
 Backend-Entwicklung
Python-Tutorial
Beispielanzeige für die Pandas-Datenverarbeitung: Erfassung globaler börsennotierter Unternehmensdaten
Backend-Entwicklung
Python-Tutorial
Beispielanzeige für die Pandas-Datenverarbeitung: Erfassung globaler börsennotierter Unternehmensdaten
Beispielanzeige für die Pandas-Datenverarbeitung: Erfassung globaler börsennotierter Unternehmensdaten
Ich habe derzeit eine Kopie der Forbes-Daten zu den „Global Top 2000 Listed Companies 2016“ zur Hand, aber die Originaldaten sind nicht standardisiert und müssen vor der weiteren Verwendung verarbeitet werden.
In diesem Artikel wird anhand praktischer Beispiele die Verwendung von Pandas für die Datenorganisation vorgestellt.
Wie üblich möchte ich zunächst wie folgt über meine Betriebsumgebung sprechen:
Windows 7, 64-Bit
Python 3.5
Pandas Version 0.19.2
Nachdem wir die Originaldaten erhalten haben, werfen wir zunächst einen Blick auf die Daten und überlegen, was Wir brauchen Datenergebnisse.
Hier sind die Rohdaten:
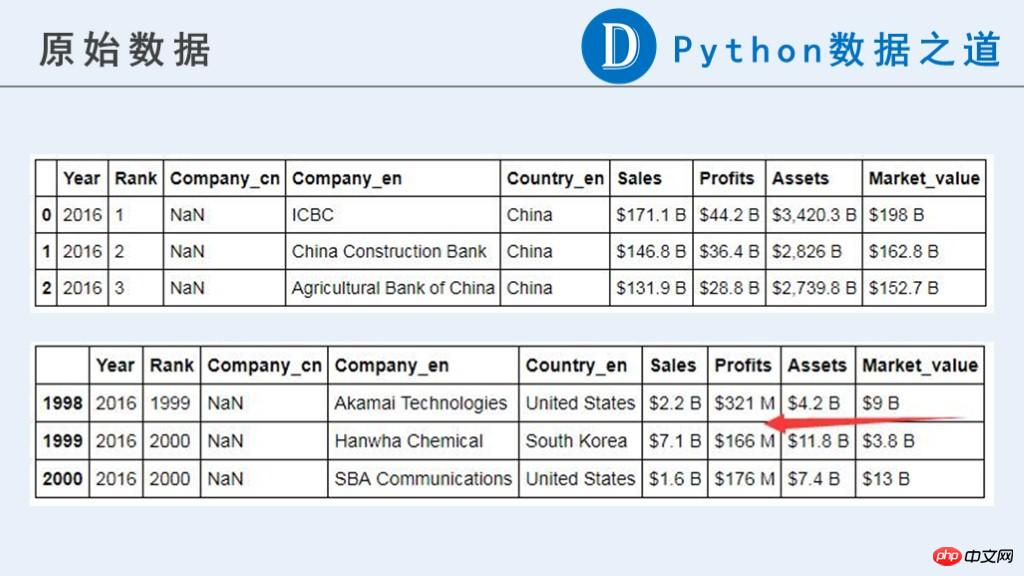
In diesem Artikel benötigen wir die folgenden vorläufigen Ergebnisse für die zukünftige Verwendung.
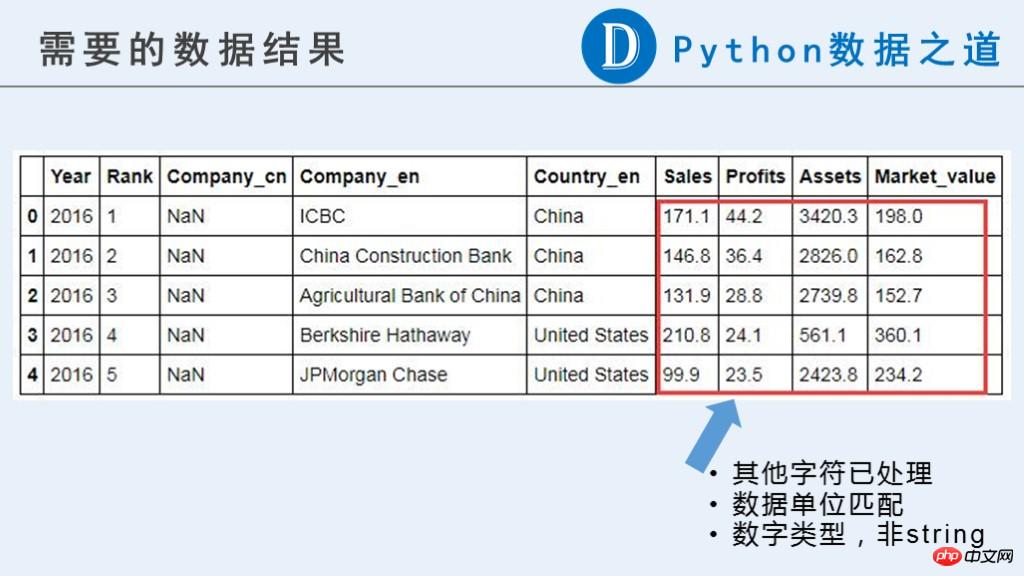
Sie können sehen, dass in den Originaldaten die unternehmensbezogenen Daten („Umsätze“, „Gewinne“, „Vermögenswerte“, „Marktwert“) derzeit nicht vorhanden sind ein numerischer Typ, der für Berechnungen verwendet werden kann.
Der Originalinhalt enthält Währungssymbole „$“, „-“, aus reinen Buchstaben bestehende Zeichenfolgen und andere Informationen, die wir als ungewöhnlich erachten. Darüber hinaus sind die Einheiten für diese Daten nicht konsistent. Sie werden durch „B“ (Billion, eine Milliarde) und „M“ (Million, eine Million) dargestellt. Vor nachfolgenden Berechnungen ist eine Einheitsvereinheitlichung erforderlich.
1 Verarbeitungsmethode Methode-1
Die erste Verarbeitungsidee, die mir in den Sinn kommt, ist die Aufteilung der Dateninformationen in Milliarden ('B') bzw. Millionen ('M'). und schließlich zusammengeführt. Der Prozess ist wie folgt.
Laden Sie die Daten und fügen Sie den Namen der Spalte hinzu
import pandas as pd
df_2016 = pd.read_csv('data_2016.csv', encoding='gbk',header=None)# 更新列名df_2016.columns = ['Year', 'Rank', 'Company_cn','Company_en', 'Country_en', 'Sales', 'Profits', 'Assets', 'Market_value']
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)Ermitteln Sie die Einheit in Milliarden (' B') Daten
# 数据单位为 B的数据(Billion,十亿)df_2016_b = df_2016[df_2016['Sales'].str.endswith('B')]
print(df_2016_b.shape)
df_2016_bErhalten Sie Daten in Millionen ('M')
# 数据单位为 M的数据(Million,百万)df_2016_m = df_2016[df_2016['Sales'].str.endswith('M')]
print(df_2016_m.shape)
df_2016_mDies Die Methode ist relativ einfach zu verstehen, die Bedienung ist jedoch umständlich, insbesondere wenn viele Datenspalten verarbeitet werden müssen, was viel Zeit in Anspruch nimmt.
Ich werde hier nicht auf die weitere Verarbeitung eingehen. Natürlich können Sie diese Methode ausprobieren.
Das Folgende ist eine etwas einfachere Methode.
2 Verarbeitungsmethode Methode-2
2.1 Laden von Daten
Der erste Schritt besteht darin, Daten zu laden, was mit Methode-1 identisch ist.
Im Folgenden wird die Spalte „Umsatz“ verarbeitet
2.2 Zugehörige abnormale Zeichen ersetzen
Die erste besteht darin, die relevanten abnormalen Zeichen zu ersetzen, einschließlich das Währungssymbol des US-Dollars, die alphabetische Zeichenfolge „undefiniert“ und „B“. Hier wollen wir die Dateneinheiten einheitlich in Milliarden organisieren, sodass „B“ direkt ersetzt werden kann. Und „M“ erfordert mehr Verarbeitungsschritte.
2.3 Verarbeitung von „M“-bezogenen Daten
Die Verarbeitung von Daten, die Millionen von „M“-Einheiten enthalten, also Daten, die mit „M“ enden, lautet wie folgt:
(1) Legen Sie die Suchbedingungsmaske fest;
(2) Ersetzen Sie die Zeichenfolge „M“ durch einen leeren Wert
(3)用pd.to_numeric()转换为数字
(4)除以1000,转换为十亿美元,与其他行的数据一致
上面两个步骤相关的代码如下:
# 替换美元符号df_2016['Sales'] = df_2016['Sales'].str.replace('$','')# # 查看异常值,均为字母(“undefined”)# df_2016[df_2016['Sales'].str.isalpha()]# 替换异常值“undefined”为空白# df_2016['Sales'] = df_2016['Sales'].str.replace('undefined','')df_2016['Sales'] = df_2016['Sales'].str.replace('^[A-Za-z]+$','')# 替换符号十亿美元“B”为空白,数字本身代表的就是十亿美元为单位df_2016['Sales'] = df_2016['Sales'].str.replace('B','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df_2016['Sales'].str.endswith('M')
df_2016.loc[mask, 'Sales'] = pd.to_numeric(df_2016.loc[mask, 'Sales'].str.replace('M', ''))/1000df_2016['Sales'] = pd.to_numeric(df_2016['Sales'])
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head(3)用同样类似的方法处理其他列
可以看到,这个方法比第一种方法还是要方便很多。当然,这个方法针对DataFrame的每列数据都要进行相关的操作,如果列数多了,也还是比较繁琐的。
有没有更方便一点的方法呢。 答案是有的。
插播一条硬广:技术文章转发太多。文章来自微信公众号“Python数据之道”(ID:PyDataRoad)。
3 处理方法 Method-3
在Method-2的基础上,将处理方法写成更通用的数据处理函数,根据数据的结构,拓展更多的适用性,则可以比较方便的处理相关数据。
3.1 加载数据
第一步还是加载数据,跟Method-1是一样的。
3.2 编写数据处理的自定义函数
参考Method-2的处理过程,编写数据处理的自定义函数’pro_col’,并在Method-2的基础上拓展其他替换功能,使之适用于这四列数据(“Sales”,“Profits”,“Assets”,“Market_value”)。
函数编写的代码如下:
def pro_col(df, col): # 替换相关字符串,如有更多的替换情形,可以自行添加df[col] = df[col].str.replace('$','')
df[col] = df[col].str.replace('^[A-Za-z]+$','')
df[col] = df[col].str.replace('B','')# 注意这里是'-$',即以'-'结尾,而不是'-',因为有负数df[col] = df[col].str.replace('-$','')
df[col] = df[col].str.replace(',','')# 处理含有百万“M”为单位的数据,即以“M”结尾的数据# 思路:# (1)设定查找条件mask;# (2)替换字符串“M”为空值# (3)用pd.to_numeric()转换为数字# (4)除以1000,转换为十亿美元,与其他行的数据一致mask = df[col].str.endswith('M')
df.loc[mask, col] = pd.to_numeric(df.loc[mask, col].str.replace('M',''))/1000# 将字符型的数字转换为数字类型df[col] = pd.to_numeric(df[col])return df3.3 将自定义函数进行应用
针对DataFrame的每列,应用该自定义函数,进行数据处理,得到需要的结果。
pro_col(df_2016, 'Sales')
pro_col(df_2016, 'Profits')
pro_col(df_2016, 'Assets')
pro_col(df_2016, 'Market_value')
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()当然,如果DataFrame的列数特别多,可以用for循环,这样代码更简洁。代码如下:
cols = ['Sales', 'Profits', 'Assets', 'Market_value']for col in cols:
pro_col(df_2016, col)
print('the shape of DataFrame: ', df_2016.shape)
print(df_2016.dtypes)
df_2016.head()最终处理后,获得的数据结果如下:
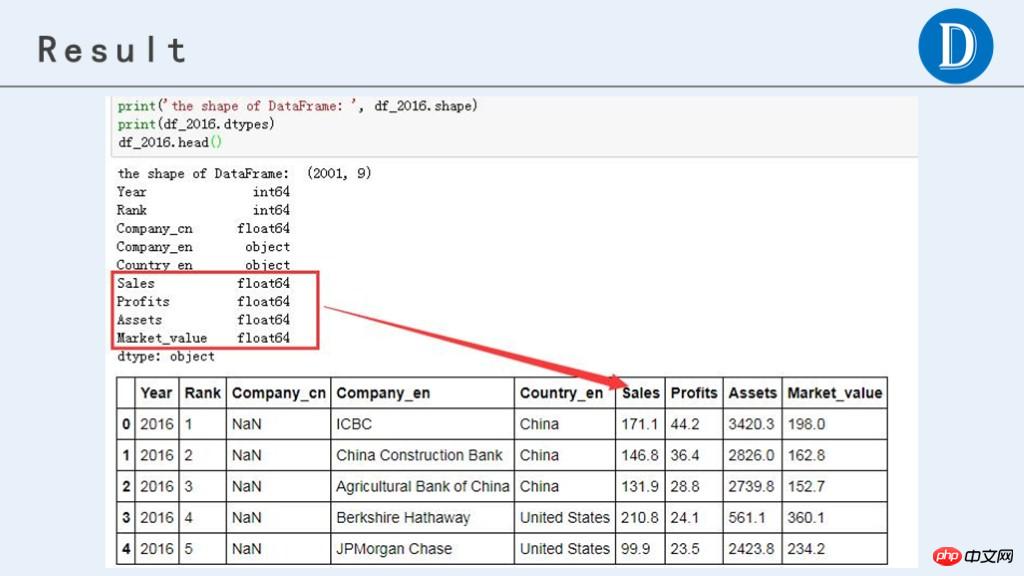
Das obige ist der detaillierte Inhalt vonBeispielanzeige für die Pandas-Datenverarbeitung: Erfassung globaler börsennotierter Unternehmensdaten. Für weitere Informationen folgen Sie bitte anderen verwandten Artikeln auf der PHP chinesischen Website!

Heiße KI -Werkzeuge

Undresser.AI Undress
KI-gestützte App zum Erstellen realistischer Aktfotos

AI Clothes Remover
Online-KI-Tool zum Entfernen von Kleidung aus Fotos.

Undress AI Tool
Ausziehbilder kostenlos

Clothoff.io
KI-Kleiderentferner

AI Hentai Generator
Erstellen Sie kostenlos Ai Hentai.

Heißer Artikel
Heiße Werkzeuge

Notepad++7.3.1
Einfach zu bedienender und kostenloser Code-Editor

SublimeText3 chinesische Version
Chinesische Version, sehr einfach zu bedienen

Senden Sie Studio 13.0.1
Leistungsstarke integrierte PHP-Entwicklungsumgebung

Dreamweaver CS6
Visuelle Webentwicklungstools

SublimeText3 Mac-Version
Codebearbeitungssoftware auf Gottesniveau (SublimeText3)
Heiße Themen
 1377
1377
 52
52

 Lösung häufiger Pandas-Installationsprobleme: Interpretation und Lösungen für Installationsfehler
Feb 19, 2024 am 09:19 AM
Lösung häufiger Pandas-Installationsprobleme: Interpretation und Lösungen für Installationsfehler
Feb 19, 2024 am 09:19 AM
Pandas-Installations-Tutorial: Analyse häufiger Installationsfehler und ihrer Lösungen. Es sind spezifische Codebeispiele erforderlich. Einführung: Pandas ist ein leistungsstarkes Datenanalysetool, das in der Datenbereinigung, Datenverarbeitung und Datenvisualisierung weit verbreitet ist und daher in der Branche hohes Ansehen genießt der Datenwissenschaft. Aufgrund von Umgebungskonfigurations- und Abhängigkeitsproblemen können jedoch bei der Installation von Pandas einige Schwierigkeiten und Fehler auftreten. In diesem Artikel erhalten Sie ein Pandas-Installations-Tutorial und analysieren einige häufige Installationsfehler und deren Lösungen. 1. Pandas installieren
 So lesen Sie eine TXT-Datei mit Pandas richtig
Jan 19, 2024 am 08:39 AM
So lesen Sie eine TXT-Datei mit Pandas richtig
Jan 19, 2024 am 08:39 AM
Um Pandas zum korrekten Lesen von TXT-Dateien zu verwenden, sind bestimmte Codebeispiele erforderlich. Pandas ist eine weit verbreitete Python-Datenanalysebibliothek. Sie kann zur Verarbeitung einer Vielzahl von Datentypen verwendet werden, einschließlich CSV-Dateien, Excel-Dateien, SQL-Datenbanken usw. Gleichzeitig können damit auch Textdateien, beispielsweise TXT-Dateien, gelesen werden. Beim Lesen von TXT-Dateien treten jedoch manchmal Probleme auf, z. B. Codierungsprobleme, Trennzeichenprobleme usw. In diesem Artikel erfahren Sie, wie Sie TXT mit Pandas richtig lesen
 Praktische Tipps zum Lesen von TXT-Dateien mit Pandas
Jan 19, 2024 am 09:49 AM
Praktische Tipps zum Lesen von TXT-Dateien mit Pandas
Jan 19, 2024 am 09:49 AM
Praktische Tipps zum Lesen von TXT-Dateien mit Pandas. In der Datenanalyse und Datenverarbeitung sind TXT-Dateien ein gängiges Datenformat. Die Verwendung von Pandas zum Lesen von TXT-Dateien ermöglicht eine schnelle und bequeme Datenverarbeitung. In diesem Artikel werden verschiedene praktische Techniken vorgestellt, die Ihnen dabei helfen, Pandas besser zum Lesen von TXT-Dateien zu verwenden, sowie spezifische Codebeispiele. TXT-Dateien mit Trennzeichen lesen Wenn Sie Pandas zum Lesen von TXT-Dateien mit Trennzeichen verwenden, können Sie read_c verwenden
 Vorstellung der effizienten Datendeduplizierungsmethode in Pandas: Tipps zum schnellen Entfernen doppelter Daten
Jan 24, 2024 am 08:12 AM
Vorstellung der effizienten Datendeduplizierungsmethode in Pandas: Tipps zum schnellen Entfernen doppelter Daten
Jan 24, 2024 am 08:12 AM
Das Geheimnis der Pandas-Deduplizierungsmethode: eine schnelle und effiziente Methode zur Datendeduplizierung, die spezifische Codebeispiele erfordert. Bei der Datenanalyse und -verarbeitung kommt es häufig zu Duplikaten in den Daten. Doppelte Daten können die Analyseergebnisse verfälschen, daher ist die Deduplizierung ein sehr wichtiger Schritt. Pandas, eine leistungsstarke Datenverarbeitungsbibliothek, bietet eine Vielzahl von Methoden zur Datendeduplizierung. In diesem Artikel werden einige häufig verwendete Deduplizierungsmethoden vorgestellt und spezifische Codebeispiele angehängt. Der häufigste Fall der Deduplizierung basierend auf einer einzelnen Spalte basiert darauf, ob der Wert einer bestimmten Spalte dupliziert wird.
 Einfaches Pandas-Installations-Tutorial: Detaillierte Anleitung zur Installation von Pandas auf verschiedenen Betriebssystemen
Feb 21, 2024 pm 06:00 PM
Einfaches Pandas-Installations-Tutorial: Detaillierte Anleitung zur Installation von Pandas auf verschiedenen Betriebssystemen
Feb 21, 2024 pm 06:00 PM
Einfaches Pandas-Installations-Tutorial: Detaillierte Anleitung zur Installation von Pandas auf verschiedenen Betriebssystemen, spezifische Codebeispiele sind erforderlich. Da die Nachfrage nach Datenverarbeitung und -analyse weiter steigt, ist Pandas für viele Datenwissenschaftler und -analysten zu einem der bevorzugten Tools geworden. Pandas ist eine leistungsstarke Datenverarbeitungs- und Analysebibliothek, die große Mengen strukturierter Daten problemlos verarbeiten und analysieren kann. In diesem Artikel wird detailliert beschrieben, wie Pandas auf verschiedenen Betriebssystemen installiert werden, und es werden spezifische Codebeispiele bereitgestellt. Auf dem Windows-Betriebssystem installieren
 Wie verbessert Golang die Effizienz der Datenverarbeitung?
May 08, 2024 pm 06:03 PM
Wie verbessert Golang die Effizienz der Datenverarbeitung?
May 08, 2024 pm 06:03 PM
Golang verbessert die Effizienz der Datenverarbeitung durch Parallelität, effiziente Speicherverwaltung, native Datenstrukturen und umfangreiche Bibliotheken von Drittanbietern. Zu den spezifischen Vorteilen gehören: Parallelverarbeitung: Coroutinen unterstützen die Ausführung mehrerer Aufgaben gleichzeitig. Effiziente Speicherverwaltung: Der Garbage-Collection-Mechanismus verwaltet den Speicher automatisch. Effiziente Datenstrukturen: Datenstrukturen wie Slices, Karten und Kanäle greifen schnell auf Daten zu und verarbeiten sie. Bibliotheken von Drittanbietern: Abdeckung verschiedener Datenverarbeitungsbibliotheken wie fasthttp und x/text.
 Verwenden Sie Redis, um die Datenverarbeitungseffizienz von Laravel-Anwendungen zu verbessern
Mar 06, 2024 pm 03:45 PM
Verwenden Sie Redis, um die Datenverarbeitungseffizienz von Laravel-Anwendungen zu verbessern
Mar 06, 2024 pm 03:45 PM
Verwenden Sie Redis, um die Datenverarbeitungseffizienz von Laravel-Anwendungen zu verbessern. Mit der kontinuierlichen Entwicklung von Internetanwendungen ist die Datenverarbeitungseffizienz zu einem Schwerpunkt der Entwickler geworden. Bei der Entwicklung von Anwendungen, die auf dem Laravel-Framework basieren, können wir Redis verwenden, um die Effizienz der Datenverarbeitung zu verbessern und einen schnellen Zugriff und ein schnelles Zwischenspeichern von Daten zu erreichen. In diesem Artikel wird die Verwendung von Redis für die Datenverarbeitung in Laravel-Anwendungen vorgestellt und spezifische Codebeispiele bereitgestellt. 1. Einführung in Redis Redis ist ein Hochleistungsspeicher für Daten
 FAQ für Pandas, die TXT-Dateien lesen
Jan 19, 2024 am 09:19 AM
FAQ für Pandas, die TXT-Dateien lesen
Jan 19, 2024 am 09:19 AM
Pandas ist ein Datenanalysetool für Python, das sich besonders zum Bereinigen, Verarbeiten und Analysieren von Daten eignet. Während des Datenanalyseprozesses müssen wir häufig Datendateien in verschiedenen Formaten lesen, beispielsweise TXT-Dateien. Während des spezifischen Vorgangs können jedoch einige Probleme auftreten. In diesem Artikel werden Antworten auf häufige Fragen zum Lesen von TXT-Dateien mit Pandas gegeben und entsprechende Codebeispiele bereitgestellt. Frage 1: Wie lese ich eine TXT-Datei? TXT-Dateien können mit der Funktion read_csv() von Pandas gelesen werden. Das ist weil
