischen Task basierend auf Topologie-Informationen . Die Verbindung zwischen Task und Task erfolgt über zeroMQ verwaltet; und dann dann läuft die gesamte Topologie. ist die grundlegende Verarbeitungseinheit des Streams, Das heißt, eine Nachricht, Tuple, fließt in task. Der Sende- und Empfangsprozess von Tuple ist wie folgt: Tuple, Worker stellt eine Transfer-Funktion für bereit Die aktuelle Aufgabe sendet Tupel an eine andere Aufgabe. Serialisieren Sie mit den Zweckparametern taskid und tuple die tuple-Daten und stellen Sie sie in die Übertragungswarteschlange. Vor der Version 0.8 war diese Warteschlange LinkedBlockingQueue und nach 0.8 war sie DisruptorQueue . bei 0,8 Nach der Version ist jeder Woker an eine Eingangsübertragungswarteschlange und Ausgangsübertragungswarteschlange gebunden, und die Eingangswarteschlange wird zum Empfangen von Nachricht, Outbond-Warteschlange wird zum Senden von Nachrichten verwendet. Beim Senden einer Nachricht ruft ein einzelner Thread Daten aus der Transferwarteschlange ab und sendet dieses Tupel über zeroMQ 🎜> an andere Woker Tupel, jeweils woker hört auf den TCP-Port von zeroMQ, um Nachrichten zu empfangen. Nachdem die Nachricht in DisruptorQueue platziert wurde, wird sie dann gesendet WarteschlangeRufen Sie message(taskid,tuple) ab und leiten Sie sie zur Ausführung basierend auf dem Wert des Ziels taskid, tuple an task weiter. Jedes Tupel kann emittieren, um Dampf zu leiten, oder kann an regulären Stream in Reglular gesendet werden Auf diese Weise wird die Funktion Stream-Gruppe (Stream-ID-->Komponenten-ID -->Outbond-Aufgaben) verwendet, um die zu vervollständigen, die vom aktuellen tuple Das Ziel von Tuple. Durch die obige Analyse können wir sehen, dass Storm ack-Komponente von Storm den XOR-xor-Algorithmus dass jede Nachricht vollständig verarbeitet wird, ohne gleichzeitig an Leistung zu verlieren. Es gibt viele Technologien, um Echtzeit-Push zu erreichen, einschließlich der Comet Websocket-Methode usw. Comet „Server Push“-Technologie basierend auf einer langen Serververbindung, einschließlich zweier Arten: Long Polling: Der Server hängt nach dem Empfang der Anfrage und wenn es ein Update gibt Die Verbindung wird nach der Rückkehr getrennt und der Client initiiert dann eine neue Verbindung StreamMethode: Die Verbindung wird nicht jedes Mal geschlossen, wenn die Serverdaten übertragen werden. Die Verbindung wird nur kommuniziert, wenn ein Fehler auftritt oder die Verbindung wiederhergestellt wird, wird sie geschlossen (einige Firewalls sind oft so eingestellt, dass sie zu lange Verbindungen verwerfen. Der Server kann ein Timeout festlegen und den Client benachrichtigen, die Verbindung danach erneut herzustellen den Timeout und schließen Sie die ursprüngliche Verbindung). Websocket: lange Verbindung, Vollduplex-Kommunikation ist ein neues Protokoll von HTML5 . Es implementiert eine bidirektionale Kommunikation zwischen dem Browser und dem Server. WebSocket-API , der Browser und der Server müssen nur eine Handshake-Aktion übergeben, um einen schnellen Zwei-Wege-Kanal zwischen dem Browser und dem Client zu bilden, sodass Daten schnell in beide Richtungen übertragen werden können. Socket.io ist eine NodeJS-Websocket-Bibliothek, einschließlich clientseitigem js und Server- Seite nodejs, die zum schnellen Erstellen von Echtzeit-Web-Anwendungen verwendet wird. Wird hinzugefügt Datenbankspeicherung ist im Allgemeinen in die folgenden Kategorien unterteilt, einschließlich relationaler (Transaktions-)Datenbanken, wie z. B. Oracle, MySQL wird durch die keyvalue-Datenbank dargestellt, die durch redis und memcached db dargestellt wird, und es gibt Dokumentdatenbanken wie mongodb, die dies haben Spalten Die verteilten Datenbanken werden durch HBase, cassandra, dynamo sowie andere Diagrammdatenbanken, Objektdatenbanken, xml-Datenbanken usw. dargestellt. Die Geschäftsfelder jeder Art von Datenbankanwendung sind unterschiedlich. Im Folgenden finden Sie eine Analyse der Leistung, Verfügbarkeit und anderer Aspekte verwandter Produkte aus den drei Dimensionen Speicher, relational und verteilt. In-Memory-Datenbank zielt auf hohe Parallelität und hohe Leistung ab, ist hinsichtlich der Transaktionalität nicht so streng und verwendet Open Source nosqlDatenbankmongodb, redis zum Beispiel Ø Mongodb Kommunikationsmethode Multithreading-Methode, der Hauptthread überwacht neue Verbindungen und startet nach der Verbindung einen neuen Thread, um Datenoperationen durchzuführen (IO Umschalten). Datenstruktur Datenbank-->collection-->record MongoDB ist in der Datenspeicherung in Namespaces unterteilt. Eine Collection ist ein Namespace, ebenso wie ein Index. Ein Namensraum. Daten im selben Namespace sind in viele Extent unterteilt, und Extent sind über eine doppelt verknüpfte Liste verbunden. In jedem Extent werden spezifische Daten jeder Zeile gespeichert, und diese Daten sind auch über bidirektionale Links verbunden. Jede Zeile des Datenspeicherplatzes umfasst nicht nur den von den Daten belegten Speicherplatz, sondern kann auch einen Teil des zusätzlichen Speicherplatzes enthalten, sodass die Position nicht verschoben werden kann, nachdem die Datenaktualisierung größer geworden ist. Der Index ist in der Struktur BTree implementiert. Wenn Sie das Jourunaling-Protokoll aktivieren, gibt es auch einige Dateien, in denen alle Ihre Betriebsaufzeichnungen gespeichert sind. Persistenter Speicher MMap-Methode ordnet Dateiadressen dem Speicheradressraum zu Sie können den Speicheradressraum direkt zum Bearbeiten von Dateien verwenden, ohne Schreib- und Lesevorgänge aufzurufen. Die Leistung ist relativ hoch. mongodb ruft mmap auf, um die Daten auf der Festplatte dem Speicher zuzuordnen, daher muss es einen Mechanismus geben, um die Daten in den Speicher zu übertragen Um die Zuverlässigkeit zu gewährleisten, hängt die Häufigkeit des Putzens vom Parameter syncdelay ab. journal (zur Wiederherstellung) ist das Redo-Log in Mongodb und Oplog ist für das Kopieren von binlog verantwortlich. Wenn Journal eingeschaltet ist, gehen auch bei ausgeschaltetem Gerät nur 100 ms Daten verloren, was für die meisten Anwendungen tolerierbar ist. Ab 1.9.2+ aktiviert mongodb standardmäßig die Funktion Journal, um die Datensicherheit zu gewährleisten. Und die Aktualisierungszeit von Journal kann im Bereich von 2-300 ms geändert werden, verwenden Sie den Befehl --journalCommitInterval . Die Zeit für die Aktualisierung von Oplog und den Daten auf der Festplatte beträgt 60 Sekunden. Für die Replikation muss nicht darauf gewartet werden, dass oplog die Festplatte aktualisiert direkt in den Knoten kopiert werden. Transaktionsunterstützung Unterstützt nur atomare Operationen für einzeilige Datensätze HACluster Replica Sets, das einen Wahlalgorithmus zur automatischen Erstellung verwendet PerformLeader Wahl kann starke Konsistenzanforderungen erfüllen und gleichzeitig die Verfügbarkeit sicherstellen. mongodb Daten-Sharding-ArchitekturSharding. Kommunikationsmethode CPU-Umschaltaufwand reduzieren, es handelt sich also um einen Single-Thread-Modus (logischer Verarbeitungsthread und ...). Hauptthread ist derselbe). Reaktor-Modus, implementieren Sie Ihren eigenen Multiplexing-NIO-Mechanismus (epoll, select, kqueue usw.) Single-Thread-Verarbeitung Multitasking Datenstruktur Hash+Bucket-Struktur: Wenn die Länge der verknüpften Liste zu lang ist, werden Migrationsmaßnahmen ergriffen (Erweitern des ursprünglichen Doppelten des HashTabelle, Daten dorthin migrieren, erweitern+aufwärmen) persistent Speicher , vollständige Persistenz RDB (Traverse redisDB, lesen Schlüssel, WertBucket 🎜>), der Befehl save blockiert den Hauptthread und der Befehl bgsave startet einen Unterprozess, um den Persistenzvorgang snapshot auszuführen und den zu generieren rdb-Datei. Herunterfahren wird der Vorgang Speichern aufgerufen
b, inkrementelle Persistenz (aof ähnelt redolog ), schreibt zuerst in den Protokoll-Puffer, und flush dann in die Protokolldatei (die Strategie von flush flush in die Datei, bevor sie tatsächlich an den Client zurückgegeben wird. Achten Sie darauf, regelmäßig nachzuschauen aof-Dateien und rdb-Dateien werden zusammengeführt (während des Snapshot-Vorgangs werden die geänderten Daten zuerst in aof buf geschrieben und dann vervollständigt der untergeordnete Prozess den Snapshot<SpeicherSchnappschuss>, dann die geänderten Teile von aofbuf3) HA
4) NachrichtNachricht
System
6) Suche

während der gesamten Transaktion Prozess Es wird eine große Anzahl von Protokollen generiert. Diese Protokolle müssen gesammelt und in einem verteilten Speichersystem gespeichert werden, um eine zentralisierte Abfrage- und Analyseverarbeitung zu ermöglichen.



9) Datenanalyse

Web
Echtzeit-Chat usw. 12) Empfehlungsmaschine
6. Datenspeicherung
1) In-Memory-Datenbank

Im Modus für hohen gleichzeitigen Zugriff RDB-Modus führt zu offensichtlichen Schwankungen in den Leistungsindikatoren des Dienstes. aof ist hinsichtlich des Leistungsaufwands besser als RDB, aber das Neuladen erfordert Zeit und Datenvolumen Speicher während der Wiederherstellung. Direkt proportional.
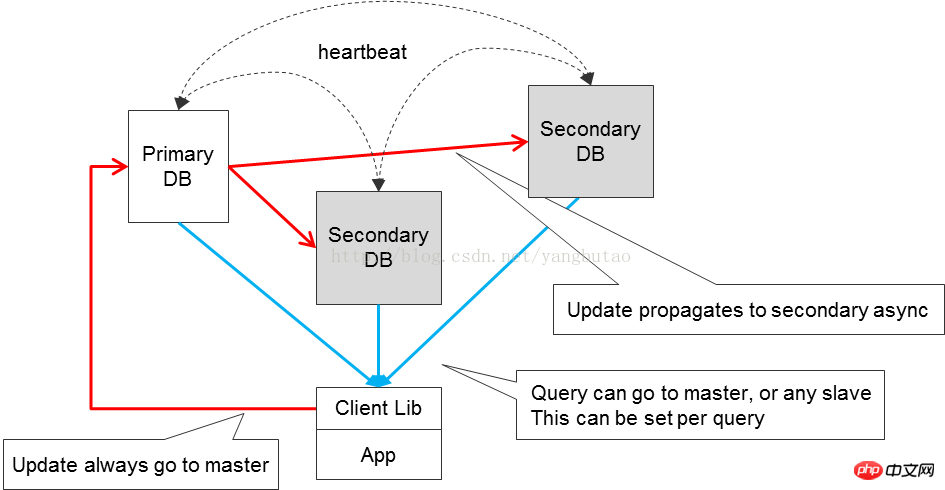
ClusterHA Die gängige Lösung ist die Master-Slave-Backup-Umschaltung unter Verwendung von HA-Software, sodass der ausgefallene Master-Redis schnell auf den Slave-Redis umgeschaltet werden kann. Die Master-Slave-Datensynchronisation übernimmt den Replikationsmechanismus, und in diesem Szenario können Lesen und Schreiben getrennt werden. Derzeit besteht ein Problem bei der Replikation darin, dass, wenn das Netzwerk instabil ist, SlaveVerbindungsunterbrechung (einschließlich Flash-Verbindung) auftritt ) vom Master bewirkt, dass Master alle Daten im Speicher in einer rdb-Datei (Snapshot-Datei) neu generiert und diese dann an Slave. Nachdem Slave die vom Master übergebene rdb-Datei empfängt, löscht er seinen eigenen Speicher und lädt die rdb-Datei neu in den Speicher. Diese Methode ist relativ ineffizient. In der zukünftigen Version Redis2.8 hat der Autor die teilweise Kopierfunktion implementiert. MySQLDie Datenbank wird übernommen als Beispiel, um die Prinzipien des Architekturdesigns, Leistungsüberlegungen und die Erfüllung von Verfügbarkeitsanforderungen zu beschreiben. (innodb) MySQL Punkte Für die Server-Schicht und die Speicher-Engine-Schicht. ist für verschiedene Speicher-Engines gleich, einschließlich Verbindungen/ Thread-Verarbeitung, Abfrageverarbeitung (Parser , Optimierer) und andere Systemaufgaben. Es gibt viele Speicher-Engine-Ebenen. mysql bietet eine Plug-in-Struktur von Speicher-Engines und unterstützt mehrere Speicher-Engines. Die am häufigsten verwendeten sind innodb und myisamin ;inodb ist hauptsächlich für OLTP-Anwendungen gedacht und unterstützt die Transaktionsverarbeitung. myisam unterstützt keine Transaktionen und Tabellensperren. Es funktioniert schnell auf OLAP . innodb-Speicher-Engine vorgestellt. In Bezug auf die Thread-Verarbeitung ist Mysql eine Multithread-Architektur, die aus einem Master-Thread, einem Sperrüberwachungs-Thread, einem Fehlerüberwachungs-Thread und mehreren besteht IOThread-Zusammensetzung. Und ein Thread wird geöffnet, damit eine Verbindung hergestellt werden kann. Der IO-Thread ist in Einfügepuffer unterteilt, der zufällige IO speichert und für die Transaktionssteuerung verwendet wird, ähnlich wie Oracle >Redo-Log sowie mehrere Schreib-, mehrere Lese- IO-Threads für Festplatten- und Speicheraustausch. Innodb-Pufferpool und Protokollpuffer. Darunter umfasst Innodb-Pufferpool Einfügepuffer, Datenseite, Indexseite, Datenwörterbuch und adaptiven Hash. Protokollpuffer wird zum Zwischenspeichern von Transaktionsprotokollen verwendet, um die Leistung zu verbessern. innodb Tabellenbereich, Segment, Bereich, Seiten-/-Block und Zeile. Die Indexstruktur ist eine B+tree-Struktur, einschließlich Sekundärindex und Primärschlüsselindex. Der Blattknoten des Sekundärindex ist der Primärschlüssel PK, und der Blattknoten ist entsprechend indiziert Der Primärschlüssel verweist auf den gespeicherten Datenblock. Diese B+-Baumspeicherstruktur kann die IO-Anforderungen von Zufallsabfragevorgängen besser erfüllen. Sie ist in Datenseiten und sekundäre Indexseiten unterteilt Um die Schreibleistung zu verbessern, verwenden Sie Einfügepuffer, um sequentielles Schreiben durchzuführen. Anschließend führt der Hintergrundthread mehrere Einfügungen mit einer bestimmten Häufigkeit in der sekundären Indexseite zusammen. Um die Konsistenz der Datenbank(Speicher- und Festplattendatendateien) sicherzustellen und die Wiederherstellungszeit der Instanz zu verkürzen, verfügt die relationale Datenbank auch über einen Prüfpunkt Funktion, verwenden Sie, um die vorherigen schmutzigen Seiten im Speicher Puffer im Verhältnis zu (alte LSN) auf die Festplatte zu schreiben, sodass das Redolog Die LSNder Datei kann während der Wiederherstellung nach einem Fehler überschrieben und recycelt werden; Sie müssen lediglich ab dem LSN-Punkt im Protokoll wiederherstellen. In Bezug auf die Unterstützung von Transaktionsfunktionen müssen relationale Datenbanken die vier Funktionen von ACID erfüllen. Basierend auf unterschiedlichen Anforderungen an die Parallelität von Transaktionen und die Datensichtbarkeit müssen unterschiedliche Transaktionsisolationsstufen definiert werden, die untrennbar miteinander verbunden sind Der Sperrmechanismus für Ressourcenkonflikte dient zur Vermeidung von Deadlocks. mysql führt eine Parallelitätskontrolle auf der Serverebene durch, die sich hauptsächlich in Lese-/Schreibsperren widerspiegelt Es gibt Sperren auf verschiedenen Ebenen (Tabellensperre, Zeilensperre, Seitensperre, MVCC), basierend auf der Überlegung, die Parallelitätsleistung und die Parallelitätskontrolle mehrerer Versionen zu verbessern MVCC wird zur Unterstützung der Transaktionsisolation verwendet und basiert auf Rückgängigmachen. Beim Transaktions-Rollback wird auch das Segment Rückgängigmachen verwendet. mysql Verwenden Sie redolog, um die Leistung beim Schreiben von Daten und die Wiederherstellung nach Fehlern sicherzustellen. Wenn Sie Daten ändern, müssen Sie nur den Speicher ändern und die Änderung dann im Transaktionsprotokoll aufzeichnen (SequentiellIO), es besteht keine Notwendigkeit, die Datenänderung selbst jedes Mal auf der Festplatte beizubehalten(ZufälligIO), was die Leistung erheblich verbessert. In puncto Zuverlässigkeit innodbDie Speicher-Engine bietet einen DoppelschreibmechanismusDoppelschreiber, um Fehler beim Leeren von Seiten in den Speicher zu verhindern und das Problem des Halbschreibers auf der Festplatte zu lösen. Ø Für hohe Parallelität und hohe Leistung MySQL Im Allgemeinen kann die Leistungsoptimierung in mehreren Dimensionen durchgeführt werden. a, Hardwareebene, Die Speicherung von Protokollen und Daten muss nacheinander geschrieben werden und muss durchgeführt werden raid1 +0 und buffer-IO verwenden; Daten werden diskret gelesen und geschrieben. Verwenden Sie einfach direct IO, um die durch die Verwendung des Dateisystems verursachten Probleme zu vermeiden Cache des Overheads. Speicherfähigkeit, SASDiskRAIDBetrieb ( RaidKartencache, Lese-Cache ausschalten, Festplatten-Cache ausschalten, Vorauslesen ausschalten, nur Rückschreibpuffer verwenden, aber Sie müssen das Lade- und Entladeproblem berücksichtigen. Wenn der Datenumfang nicht groß ist, können natürlich Hochgeschwindigkeitsgeräte zur Datenspeicherung verwendet werden, wie z. B. Fusion IO und SSD . Kontrollieren Sie beim Datenschreiben die Häufigkeit der Aktualisierung schmutziger Seiten und beim Datenlesen die Cache-Trefferrate. Schätzen Sie daher die vom System benötigten IOPS und werten Sie sie aus die Anforderungen Die Anzahl der Festplatten (Fusion io bis zu IOPS beträgt mehr als 10 W , normale Festplatten 150) . Cpu schaltet eine einzelne Instanz NUMA aus und MySQL unterstützt Multi-Core nicht sehr gut. Mehrere Instanzen können an CPU gebunden werden . b Optimierung der Betriebssystemebene, Kernel und Socket , Netzwerkoptimierung Bond, Dateisystem, IO Planung innodb wird hauptsächlich in OLTP-Anwendungen sind im Allgemeinen IO-intensive Anwendungen. Aufgrund der Verbesserung der IO-Fähigkeiten nutzen sie den Cache-Mechanismus voll aus. Zu berücksichtigen sind: innodb-Pufferpools ist im Allgemeinen auf 3/4 MySQL zu vermeiden, indem Sie Swap verwenden (Sie können vm.swappiness=0 um das Dateisystem freizugeben, wenn der Speicher knapp ist) Cache)IO Planungsoptimierung, Reduzierung unnötiger Blockierungen und Reduzierung der Zufälligkeit IO (CFQ, Deadline, NOOP)c, Server- und Speicher-Engine-Ebene (Verbindungsverwaltung, Netzwerkverwaltung, Tabellenverwaltung Enthält Cache/Puffer, , IO d. Anwendungsebene (z. B. Indexüberlegungen, Optimierung des Schemas mit entsprechender Redundanz; Optimierung von -Problemen und Speicherproblemen, die durch SQL Abfragen, um den Umfang von Sperren zu reduzieren, Back-Table-Scans zu reduzieren, Indizes abzudecken) Ø Im Hinblick auf die Hochverfügbarkeitspraxis , unterstützt den Modus Master-Master Master-Slave Master-Master ist einer als Master für das Lesen und Schreiben verantwortlich , und der andere ist für die Notfallwiederherstellung verantwortlich, da Standby einer ist, der als Master Schreibvorgänge bereitstellt, und mehrere andere Knoten dienen als Lesevorgänge und unterstützen Lese- und Schreibvorgänge Trennung. Für die Erkennung und Umschaltung von Knoten-Primär- und Backup-Ausfällen kann Natürlich kann die HA-Software auch zookeeper als Cluster-Koordinationsdienst verwenden, um eine detailliertere Anpassung zu ermöglichen. Bei verteilten Systemen ist die Konsistenz der Datenbank-Primär- und Backup-Umschaltung immer ein Problem. Es gibt mehrere Möglichkeiten: a , Clustering-Methode, wie Oracles , der Nachteil ist, dass es komplizierter ist b, gemeinsame SAN Speichermethode, zugehörige Datendateien und Protokolldateien werden im gemeinsamen Speicher abgelegt. Der Vorteil besteht darin, dass die Daten während der aktiven und Backup-Umschaltung konsistent bleiben und nicht verloren gehen . Aufgrund der Sicherung kommt es jedoch zu einem kurzfristigen Nichtverfügbarkeitszustand c und Sicherungsmethoden für die Datensynchronisierung. Die häufigste Methode ist die Protokollsynchronisierung, die eine gute Echtzeitleistung gewährleistet, aber während des Wechsels werden möglicherweise einige Daten nicht synchronisiert, was zu Problemen mit der Datenkonsistenz führt. Sie können das Betriebsprotokoll aufzeichnen, während die Hauptdatenbank in den Standby-Modus wechselt. Diese wird mit dem Betriebsprotokoll überprüft, um die nicht synchronisierten Daten auszugleichen d Eine andere Möglichkeit besteht darin, die Standby-Datenbank auf die Speicherung von regolog der Hauptdatenbank umzustellen, um sicherzustellen, dass keine Daten verloren gehen. Die Effizienz der Datenbank-Master-Slave-Replikation ist unter MySQL nicht allzu hoch. Der Hauptgrund dafür ist, dass Transaktionen strikt die Reihenfolge beibehalten und der Index mysqlIn Bezug auf die Replikation, einschließlich Protokoll und Relog-Protokoll, handelt es sich bei beiden Prozessen um serielle Single-Thread-Operationen. Versuchen Sie, IO so viel Einfluss wie möglich. Mit der Mysql5.6-Version kann jedoch die parallele Replikation auf verschiedenen Bibliotheken unterstützt werden. Ø Zugriffsmethoden basierend auf unterschiedlichen Geschäftsanforderungen Im Plattformgeschäft haben verschiedene Unternehmen unterschiedliche Zugriffsanforderungen, wie z. B. die beiden typischen Geschäftsbenutzer und Bestellungen. Im Allgemeinen ist die Gesamtzahl der Benutzer kontrollierbar, während die Bestellungen ständig zunehmen. Für Benutzertabellen verwenden wir zunächst Sub-. Bibliothekssegmentierung, und jedes Sharding wird als Master für mehrere Lesevorgänge verwendet. Da Benutzer häufiger ihre eigenen Bestellungen abfragen müssen, muss die Bestelldatenbank auch nach Benutzern segmentiert werden. und unterstützt einen Herrn weiterlesen. Raid-Karte wird verwendet Speicher; Für Datendateien wird es eine große Anzahl zufälliger Lese- und Schreibvorgänge für Benutzer oder Bestellungen geben. Darüber hinaus ist die Erhöhung der Speicherkapazität ein Aspekt IO-Geräte-Flash-Speicher kann verwendet werden, z. B. PCIeKarte . Die Verwendung von Flash-Speicher eignet sich auch für Single-Threaded-Workloads, wie z. B. Master-Slave-Replikation. Sie können die Fusion-IO-Karte auf dem Slave-Knoten konfigurieren, um die Latenz der Replikation zu reduzieren. Für das Auftragsgeschäft nimmt das Volumen stetig zu, PCIe Die Speicherkapazität der Karte ist relativ begrenzt und die wichtigsten Daten des Auftragsgeschäfts beziehen sich nur auf den letzten Zeitraum(zum Beispiel die letzten3Monate , rechts Hier sind zwei Lösungen aufgeführt. Eine davon ist die Flashcache-Methode, die eine Open-Source-Hybridspeichermethode basierend auf Flash-Speicher und Festplattenspeicher verwendet, um Hotspot-Daten im Flash-Speicher zu speichern. Eine andere Methode besteht darin, alte Daten regelmäßig in die verteilte Datenbank HBase zu exportieren. Wenn Benutzer die Bestellliste abfragen, werden die aktuellen Daten von MySQL abgerufen, und die alten Daten können von HBase Das Abfragen in 🎜>HBase erfordert sicherlich ein gutes Rowkey-Design von HBase, um sich an die Abfrageanforderungen anzupassen. Für den Zugriff auf Daten mit hoher Parallelität bieten herkömmliche relationale Datenbanken eine Lösung zur Lese-/Schreibtrennung, die jedoch das Problem der Datenkonsistenz mit sich bringt Bei größeren Datenmengen verwenden herkömmliche Datenbanken Unterdatenbanken und Untertabellen, die komplizierter zu implementieren sind und für eine hohe Verfügbarkeit und Skalierung eine kontinuierliche Migration und Wartung erfordern. Herkömmliche Daten verwenden Main-Standby und Master-Slave. Multi-Master-Lösung, aber ihre Skalierbarkeit ist relativ schlecht. Das Hinzufügen von Knoten und Ausfallzeiten erfordern eine Datenmigration. Für die oben angesprochenen Probleme verfügt die verteilte Datenbank HBase über einen vollständigen Satz von Lösungen, die für den Bedarf an massivem Datenzugriff mit hoher Parallelität geeignet sind. Ø HBase Spaltenbasierte effiziente Speicherung reduziert IO Hohe Leistung LSM-Baum Geeignet für Hochgeschwindigkeits-Schreibszenarien Stark konsistenter Datenzugriff MVCC HBases konsistenter Datenzugriff erfolgt über MVCC erreichen. HBase muss im Prozess des Schreibens von Daten, des Schreibens von HLog, des Schreibens von memstore mehrere Phasen durchlaufen. Aktualisieren Sie MVCC; Das Schreiben ist erfolgreich und die Isolation von Transaktionen muss durch mvcc gesteuert werden. Beim Lesen von Daten können beispielsweise keine Daten abgerufen werden, die nicht von anderen Threads übermittelt wurden. Hohe ZuverlässigkeitHBases Datenspeicherung basiert auf HDFS bietet einen Redundanzmechanismus. Region Knotenausfallzeiten bieten einen zuverlässigen Wiederherstellungsmechanismus für die Daten im Speicher, die nicht in die Datei geleert Skalierbar, automatische Segmentierung, Migration Regionsserver und suchen Sie schließlich die .
Region Server wird erweitert, indem es sich selbst als Master, Master Evenly veröffentlicht verteilt. VerfügbarkeitEs gibt einen einzigen Fehlerpunkt, Regionsserver Nach der Ausfallzeit ist die vom Server verwaltete für kurze Zeit nicht zugänglich und wartet auf den Wirkung. verwaltet den Gesundheitsstatus jedes Regionsservers bis Master und Region Verteilung. Mehrere Master, Master ist ausgefallen und es gibt den Paxos-Abstimmungsmechanismus von Zookeeper, um den nächsten Master auszuwählen . Selbst wenn Master vollständig ausgefallen ist, wird das Lesen und Schreiben von Region nicht beeinträchtigt. Master fungiert nur als automatische Betriebs- und Wartungsrolle. HDFS ist eine verteilte Speicher-Engine mit einem Backup und drei Backups, hoher Zuverlässigkeit und 0 Datenverlust. Der Namenode von HDFS ist ein SPOF. Um zu häufigen Zugriff auf eine einzelne Region und übermäßigen Druck auf eine einzelne Maschine zu vermeiden, wurde ein Split-Mechanismus eingesetzt wird bereitgestellt HBase ist in der Architektur von LSM-TREE geschrieben. Da die Daten anhängen sind, HFileImmer mehr stellt HBase HFile-Dateien für compact bereit, um abgelaufene Daten zu löschen und die Abfrageleistung zu verbessern. Schemafrei HBase hat kein striktes Schema wie eine relationale Datenbank, und Sie können Felder im Schema frei hinzufügen und löschen. HBase , daher ist das Design von rowkey sehr entscheidend für die Leistung der Abfrage. 7. Verwaltungs- und Bereitstellungskonfiguration 8. Überwachung und Statistik Große verteilte Systeme umfassen verschiedene Geräte, wie z. B. Netzwerk-Switches, gewöhnliche PCs Datenklassifizierung der Plattform Systemebene: CPU, Speicher, Netzwerk, IO Anforderungen an die AktualitätSchwellenwert, Alarm: Minutenberechnung nahezu in EchtzeitOffline-Analyse nach Stunde und TagEchtzeitabfrage Architektur Agent Agent Daten werden einheitlich über den Kollektor-Cluster gesammelt und zur Verarbeitung nach verschiedenen Datentypen verteilt. Einige Daten sind nicht aktuell, z. B. stündliche Statistiken, und werden in abgelegt hadoop-Cluster; einige Daten verfolgen Daten des Anforderungsflusses und müssen abgefragt werden, dann können sie zur Indizierung in den solr-Cluster gestellt werden; einige Daten müssen in Echtzeit berechnet und dann benachrichtigt werden , es muss in storm gestellt und im Cluster verarbeitet werden. Nachdem die Daten vom Rechencluster verarbeitet wurden, werden die Ergebnisse in Mysql oder HBaseIn. Web-Anwendung kann die Echtzeit-Überwachungsergebnisse an den Browser übertragen und kann auch eine API Zur Anzeige und Suche von Ergebnissen. 
3) Verteilte Datenbank
Übliche Abfragen erfordern nicht alle Felder in einer Zeile . Die meisten erfordern nur wenige Felder.
Im Vergleich zu zeilenorientierten Speichersystemen werden alle Daten für jede Abfrage abgerufen und dann werden die erforderlichen Felder daraus ausgewählt.
Spaltenorientierte Speichersysteme können eine Spalte separat abfragen. Dadurch stark reduzierenIO
Komprimierungseffizienz verbessern
Daten in derselben Spalte haben eine hohe Ähnlichkeit, was die Komprimierungseffizienz erhöht
Viele Funktionen von Hbasewerden durch die Spaltenspeicherung bestimmt
 über
über Metriken
, Leistungsmetriken

Das obige ist der detaillierte Inhalt vonErstellen Sie eine Architektur mit hoher Parallelität und hoher Verfügbarkeit. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 Einführung in den Inhalt der Java-Kerntechnologie
Einführung in den Inhalt der Java-Kerntechnologie
 Was ist der Unterschied zwischen 4g- und 5g-Mobiltelefonen?
Was ist der Unterschied zwischen 4g- und 5g-Mobiltelefonen?
 Probleme mit Ihrem WLAN-Adapter oder Zugangspunkt
Probleme mit Ihrem WLAN-Adapter oder Zugangspunkt
 Was sind die häufig verwendeten Funktionen von Informix?
Was sind die häufig verwendeten Funktionen von Informix?
 So generieren Sie Zufallszahlen in js
So generieren Sie Zufallszahlen in js
 navigator.appname
navigator.appname
 Die Laufumgebung des Java-Programms
Die Laufumgebung des Java-Programms
 ^quxjg$c
^quxjg$c
 Computer-Anwendungsbereiche
Computer-Anwendungsbereiche








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



