

Lassen Sie uns zunächst kurz Crawler verstehen. Dabei handelt es sich um einen Prozess, bei dem eine Website angefordert und die benötigten Daten extrahiert werden. Was das Klettern und Klettern angeht, wird es später der Inhalt des Lernens sein, sodass es vorerst nicht nötig ist, darauf einzugehen. Über unser Programm können wir in unserem Namen Anfragen an den Server senden und dann große Datenmengen stapelweise herunterladen.
Eine Anfrage initiieren: Eine Anfrage an den Server initiieren Die URL, Anfragen können zusätzliche Header-Informationen enthalten.
Antwortinhalt abrufen: Wenn der Server normal antwortet, erhalten wir eine Antwort. Die Antwort ist der Inhalt der von uns angeforderten Webseite Fügen Sie HTML ein. Json-String oder Binärdaten (Video, Bild) usw.
Inhalt analysieren: Wenn es sich um HTML-Code handelt, kann er mit einem Webseitenparser analysiert werden. Wenn es sich um Json-Daten handelt, kann er in Json konvertiert werden Objekt zum Parsen. Wenn es sich um Binärdaten handelt, können diese zur weiteren Verarbeitung in einer Datei gespeichert werden.
Daten speichern: Sie können sie in einer lokalen Datei oder in einer Datenbank (MySQL, Redis, Mongodb usw.) speichern
Wenn wir eine senden Anfrage an den Server über den Browser Welche Informationen enthält diese Anfrage bei der Anfrage? Wir können es mithilfe der Entwicklertools von Chrome erklären (wenn Sie nicht wissen, wie man es verwendet, lesen Sie die Hinweise in diesem Artikel).
Anfragemethode: Zu den am häufigsten verwendeten Anfragemethoden gehören Get Request und Post Request. Die häufigste Beitragsanfrage in der Entwicklung wird über ein Formular übermittelt. Aus Benutzersicht ist die Anmeldebestätigung die häufigste. Wenn Sie zum Anmelden einige Informationen eingeben müssen, handelt es sich bei dieser Anfrage um eine Post-Anfrage.
URL Uniform Resource Locator: Eine URL, ein Bild, ein Video usw. kann durch die URL definiert werden. Wenn wir eine Webseite anfordern, können wir das Netzwerk-Tag anzeigen. Das erste ist normalerweise ein Dokument, was bedeutet, dass es sich bei diesem Dokument um einen HTML-Code handelt, der nicht mit externen Bildern, CSS, JS usw. gerendert wird. Unter diesem Dokument werden wir dies tun Siehe Bei einer Reihe von JPGs, JS usw. handelt es sich um eine vom Browser immer wieder initiierte Anforderung basierend auf dem HTML-Code. Die angeforderte Adresse ist die URL-Adresse des Bildes, der JS usw. im HTML-Dokument
Anfrage-Header: Anfrage-Header, einschließlich des Anfragetyps, der Cookie-Informationen und des Browsertyps dieser Anfrage. Dieser Anforderungsheader ist weiterhin nützlich, wenn wir Webseiten crawlen. Der Server überprüft die Informationen, indem er den Anforderungsheader analysiert, um festzustellen, ob es sich bei der Anforderung um eine legale Anfrage handelt. Wenn wir also eine Anfrage über ein Programm stellen, das den Browser verschleiert, können wir die Header-Informationen der Anfrage festlegen.
Anfragetext: Die Post-Anfrage verpackt die Benutzerinformationen in Formulardaten zur Übermittlung, also im Vergleich zur Get-Anfrage, der Inhalt des Headers-Tags von Bei der Postanforderung wird es ein zusätzliches Informationspaket mit dem Namen „Formulardaten“ geben. Die Get-Anfrage kann einfach als gewöhnlicher Suchwagenrücklauf verstanden werden, und die Informationen werden in Abständen von ? am Ende der URL hinzugefügt.
Antwortstatus: Der Statuscode kann unter „Allgemein“ in den Kopfzeilen angezeigt werden. 200 bedeutet Erfolg, 301 Sprung, 404 Webseite nicht gefunden, 502 Serverfehler usw.
Antwortheader: Enthält Inhaltstyp, Cookie-Informationen usw.
Antworttext: Der Zweck der Anfrage besteht darin, den Antworttext einschließlich HTML-Code, JSON und Binärdaten abzurufen.
Erstellen Sie Webseitenanforderungen über die Anforderungsbibliothek von Python:

Das Ausgabeergebnis ist der Webseitencode, der noch nicht gerendert wurde, also der Inhalt des Anfragetextes. Sie können die Antwort-Header-Informationen anzeigen:
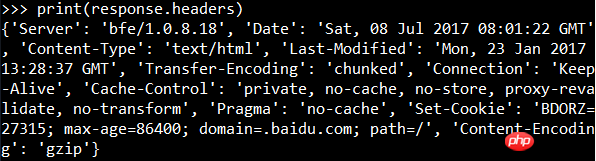
Sie können den Anforderungsinformationen auch Anforderungs-Header hinzufügen:

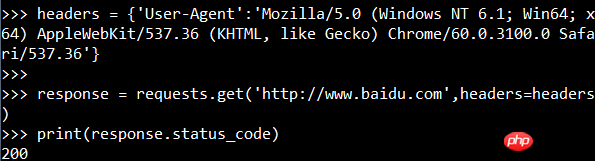
Schnapp dir Bilder (Baidu-Logo): 🎜>
6. So lösen Sie JavaScript-Rendering-Probleme

Geben Sie print(driver.page_source ) und Sie können sehen, dass der Code dieses Mal der Code nach dem Rendern ist.
[Bemerkungen] Verwendung des Chrome-Browsers
HTML-Code. 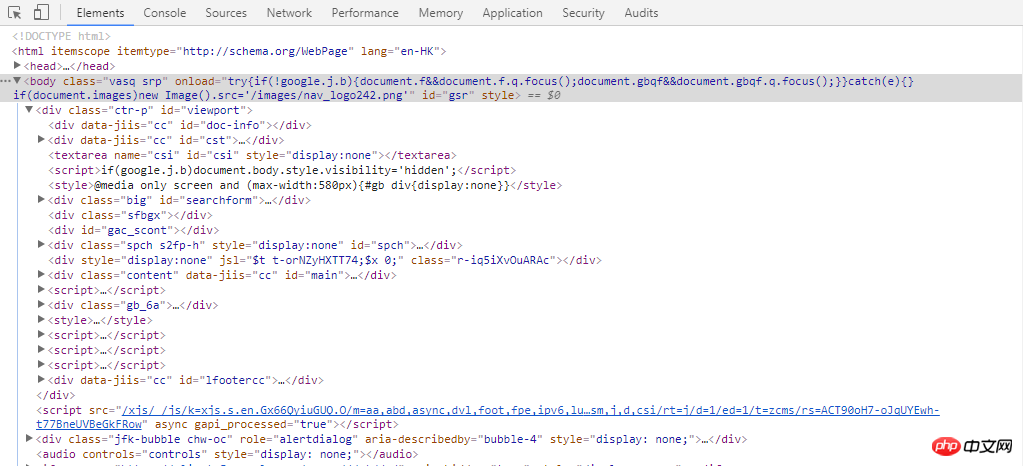
Netzwerk-Tag
Netzwerk-Tag Dort sind vom Browser angeforderte Daten. Klicken Sie darauf, um detaillierte Informationen wie die oben genannten Anforderungsheader, Antwortheader usw. anzuzeigen.
Das obige ist der detaillierte Inhalt vonWas ist ein Crawler? Was ist der grundlegende Prozess des Crawlers?. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!
 So bereinigen Sie das Laufwerk C des Computers, wenn es voll ist
So bereinigen Sie das Laufwerk C des Computers, wenn es voll ist
 Fil-Währungspreis Echtzeitpreis
Fil-Währungspreis Echtzeitpreis
 So schützen Sie Cloud-Server vor DDoS-Angriffen
So schützen Sie Cloud-Server vor DDoS-Angriffen
 So laden Sie Binance herunter
So laden Sie Binance herunter
 So kaufen und verkaufen Sie Bitcoin auf Huobi.com
So kaufen und verkaufen Sie Bitcoin auf Huobi.com
 So öffnen Sie eine ISO-Datei
So öffnen Sie eine ISO-Datei
 Welche Funktionen haben Computernetzwerke?
Welche Funktionen haben Computernetzwerke?
 So verbergen Sie die IP-Adresse
So verbergen Sie die IP-Adresse
 So lösen Sie Probleme beim Parsen von Paketen
So lösen Sie Probleme beim Parsen von Paketen








![[Web-Frontend] Node.js-Schnellstart](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



